Wir präsentieren hier die Abstracts der Tagungsteilnehmer, die diese im Vorfeld der Tagung als Ankündigung ihres Vortrags an VerbaAlpina übersandt hatten. Zwischenzeitlich waren diese jeweils unmittelbar den ausformulierten Beiträgen vorangestellt, nunmehr sind sie im vorliegenden Beitrag versammelt. Die Reihenfolge orientiert sich an der, in der die Vorträge auf der Tagung gehalten worden sind (s. das Programm). Nicht alle der gehaltenen Vorträge wurden später verschriftlicht und zur Veröffentlichung im vorliegenden Tagungsband übersandt. Gegebenenfalls führt der Link "Beitrag/contributo" unter der jeweiligen Überschrift eines der folgenden Abstracts zum entsprechenden Beitrag im Tagungsband. Für den Beitrag von Thomas Krefeld und Stephan Lücke war im Vorfeld der Tagung kein Abstract formuliert worden. Das Abstract des Vortrags von Roberto Sottile, der nicht auf der Tagung gehalten wurde, ist an das Ende der vorliegenden Sammlung der Abstracts gestellt.
1. Graziano Tisato: FAIRness principle implementation in the NavigAIS, AMDV and AIS Reloaded projects
Beitrag/contributo/contribution
The paper presents the methodology, the development, the results, and the FAIRness principle implementation of three related projects:
NavigAIS (2009-2017), a high resolution navigable version of the AIS, the Linguistic and Ethnographic Atlas of Italy and Southern Switzerland (Sprach- und Sachatlas Italiens und der Südschweiz) (Karl Jaberg and Jakob Jud, 1928-1940), born to allow the exploration of the 1705 maps contained in the atlas, and to digitize the text of the whole AIS, in these successive stages:
- Stand alone version https://navigais.pd.istc.cnr.it (Ch. 5.1).
- Online version https://navigais-web.pd.istc.cnr.it/, and embedded object in a HTML, PowerPoint or WordPress document as in Fig. 1a-1b (Ch. 5.4).
- OCR version, which concludes the project with the AIS database creation (Ch. 6).
AMDV – Multimedia Atlas of Veneto Dialects (2009-2015) (Ch. 7), a framework to analyze the diachronic evolution of the Italian dialects occurred in 90 years in the Veneto region (North East of Italy), by means a recording campaign in the same locations subject of the original AIS surveys, and on the same questionnaire used at that time. NavigAIS assured the real time access to the AIS maps to check on the field the speaker’s answers, and to implement the database of the AMDV 2009-2010 lemmas and the related 1921 AIS lemmas.
AISr – AIS Reloaded (2016-2019) (Ch. 6), that intends to achieve an online searchable database of the AIS lemmas, and carry out an investigation in the Swiss Canton Tessin and Grisons, to study the changes occurred in dialects in a century (http://www.rose.uzh.ch/de/forschung/forschungamrose/projekte/AIS-reloaded.html). For the creation of the database, NavigAIS has been provided with a specific supervised OCR, to acquire the AIS text in acceptable times. Half of the work (maps 1-880 of a total of 1705) has already been completed by the end of 2019, and 700,000 entries in all are now accessible and downloadable at https://www.ais-reloaded.uzh.ch.
