
QR-Code auf vorliegenden Beitrag
1. Vorab
Dieser Beitrag wurde für die Sektion Rekonstruktion und Erneuerung romanischer Regional- oder Minderheitensprachen im Zeitalter der Digital Humanities des XXXVI. Deutschen Romanistentags verfasst. Der genannte Sektionstitel eröffnet einen außerordentlich weiten Horizont; denn die Ausdrücke, die er zusammenbringt, weisen
- in die Sprachgeschichte (‘Rekonstruktion’);
- in die Sprachplanung (‘Erneuerung’);
- in den Sprachvergleich (‘romanisch’);
- in die Geolinguistik (‘Regional-’);
- in die Sprachpolitik (‘Minderheiten-’);
- in die Sprachsoziologie (‘-sprache)’);
- in die Neuen Medien (‘Digital Humanities’).
Unser Beitrag ist zwar in der Geolinguistik und in den Neuen Medien zentriert, aber Perspektiven für die anderen Felder lassen sich leicht daraus ableiten, wie angedeutet werden wird.
2. Romanische Geolinguistik
Ziel des Projekts VerbaAlpina (VA) ist die kleinräumige, d.h. lokale Erfassung des spezifisch alpinen Wortschatzes in den drei im Untersuchungsgebiet gesprochenen Sprachfamilien (Germanisch, Romanisch, Slawisch). Diese systematische Erweiterung der traditionell einzelsprachlichen Dialektologie ist sinnvoll, da zahlreiche Bezeichnungstypen über die Grenzen nur einer Sprachfamilie hinaus verbreitet sind; diese Ausdrücke wurden daher nicht zu Unrecht als ‘Alpenwörter’ (vgl. Krefeld 2018w) bezeichnet. Die Konzeption, der VA verpflichtet ist, lässt sich als ‘interlinguale Geolinguistik’ (vgl. Krefeld 2018q) charakterisieren, da Varianten aus mehreren Einzelsprachen zusammengebracht werden; Berücksichtigung finden jedoch ausschließlich georeferenzierbare Belege, wobei die politische Gemeinde als Bezugseinheit der Georeferenzierung fungiert. Das potentielle Netz umfasst alle 6990 Gemeinden der so genannten Alpenkonvention. Dieser Voraussetzung genügen im wesentlichen zwei Typen von Quellen: grundsätzlich die Sprachatlanten und - wenngleich nicht im Grundsatz, sondern im Idealfall - die dialektale Lexikographie. Sobald diese gemeinsame Voraussetzung der Georeferenzierbarkeit gegeben ist, lassen sich beide Quellentypen auch komplementär darstellen, wie es auf den VA-Karten geschieht. So illustriert dieser Kartenausschnitt den Einbezug des Dizionario del dialetto di Montagne di Trento von Corrado Grassi, der einen einzigen Lokaldialekt thesauriert. Überblicksartige Darstellungen, wie auf der gerade genannten Beispielkarte, sind jedoch nur möglich, wenn die nicht selten zahlreichen lokalen Einheiten zu Gruppen zusammengefasst werden, so wie [fromˈavo], [fromˈazo|], [fryˈmai|, [furˈmaj|], [furmˈaʧ|] usw., die alle das Konzept KÄSE bezeichnen.
- Durch die Gruppierung werden die Belege zu Varianten abstrakterer Typen.
Systematisch unterschieden werden in VA sogenannte ‘morpho-lexikalische Typen’ und ‘Basistypen’ (vgl. Krefeld/Lücke 2018c); die morpholexikalischen Typen definieren sich über die Wortart, die Konstituenten des Worts (Basis [+ Wortbildungsmorphem]), im Fall von Nomina zudem über das Genus sowie über die Sprachfamilie; nun ist es praktisch, die Typen (d.h. die Klassen von Varianten) auch durch sprachliche Einheiten identifizieren zu können; dazu werden in VA die am besten bekannten/am weitesten verbreiteten Varianten gewählt, also die standardsprachlichen Äquivalente. So wird der morpholexikalische Typ, zu dem alle genannten Beispiele sowie 368 weitere (Stand: 17.9.2019) gehören, durch standardfra. fromage/standardita. formaggio identifiziert. Noch abstrakter sind die Basistypen; sie gestatten es morpho-lexikalische Typen zu gruppieren, wenn sie eine gemeinsame historische Basis haben; das gilt auch für morpho-lexikalische Typen unterschiedlicher Sprachfamilien, also im Fall von Entlehnungen. So werden die morpho-lexikalischen Typen fra. fromage/ita. formaggio (m.), formaggia| (f.), fra. forme/ita. forma zum Basistyp [[lat. forma(m)| gebündelt oder schweizerdeu. staafel, fra. étable (f.), ita. stabbio (m.) zum Basistyp lat. stabulum|.
3. FAIRness
3.1. ... im Allgemeinen
VA ist ein vollständig digital konzipiertes und realisiertes Projekt. Die erweiterten Möglichkeiten von Digitalisierung und Vernetzung bringen gegenüber den herkömmlichen Formen des wissenschaftlichen Publikationswesens neben Vorteilen auch Herausforderungen mit sich. Prekär ist vor allem die "Flüchtigkeit" aller elektronischen Medien. Gerade im Wissenschaftsbetrieb erwachsen daraus erhebliche Probleme. Einmal veröffentlichte Inhalte müssen zuverlässig, dauerhaft verfügbar und stabil zitierbar sein.
Seit einiger Zeit hat sich das Akronym FAIR etabliert, das schlagwortartig die wichtigsten Bedingungen formuliert, die erfüllt sein müssen, damit den genannten Erfordernissen genüge getan wird. Viele, wenn nicht die Meisten, werden die entsprechenden Schlagwörter kennen: Findability, Accessibilty, Interoperability und Reusability. Dass die genannten Kriterien sich zueinander nicht trennscharf verhalten, ist leicht erkennbar: Damit eine Ressource wiederverwendbar ist, muss sie natürlich auch auffindbar und zugänglich sein. Verbindliche Regelungen, welche Maßnahmen konkret ergriffen werden müssen, um die FAIR-Postulate zu erfüllen, existieren nicht. Sie bilden somit "nur" einen ausgesprochen wichtigen Orientierungspunkt, an dem die Konzeption eines digitalen Projekts ausgerichtet werden sollte.
VA bemüht sich mit einem Bündel von Maßnahmen, die zumeist jeweils nicht eindeutig einem der FAIR-Kriterien zuzuordnen sind, sondern - entsprechend der fehlenden Trennschärfe - häufig mehreren Postulaten zugleich begegnen, um die Einhaltung dieser Kriterien.
Seit einiger Zeit ist VA bestrebt, all seine Datenprodukte, wozu neben dem sprachlichen Kerndatenbestand auch der entwickelte Computercode oder auch erläuternde Texte gehören, in dauerhaften Repositorien unterzubringen. Besonders wichtig erscheint dabei die langfristige Existenzperspektive der die Repositorien betreibenden Institutionen. Naheliegend ist daher die Kooperation mit der Universitätsbibliothek der LMU (UB). Seit über einem Jahr ist VA Pilotprojekt in einem vom bayerischen Wissenschaftsministerium finanzierten Projekt zum Thema Forschungsdatenmanagement (e-humanities interdisziplinär; https://www.fdm-bayern.org/). Im Zuge dessen werden die VA-Daten um generische DataCite-Metadaten angereichert und werden bald – so zumindest die Perspektive – in Bibliothekskatalogen oder über sog. Datenaggregatoren wie v.a. GeRDI (Generic Research Data Infrastructure) auffindbar sein. Die VA-Daten erhalten im Rahmen der Übertragung in das OpenData-Repositorium der UB auch persistente feingranulare DOIs, was für die Nachnutzbarkeit bzw. Nachhaltigkeit eine wichtige Rolle spielt.
Ein wesentlicher Aspekt, der ebenfalls die FAIR-Kriterien berührt, ist sicherlich die Frage der Lizenzpolitik. Für Zugänglichkeit und Nachnutzung ist das traditionelle Copyright fraglos ein Hindernis, weswegen VA sämtliche von ihm selbst produzierten Inhalte unter eine möglichst freie Creative Commons Lizenz stellt (CC BY-SA).
