| Motto: Das Wörterbuch ist tot - es lebe die Lexikographie! |
1. Hintergrund: Gattungsgeschichte und Mediengeschichte1
Die Gattung des Wörterbuchs ist ein Produkt der ersten medialen Revolution, nämlich der Durchsetzung des Buchdrucks, und insofern geradezu emblematisch für die sogenannte Gutenberg-Galaxis (vgl. McLuhan 1962): In den europäischen Sprachgemeinschaften entfaltete sich die Lexikographie im Laufe des 16. Jahrhunderts schnell. Es entwickelte sich mit den ersten großen Referenzwörterbüchern, vor allem im Gefolge des Vocabolario degli Accademici della Crusca (1612), eine kanonische Form, die mit großer Selbstverständlichkeit grosso modo bis in die jüngste Zeit, ja bis in die Gegenwart reproduziert wird.
Wörterbücher haben in erheblichem Maße zur Herausbildung von Standardvarietäten beigetragen; nicht selten wurden sie ganz bewusst als Instrument der Standardisierung geplant und eingesetzt. Aber komplementär und nicht selten in direkter Verbindung entstand auch eine durchaus ambitionierte und elaborierte Dialektlexikographie; so wurde im Italien des 19. Jahrhunderts eine ganze Serie bis heute wichtiger Dialektwörterbücher (vgl. Boerio 1829, Cherubini 1814, di Sant'Albino 1859, u.a.) verfasst, die im Selbstverständnis ihrer Autoren zur Kenntnis und Verbreitung des Standards beitragen sollten, de facto jedoch gerade die Dialekte systematisch dokumentierten.
In jedem Fall ist die europäische Lexikographie ein wichtiger und unverzichtbarer Pfeiler des kulturellen Gedächtnisses; die Thesaurierung des Wortschatzes als solche ist gewissermaßen materialisierte historische Erinnerungsarbeit.
Mit der zweiten medialen Revolution durch die sogenannten Neuen Medien ist nun eine radikal veränderte Situation entstanden, die zwar den Sinn der Lexikographie keineswegs in Frage stellt, sondern - ganz im Gegenteil - nachdrücklich unterstreicht. Vollkommen obsolet geworden ist jedoch in wenigen Jahren das Format des abgeschlossenen, medial isolierten einzelnen Wörterbuchs. Denn die kulturellen Aufgaben der Lexikographie werden bei konsequenter Verwendung von Webtechnologie in nicht weniger adäquater, aber deutlich effizienterer Weise erfüllt; das gilt sowohl im Hinblick auf die Vielfalt und Menge der auswertbaren Quellen wie im Hinblick auf die öffentliche Verfügbarkeit des produzierten lexikographischen Angebots, das nicht länger von den mehr oder weniger reichhaltigen Beständen eingeschränkt zugänglicher Bibliotheken abhängig ist.
Die aktuelle Situation steht im Zeichen des Übergangs und ist dementsprechend disparat; nebeneinander stehen Werke, die sehr unterschiedlichen Digitalisierungsgraden im Sinne von Lücke 2019 entsprechen:
| Mediale lexikographische Formate | Digital.grad | |
| (a) | Printwörterbücher, die nicht abgeschlossen sein müssen (z.B. VS) | 0 |
| (b) | retrodigitalisierte, aber nicht/kaum tiefenerschlossene Printwörterbücher, die im Internet wie ein paginiertes Buch gelesen bzw. konsultiert werden können (z.B. FEW en ligne, REW), deren Inhalt jedoch nicht elektronisch durchsuchbar ist (Bildateien oder auch nicht mit elektronischem Text hinterlegte PDFs) | 1 |
| (c) | Wörterbücher auf der Basis von digitaler Textverarbeitung aber ohne Webtechnologie (z.B. Foti 2015), deren Text elektronisch durchsuchbar, jedoch nicht logisch strukturiert oder bestenfalls teilstrukturiert ist (z. B. die in archive.org abrufbare Version des REW). | 2 |
| (d) | genuin virtuelle Wörterbücher, deren Inhalt als vollstrukturierter elektronischer Text in mehr oder minder feiner Granulierung vorliegt und deren Publikation von vorneherein mit Webtechnologie konzipiert und realisiert wurde (z.B. LEO, TLIO) oder retrodigitalisierte und tiefenerschlossene Printwörterbücher, die nicht abgeschlossen sein müssen, aber deren Inhalt sekundär feingranuliert strukturiert und webtechnologisch aufbereitet wurde und jetzt mit Suchfiltern im Web angeboten wird (z.B. AWB) | 3 |
Zur Disparität der Gegenwartslexikographie trägt aber auch die Tatsache bei, dass sich gerade mit dem technologisch avanciertesten Digitalisierungsgrad 3 eine lexikographische Ausrichtung Bahn gebrochen hat, die sich von der Tradition sehr stark unterscheidet; exemplarisch ist hier der Dienst LEO zu nennen, der sich einerseits durch seine Dynamik in Bezug auf die erfassten Lemmata und den äußerst reichhaltigen und dynamischen Bestand an Beispielen auszeichnet und schnell auf Neologismen und Frequenzverschiebungen regieren kann, der aber andererseits auf viele metalexikalische Informationen verzichtet (Erstbeleg, Herkunft, Registerzuweisungen usw.). Gerade die genuin webbasierte Lexikographie polarisiert daher - zu Unrecht - die Nutzer; es handelt sich ja nicht um ein Angebot mit substituierendem, sondern mit komplementärem Inhalt. Massiv verdrängt und mittelfristig substituiert wird jedoch das Trägermedium des Drucks und das korrespondierende Format der Seite.
2. Ziel
Die skizzierte Lage fordert also geradezu den Aufbau eines Dienstes, der die komplementären Stränge in einer nutzerfreundlichen Oberfläche integriert, und der weiterhin Prozeduren bereitstellt und exemplifiziert, mit welchen Wörterbücher niederer Digitalisierungsgrade auf einen mediengerechten, zeitgemäßen Grad ‘angehoben’ werden können.
Der Nukleus eines solchen Dienstes würde mit dem Projekt entwickelt; sein Ziel ist also nicht die Erstellung eines reinen Netzes von Wörtern (d.h. von morpho-lexikalischen Typen), wie es z.B. durch den sehr technischen Dienst lexvo (lexvo.org) bereits geleistet wird, sondern eines Netzes von Wörtern, die jeweils in den Kontext eines lexikographischen Artikels eingebettet sind. Nur so kann das spezielle historische Wissen der klassischen Wörterbücher, das für das Selbstverständnis der historisch-vergleichend angelegten Philologien (‘Germanistik’, ‘Romanistik’, ‘Slawistik’, usw.) von grundlegendem Wert ist, im Sinne dieser Disziplinen erfolgreich in die virtuelle Lexikographie transportiert werden. Das eigentliche Ziel besteht deshalb in der Entwicklung eines Netzes von einheitlich strukturierten Wörterbuchartikeln (Digitalisierungsgrad 3).
2.1. Nutzeroberfläche
In diesem Sinn wird eine Benutzerschnittstelle mit unterschiedlichen Zugängen und Funktionen entwickelt, die sowohl eine diachrone als auch synchrone Perspektive eröffnen.
2.1.1. Funktion Itemsuche
Als zentrale Sucheinstiege sind geplant:
(a) Onomasiologischer Zugriff: Sucheinstieg über die Auswahl eines KONZEPTs.
Die vorgesehene Verknüpfung der Konzepte mit etablierten Normdatenvokabularen hat zwei positive Effekte auf die Suche: Zum einen ermöglichen die vom Normdatensystem bereitgestellten Konzept-Beschreibungen dem Benutzer einen prinzipiell sprachunabhängigen, sachbezogenen Sucheinstieg. Zum anderen lassen sich die Beziehungen zwischen den Konzepten des Normdatensystems in Form eines hierarchischen Konzeptbaums präsentieren, durch welchen der Benutzer komfortabel navigieren kann.