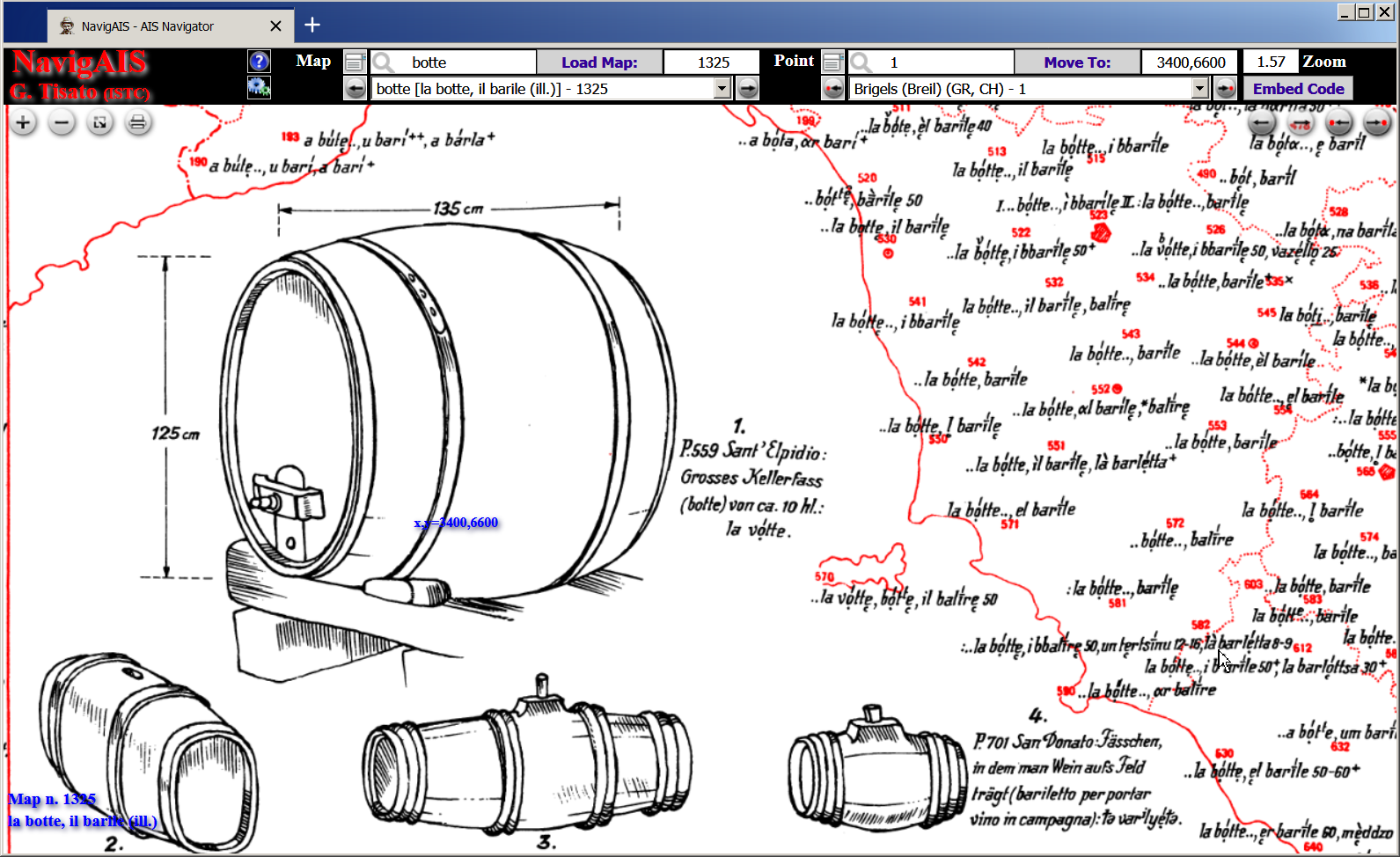
NavigAIS Online Version: https://navigais-web.pd.istc.cnr.it/?map=1325&point=570&zoom=1.65
2. Yves Scherrer: dialektkarten.ch - Interactive dialect maps for German-speaking Switzerland and other European dialect areas
Beitrag/contributo/contribution
The web site dialektkarten.ch has been online since 2014. It presents various interactive visualisations of the Swiss German dialect atlas SDS (Sprachatlas der deutschen Schweiz). Besides a set of digitized feature maps, it also provides results of dialectometric analyses as well as prototypes of machine translation and dialect identification systems for the entire German-speaking area of Switzerland. In this paper, we present three recent developments of this web site:
- The mapping backend has been changed from Google Maps to Leaflet.
- The data set has been extended with additional digitized SDS maps.