Stabile Zitierbarkeit von VA-Ressourcen wird durch eine halbjährliche Versionierung des kompletten Datenbestands gewährleistet. Schließlich ist noch die Bedeutung der langfristigen Existenzperspektive hevorzuheben, die die Insititutionen haben *müssen*, von denen ein digitales Projekt betrieben wird. Im Fall von VA sind diese Rahmenbedingungen durch die Anbindung an die IT-Gruppe Geisteswissenschaften sowie an die UB ausgesprochen günstig.
Den größten Mehrwert, gleichzeitig jedoch auch die größte Herausforderung, stellt aus Sicht von VA die von FAIR geforderte Interoperabilität dar.1 Im Folgenden soll daher der Blick gezielt darauf gerichtet werden.
3.2. ... im Speziellen zum Ersten: Interoperabilität
Dieser "Begriff" impliziert zunächst technische Operationalisierung. Ganz wesentlich erscheint VA jedoch auch das Maß der Datengranulierung, die schlicht so fein sein muss, dass die einzelnen Datenobjekte gezielt und zweifelfsfrei angesprochen werden können.
VA unterscheidet im Wesentlichen drei Kern-Entitäten:
- Morpholexikalische Typen (im Folgenden kurz: "Morphtypen"),
- Konzepte sowie
- politische Gemeinden.
Die Daten innerhalb dieser Kategorien sind jeweils bis zur Einzelinstanz runtergebrochen, will heißen: Jeder einzelne Morphtyp und jedes Konzept ist in einer eigenen Zeile einer Datenbanktabelle abgelegt. Jedes dieser digitalen Objekte ist überdies mit einem eindeutigen und persistenten Identifikator versehen, wobei das Präfix L für Morphtypen, C für Konzepte und A für Ortschaften reserviert sind:
- L1435,"babeurre (m.) (roa.)"
- C612,"ALMHÜTTE (WIRTSCHAFTSGEBÄUDE AUF DER ALM)"
- A60171,"Sils im Engadin/Segl"
Letztlich handelt es sich bei diesem Nummernsystem um VA-spezifische Normdaten, die zweifelsfreie Identifizierungen von Inhalten ermöglichen.
Der Zugriff auf diese Daten kann nun entweder durch einen Menschen über einen Browser oder automatisiert durch Maschinen erfolgen. Für den automatisierten Zugriff durch Maschinen hat VA eine sog. API ("Application Programming Interface") entwickelt.
Der folgende Link zeigt die bislang durch die VA-Daten dokumentierte Verbreitung des VA-Morphtyps L1435 ("babeurre (m.) (roa.)") auf der interaktiven Online-Karte des Projekts:
https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=133&db=191&single=L1435
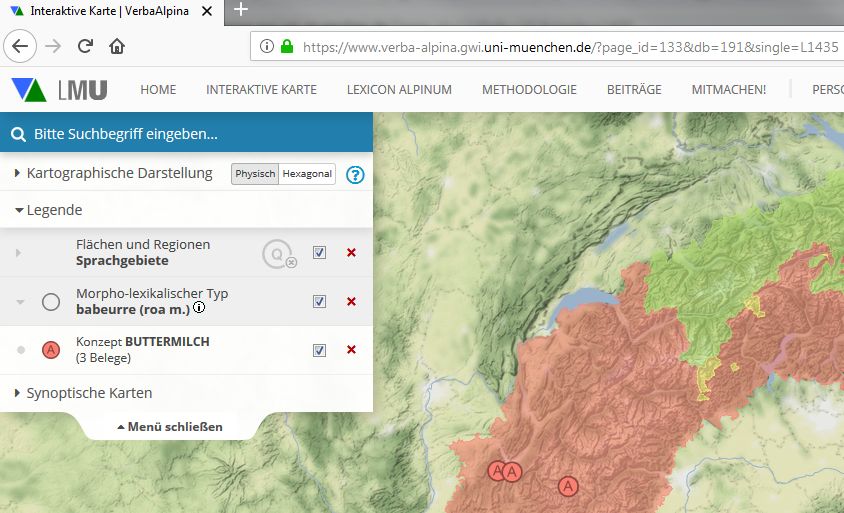
Interaktive Karte mit der bislang dokumentierten Verbreitung des morpholexikalischen Typs babeurre (L1435)
Auf den selben Morphtyp kann auch über die API von VA zugegriffen werden. Der folgende Link führt zum Download der nachfolgend abgebildeten XML-Datei.
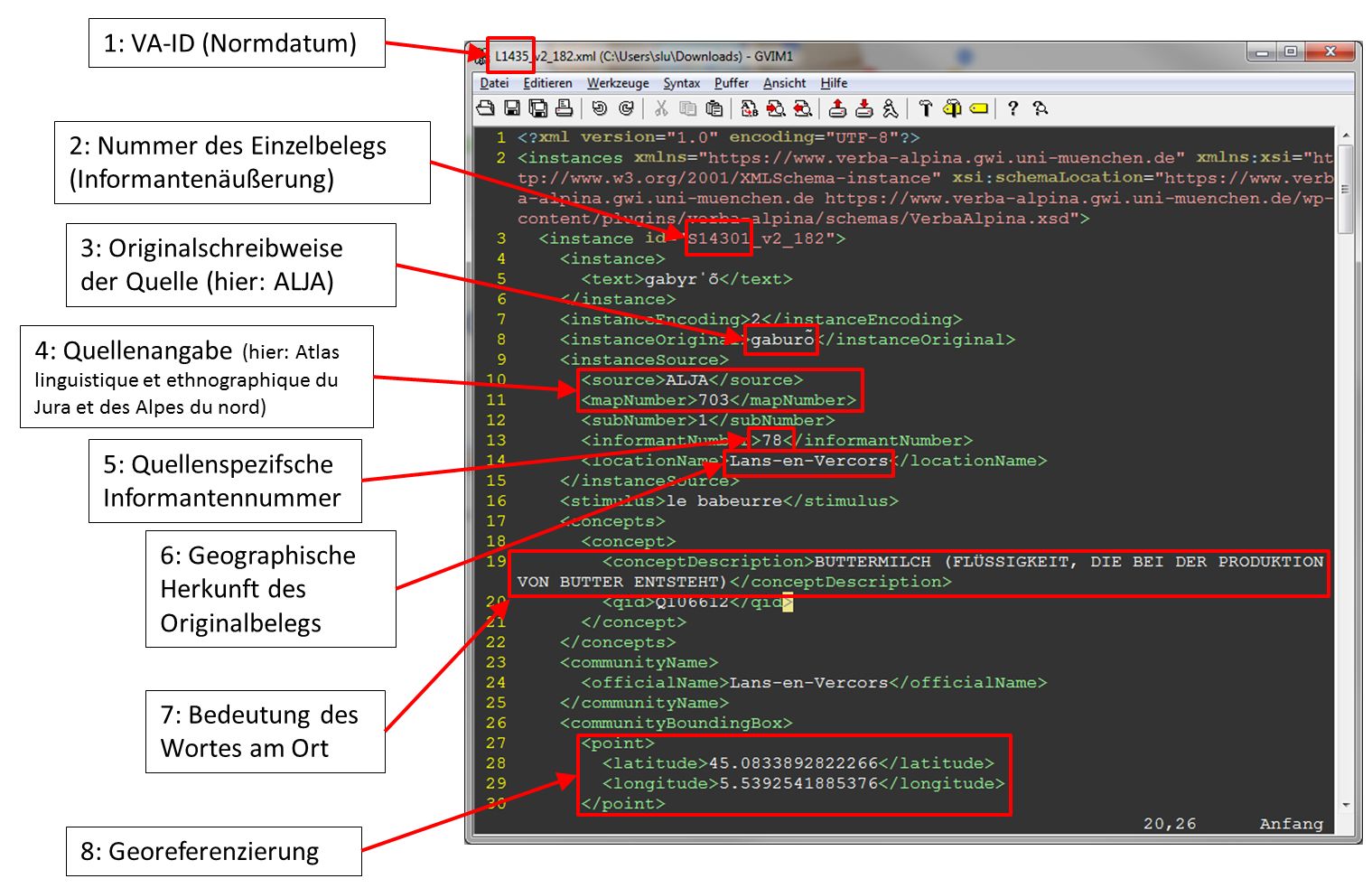
Repräsentation des morpholexikalischen Typs L1435 (babeurre) im XML-Format
Die vorliegende Datenrepräsentation stellt die wesentlichen im System erfassten Metadaten in strukturierter und von Maschinen verarbeitbarer Gestalt zur Verfügung. Die API von VA bietet eine Reihe unterschiedlicher Export- bzw. Zugriffsformate an. Neben dem hier gezeigten (VA-spezifischem; Schema-Definition) XML-Format sind auch csv- und json-Format verfügbar. Die genaue Syntax der VA-API ist auf einer eigenen Seite von VA im Detail dokumentiert.