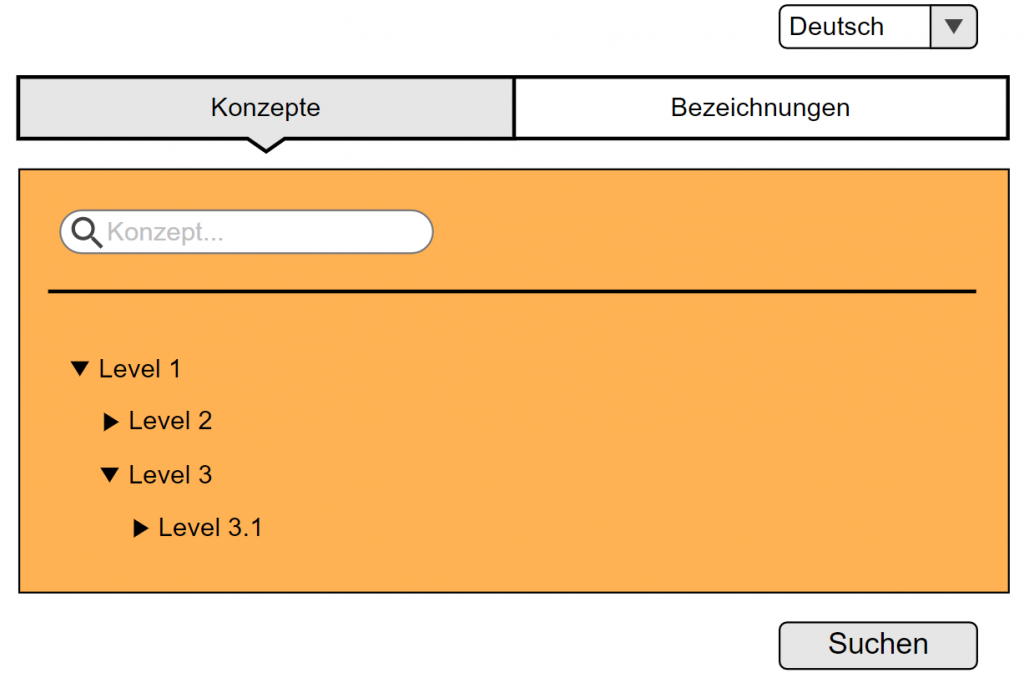
Eingabemaske für den onomasiologischen Sucheinstieg (Mockup)
(b) Semasiologischer Zugriff: Sucheinstieg über die Eingabe einer sprach-spezifizierten Bezeichnung
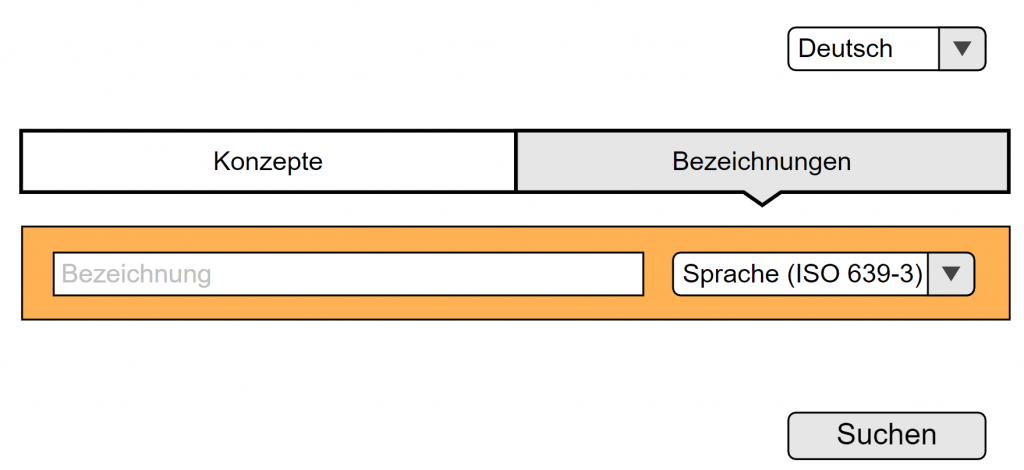
Eingabemaske für den semasiologischen Sucheinstieg (Mockup)
Alternativ zum hier vorgestellten Modell, in dem der Nutzer sich zunächst zwischen dem onomasiologischen und dem semasiologischen Sucheinstieg zu entscheiden hat, wäre auch die Variante einer nachgelagerten Differenzierung vorstellbar, bei der der Nutzer nach der Eingabe eines Suchstrings zwischen Bezeichnungen und Konzepten entscheiden kann. In dieser Weise ist z.B. die Suchlogik auf der interaktiven online-Karte von VerbaAlpina konzipiert:
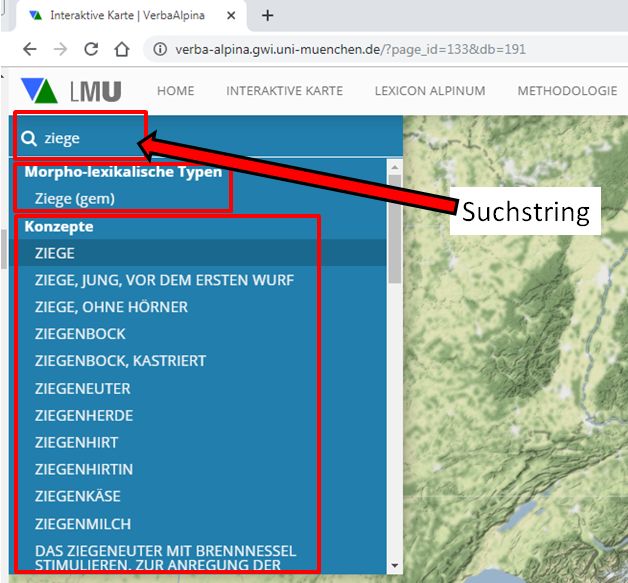
Kombinierte Suche nach Morpholexikalischen Typen und Konzepten mit nachgelagerter Auswahl (https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=133&db=191)
Sowohl die Konzepte als auch die Bezeichnungen werden durch global eindeutige URIs identifiziert (Normdaten; vgl. Lücke 2018d), wodurch sie auch über das Projekt hinaus als digitale Objekte referenzierbar werden. Als solche stehen sie zueinander in einer m:n-Beziehung: eine Bezeichnung kann ebenso mehreren KONZEPTEN zugeordnet sein (Polysemie und Homonymie), wie ein KONZEPT mehreren Bezeichnungen (Synonymie).
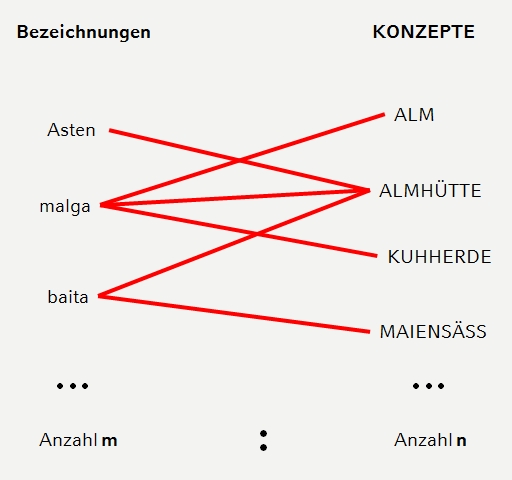
Zusammenhang zwischen Bezeichnung und KONZEPT (Graphik entnommen aus Lücke 2016c)
2.1.2. Funktion Visualisierung
Neben der Itemsuche werden dem Nutzer quantitative Visualisierungen (z.B. durch Wolken und Heatmaps) der skizzierten Relationen angeboten; sie zeigen in prägnanter Weise, für welche KONZEPTE besonders viele Bezeichnungen existieren, welche KONZEPTE und Bezeichnungen besonders attraktiv für Entlehnungen oder welche Bezeichnungen welcher Konzepte sich durch besondere Resilienz auszeichnen (so die Bezeichnungen von MILCH im Unterschied zu KÄSE, von GUT im Unterschied zu SCHLECHT/BÖSE usw.).
2.2. Positionierung von LexiCon im Umfeld der virtuellen Lexikographie
Das am Trier Center for Digital Humanities beheimatete und bereits in den 2000-nuller-Jahren entwickelte "Wörterbuchnetz" (http://www.woerterbuchnetz.de) verfolgte ursprünglich anscheinend ähnliche Ziele wie das hier beantragte Projekt LexiCon (vgl. http://woerterbuchnetz.de/hinweise). Bis heute präsentiert es sich jedoch de facto als eine Art Meta-Suchmaschine für eine Anzahl von lexikalischen online-Ressourcen hauptsächlich aus dem Bereich der Germanistik. Augenscheinlich fehlt dem System die klare Trennung zwischen onomasiologischer und semasiologischer Perspektive. Die Suchmaske bietet jedenfalls keine entsprechende Differenzierung an, und auch die Suchergebnisse liefern keine entsprechend kategorisierten Ergebnisse. Desweiteren existiert anscheinend keine Bündelung kongruenter Einträge in den verschiedenen Wörterbüchern zu morpholexikalischen Typen, wie sie für den vorliegenden Antrag essentiell sind. Darauf deuten die verschiedenen IDs hin, die in den im Wörterbuchnetz verwendeten URLs auftauchen. So ist z.B. der Eintrag Milch im Mittelhochdeutschen Wörterbuch (Benecke 1866) mit der "lemid" BM01258 hinterlegt (http://www.woerterbuchnetz.de/cgi-bin/WBNetz/wbgui_py?sigle=BMZ&lemid=BM01258), der Eintrag Milch im Grammatisch-Kritischen Wörterbuch der Hochdeutschen Mundart (Adelung 1793) hingegen mit der "lemid" DM01390 (http://www.woerterbuchnetz.de/cgi-bin/WBNetz/wbgui_py?sigle=Adelung&lemid=DM01390). Ob das System im Hintergrund auf eine gemeinsame Referenz-ID mappt, ist auf diese Weise freilich nicht feststellbar. Die hier vorgestellte LexiCon-Initiative wird vom Trierer Wörterbuchnetz ausdrücklich unterstützt.