- The same interactive backend is applied to new sister projects which present interactive visualisations of French, Italian and Romansh dialect data. These sister projects are being realized in collaboration with the Salzburg dialectometry group under Prof. Hans Goebl and are based on the ALF (Atlas linguistique de la France) and AIS (Atlante linguistico ed etnografico d'Italia e della Svizzera meridionale), respectively. Taken together, the SDS, ALF and AIS dialect maps cover all four linguistic areas of Switzerland.
We will also provide an outlook on future projects.
3. Sonja Kümmet: eHumanities and VerbaAlpina
Beitrag/contributo/contribution
Als Pilotprojekt hat VerbaAlpina den Umgang des FDM-Modellprojekts eHumanities – interdisziplinär mit Forschungsdaten aus der digitalen Geolinguistik, und allgemein den Digital Humanities, grundlegend beeinflusst. Eines der Projektergebnisse, die Initiierung eines DH-Kompetenz- und Datenzentrums für das Forschungsdatenmanagement an der LMU, bestehend aus der IT-Gruppe Geisteswissenschaften und der Universitätsbibliothek, wurde maßgeblich durch die von VerbaAlpina formulierten Anforderungen ausgestaltet. Inwieweit hierbei die beiden Leitthemen der Arbeitstagung, „Vernetzung“ und „Nachhaltigkeit“, Berücksichtigung fanden, soll Gegenstand dieses Vortrags sein.
Vernetzung zielt auf Interoperabilität, d.h. darauf, dass die Daten „ausgetauscht, interpretiert und in einer (semi-)automatisierten Weise mit anderen Datensätzen von Menschen sowie Computersystemen kombiniert werden können.“ (Quelle: <https://blogs.tib.eu/wp/tib/wp-content/uploads/sites/3/2017/09/Die-FAIR-Data-Prinzipien.pdf>, S. 10, zuletzt aufgerufen am 01.04.2019) Um diesem FAIR-Kriterium zu entsprechen, bedarf es besonderer Anstrengungen bei der Erschließung der Forschungsdaten: Die Metadaten sollen möglichst präzise, vollständig sowie maschinenlesbar sein, einer gängigen Ontologie entsprechen sowie Beziehungen zu anderen (Forschungs-)Daten enthalten. VerbaAlpina hat ein recht komplexes Beziehungsgefüge. Dieses mit Metadaten abzubilden und damit auch maschinell zugänglich zu machen, war eine der größten Herausforderungen bei der „FAIRisierung“ der VerbaAlpina-Forschungsdaten. Motivation und Umsetzung sollen daher im Rahmen des Vortrags ausführlich beleuchtet werden.
Der Aspekt der Nachhaltigkeit wird v.a. im Hinblick auf Referenzierbarkeit und Auffindbarkeit betrachtet werden. Konkret sollen die Maßnahmen des DH-Datenzentrums aufgeführt werden, die darauf zielen, die VerbaAlpina-Daten langfristig verfügbar zu halten. Diese schließen die Vergabe eines persistenten Identifiers, eine die Semantik der Daten mitberücksichtigende Erschließung sowie ein Konzept zur „Langzeitarchivierung“ auf Seiten des Repositoriums-Betreibers, hier der Universitätsbibliothek der LMU, ein.
4. Hai Nguyen / Tobias Weber: Generic Research Data Infrastructure (GeRDI)
Im November 2016 gestartet, verfolgt das Projekt Generic Research Data Infrastructure (GeRDI) das Ziel, eine vernetzte Forschungsdateninfrastruktur zu entwickeln und in Deutschland aufzubauen. Dabei ermöglicht die Verknüpfung von Datenrepositorien es Wissenschaftlerinnen und Wissenschaftler disziplinübergreifend nach Forschungsdaten zu suchen und sie nachzunutzen. Unter Ausübung der FAIR (Findable, Accessible, Interoperable, Reusable) Prinzipien werden Software und Dienste für eine nachhaltige und reproduzierbare Forschung entwickelt.