Im Sinne der Interoperabilität ist VA bemüht, die eigenen Inhalte mit externen Datenbeständen zu verknüpfen. Dies erfolgt durch die Zuweisung von persistenten Identifikatoren. In diesem Punkt ist VA ganz wesentlich von den Betreibern jener externen Instanzen abhängig, von denen bei weitem nicht alle die erforderlichen Bedingungen erfüllen, wobei die jeweilige Problematik durchaus unterschiedlich gelagert sein kann. Letztlich sind eigentlich nur solche Ressourcen wirklich verwendbar, die sich ebenfalls den FAIR-Kriterien und hier speziell der Interoperabilität verpflichtet fühlen.
VA bindet derzeit u.a. Identifikatoren der folgenden Instanzen ein:
- Gemeinsame Normdatei (GND) der DNB (für KONZEPTE)
- Wikidata (für KONZEPTE und morpholexikalische Typen)
- Geonames (für Ortschaften)
- Sprachkodierungen nach ISO 639-3 (DEFAULT)
- verschiedene Referenz-Lexika (für morpholexikalische Typen; derzeit 43 Titel, darunter VocTrecc, FEW en ligne, DRG, Georges 1913 [1998], Kluge/Seebold 2015, Duden, ...)
Speziell die Interoperabilität der Ressourcen fällt durchaus unterschiedlich aus, und es ist erkennbar, dass der Mehrwert, der speziell durch feine Datengranulierung und elektronische Adressierbarkeit, entstehen kann, noch nicht überall erkannt worden ist. Im Hinblick auf die Referenz-Lexika lässt sich ein Kontinuum von vorbildlich bis - im informatisch-technischen Sinne - unbrauchbar konstatieren.
Als vorbildlich in diesem Sinne kann z. B. die online-Präsenz des lateinischen Handwörterbuchs von Karl-Ernst Georges (Georges 1913 [1998]) bezeichnet werden. Die Webseite erlaubt die präzise Referenzierung auf die einzelnen Wörterbucheinträge, überdies sind Struktur und Semantik der zu verwendenden URLs transparent:
http://www.zeno.org/Georges-1913/A/butyrum
Hervorzuheben ist in diesem Fall auch die offene Lizenz ("gemeinfrei"), sowie die Tatsache, dass es sich um eine HTML-Seite handelt, deren Inhalte durch copy/paste übernommen werden können.
Irgendwo im Graubereich des Kontinuums zwischen ideal und unbrauchbar bewegt sich die online-Präsenz des schweizerdeutschen Idiotikons (Idiotikon 1881). Hier ist eine Referenzierung zwar grundsätzlich, jedoch nicht mit der wünschenswerten Präzision möglich. Überdies ist die Struktur der einzusetzenden URLs kryptisch. Der folgende - und vom Idiotikon als "stabiler Direktlink" bezeichnete - Link verweist auf den Eintrag Teie(n):
https://digital.idiotikon.ch/idtkn/id12.htm#
Abgesehen davon, dass dieser Link nicht zuverlässig zu funktionieren scheint (Tests am 26.9.19), ist seine semantische Intransparenz zu bemängeln. Allerdings bietet das Idiotikon für seine Ressourcen mehrere konkurrierende URLs an, wobei gerade die nicht offiziellen anscheinend stabiler funktionieren, als die empfohlenen:
https://digital.idiotikon.ch/idtkn/faksimile.php?band=12&spalte=31&hl=229458
Dieser Link wird beim Aufruf wiederum auf folgenden weitergeleitet:
https://digital.idiotikon.ch/idtkn/id12.htm#!page/120031/mode/1up
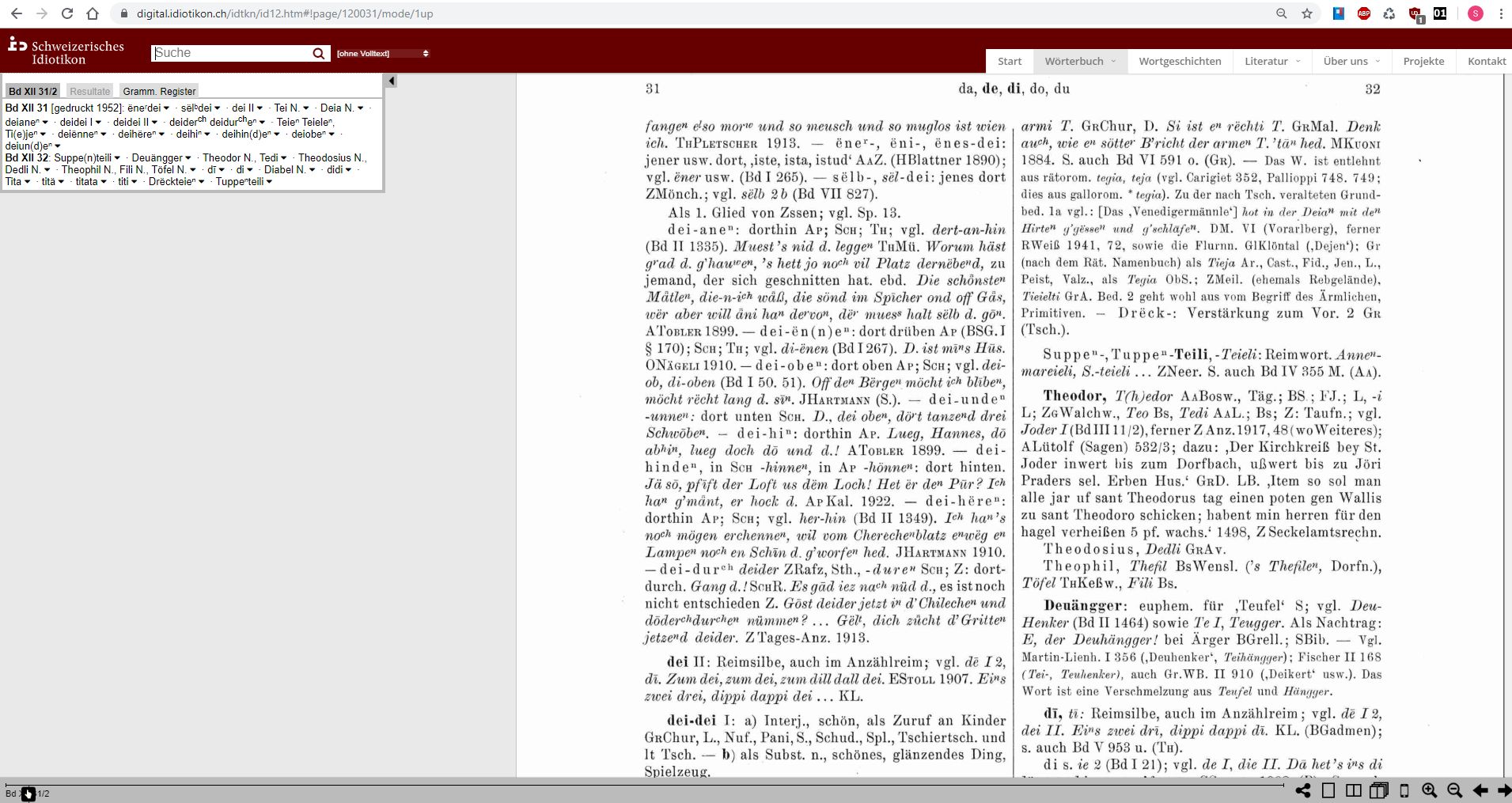
"Landingpage" beim Aufruf der URL https://digital.idiotikon.ch/idtkn/id12.htm#!page/120031/mode/1up, die auf den Eintrag Teie(n) verweist
Die Nennung von Band und Spalte in einer der Beispiel-URLs zeigt, dass die Referenzierbarkeit sich offenkundig an den Seiten des Druckwerks orientiert und nicht an den spezifischen Einträgen, um die es ja eigentlich geht. Der Eintrag Teie(n) erscheint erst, wenn man auf der angesteuerten Seite nach unten scrollt. Die Konsequenz ist, dass sämtliche auf einer Seite des Idiotikons befindlichen Artikel über ein und dieselbe URL angesprochen werden müssen, also keine individuellen URLs besitzen.