Unter der mangelnden klaren Unterscheidung zwischen Bezeichnungen einer- und Konzepten andererseits leidet letztlich auch das DWDS, das überdies auf die deutsche Sprache begrenzt ist. Möglich ist hier lediglich eine semasiologische Suche, der Einsatz von persistenten Identifikatoren im Sinne von Normdaten ist zumindest an der Oberfläche nicht erkennbar. In welche Richtung sich das jüngst (Anfang 2019) unter dem Dach der Akademienunion ins Leben gerufene, vom BMBF finanzierte und von der Berlin-Brandenburgische Akademie der Wissenschaften (BBAW) getragene "Zentrum für digitale Lexikographie der deutschen Sprache" (https://www.zentrum-lexikographie.de/), das auf dem DWDS aufbaut, entwickeln wird, ist zumindest in den Details derzeit noch nicht erkennbar. Die sehr allgemein gehaltene Selbstdarstellung des ZDL (https://www.zentrum-lexikographie.de/ueber-das-zdl.html) vermittelt nicht den Eindruck, dass das Vorhaben die genannten Beschränkungen, die dem patestehenden DWDS anhaften, durch eine substantielle konzeptionelle Neuausrichtung überwunden werden sollen. Selbst innerhalb der Akademienunion wird das Vorhaben jedenfalls bisweilen kritisch gesehen (s. z. B. Arnold 2019).
Im Unterschied dazu wird der durch LexiCon erfasste einzelsprachliche Wortbestand substantiell angereichert, da er auf ein sprachunabhängiges Normdatenvokabular gemappt wird; so operiert der Dienst konsequent auf zwei Ebenen, einer semasiologischen Ebene von Bezeichnungen und einer onomasiologischen Ebene von KONZEPTEN.
Auch die geplante Implementierung von KONZEPT-Bezeichnungs-Relationen ist nicht ganz neu, denn sie werden bereits durch Online-Anwendungen unterstützt, z.B. durch den von WordNet (vgl. Fellbaum 2010) inspirierten, umfassenden und vielsprachigen Online-Thesaurus BabelNet (vgl.Navigli). BabelNet profitiert u.a. von der stetig wachsenden Informationsfülle auf Wikidata: Durch eine Verknüpfung der BabelNet-IDs mit den korrespondierenden QIDs lassen sich die in RDF Tripeln organisierten Wikidata-Informationen in den BabelNet-Kosmos integrieren. Abhängig vom Wissensbereich stehen auf diese Weise mitunter recht umfangreiche, streng konventionalisierte taxonomische Hierarchien zur Verfügung, wie sich an deu. Lattich exemplarisch zeigen lässt:
| referenziertes KONZEPT (Wikidata QID) | Taxonomischer Status (=) und hierarchische Relationen (⊂, ⊃) | verknüpftes KONZEPT ; Wikidata QID |
| (i) Gruppe (Klade) ⊃ (i)-(vi) | ASTERIDEN/EUASTERIDEN II; Q747502 | |
| (ii) Ordnung ⊂ (i) | ASTERNARTIGE ; Q21730 | |
| (iii) Familie ⊂ (ii) | KORBBLÜTLER ; Q25400 | |
| (iv) Unterfamilie⊂ (iii) |
CICHORIOIDEAE ; Q133142 |
|
| LATTICH, (Linné: LACTUCA ; Q578052) | = (v) Gattung ⊂ (iv), ⊃ (vi) | |
| (vi) Arten (...) | nn ; Q... |
Die KONZEPTe, d.h. die ontologischen Items in Gestalt der Wikidata-IDs sind also nicht nur mit Bezeichnungen sondern auch untereinander verknüpft, wenngleich die bestehenden Relationen in den allermeisten Bereichen ergänzungs- und revisionsbedürftig sind. Äquivalente Inter-Bezeichnungs-Relationen, d.h. Beziehungen zwischen verschiedenen Bezeichnungen, sind jedoch nicht vorgesehen und auch darüber hinaus nicht allgemein etabliert; sie wären jedoch im Sinne der lexikographischen Tradition und der damit verbundenen Disziplinen unbedingt sinnvoll. Immerhin kennt das Lexicon Model for Ontologies (LEMON; vgl. Cimiano u.a. 2016), eine etablierte Ontologie zur Repräsentation komplexer lexikalischer Ressourcen, die Relation 'etymologicalRoot', die allerdings unzureichend ist, denn es muss zwischen Etyma im Sinne älterer Vorläufer und Etyma im Sinn der Entlehnung aus einer anderen Sprache unterschieden werden. So ist lat. lactuca zwar Etymon von ita. lattuga [llatːˈuga]2, frz. laitue [lɛtˈy] usw. auf der einen Seite und von deu. Lattich, engl. lettuce usw. auf der anderen Seite, aber im Fall der beiden germanischen Ausdrücke ist zudem eine Entlehnung im Spiel. Die beiden romanischen Formen zeigen ferner, dass sich aus identischen Vorläufern an unterschiedlichen Orten sehr unterschiedliche Formen entwickeln. Für die Nutzeroberfläche ergibt sich hieraus die Anforderung, die Unterscheidung in Vorläufer und Entlehnung, beispielsweise durch eine gezielte Facettierung von Kognaten (‘Ergebnisse mit gemeinsamen Etymon aus nahverwandten Sprachen’), zu unterstützen.
Zusammenfassend sind für das Projekt LexiCon drei verschiedene Beziehungstypen vorgesehen:
- Beziehungen zwischen Bezeichnungen und Konzepten
- Beziehungen zwischen Konzepten
- Beziehungen zwischen Bezeichnungen
Letztere lassen sich noch weiter untergliedern:
| elementare sprachhistorische Relationen | ||
| (1) | Vorläufer | Etymon |
| (2) | Entlehnung | |
Schematisch stellt sich das Beziehungsgefüge von LexiCon wie folgt dar:
| ↓ ontolog. Relationen ↑ |
KONZEPT 1 | → | Bezeichnung 1 | ↓ sprachgesch. Relationen ↑ |
| (evtll. → | Bezeichnung 2, 3 usw.) | |||
| KONZEPT n | ← | Bezeichnung n | ||
| (KONZEPT o, p usw. | ← evtll.) |
3. Praktische Umsetzung
3.1. Standardsprachliches Fundament: Latein ~ Romanisch
Die geplante Plattform soll ausgehend von den Romanischen Sprachen mit einem besonderen Fokus auf dem Italienischen entwickelt werden. Dabei dient der Wortbestand des REW als Kern; dort werden romanische Entwicklungen mit ihren meist lateinischen Etyma verknüpft. Dieses Standardwerk der Romanistik lemmatisiert nach (ganz überwiegend lateinischen) Etyma, denen jeweils die Entsprechungen der romanischen Standardsprachen sowie im Rahmen der damaligen Verfügbarkeit mehr oder weniger zahlreiche dialektale Kognaten zugeordnet werden; das Wörterbuch wird derzeit im Rahmen einer linguistischen Dissertation (von Florian Zacherl) in ein strukturiertes und tiefenerschlossenes lexikographisches Korpus überführt; dabei erhält jede im Artikel erfasste Bezeichnung eine ID. Zwischen den per ID erfassten Belegen des REW bestehen genau die drei oben herausgestellten lexikographischen Relationen; sie können durch Verknüpfung mit verfügbaren anderen IDs desselben Worts inhaltlich in einem offenen System auch über das Romanische hinaus quasi unbegrenzt erweitert und inhaltlich präzisiert werden, wie die folgende, ganz unvollständige Auswahl am Beispiel von REW 4833 andeutet:
| lat. lactūca → ID Georges | ||
| engl. lettuce ?→ ID OEtD, ID_LEO |  [...] lat. lactūca REW; ID lat. Bez. = 4833 [...] lat. lactūca REW; ID lat. Bez. = 4833 |
ahd. lat(t)uh(ha), lat(t)ih(ha) → ID AWD |
| ita. lattuga → ID LEO ID TLIO |
fra. laitue → ID LEO, ID TLFI |
rum. laptucă → ID DEX online |
| Vorläufer: grün ~ gelb | Entlehnung: grün ~ rosa3 | ||
Die zwei elementaren Relationen sowie die Verwandtschaftsbeziehungen können weitgehend aus der Anlage des (REW) extrahiert und Paaren von Bezeichnungen zugeordnet werden. Zwischen dem nummerierten Stichwort des REW-Artikels (hier: 4833 lactūca) und den im Artikel genannten Bezeichnungen besteht grundsätzlich die Relation ‘Etymon’; da die zugehörige Sprache jeder Bezeichnung explizit genannt wird (gelegentlich in Gestalt eines Orts), können die romanischen Bezeichnungen automatisch von nicht-romanischen Bezeichnungen getrennt werden; zwischen lat. Stichwörtern (die natürlich immer auch Bezeichnungen sind) und romanischen Bezeichnungen ergibt sich die Relation ‘Vorläufer’. In allen anderen Fällen, d.h. zwischen nicht-romanischen Stichwörtern und romanischen Bezeichnungen im Verlauf des Artikels oder zwischen lat. Stichwörtern und nicht-romanischen Bezeichnungen, die in den Artikeln auch immer wieder genannt werden (wenngleich nicht im zitierten Beispiel) liegt dagegen die Relation Entlehnung vor. (Zudem wird die Entlehnung aus einer romanischen in eine andere romanische Sprache in dieser Quelle systematisch durch den Pfeil > markiert; dieser Fall ist im zitierten Beispiel ebenfalls nicht belegt). Das REW kann deshalb als start up eingesetzt werden und bei der Integration der synchronen und diachronen Perspektive eine wichtige Scharnierfunktion übernehmen.