Das Einbeziehen unterschiedlicher Fach-Communities im Entwicklungsprozess ist von zentraler Bedeutung für GeRDI. Neben Partnerschaften zu Projekten und Forschungsgruppen aus der Sozio-Ökonomik, der Umweltwissenschaften und Lebenswissenschaften, ist mit VerbaAlpina ein wichtiger Partner aus dem Bereich der digitalen Geolinguistik dabei. Die Anforderungen und Arbeitsabläufe für die Forschungsdaten werden aus dem Austausch mit den Fach-Communities dokumentiert und fließen in die Entwicklung der Forschungsdatenmanagement-Dienste ein.
Die Datenrecherche ist häufig das erste Vorgehen bei der Bearbeitung einer neuen Forschungsfrage, jedoch betreiben nur wenige wissenschaftliche Institutionen ein Datenrepositorium und bestehende Datenbestände sind kaum miteinander vernetzt. Mit einem Harvester werden Metadaten von existierenden Forschungsdatenspeichern in einem GeRDI Index gesammelt und durch einen Suchdienst das Auffinden von Forschungsdaten über Disziplinengrenzen hinweg ermöglicht. Um die Datenrecherche auch für andere Forschende nachhaltig bereitszustellen, können Suchergebnisse in Listen abgespeichert und frei geteilt werden.
GeRDI beschränkt sich nicht nur auf das Auffinden von Forschungsdaten. Ein wichtiger Bestandteil der GeRDI-Infrastruktur ist die Interoperabilität und Nachnutzung der Daten. Durch entwickelte Dienste für die Aufbereitung und Analyse können neue Forschungsdaten erzeugt und mit der Verknüpfung zu institutionellen Speichersystemen auch langfristig bewahrt werden. Mit der Veröffentlichung aus der GeRDI-Infrastruktur hinaus kann mit Hilfe von Provenance Metadaten die Nachvollziehbarkeit der Forschung unterstützt werden.
5. Michael Schönitzer: Wikidata und Wikibase als technische Grundlage einer vernetzten Geolinguistik
Wikidata ist eine, von den Betreibern der Wikipedia entwickelte, freie, mensch- und maschienenlesbare Wissensdatenbank, welche in den letzten Jahren quantitativ und qualitativ rasant gewachsen ist. Letztes Jahr wurde Wikidata erweitert, um lexikografische Informationen zu sammeln und zu verknüpfen. Die Inhalte von Wikidata sind für alle Arten von Forschungsprojekten frei nutzbar.
Die Identifier von Wikidata werden zunehmend von Museen, Archiven, Bibliotheken (GLAM) verwendet, um ihre Datenbestände zu verknüpfen und zu erweitern. Wikibase, die Software mit der Wikidata betrieben wird, ist frei verfügbar und kann für Forschungsprojekte als technische Plattform genutzt werden. Dank der „Federation“ der Software können unterschiedliche Wikibase Instanzen verknüpft werden und so bereits vorhandene Daten und Ontologien von Wikidata nutzen und erweitern. Diesbezüglich werde ich auf die absehbaren, zukünftigen Möglichkeiten eingehen.
In dem Vortrag werde ich skizzieren, wie Wikidata als zentrale Schnittstelle die Vernetzung von unterschiedlichen geolinguistischen Projekten ermöglicht und wie Wikibase als Plattform für Projekte eine Vereinheitlichung fördern kann, ohne die Modellierung der Informationen einzuschränken. Dadurch kann vom stetig wachsenden Ökosystem an Anwendungen und Werkzeugen rund um Wikidata und Wikibase profitiert werden.
6. Lydia Flöss: La banca dati del Dizionario toponomastico trentino e la realizzazione di carte tematiche attraverso sistemi georeferenziati
La banca-dati del Dizionario toponomastico trentino è costituita da 205.687 nomi di luogo (corrispondenti a 155.872 siti geografici) trascritti secondo regole appositamente introdotte dalla Provincia autonoma di Trento per riprodurre esattamente la corretta pronuncia dialettale dei nomi di luogo secondo le numerose varietà dei dialetti trentini. Ogni nome è georeferenziato, corredato di una descrizione del luogo cui corrisponde, delle informazioni relative agli informatori consultati e della voce del parlante che ne ha fornito la pronuncia.