Zu bemängeln ist schließlich noch, dass sich die Idiotikon-URLs auf einen Scan des gedruckten Werkes beziehen und dabei nach wie vor dessen Seiten/Spalten-Logik als Referenzsystem fortwirkt, wie auch aus einem der oben zitierten Links hervorgeht. Die Übernahme von Inhalten durch Copy/Paste ist leider auch nicht möglich, da es sich um ein Bild und nicht um HTML-Code handelt.
Um die auf der FAIR-Skala vorhandenen Schattierungen noch etwas zu verdeutlichen, sei noch kurz der Dicziunari Rumantsch Grischun (DRG) erwähnt. Der folgende Link führt auf den Eintrag "BARGUN" ( ‘Heustadel auf Bergwiesen, Alpstall, Alphütte auf der obersten Weidestufe’):
http://online.drg.ch/main.aspx#35ac0b4c3795c91831f3534a40a0c5f0
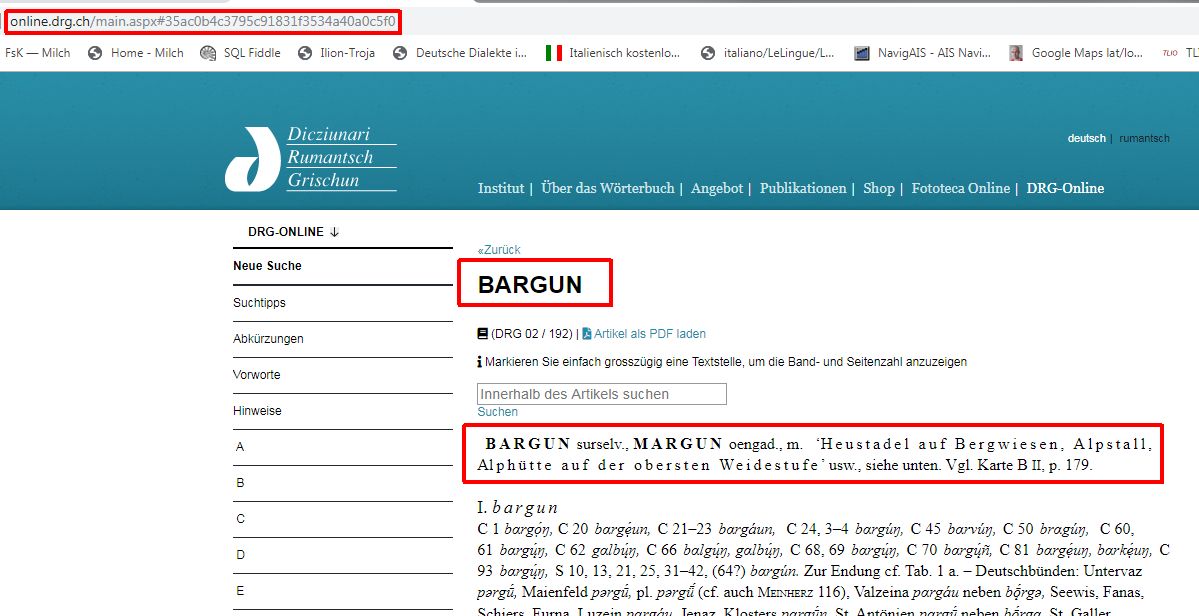
Eintrag BARGUN (ID 35ac0b4c3795c91831f3534a40a0c5f0) im DRG
Der Link verweist nicht wie beim Idiotikon auf die Buchseite, sondern springt exakt auf den entsprechenden Eintrag. Die dort präsentierten Inhalte liegen überdies in HTML vor, können also per copy/paste übernommen und zitiert werden. Zu bemängeln wäre höchstens die sperrige Gestalt des Identifikators, die eine intuitive oder auch automatische Erzeugung spezifischer URLs, wie dies z.B. bei der online Version des "Georges" möglich wäre, verhindern.
Das beschriebene Verfahren der Referenzierung auf Einträge in ausgewählten Referenzlexika lässt ein Beziehungsgeflecht entstehen, in dessen Mitte der Datenbestand von VA gesehen werden könnte:
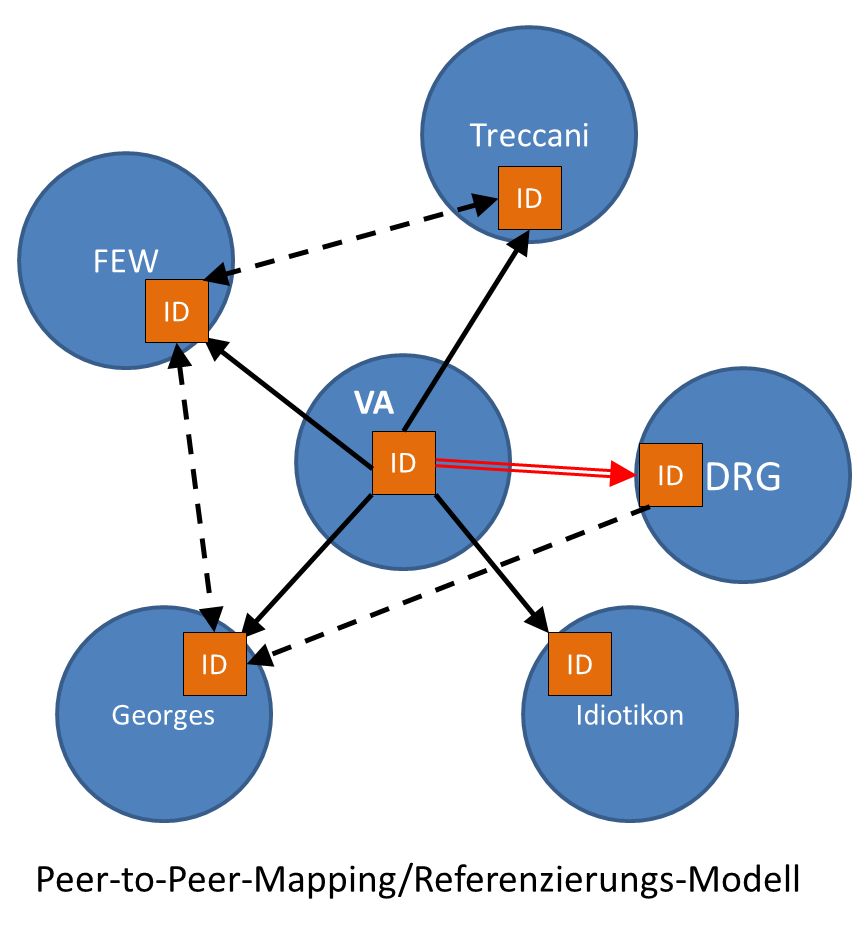
Dezentrale Verknüpfung lexikographischer Datenbestände
Die gestrichelten Linien symbolisieren theoretisch mögliche Mappings, die ggf. auch "manuell" auf einem Stück Papier erfolgen könnten; von technischer Realisierbarkeit oder gar Realisierung ist hier nicht die Rede. Doppelpfeile markieren direktes Mapping zwischen korrespondierenden Lemmata, einfache Pfeile bezeichnen monodirektionale Referenzierungen etwa aus Lexikoneinträgen heraus (z.B. Erwähnung des lat. casa als Etymon/Basistype zu chasa im DRG). Der rote Pfeil markiert exemplarisch die Referenzierung von einem VA-Morphtyp auf einen Eintrag im DRG.