3.2. Exemplarische dialektale Vertiefung: Italienisch ~ Sizilianisch
Italien und das Italoromanische im weitesten Sinn, d.h. einschließlich der soziologisch als eigenständige Sprachen geführten Ausprägungen des Romanischen im Alpenraum (so genanntes Rätoromanisch), spielen dabei aus dreifachem Grund eine zentrale Rolle. Es gibt:
- nicht abgeschlossene diachronische Wörterbuchprojekte, die mitten in ihrem Entstehen in eine digitale Existenform überführt werden (so der LEI und der DRG);
- ein großes, korpusbasiertes Lexikon des älteren Italienischen, das originär als Online-Dienst entwickelt wurde und noch weitergeführt wird (TLIO);
- neue Dialekt- und Kleinsprachenwörterbücher (vgl. zum Ladinischen Mischì 2001, Mischí 2002, Forni 2013 und Moling 2016 sowie die unten genannten Arbeiten zum Sizilianischen);
- ‘klassische’ Dialektwörterbücher des 19. Jahrhunderts, die mittlerweile im Internet Archive verfügbar (so Boerio 1829, Cherubini 1814, di Sant'Albino 1859, Pasqualino 1785-1789a u.a.), aber nur mit einigem, auch manuellem Aufwand nachgenutzt werden können.
Die genannten lexikographischen Dienste lexvo, BabelNet u.a., die primär Online-Quellen rezipieren, blenden die Dialekte weitestgehend aus - zumindest werden selbst die repräsentativen Dialektwörterbücher nicht als Quellen angeführt. Aus Sicht der Fächer sind jedoch die Dialekte fundamental, da sie älter als die Standardsprachen sind und ein historisch weitaus komplexeres und differenziertes Bild zeigen; die Einbeziehung der Dialektlexikographie ist sprachökologisch ein wichtiges Anliegen.
Das Projekt stellt auf Grund von bestehenden und seit etlichen Jahren gut bewährten Forschungskontakten zunächst Sizilien in den Vordergrund und startet mit ganz neuen Dialektwörterbüchern, die zwar im Druck erschienen sind (und dafür auch konzipiert wurden), die jedoch in digitaler Weise hergestellt wurden, so dass von den Autoren Kopien für die Web-Veröfentlichung zur Verfügung gestellt werden können (Sottile 2002, Foti 2015, Sottile/Genchi 2010 und Raccuglia 2003); es will jedoch zumindest exemplarisch zwei bislang gar nicht (VS) oder nur unzulänglich (Boerio 1829) digitalisierte Lexika hinzunehmen.
Der gesamte Wortschatz, die dialektalen Stichwörter wie ihre italienischen Äquivalente, werden mit IDs versehen. Sie bilden gewissermaßen die Anker für die aus der Tiefenerschließung des REW gewonnenen Beziehungsinformationen, die Kernbereiche des lateinischen und romanischen Wortschatzes miteinander verbinden.
Selbstverständlich ergeben sich sehr konstruktive Anschlussmöglichkeiten zu anderen auch nichtromanischen Wörterbüchern, wie z.B. dem AWB, so dass sich die zahlreichen lateinischen und romanischen Entlehnungen im Althochdeutschen im systematischen Abgleich mit den romanischen Sprachen beurteilen lassen; für das Verständnis und die Rekonstruktion der Entlehnungswege ist dieser Kontext ja fundamental.
Wichtige Vorarbeiten zur webbasierten Verknüpfung lexikographischer Ressourcen aus unterschiedlichen Sprachen und Dialekten mehrerer Sprachfamilien sowie zu deren Visualisierung wurden im Projekt Verba Alpina geleistet.
Auch wenn LexiCon sich als universales System versteht, das grundsätzlich dafür ausgelegt ist, sämtliche Weltsprachen zu erfassen, muss aus naheliegenden Gründen zunächst eine Beschränkung auf einen Teilbereich erfolgen. Ausgehend von den fachlichen Kompetenzen der Antragsteller wurden dafür die romanischen Sprachen inklusive Latein sowie das Deutsche bzw. einige seiner Dialekte ausgewählt. Mit Ende des Projekts soll ein die Wörterbücher der genannten Sprachen einigermaßen vollständig aufschließendes Portal bzw. ein entsprechender Dienst entstanden sein, der anschließend unter Einsatz der im Projekt entwickelten Konzepte und Methoden um beliebige weitere Sprachen bzw. Sprachfamilien erweitert bzw. mit diesen verknüpft werden kann.
4. Innovationspotential
Das besondere Innovationspotential des Projekts besteht darin, der Lexikographie einen webbasierten, integrativen und kontinuierlich erweiterbaren Horizont zu eröffnen, der verlagsunabhängig sein wird, aber kommerziellen Online-Diensten, wie (LEO), durchaus die Möglichkeit zur Kooperation anbieten kann. Vor allem wird jedoch durch die originäre Anbindung an die auf Dauer gestellte und bestens vernetzte UB der LMU maximale Nachhaltigkeit (vgl. Krefeld/Lücke 2017a) in Aussicht gestellt.
Gewisse Einschränkungen bereits bestehender und vordergründig vergleichbarer Dienste wie etwa Lexvo oder BabelNet sind bereits erwähnt worden (erinnert sei an die weitgehende Ausblendung von Dialektmaterial). Anders als z. B. die genannten Dienste wird LexiCon auch die z. T. sehr detaillierten sprachwissenschaftlichen, insbesondere auch sprachhistorischen Informationen, die nicht selten in Wörterbuchartikeln enthalten sind, in strukturierter Form aufschlüsseln, elektronisch im Netz verfügbar und somit interoperabel machen, womit zugleich eines der zentralen im Akronym FAIR zusammengefassten Postulate erfüllt wird.
Aus computerlinguistischer Sicht erscheint den Antragstellern die automatisch-algorithmische Strukturierung semi-strukturierten Sprachmaterials, wie es gerade in gedruckten Wörterbüchern vorliegt, als eine bislang noch nicht in Angriff genommene Herausforderung, für die ein ausgewiesener computerlinguistischer Spezialist mit erheblicher Erfahrung unentbehrlich erscheint. Bisherige Lösungsansätze für dieses spezielle Problem sind kaum vorhanden. Die sogenannte Named Entity Recognition beschäftigt sich zwar mit der Klassifizierung bestimmter Abschnitte eines Textes, berücksichtigt aber die Gesamtstruktur des Textes tendenziell nicht. Umgekehrt beschäftigt sich die Forschung zur Analyse von natürlichsprachlichen Texten meist mit deutlich allgemeineren Problemstellungen. Der Spezialfall der Kombination eines nach mehr oder weniger festen Kriterien strukturierten Artikels mit unstrukturierten natürlichsprachigen Elementen, den ein traditionelles Wörterbuch darstellt, bedarf besonderer Methoden, insbesondere da eine möglichst vollständige (und valide) Erfassung der zugrundeliegenden Struktur für die Erkennung de zwischen den Lemmata bestehenden Beziehungen essentiell ist.