Mentre un terzo dei toponimi della banca-dati è consultabile on line nel portale <www.cultura.trentino.it>, circa 50.000 toponimi sono stati pubblicati e ampiamente illustrati nei 18 volumi della collana Ricerca geografica. Essi presentano nell’ampia parte introduttiva numerose carte tematiche realizzate attraverso sistemi georeferenziati come ad esempio Arcmap.
Tali sistemi consentono infatti da qualche tempo di realizzare delle ricerche mirate all’interno della banca-dati e di ottenere significative visualizzazioni grafiche. Le ricerche possono riguardare aspetti linguistico-dialettologici legati alla distribuzione sul territorio di determinate forme dialettali che i toponimi meglio conservano rispetto alla parlata, oppure aspetti di natura etimologica relativi ad esempio a forme provenienti da altre lingue che non sono il latino; possono illustrare come alcuni luoghi hanno ricevuto nomi per la loro conformazione morfologica o paesaggistica o ancora possono contribuire a dimostrare la presenza nell’antichità di piante o di animali che hanno ispirato molti nomi di luogo che ancora sopravvivono.
7. Jesse de Does / Veronique De Tier: The Dictionary of the Southern Dutch Dialects (DSDD): a database with cartographic tools for the Southern Dutch Dialects
The project Database of the Southern Dutch Dialects (DSDD) aims to aggregate and standardize three existing comprehensive dialect lexicographic databases of the Flemish, Brabantic and Limburgian dialects into one integrated dataset. The project will result in a harmonised dataset, an API for researchers and a portal application in which the outcome of the project will be available to a broad audience.
Although the dictionaries were explicitly set up in parallel in order to make a future aggregation possible, there are differences in methodology and they have not used the same set of concepts. There is also a significant degree of heterogeneity from a technical point of view, in terms of file formats and logical structure.
The project has set up a workflow to harmonize the data structures and to interconnect the dictionaries by adding an overarching layer of concepts. The integrated database aims to enable innovative research, especially in the field of quantitative lexicology and dialect-geographical analysis.
In the near future a user-friendly website will be created with search facilities and cartographic tools. As to the cartographic tools, they should be able to automatically generate linguistic maps: an API will feed the data from the database into the mapping tool.
The DSDD project has expressed some linguistic needs with regard to cartography. Dialect maps should be highly flexible: it must be possible for researchers to customise the map according to their research needs. Researchers should be able to select and provide their own base maps with different regions (e.g. a province, …) and to use orientations such as cities and rivers as they prefer. It must also be possible to manually cluster keywords, and to add some interpretation to the dialect map. This also includes the possibility to change the legend of the map and to select the colours of the symbols.
8. Ludwig M. Breuer & Philipp Stöckle: Das WBÖ-online im 'Lexikalischen Informationssystem Österreich' - Zugriff und Vernetzungsmöglichkeiten
Beitrag/contributo/contribution
Das Wörterbuch der bairischen Mundarten in Österreich (WBÖ) ist ein Langzeitprojekt, dessen Ziel in der umfassenden Dokumentation und lexikographischen Aufarbeitung der reich gegliederten bairischen Dialekte in Österreich und Südtirol besteht. Die Datengrundlage bildet der sog. „Hauptkatalog“, eine ca. 3,6 Millionen Handzettel umfassende Sammlung von Belegen, die in der ersten Hälfte des 20. Jahrhunderts mithilfe von freiwilligen Sammlern oder auf Kundfahrten sowie durch das Exzerpieren einschlägiger Literatur erstellt wurde.
Mit der ursprünglichen Absicht, die lexikographische Arbeit zu erleichtern und das Artikelschreiben zu beschleunigen, wurden die Handzettel ab dem Buchstaben D – die Buchstaben A, B/P und C waren bereits in die Artikel der ersten vier Bände eingegangen – manuell in ein TUSTEP-System übertragen und später in mehreren Schritten (zuletzt Anfang 2019) in XML/TEI konvertiert. Insgesamt enthält die Belegdatenbank ca. 2,4 Millionen Einträge.