Alternativ wäre die Erzeugung einer zentralen Instanz vorstellbar, auf die die unterschiedlichen lexikalischen Ressourcen, darunter auch VA, referieren. Wenigstens ansatzweise bietet das Lexemes-Portal von Wikidata eine entsprechende Perspektive. Sämtliche dort vorhandenen Einträge sind über eine sog. LID eindeutig und persistent identifiziert. Ein Vorteil besteht auch darin, dass die Wikidata-Lexeme von der Community nach Bedarf um weitere Einträge erweitert werden können. Natürlich ist mit diesem Vorteil auch die Gefahr der Erzeugung von Duplikaten und nachfolgenden Inkonsistenzen verbunden. Daher wäre ein, nach Möglichkeit von einer staatlichen Institution mit langfristiger Bestandsgarantie betriebenes, System vorzuziehen, das die Pflege des Datenbestands übernimmt oder zumindest überwacht. VA hat aus diesem Grund vor Kurzem Kontakt zu Vertretern der an der Deutschen Nationalbibliothek (DNB) angesiedelten Gemeinsamen Normdatei (GND) hergestellt, um die Perspektive der Etablierung von Morphtypen als weitere GND-Entität zu eruieren. Tatsächlich registriert die GND bereits jetzt vereinzelt Morphtypen, jedoch nur dann, wenn diese als Gegenstand einer im Sachkatalog der DNB erfassten Publikation auftreten. Die systematische Erfassung von Morphtypen samt Vergabe von persistenten Identifikatoren wird jedoch von der GND in absehbarer Zeit wohl nicht geleistet werden können. Aus diesem Grund erscheint bis auf Weiteres allein die Lexem-Abteilung von Wikidata als einzige universale Zentralinstanz für die projektübergreifende Referenzierung von Morphtypen.
Die geschilderte Situation hat zu der Idee geführt, einen wissenschaftlich-bibliothekarisch kontrollierten Dienst zu entwickeln, der eine mit den Lexemen von Wikidata vergleichbare Liste verwaltet, auf deren Konsistenz geachtet wird, und der überdies insofern operationalisiert ist, als er über technische Verlinkung direkt auf die verschiedenen Einträge in den unterschiedlichen lexikalischen Ressourcen verweist. An der LMU ist aktuell ein entsprechender DFG-Antrag in Vorbereitung, der gemeinsam vom Institut für Romanische Philologie, der Universitätsbibliothek sowie der IT-Gruppe Geisteswissenschaften getragen wird. Der Titel lautet programmatisch Lexicographia Coniuncta, kurz LexiCon. Die Einreichung des Antrags erfolgt im Lauf des Oktobers 2019. Konkret ist geplant, zunächst, beginnend mit dem REW, eine Reihe traditioneller Wörterbücher (erforderlichenfalls) zu retrodigitalisieren und anschließend nach Möglichkeit algorithmisch zu strukturieren und die Daten in einer gemeinsamen Datenbank abzulegen, die auch die ursprünglichen Referenzen dokumentiert.2
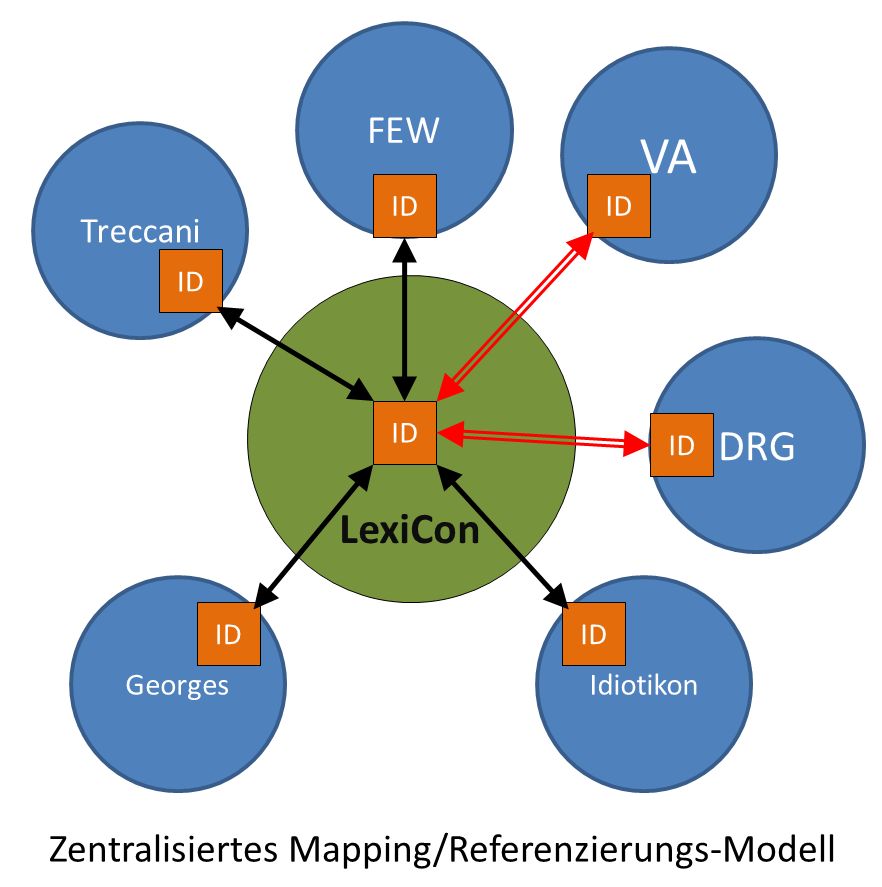
Verknüpfung lexikographischer Ressourcen über eine kontrollierte Zentralinstanz (LexiCon)
Wie sehr gerade die Propagierung der von den FAIR-Kriterien postulierten Interoperabilität Not tut, zeigt auch eine Reihe von jüngst publizierten Wörterbüchern des Dolomitenladinischen.3

Cover der Wörterbücher Italienisch-Ladinisch bzw. Deutsch-Ladinisch, herausgegeben vom Istitut Ladin Micurá de Rü (Quelle: https://www.micura.it/de/woerterbuecher)
Die insgesamt vier Bände sind ganz offenkundig als herkömmliche Buchpublikationen konzipiert und publiziert worden. Erst in einem zweiten Schritt erfolgte dann die Entwicklung einer Webpräsenz, die die Inhalte der Buchpublikationen auch elektronisch übers Internet zugänglich gemacht hat. Obwohl die Datenbestände inhaltlich aufs Engste miteinander verbunden sind, erscheinen sie auch im Internet im Grunde ebenso isoliert wie die im Bücherregal nebeneinander stehenden Buchpublikationen.
So führt beispielsweise eine Suche nach dem italienischen lumaca im Dizionario Italiano - Ladino Val Badia (http://itavalbadia.ladinternet.it/) auf den Eintrag des gadertalischen Wortes sgnech, um die Verbindung zum deutschen Wort Schnecke zu erkennen, muss man jedoch die Webseite des Wörterbuchs Deutsch - Gadertalisch aufrufen und manuell die Suche nach dem Wort Schnecke ausführen (https://www.micura.it/de/woerterbuecher/vb/dl?q=Schnecke), die dann als eines der Ergebnisse wiederum das ladinische sgnech liefert. Dies mag wenigstens noch einigermaßen verständlich sein angesichts der Tatsache, dass die italienisch-ladinischen Wörterbücher offenbar von einer anderen - privaten - Firma "ins Netz" gestellt worden sind als die deutsch-ladinischen.4 Wirklich unverständlich aber ist, dass selbst die Datenbestände der beiden italienisch-ladinischen Wörterbücher, deren Webportale von ein und derselben Firma entwickelt worden sind, nicht durch wechselseitige Verlinkung aufeinander bezogen sind. Auf diese Weise bleibt es der Intuition des Nutzers überlassen festzustellen, dass das gadertalische Wort sgnech eine offenkundige Entsprechung im grödnerischen snech besitzt.