Der hohe Anforderungsgrad des für die Entwicklung der entsprechenden Algorithmen zuständigen Stelleninhabers scheint uns die Besetzung mit einem Postdoktoranden unerlässlich zu machen. Als ein für die Aufgabe geradezu idealer Kandidat bietet sich Herr Axel Wisiorek an, der in den nächsten Monaten seine Dissertation in Allgemeiner und Vergleichender Sprachwissenschaft abschließen wird (Betreuer: Prof. Wolfgang Schulze) und gleichermaßen über die nötige sprachwissenschaftliche wie auch informatische Kompetenz verfügt. Herr Wisiorek ist seit mehreren Jahren Mitarbeiter an der IT-Gruppe Geisteswissenschaften sowie am Centrum für Informations- und Sprachverarbeitung der LMU und hat sich bei zahlreichen Projekten jeweils bestens bewährt.
5. Datenmodellierung
Die zentralen Entitäten des Datenmodells sind die Formen und die von ihnen bezeichneten Konzepte.
‘Formen’ werden im Sinne morpholexikalisch spezifierter Typen bestimmt (damit orientiert sich LexiCon an den Vorarbeiten, die im Projekt VerbaAlpina geleistet wurden; vgl. Krefeld/Lücke 2018c). Demnach konstituieren distinkte Werte für folgende Eigenschaften eine Form:
- Schreibweise/Orthographie
- Sprach- bzw. Dialektzugehörigkeit (ergibt sich aus der Sprachzuordnung des jeweiligen Wörterbuchs)
- Wortart
- Genus
- Affigierung
Diese Eigenschaften werden nach Möglichkeit per OCR aus den Wörterbucheinträgen extrahiert und in entsprechende Felder einer Tabelle "Form" eingetragen; die von den Formen bezeichneten Konzepte werden gesondert in einer eigenen Tabelle ("Bedeutung") verwaltet. Über eine dritte Tabelle, "Einheit", geschieht die Abbildung der beschriebenen m:n-Beziehungen zwischen Formen und Konzepten (s. Abb. 1). Indem zusätzlich die Quelle der lexikalischen Informationen ("Referenzsystem") erfasst wird, wird zum einen ihre Überprüfbarkeit gewährleistet (Postulat der Quellentreue) und zum anderen der (elektronische) Rückgriff auf das Original ermöglicht.
Auch die Abbildung von etymologischen Zusammenhängen (Vorläufer oder Entlehnung) erfolgt durch Zuordnung der jeweiligen IDs in einer Verknüpfungstabelle ("Relation_Form"). Verwandtschaftsbeziehungen (auch mehrstufige) zwischen den Typen lassen sich anschließend problemfrei und zuverlässig errechnen, müssen also nicht eigens als Attribut den Datensätzen beigegeben werden. Diese algorithmische Berechnung von verwandtschaftlichen Beziehungen dürfte vielfach Zusammenhänge aufdecken, die bislang verborgen geblieben sind. Anzumerken ist, dass die in der Datenbank abgebildeten etymologischen Zusammenhänge natürlich nicht als absolute Wahrheiten angesehen werden dürfen, sondern lediglich die in den Wörterbuchquellen gegebenen Informationen abbilden. Dabei sind auch konkurrierende oder unsichere Herleitungen (mit jeweiliger Quellenangabe) möglich und im Datenmodell explizit vorgesehen.
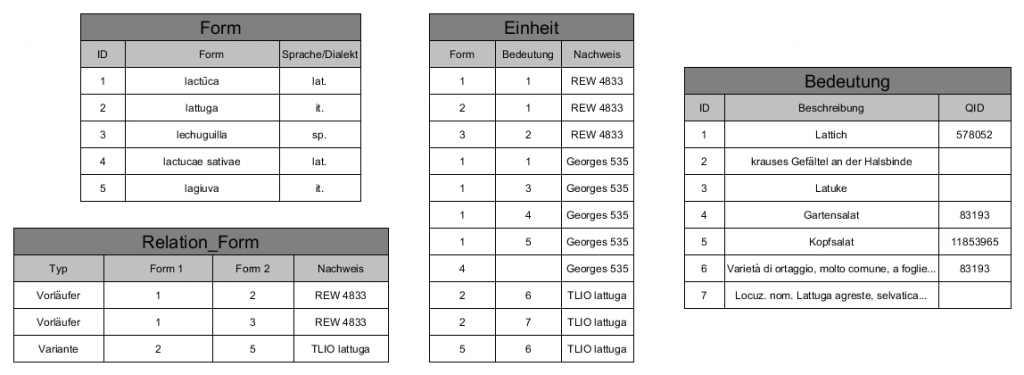
Abbildung der Beziehungen zwischen Wörterbuch-"Formen" und deren Bedeutungen sowie zwischen den Formen untereinander (Etymon-Beziehungen)
Nachfolgendes UML-Klassendiagramm illustriert die Klassen bzw. Entitätentypen sowie deren logische Zusammenhänge. Im Detail können sich während des Projektverlaufs noch Änderungen ergeben.
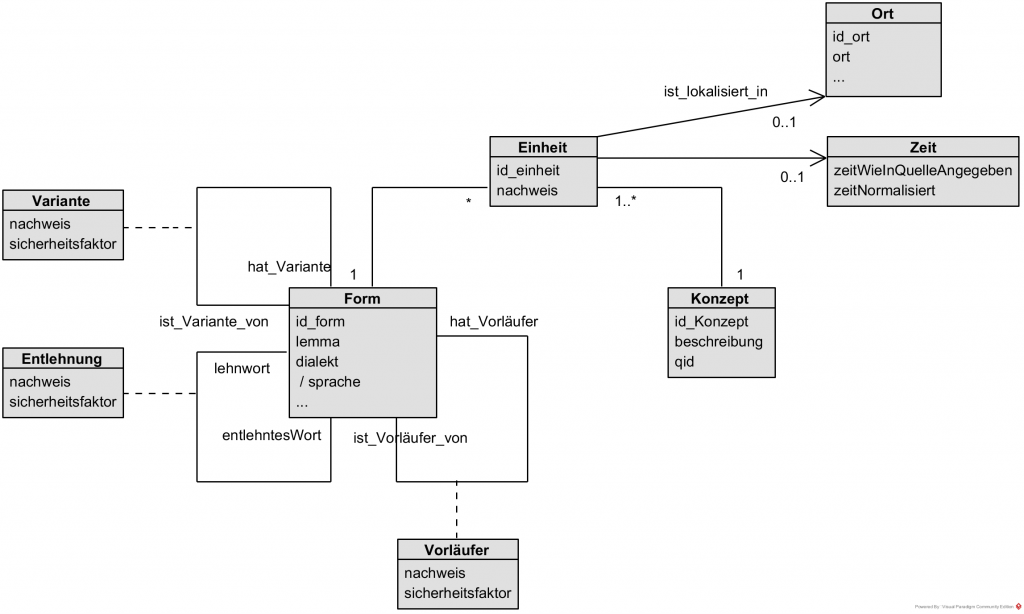
UML-Klassendiagramm
Teil der Erfassung der einzelnen Formen und Konzepte wird ihre Identifizierung sein. Dieser Prozess erfolgt im Grunde auf zwei Ebenen: Einmal auf einer Intra-Projektebene, indem identische Formen aus unterschiedlichen Wörterbüchern durch Vergabe identischer, projektspezifischer IDs miteinander verknüpft werden. Und einmal auf einer Supra-Projektebene, durch Abgleich der LexiCon-Entitäten mit dem Vokabular etablierter Normdatensysteme. Für die Entitäten vom Typ "Konzept" kommen hierfür in erster Linie Wikidata, für diejenigen vom Typ "Form" Wikidata und lexvo in Frage. Der Disambiguierungs-Vorgang soll in beiden Fällen semi-automatisch stattfinden: Zunächst in Form von String-Vergleichen und Entity Recognition (s. nächsten Abschnitt); anschließend in Form manueller Korrekturen bzw. Ergänzungen.
Linguistic Linked Open Data (LLOD)
Ziel von LexiCon ist nichts weniger als eine konsistente Reorganisation der Lexikographie im Sinne der Digital Humanities. Daher ist das Projekt von vornherein auf eine Öffnung des Datenbestands angelegt; konkret sollen die in LexiCon systematisch erfassten lexikographischen Daten in die LLOD-Cloud und allgemein in das Semantic Web integriert und damit für beliebige andere Projekte anschlussfähig und nachnutzbar werden.
Für das Datenmodell von LexiCon bedeutet dies, dass
- die Entitäten möglichst vollständig mit globalen, persistenten URIs identifiziert werden müssen
- das Datenmodell auf eine Ontologie abgebildet werden muss, die, zusätzlich zu den Entitäten, die Entität-, Attribut- und Beziehungstypen mit URIs identifiziert.