Gleichsam die zweite Hälfte des Kerndatenmaterials von VA wird durch den Kosmos der KONZEPTE repräsentiert. Ebenso wie für die Morphtypen ist VA bestrebt, auch die Instanzen dieser Kategorie im Sinne der Interoperabilität mit externen Ressourcen zu verknüpfen. Eine ganz zentrale Rolle spielt dabei bislang wiederum die Wikidata, die neben dem Lexem-Portal bzw. sogar im Wesentlichen eine Sammlung von Konzepten enthält, die ihrerseits mit den verschiedensprachigen Artikeln der Wikipedia verknüpft sind. Das nachfolgende Beispiel zeigt den Eintrag "Chalet", spezifiziert als "ländlicher Haustyp im Alpenraum", "Sennhütte", das im Datenbestand von VA über die sog. QID mit dem Konzept SENNHÜTTE verknüpft ist:
https://www.wikidata.org/w/index.php?title=Q136689&oldid=1007516304 (Permalink)
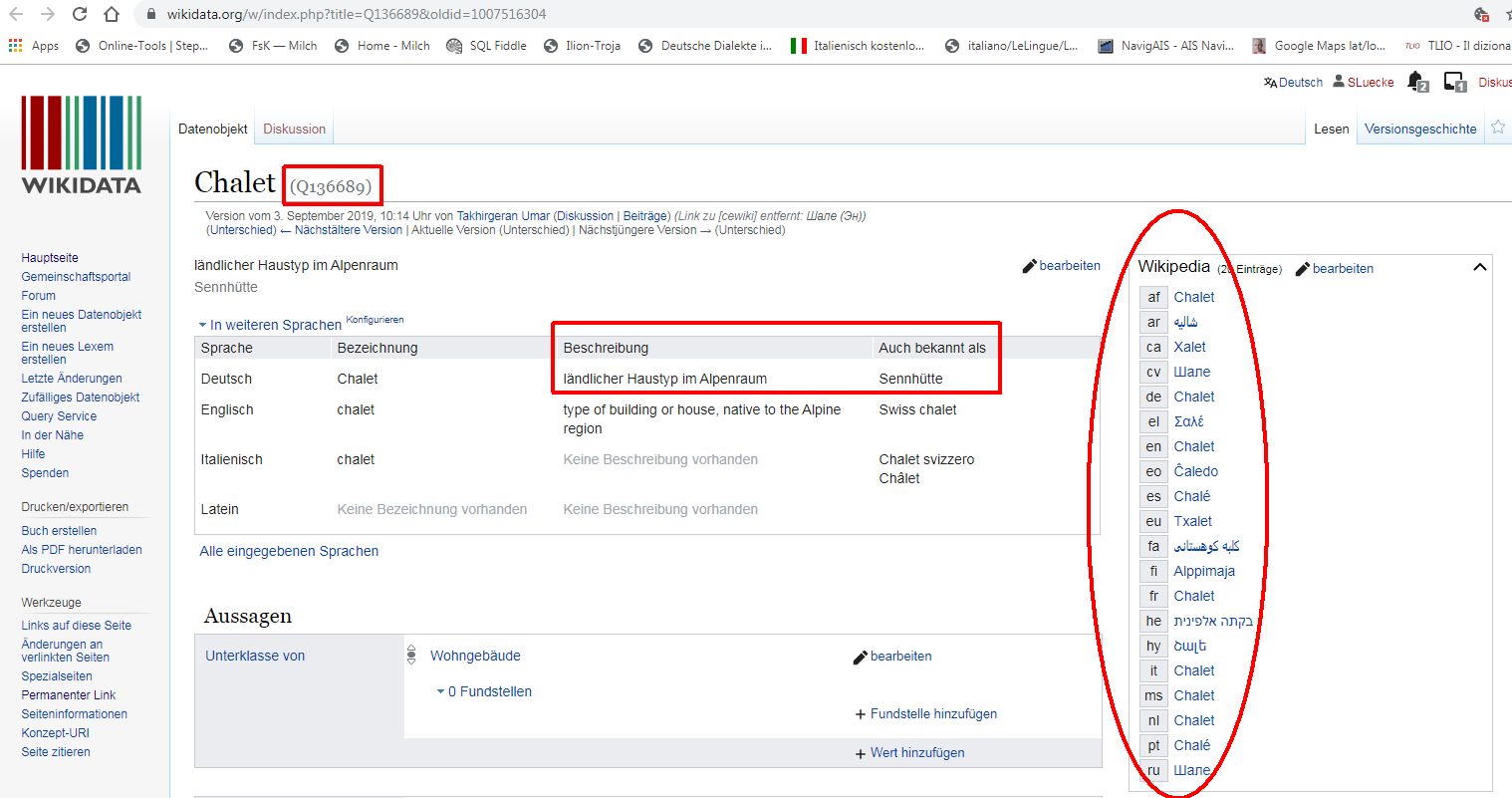
Seite des Wikidata-Datenobjekts Q136689 (CHALET, SENNHÜTTE)
Die Box rechts im Fenster listet die Titel der verschiedenen Einträge der Wikipedia auf, die letztlich die einzelsprachlichen Morphtypen darstellen, mit denen das Konzept SENNHÜTTE bezeichnet wird. Zumindest theoretisch ist damit eine logische Verknüpfung von jedem einzelnen der Wikipedia-Artikel zu den entsprechenden Datensätzen in VA gegeben. VA registriert die QIDs systematisch. In der interaktiven Karte des Projekts werden in den kleinen Popup-Fenstern, die die Einzelbelege präsentieren, gegebenenfalls Links auf die Wikidata-Datenobjekte angeboten.
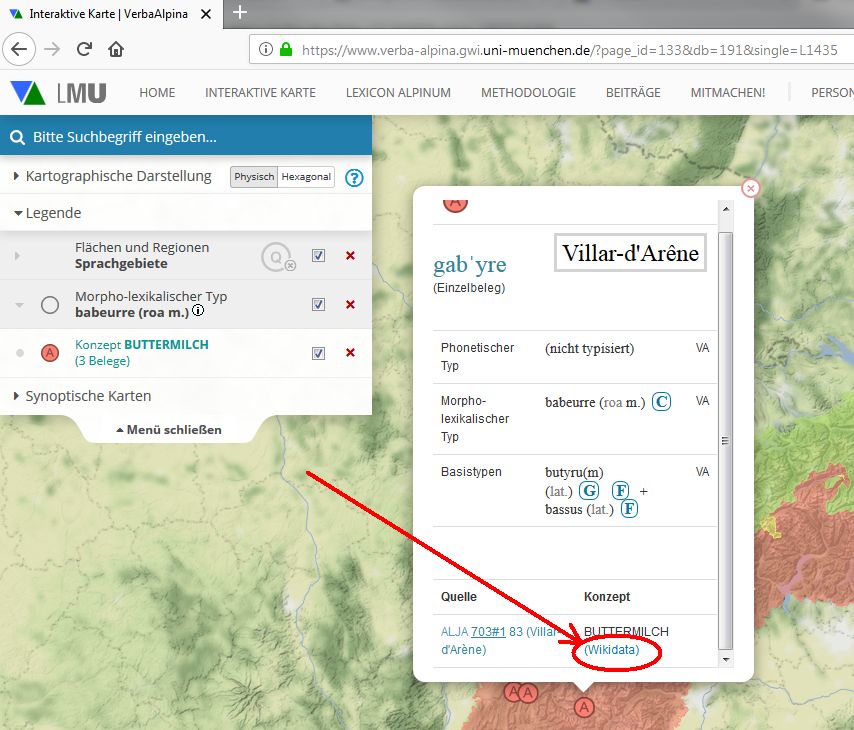
Verlinkung auf das Wikidata-Datenobjekt in einem Einzelbelegfenster auf der interaktiven Online-Karte von VA (https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=191&single=L1435&tk=2356)
3.3. ... im Speziellen zum Zweiten: Findbarkeit (am Beispiel geolinguistischer Identifikatoren
Wie die FAIR-Kriterien nun im Einzelnen ausbuchstabiert werden sollten, ist, wie bereits gesagt, nicht eindeutig zu beantworten, denn es ergeben sich unterschiedliche Möglichkeiten. Ein geolinguistisches Modell für die virtuelle Abbildung dialektaler Kontinua wird von VA entwickelt. Grundlegend für die Identifikation der Daten ist darin die Georeferenzierung, die auf der Ebene der politischen Gemeinde erfolgt. Zusätzlich zu den Geodaten wird jeder Sprachbeleg einer der drei alpinen Sprachfamilien zugeordnet. Die Zugehörigkeit kann übrigens nicht automatisch von der Gemeinde auf die Daten ‚vererbt‘ werden, denn es gibt durchaus zweisprachige Orte; so wurden für Selva di Progno oberhalb von Verona von Nutzern des CS–Tools germanische und romanische Belege geliefert, wie der Ausschnitt zeigt:
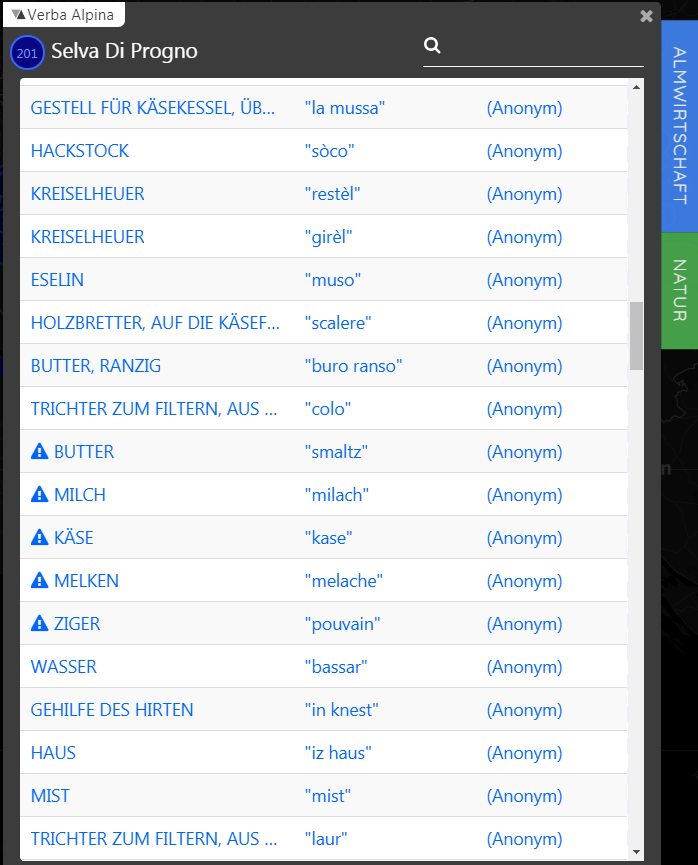
Zufälliger Ausschnitt aus den Crowd-Daten aus Selva di Progno