Eine erste Recherche nach einer passenden Ontologie über https://linguistic-lod.org/llod-cloud hat ergeben, dass LEMON - wie bereits in Absatz 21 angedeutet - grundsätzlich geeignet wäre, aber nicht alle vorgesehenen Beziehungstypen unterstützt. Nach Finalisierung des LexiCon-Datenmodells müsste daher geklärt werden, ob LEMON als "Grundbaustein" einer LexiCon-Ontologie weiterhin in Frage kommt, oder es nicht doch noch eine andere Ontologie mit einer größeren Abdeckung des LexiCon-Datenmodells gibt. Sollte der UseCase von LexiCon in keiner bereits etablierten Ontologie zufriedenstellend repräsentiert sein, würde im Rahmen des Projekts eine eigene, LexiCon-spezifische Ontologie entwickelt werden; deren Interoperabilität würde jedoch durch Ontology Alignment sichergestellt werden.
Die Identifizierung der Entitäten, speziell der Abgleich mit bestehenden Normdatenvokabularen, ist, neben der Extraktion der einzelnen Informationseinheiten aus den Wörterbuchartikeln, eine der größten Herausforderungen des Projekts.
Für die beiden zentralen Entitätentypen Form und Konzept soll das Vorgehen kurz skizziert werden: Nachdem die Formen aus den Wörterbuchartikeln gefiltert und auf Grundlage des Projektdatenbestands disambiguiert wurden, ist der nächste Schritt ein Abgleich der sprachlich-spezifizierten Form mit der lexvo-Knowledge-base über die Java API von lexvo. Ist die Form bereits in lexvo nachgewiesen, wird die zugehörige lexvo-URI als Attribut in den LexiCon-Datenbestand übernommen. Andernfalls wird über die API eine neue lexvo-URI generiert und ebenfalls in LexiCon integriert. Durch die lexvo-URI ist die Form global eindeutig identifiziert. Wünschenswert wäre aber darüber hinaus ein Anschluss an den stetig im Wachsen begriffenen "Normdatenhub" Wikidata, im besten Fall über eine wechselseitige Verlinkung. Hierzu bedarf es wiederum eines Abgleichs der durch lexvo identifizierten Form mit den durch L-IDs identifizierten Lexemen von Wikidata. Gibt es eine Übereinstimmung, wird diese durch Referenzen auf den jeweils anderen Datenbestand sowohl in LexiCon als auch in Wikidata formalisiert. Schlägt der Abgleich fehl, wird die Form samt Referenz auf LexiCon in Wikidata nachgetragen, sofern dies zur Projektlaufzeit automatisiert, z.B. in Form eines batch-Imports, möglich ist 4.
Im Unterschied zur globalen Identifizierung der Form-Entitäten, gibt es für die Konzept-Entitäten keine "einfache" lexvo-API-Lösung. Um die aus den Wörterbuch-Artikeln generierten Konzepte mit globalen URIs auszustatten, ist ein Abgleich mit Wikidata (Q-IDs) und/oder der GND unerlässlich. Dieser gestaltet sich jedoch um einiges schwieriger als der Abgleich von Formen, müssen doch bei den Konzepten unterschiedliche Ansetzungen ein und desselben (per se gedanklichen) Konzepts berücksichtigt werden. Um dies zu bewerkstelligen, ist ein reiner Stringvergleich in vielen Fällen nicht zielführend. - Für die Zusammenführung von Synonymen, das Auseinanderhalten von Homonymen, Stemming usw. müssen vielmehr Machine-Learning-Verfahren angewendet werden. Voraussetzung für den Einsatz solcher Verfahren ist die Generierung eines Sets an qualitativ hochwertigen Trainingsdaten, anhand derer der Entitiy-Recognition-Algorithmus trainiert werden kann. Solche Datensätze sind bisher nicht, oder zumindest nicht in ausreichend großer Zahl vorhanden, weswegen die im Rahmen des Projekts - gewissermaßen nur als Mittel zum Zweck - zu erstellenden Trainingsdaten als eigenständiges Projektergebnis angesehen werden können. Als solches würden sie der Community am Ende des Projekts zur Verfügung gestellt werden.
Im Hinblick auf die Integration der LexiCon-Daten in die LLOD-Cloud bzw. das Semantic Web werden ein SPARQL-Endpoint implementiert und die Daten als RDF triple über diesen bereitgestellt.
6. Nachhaltigkeitskonzept
Die von LexiCon gesammelten und strukturierten Daten, sämtliche im Rahmen des Projekts entwickelten Software-Konzepte und -Realisierungen (Programmcode) sowie alles entstandene Know-How werden getreu den im Akronym "FAIR" (Lücke 2018b) versammelten Prinzipien verwaltet und am Ende des Projekts veröffentlicht. Ein ganz wesentlicher Faktor in diesem Zusammenhang stellt die Ansiedlung des Projekts an den beiden auf Dauer an der LMU eingerichteten Institutionen der Universitätsbibliothek (UB) und der IT-Gruppe Geisteswissenschaften (ITG) dar. Die genannten Einrichtungen haben in den letzten Jahren ihre Kooperation weiter ausgebaut und verstärkt. Gemeinsam bilden sie nun ein Kompetenz- und Datenzentrum, das sich als Dienstleister im Bereich nachhaltiges Management von Forschungsdaten für die geisteswissenschaftlichen Fakultäten an der LMU versteht. UB und ITG sind überdies aktuell am vom Bayerischen Staatsministerium für Wissenschaft und Kunst geförderte Projekt eHumanities – interdisziplinär beteiligt, in dessen Fokus ebenfalls die Herausforderungen des nachhaltigen Forschungsdatenmanagements stehen.
Im Hinblick auf weitere Details zur Rolle der ITG als DH Kompetenz- und Datenzentrum sei an dieser Stelle auf den einschlägigen generischen Text der ITG verwiesen, der als Anhang diesem Antrag beigegeben ist (Download).
7. Vorarbeiten
Die Initiative zur Konzeption des Projekts ergab sich mit einer gewissen Selbstverständlichkeit aus mehreren an der LMU angesiedelten Forschungsprojekten:
- Das DFG-Langfristvorhaben (Verba Alpina) stützt sich bei der Präsentation der Sprachdaten auf eine Reihe von Referenzlexika (vgl. die interaktiven Siglen T, C, L, F in diesem zufällig gewählten Beispiel); die Aufnahme der jeweiligen Verweise erwies sich als außerordentlich aufwändig, da sie weitestgehend manuell vorgenommen werden musste; selbst die Wörterbücher, die bereits im Internet aufrufbar sind, erweisen sich in ihrer Funktionalität oft als unzulänglich und - vor allem - vollkommen isolierte Einzelwerke; die Notwendigkeit einer Koordination und Verflechtung ist evident.
- Die technische Machbarkeit und das erhebliche lexikologische Potential einer digitalen Tiefenerschließung klassischer Wörterbücher wird aktuell am Beispiel der Aufbereitung des REW (vgl. Zacherl in Vorbereitung) durch Florian Zacherl im Rahmen seiner einschlägigen DH-Dissertation (Zacherl in Vorbereitung; Betreuer: Prof. Thomas Krefeld) offenkundig.
- Die UB der LMU hat ihre Aufgabe bei der Institutionalisierung des Forschungsdatenmanagements erkannt und entwickelt im Modellprojekt „eHumanities – interdisziplinär“ gemeinsam mit der UB der FAU Erlangen und der ITG Prozeduren der Standardisierung, speziell für die Anreicherung von Forschungsdaten mit Metadaten, die eine wichtige Voraussetzung des projektierten lexikographischen Dienstes bilden und sich hier gleichzeitig in der Praxis bewähren könnten.
- Im ersten Halbjahr 2019 wurde bereits die elektronische Version des renommierten lateinischen Wörterbuchs "Georges" (Karl Ernst Georges (1913), Ausführliches lateinisch-deutsches Handwörterbuch [http://www.zeno.org/Georges-1913]) in der generischen partiell vorstrukturierten Form in das von der IT-Gruppe Geisteswissenschaft betriebene MySQL-Datenbankmanagementsystem übertragen.
- Im Rahmen des ebenfalls lexikalisch ausgerichteten Projekts VerbaAlpina wird bereits seit dem Jahr 2014 eine intensive Methodenreflexion betrieben, die sich neben den auch für LexiCon zentralen lexikographischen Aspekten auch mit den Herausforderungen rein digitaler Arbeitsweisen auseinandersetzt. Für eine ganze Reihe von Fragen und Problemen, die grundsätzlich auch für LexiCon Relevanz besitzen, konnten dort bereits tragfähige Konzepte und Lösungen entwickelt werden, auf die LexiCon zurückgreifen kann.
- U. a. im Bereich der Informationsvisualisierung wurden im Rahmen von VerbaAlpina z.T. komplexe Softwarelösungen entwickelt, auf die von LexiCon zurückgegriffen werden kann.