Die Zweisprachigkeit der gelieferten Materialien ist im Übrigen keineswegs überraschend, denn zur Gemeinde gehört die zimbrische Sprachinsel Ljetzan (ita. Giazza). Eine genauere Georeferenzierung auf diese frazione wäre übrigens auch keine Lösung, denn das Zimbrische ist in rapidem Rückgang begriffen, so dass auch im Ortsteil Ljetzan mittlerweile ganz überwiegend eine romanische Varietät gesprochen wird. Mit den Geokoordinaten und der Zuweisung einer Sprachfamilie ist eine lokal erhobene sprachliche Einheit hinreichend charakterisiert, um sie eindeutig im Dialektkontinuum zu verankern. Damit die lokalen sprachlichen Einheiten außerdem auch lexikologisch identifiziert werden, weist VA ihnen (wie eingangs gesagt) einen möglichst weitverbreiteten, nicht selten standardsprachlichen morpho-lexikalischen Typ zu, wie z.B. im Fall der im Ausschnitt gezeigten Form knest ‘Gehilfe des Hirten’ das deu. Knecht.
Allerdings lassen sich aus der Tatsache, dass diese lokale Form knest (sowie mehr oder weniger viele andere desselben Ortes auch) sich als Variante eines Typs erweist, für den es auch eine standarddeu. Variante gibt (Knecht) auch nicht im Ansatz Argumente gewinnen, ob man das lokale Zimbrische womöglich als eigenständige Sprache und nicht als Dialekt des Bairischen einstufen sollte. Diese Frage stellt sich im germanisch- und slawischsprachigen Gebiet der Alpen ohnehin selten, allenfalls noch für das Walserische in manchen italienischen Walsergemeinden| sowie für das Rezijansko in der Val Resia|. Im Hinblick auf die geolinguistische Dokumentation, die in sprachwissenschaftlicher Perspektive unbedingt im Vordergrund stehen muss, ist der Unterschied sekundär und letztlich vollkommen unerheblich, denn jeder Erhebungsort hat potentiell ein mehr oder weniger spezifisches Idiom, und alle diese lokalen Idiome sind im Hinblick auf das romanische Kontinuum gleichwertig - vollkommen unabhängig davon, ob ihr gesellschaftlicher Status als ‘Dialekt’ oder ‘Minderheitensprache’ eingestuft wird, oder ob sie in klassifikatorischer Absicht als ‘Kleinsprache’ oder ‘Subdialekt’ eines regional weiterverbreiteten Dialektverbunds eingeschätzt werden. Die romanische Situation muss man im Hinblick auf diese sprachsoziologischen und arealtypologischen Fragen als außerordentlich unübersichtlich bezeichnen. Ganz unterschiedlich motivierte Sprachnamen und klassifikatorische Kategorien werden oft vermischt. Das Problem muss hier nicht im Detail beschrieben werden; es reicht ein Blick auf das Rätoromanische in der Schweiz. Mit diesem Ausdruck wird in der Bundesverfassung 1999 eine der vier ‘Landessprachen’ bezeichnet. Im Art. 4 heißt es ganz lapidar:
"Die Landessprachen sind Deutsch, Französisch, Italienisch und Rätoromanisch." 5
Es wird in Art. 70 weiterhin spezifiziert, dass diese Sprache auch ‘Amtssprache’ ist:
"Die Amtssprachen des Bundes sind Deutsch, Französisch und Italienisch. Im Verkehr mit Personen rätoromanischer Sprache ist auch das Rätoromanische Amtssprache des Bundes." (Art. 70 Sprachen)
"Art. 3 Sprachen 1 Deutsch, Rätoromanisch und Italienisch sind die gleichwertigen Landes- und Amtssprachen des Kantons. [...] 3 Die Gemeinden bestimmen ihre Amts- und Schulsprachen im Rahmen ihrer Zuständigkeiten und im Zusammenwirken mit dem Kanton. Sie achten dabei auf die herkömmliche sprachliche Zusammensetzung und nehmen Rücksicht auf die angestammten sprachlichen Minderheiten" (VerfassungGR 2003).