- Die IT-Gruppe Geisteswissenschaften verfügt seit Jahrzehnten über zwischenzeitlich umfangreiche Erfahrung bei der Erzeugung, Verwaltung und Analyse von Sprachmaterial in relationalen Datenbanken.
- Als hilfreich dürfte sich auch die Expertise erweisen, die an der ITG durch ihre engen Kontakte mit dem Centrum für Informations- und Sprachverarbeitung der LMU (CIS) vorhanden sind. Einer der Mitarbeiter der ITG, Tobias Englmeier, ist Doktorand von Prof. Klaus Schulz, der sich in den letzten Jahren einen sehr guten Ruf auf dem Gebiet des OCR erworben hat (s. https://www.cis.uni-muenchen.de/dighum/cisocrgroup/index.html).
8. Arbeitsplan
Es ist beabsichtigt, die Inhalte aus folgenden Wörterbüchern bzw. lexikographischen Ressourcen in der gegebenen Reihenfolge nach den oben genannten Prinzipien strukturiert zu erfassen:
- REW (Prototyp)
- Georges 1913 [1998]
- LEO (romanische Sprachen, Deutsch, Englisch)
- LEI
- TLIO
- TLFi
- FEW en ligne
- DOM
- VS
- Sottile 2002
- Sottile/Genchi 2010
- Foti 2015
- Raccuglia 2003
- Boerio 1829
- Cherubini 1814
- Trovato/Lanaia 2011
- AWB
- Pirona 1871
- Schmeller 1872
- Idiotikon 1881
- Pirona i.a. 1935
9. Internationale Kooperationen
Der Erfolg des angepeilten Vorhabens kann durch die Beteiligung möglichst vieler Kooperationspartner aus dem Bereich der Lexikographie nicht unwesentlich gesteigert werden. Vor diesem Hintergrund kommt der Nutzung bestehender und der Schaffung neuer einschlägiger Kontakte mit dem Ziel der Etablierung eines sowohl aus Personen wie auch deren Daten bestehenden Netzwerks eine besondere Bedeutung zu. Bereits im Rahmen der vorbereitenden Tätigkeiten wird LexiCon daher entsprechend propagiert. Formal dient diesem Zweck eine schriftliche Absichtserklärung (Download der deutschen Version: docx, pdf), die von geeigneten Institutionen bzw. deren Vertretern unterzeichnet werden soll. Wesentlicher Bestandteil dieser Absichtserklärung ist das Bekenntnis zum Ideal des Open Access sowie der Einhaltung der sog. FAIR-Prinzipien (vgl. Lücke 2018b).
Ernsthaftes Interesse an der in der Arbeit an VerbaAlpina entwickelten und für das hier beantragte Vorhaben zentralen Idee der Vergabe von Normdaten für morpholexikalische Typen wurde in Gesprächen von Seiten der GND-(Verbund)-Redaktion signalisiert. Entsprechende Kontakte bestanden bislang zu Frau Eva-Maria Gulder und Werner Holbach (beide Bayerische Staatsbibliothek) sowie Jürgen Kett (Leiter der Arbeitsstelle für Standardisierung an der Deutschen Nationalbibliothek). Als wünschenswertes Szenario erschien den Gesprächsteilnehmern eine wechselseitige Verlinkung der beiden Datenbestände - GND und LexiCon - auf Ebene der Konzepte. Hierdurch könnte zum einen das bisher weitestgehend sprachunabhängige, semantische Netz der GND um die sprach(wissenschaft)liche Dimension von LexiCon erweitert werden; Zum anderen würde LexiCon durch ein Mapping der Konzept-IDs auf entsprechende GND-Schlagwort-IDs Anschluss an den "Normdaten-Hub" GND erhalten. Vertreter der GND haben dem hier beantragten Projekt die Ausstellung eines LoI fest zugesagt; zum Zeitpunkt der Antragstellung war dieser jedoch noch nicht eingegangen; er wird so bald als möglich nachgereicht.
Darüber hinaus haben die im Folgenden genannten Institutionen und Einzelpersonen durch Unterzeichnung einer entsprechenden Absichtserklärung (Letter of Intent, LoI) ihr Interesse an einer Beteiligung am Projekt LexiCon bekundet oder eine solche Bekundung angekündigt. Einige der gelisteten Institutionen repräsentieren aus der Perspektive des vorliegenden Antrags inhaltlich insofern periphere Bereiche, als sich das von ihnen verwaltete Sprachmaterial jenseits der im Mittelpunkt befindlichen romanischen Sprachfamilie liegt. Die entsprechenden Absichtsbekundungen werden hier dennoch aufgeführt, da sie das weitreichende und einzeldisziplinübergreifende Interesse an dem von LexiCon angestrebten integrativen lexikographischen Ansatz dokumentieren. Eine spätere Erweiterung des im Rahmen des vorliegenden Antrags zusammengeführten lexikalischen Materials um weitere nicht-romanische Ressourcen erscheint aufgrund des erkennbaren positiven Echos von (nicht nur Sprach-) Wissenschaftlern außerhalb der Romanischen Philologie als eine naheliegende Option.
| Sprache (ISO 639-3-Codes) |
Institution/Projekt | Kooperation |
| lat | Karl Ernst Georges (1913), Ausführliches lateinisch-deutsches Handwörterbuch (http://www.zeno.org/Georges-1913), vorstrukturierter Datenbestand |
dump und Nutzungsgenehmigung |
| por, spa, fra, ita, ron (Romanische Sprachen) | Meyer-Lübke, Wilhelm (1935): Romanisches etymologisches Wörterbuch (REW), 3., vollst. neubearb. Aufl., Heidelberg, Winter; digitale Tiefnerschließung in Arbeit | gemeinfrei |
| deu, eng, fra, ita, por, spa5 | LEO | LoI |
| deu | Althochdeutsches Wörterbuch (AWB) | CC BY-NC-ND |
| woerterbuchnetz.de |
LoI angekünd. | |
| fra | CNRS Analyse et traitment informatique de la langue française (atilf); Lexikographische Referenzwerke, teils vollständig digitalisiert : - Trésor de la de la langue Française informatisé (TLFi) teils im Prozess der Retrodigitalisierung: - Französisches etymologisches Wörterbuch (FEW) |
LoI |
| ita | Tesoro della lingua italiana delle origini (TLIO), ( angefragt) | LoI angekünd. |
| Dizionario etimologico italiano (LEI) | LoI | |
| scn (Sizilianisch) | Centro di Studi filologici e linguistici siciliani; maßgebliche Print-Wörterbücher des Sizilianischen; insbesondere: - Vocabolario siciliano - mehrere lokale Wörterbücher (vgl. Bibliographie) |
LoI; Facebook-Post |
| lmo (Lombardisch) | Gabriele Iannaccaro (Uni Mailand Bicocca) für: Cherubini 1814 | LoI |
| oci (Okzitanisch) | Dictionnaire de l'occitan médiéval (DOM en ligne) | LoI |
| fur (Friaulisch) | Società filologica friulana für: Il nuovo Pirona (Pirona i.a. 1935) | LoI |
| egy (Alt-Ägyptisch) |
Ousia: Eine Online-Datenbank für die Erforschung und Erfassung ägyptischer Semiophore (Dr. Roberto A. Díaz Hernández); partielle Erfassung von:
|
LoI |
|
Gemeinsame Normdatei (GND) der Deutschen Nationalbibliothek (DNB) |
LoI (zugesagt) | |
| lij (Ligurisch) |
F. Toso, Dizionario etimologico storico genovese e ligure (DESGEL) |
LoI |
| gem |
Trierer Wörterbuchnetz (http://www.woerterbuchnetz.de/) |
LoI (zugesagt) |
| por, spa, fra, ita, ron (Romanische Sprachen) |
Fachinformationsdienst (FID) Romanistik |
LoI |
Bibliographie
- Adelung 1793 = Adelung, Johann Christoph (1793): Grammatisch-kritisches Wörterbuch der hochdeutschen Mundart: mit beständiger Vergleichung der übrigen Mundarten, besonders aber der Oberdeutschen, vol. 3, JGI Breitkopf.
- Arnold 2019 = Arnold, Eckhart (2019): Digitalisierung mit Augenmaß. Teil 1: Warum Digitale Lexikalische Systeme nicht halten, was sie versprechen, in: .dhmuc - Digital Humanities München (Link).
- AWB = Frings, Theodor (1952-2015 ff.): Althochdeutsches Wörterbuch. Auf Grund der von Elias v. Steinmeyer hinterlassenen Sammlungen, Leipzig, Sächsische Akademie der Wissenschaften (Link).