Dem verfassungsrechtlichen Gebrauch entspricht die Sprachkodierung in ISO 693-3 , denn dort ist ebenfalls für 'Rätoromanisch' (bzw. eng. Romansh) ein Identifikator vorgesehen, nämlich roh. Diese Kodierung lässt sich zwar als ein verlässliches Normdatum in geolinguistischen Metadatensätzen verwenden; es ist jedoch nicht genau genug, denn ‘das’ Rätoromanische in Graubünden existiert in Gestalt von mindestens 7 Varietäten, von denen 6 auch in der Schriftlichkeit ganz selbstverständlich und mit lang zurückreichender Tradition gebraucht werden.6 Daher sind weitere Sprachcodes erforderlich, die z.B. von Wikidata oder vom Glottolog angeboten werden:7
| Varietäten gemäß Lia Rumantscha | Wikidata QID | Glottolog | Verfassungen CH, GR |
ISO-693.3 | |
| "Standardsprache" | Rumantsch Grischun | "Räto- romanisch" |
roh | ||
| "Schriftidiome" | Puter | ||||
| Vallader | Q690226 | Lower Engadine | |||
| Surmiran | Q690216 | Surmiran-Albula | |||
| Sursilvan | Q688348 | Sursilvan | |||
| Sursilvan-Oberland | |||||
| Sutsilvan | Q688272 | Sutsilvan | |||
| geprochener Dialekt | Jauer | Q690181 | |||
Man beachte, dass Wikidata das differenzierteste Angebot an IDs macht. Unabhängig davon, ob sie sich auf Dialekte oder (Klein)Sprachen beziehen, sind diese Codes mindestens dann für die geolinguistische Datenstrukturierung relevant, wenn sie in Referenzwörterbüchern explizit erscheinen, wie zum Beispiel im Niev Vocabulari sursilvan online (Decurtins o.J.), im Dicziunari Vallder (Uniun dals Grischs o.J.) oder im Dicziunari Puter (Uniun dals Grischs o.J. b). Glottolog identifiziert zwar die "Schriftidiome", bezeichnet sie jedoch teils (Puter, Vallader) nur mit englischen Termini. Darüber werden die in der Tabelle (Spalte ‘Glottolog’) identifizierten Idiome weiterhin auf der spezifischsten Ebene einer zwölfstufigen Hierarchie positioniert, die teils auf rezent geographischen, teils auf genealogischen Kriterien beruht (in Klammern steht die Anzahl der erfassten Sprachen)8:
Taxonomie des Glottolog
-
►Albanian (4)
-
►Anatolian (10)
-
►Armenic (3)
-
►Balto-Slavic (23)
-
►Celtic (14)
-
Dacian
-
►Germanic (106)
-
►Graeco-Phrygian (11)
-
►Indo-Iranian (324)
-
2.▼Italic (86)
-
3.▼Latino-Faliscan (83)
-
Faliscan
-
4.▼Latinic (82)
-
▼Imperial Latin (81)
-
5.►Latin
-
▼Romance (80)
-
►Eastern Romance (5)
-
6.▼Italo-Western Romance (70)
-
►Italo-Dalmatian (5)
-
7.▼Western Romance (65)
-
8.▼Shifted Western Romance (63)
-
9.▼Northwestern Shifted Romance (31)
-
►Gallo-Italian (8)
-
10.▼Gallo-Rhaetian (23)
-
►Friulian
-
►Ladin
-
►Oil (20)
-
11.▼Romansh
-
Lower Engadine
-
Rumantsch Grischun
-
Surmiran-Albula
-
Sursilvan
-
Sursilvan-Oberland
-
Sutsilvan
-
Upper Engadine
-
-
-
-
-
-
-
-
-
-
-
Jede taxonomische Ebene ist durch einen (hier nicht wiedergegebenen) Identifikator ansprechbar, so dass sich natürlich die Frage erhebt, ob diese auf den ersten Blick elaborierte Taxonomie, speziell die sechs romanischen Stufen für die digitale Strukturierung geolinguistischer Kontinua aus der Romania - im Sinne der FAIR-Kriterien F und I (Findable, Interoperable) - einen nützlichen Fortschritt bedeutet. Die Antwort ist ebenso klar wie kurz: nein. Es fehlt den Kategorien jedenfalls am Ort, wo sie bereitgestellt werden, jegliche Transparenz, da keine Daten hinterlegt sind und keinerlei Kriterien mitgeliefert werden, die sich auf konkrete Daten anwenden ließen; dazu müsste gesagt werden, wo z.B. der Westen ("Western Romance") beginnt, wie eine alternative Trennung in 'Gallo-Italian' und 'Gallo-Rhaetian' abgeleitet wird usw. Von der fehlenden Operationalisierung dieser klassifikatorischen Kategorien abgesehen muss ganz grundsätzlich bezweifelt werden, ob sich derartige top down formulierte trennscharfe Klassifikatoren überhaupt auf Kontinua anwenden lassen. Der einzig mögliche Weg für eine raumbezogene Klassifikation geht bottom up durch die metrische Bestimmung gemeinsamer bzw. nicht-gemeinsamer Merkmale, also im Sinne einer induktiven, datengetriebenen Dialektometrie, deren Präsentation stets gestattet zu den zugrunde liegenden Daten zurückzugehen und insofern auch reusability verspricht. Voraussetzung dafür ist jedoch, dass nicht nur die lokalen Idiome, sondern alle relevanten sprachlichen Merkmale mit eindeutigen Identifikatoren versehen werden; Ansätze dazu finden sich bereits im bereits erwähnten Wikidataprojekt in Gestalt von QIDs für grammatische Kategorien und LIDs für lexikalische Typen und selbstverständlich ebenfalls für morphosyntaktische Katgeorien/Funktionen. Dieser Bestand sollte durch alle geolinguistischen Projekte im Sinne der FAIR-Prinzipien systematisch ausgebaut werden. Angesichts dieser eigentlich fundamentalen Herausforderung ist die skizzierte Taxonomie nicht nur unnütz sondern schädlich.
QR-Code auf vorliegenden Beitrag
Bibliographie
- Bundesverfassung 1999 = Bundesverfassung (1999): Bundesverfassung der Schweizerischen Eidgenossenschaft (Stand am 23. September 2018) (Link).
- Burch/Rapp 2006 = Burch, Thomas / Rapp, Andrea (2006): Das Wörterbuch-Netz: Verfahren-Methoden-Perspektiven, in: Geschichte im Netz: Praxis, Chancen, Visionen. Beiträge der Tagung. hist, 607-627.
- Decurtins o.J. = Decurtins, Alexi (o.J.): Niev Vocabulari sursilvan online (Link).
- DRG = Melcher, Florian / De Planta, Robert (Hrsgg.) (1939-): Dicziunari Rumantsch Grischun, Cuoira, Società Retorumantscha (Link).
- FAIR = GO FAIR Initiative: Principles (Link).
- FEW en ligne = atilf: Französisches etymologisches Wörterbuch (Link).
- Forni 2013b = Forni, Marco (2013): Dizionario italiano-ladino gardenese / Dizioner ladin de Gherdëina-talian, San Martin de Tor, Istitut Ladin «Micurà de Rü» (Link).
- Georges 1913 [1998] = Georges, Karl Ernst (1913 [1998]): Ausführliches lateinisch-deutsches Handwörterbuch, Hannover (Darmstadt) (Link).
- Glottolog = Hammarström, Harald u.a. (2019): Glottolog 4.0, Jena, Max Planck Institute for the Science of Human History (Link).
- Grassi 2009 = Grassi, Corrado (2009): Dizionario del dialetto di Montagne di Trento, San Michele all'Adige.
- Idiotikon 1881 = Idiotikon, Schweizerisches (1881): Wörterbuch der schweizerdeutschen Sprache, in: Begonnen von Staub F. und Tobler L. Bearb. von Bachmann A. Bd. I—XIV. Frauenfeld.
- Kluge/Seebold 2015 = Kluge, Friedrich / Seebold, Elmar (2015): Etymologisches Wörterbuch der deutschen Sprache, Berlin/Boston, De Gruyter (Link).
- Krefeld 2018q = Krefeld, Thomas (2018): Interlinguale Geolinguistik, in: Methodologie, VerbaAlpina-de 18/2 (Link).
- Krefeld 2018w = Krefeld, Thomas (2018): Alpenwörter, in: Methodologie, VerbaAlpina-de 18/2 (Link).
- Krefeld/Lücke 2018c = Krefeld, Thomas / Lücke, Stephan (2018): Typisierung, in: Methodologie, VerbaAlpina-de 19/1 (Link).
- Lücke 2018b = Lücke, Stephan (2018): FAIR-Prinzipien, in: Methodologie, VerbaAlpina-de 18/2 (Link).
- Mihm 2010 = Mihm, Hildegard (2010): Rezension:„Das Wörterbuch-Netz “, in: Lexicographica, vol. 26, DE GRUYTER, 97-108.
- Mischì 2001 = Mischì, Giovanni (2001): Wörterbuch deutsch - gadertalisch = Vocabolar todësch - ladin, , San Martin de Tor (Link).
- Mischí 2002 = Mischì, Giovanni (2002): Wörterbuch : Deutsch - Grödner-Ladinisch = Vocabuler : tudësch - ladin de Gherdëina, , San Martin de Tor, Istitut Ladin Micurà de Rü (Link).
- Moling 2016 = Moling, Sara (2016): Dizionario italiano - ladino Val Badia; Dizionar ladin Val Badia - talian, San Martin de Tor, Istitut ladin Micurá de Rü (Link).
- REW = Meyer-Lübke, Wilhelm (1935): Romanisches etymologisches Wörterbuch 3., vollst. neubearb. Aufl., Heidelberg, Winter (Link).
- Uniun dals Grischs o.J. = Uniun dals Grischs (o.J.): Dicziunari Vallader (Link).
- Uniun dals Grischs o.J. b = Uniun dals Grischs (o.J.): Dicziunari Puter (Link).
- VerfassungGR 2003 = VerfassungGR (2003): Verfassung des Kantons Graubünden (Stand am 27. September 2016) (Link).
- VocTrecc = Vocabolario, Treccani: Vocabolario Treccani , Rom, Istituto della Enciclopedia Italiana (Link).