- Benecke 1866 = Benecke, Georg Friedrich (1866): Mittelhochdeutsches Wörterbuch, vol. 2, S. Hirzel.
- Boerio 1829 = Boerio, Giuseppe (1829): Dizionario del dialetto veneziano, Venezia.
- Burch/Rapp 2006 = Burch, Thomas / Rapp, Andrea (2006): Das Wörterbuch-Netz: Verfahren-Methoden-Perspektiven, in: Geschichte im Netz: Praxis, Chancen, Visionen. Beiträge der Tagung. hist, 607-627.
- Cherubini 1814 = Cherubini, Francesco (1814): Vocabolario milanese-italiano, 2 voll., Milano, Milano, Stamperia reale (Link).
- Cimiano u.a. 2016 = Cimiano, Philipp / McCrae, John P. / Buitelaar, Paul (2016): Lexicon Model for Ontologies: Final Community Group Report 10 May 2016 (Link).
- Crusca 1612 = Crusca (1612): Vocabolario degli Accademici della Crusca (Link).
- de Melo 2015 = de Melo, Gerard (2015): Lexvo.org: Language-Related Information for the Linguistic Linked Data Cloud, in: Semantic Web, vol. 6, 4, IOS Press, 393-400 (Link).
- di Sant'Albino 1859 = di Sant'Albino, Vittorio (1859): Gran dizionario piemontese, Torino, UTET (Link).
- DOM = Stempel, Wolf-Dieter (1996): Dictionnaire de l'occitan médiéval: A-Acceptar Fasc. 2. Acceptat-Adenan Fasc. 3. Adenan-Afermat Fasc. 4. Afermetat-Agreable Fasc. 5. Agrear-Airienc, Niemeyer.
- DRG = Melcher, Florian / De Planta, Robert (Hrsgg.) (1939-): Dicziunari Rumantsch Grischun, Cuoira, Società Retorumantscha (Link).
- du Cange = du Cange, Charles du Fresne: Glossarium mediae et infimae latinitatis, Niort (Link).
- DWDS = Berlin-Brandenburgischen Akademie der Wissenschaften (Hrsg.): Digitales Wörterbuch der Deutschen Sprache. Das Wortauskunftssystem zur deutschen Sprache in Geschichte und Gegenwart, Berlin-Brandenburgischen Akademie der Wissenschaften (Link).
- Fellbaum 2010 = Fellbaum, Christiane (Hrsg.) (2010): WordNet: An Electronic Lexical Database, Princeton, Princeton University (Link).
- FEW en ligne = atilf: Französisches etymologisches Wörterbuch (Link).
- Forni 2013 = Forni, Marco (Hrsg.) (2013): Dizionario italiano - ladino gardenese = Dizioner ladin de gherdëina - talian, 2013, San Martin de Tor, Istitut ladin Micurá de Rü (Link).
- Foti 2015 = Foti, Giuseppe (2015): Vocabolario del dialetto galloitalico di San Fratello, in: ArchivIA - Archivio istituzionale dell'Università di Catania, Tesi di dottorato, Area 10 - Scienze dell'antichità, filologico-letterarie e storico artistiche, Catania, Università di Catania (Link).
- Georges 1913 [1998] = Georges, Karl Ernst (1913 [1998]): Ausführliches lateinisch-deutsches Handwörterbuch, Hannover (Darmstadt) (Link).
- Idiotikon 1881 = Idiotikon, Schweizerisches (1881): Wörterbuch der schweizerdeutschen Sprache, in: Begonnen von Staub F. und Tobler L. Bearb. von Bachmann A. Bd. I—XIV. Frauenfeld.
- Jiang 2012 = Jiang, Jing (2012): Information Extraction from Text, Boston, MA, Springer US, 11-41 (Link).
- Krefeld/Lücke 2017a = Krefeld, Thomas / Lücke, Stephan (2017a): Nachhaltigkeit – aus der Sicht virtueller Forschungsumgebungen, in: Korpus im Text (Link).
- Krefeld/Lücke 2018c = Krefeld, Thomas / Lücke, Stephan (2018): Typisierung, in: Methodologie, VerbaAlpina-de 19/1 (Link).
- LEI = Pfister, Max / Schweickard, Wolfgang (1979-): Lessico etimologico italiano, Wiesbaden, Reichert.
- LEO = LEOs Wörterbücher (Link).
- Lücke 2016c = Lücke, Stephan (2016): Bezeichnung, in: Methodologie, VerbaAlpina-de 19/1 (Link).
- Lücke 2018b = Lücke, Stephan (2018): FAIR-Prinzipien, in: Methodologie, VerbaAlpina-de 18/2 (Link).
- Lücke 2018d = Lücke, Stephan (2018): Normdaten, in: Methodologie, VerbaAlpina-de 18/2 (Link).
- Lücke 2019 = Lücke, Stephan (2019): Digitalisierung, in: Methodologie, VerbaAlpina-de 19/1 (Link).
- McLuhan 1962 = McLuhan, Marshall (1962): The Gutenberg Galaxy, London.
- Mischì 2001 = Mischì, Giovanni (2001): Wörterbuch deutsch - gadertalisch = Vocabolar todësch - ladin, , San Martin de Tor (Link).
- Mischí 2002 = Mischì, Giovanni (2002): Wörterbuch : Deutsch - Grödner-Ladinisch = Vocabuler : tudësch - ladin de Gherdëina, , San Martin de Tor, Istitut Ladin Micurà de Rü (Link).
- Moling 2016 = Moling, Sara (2016): Dizionario italiano - ladino Val Badia; Dizionar ladin Val Badia - talian, San Martin de Tor, Istitut ladin Micurá de Rü (Link).
- Navigli = Navigli, Roberto (Hrsg.): BabelNet (Link).
- OEtD = OEtD: Online Etymology Dictionary (Link).
- Pasqualino 1785-1789a = Pasqualino, Michele (1785-1789(a)): Vocabolario siciliano etimologico, italiano e latino, vol. 1, Palermo, Reale Stamperia (Link).
- Pirona 1871 = Pirona, Giulio Andrea (1871): Vocabolario friulano dell’abate Jacopo Pirona, Venezia, Antonelli.
- Pirona i.a. 1935 = Pirona, Giulio Andrea / Carletti, Ettore / Corgnali, Giovanni Battista (1935): Il Nuovo Pirona. Vocabolario friulano, Udine, Bosetti.
- Raccuglia 2003 = Raccuglia, Sandra (2003): Vocabolario del dialetto galloitalico di Aidone, Palermo, Centro di studi filologici e linguistici siciliani.
- REW = Meyer-Lübke, Wilhelm (1935): Romanisches etymologisches Wörterbuch 3., vollst. neubearb. Aufl., Heidelberg, Winter (Link).
- Riethmayer/Bartel 1995- = Riethmayer, Hans / Bartel, Elmar (Hrsgg.) (1995-): LEOs Wörterbücher (Link).
- Schmeller 1872 = Schmeller, Johann Andreas (1872): Bayerisches Wörterbuch. 2 Bde. 2, in: Aufl. Stuttgart.
- Sottile 2002 = Sottile, Roberto (2002): Lessico dei pastori delle Madonie, Palermo, Centro di studi filologici e linguistici siciliani, Dipartimento di scienze filologiche e linguistiche, Università di Palermo (Link).
- Sottile/Genchi 2010 = Sottile, Roberto / Genchi, Massimo (2010): Lessico della cultura dialettale delle Madonie. 1. L'alimentazione, Palermo, Centro di studi filologici e linguistici siciliani.
- TLFi = atilf (1994): Trésor de la Langue Française informatisé, Nancy, Université de Lorraine - CNRS (Link).
- TLIO = Leonardi, Lino (2017): Tesoro della Lingua Italiana delle Origini Il primo dizionario storico dell'italiano antico che nasce direttamente in rete fondato da Pietro G. Beltrami. Data di prima pubblicazione: 15.10.1997 (Link).
- Trovato/Lanaia 2011 = Trovato, Salvator C. / Lanaia, Alfio (2011): Vocabolario-Atlante della cultura alimentare nella 'Sicilia lombarda', Palermo, Centro di studi filologici e linguistici siciliani.
- Verba Alpina = Krefeld, Thomas / Lücke, Stephan (2014-): VerbaAlpina. Der alpine Kulturraum im Spiegel seiner Mehrsprachigkeit, München (Link).
- VS = Piccitto, Giorgio / Tropea, Giovanni / Trovato, Salvatore C. (1977-2002): Vocabolario siciliano, vol. 5, Palermo, Centro di studi filologici e linguistici siciliani.
- Zacherl in Vorbereitung = Zacherl, Florian (in Vorbereitung): Digitale Tiefenerschließung traditioneller Lexikographie - am Beispiel des Romanischen Etymologischen Wörterbuchs, LMU.