Seit Dezember 2016 wird das WBÖ an der Forschungsabteilung „Variation und Wandel des Deutschen in Österreich“ am Austrian Centre for Digital Humanities der ÖAW von einem neuen Team auf der Basis einer überarbeiteten Konzeption und mit modernisierter texttechnologischer Grundlage fortgeführt. Einen wesentlichen Bestandteil dieser neuen Konzeption stellt die (derzeit noch passwortgeschützte) Publikations- und Rechercheplattform „Lexikographisches Informationssystem Österreich (LIÖ)“ dar (https://lioe.dioe.at/). Auf der Plattform werden nicht nur alle neuen WBÖ-Artikel publiziert, zusätzlich erhalten NutzerInnen die Möglichkeit, Recherchen in der Belegdatenbank durchzuführen sowie ein interaktives Kartentool zu nutzen.
Die digitale Publikation der Wörterbuchartikel und die Einbindung der digitalen Belegdatenbank, die beide im TEI-Format vorliegen, eröffnen zudem weiteres Potenzial zur Vernetzung mit anderen Wörterbuchprojekten (wie etwa dem Bayerischen Wörterbuch, dem Fränkischen Wörterbuch oder dem Wörterbuch von Bayerisch-Schwaben) mit ähnlicher texttechnologischer Grundlage. Möglichkeiten für solch eine Vernetzung ergeben sich etwa auf der Ebene gemeinsamer Lemmata oder über semantische Felder, wie sie beispielsweise in der semantischen Taxonomie nach Rudolf Post beschrieben sind, die bereits von verschiedenen Wörterbuchprojekten adaptiert wurde.
9. Paolo Benedetto Mas / Lorenzo Ferrarotti: L’ALEPO: prospettive di sviluppo del trattamento informatizzato dei dati (etno-)linguistici
Beitrag/contributo/contribution
L’ALEPO (Atlante Linguistico ed Etnografico del Piemonte Occidentale) è un atlante sub-regionale dedicato ai territori del Piemonte occidentale, il cui obiettivo è raccogliere dati linguistici ed etnografici delle varietà galloromanze e galloitaliche dell’area. Dell’Atlante sono già stati pubblicati i volumi I (Il mondo vegetale) e III (Il mondo animale) ed è ormai prossima la pubblicazione del V volume (Lo spazio e il tempo). I primi due volumi sono stati pubblicati in formato cartaceo, su cui era presente una selezione di voci dell’Atlante; il resto dei materiali era contenuto in un CD-ROM allegato, interrogabile solo per alcune funzioni. La pubblicazione del V volume, invece, sarà completamente digitale e open access, sotto forma di file PDF con collegamenti ipertestuali; contestualmente, saranno aggiornati e ripubblicati con lo stesso formato elettronico l’indice dei tipi lessicali e l’indice delle forme.
Le prospettive future per la continuazione dell’Atlante impongono una profonda revisione della selezione e del trattamento dei materiali da pubblicare. Infatti, con il lavoro redazionale dei primi tre volumi si è osservato che non tutti i dati raccolti durante le inchieste possono essere opportunamente convertiti in voci strutturate rigidamente: a volte le risposte ottenute sono troppo scarse o poco rilevanti sotto il profilo linguistico ed etnografico e per l’economia generale della redazione dell’Atlante; altre volte alcuni materiali, come gli etnotesti, sono troppo complessi e articolati per essere trattati come risposte di un questionario. Inoltre, per favorire l’interoperabilità dei dati, occorrerà adeguare alcuni aspetti tecnici della pubblicazione dei materiali, sia verso l’interno (ad es. l’adozione di caratteri IPA Unicode e di modalità più agili di interrogazione del database redazionale) sia verso l’esterno (ripensamento o superamento del tipo di pubblicazione, ancora legato al formato cartaceo).
10. Jožica Škofic: Slovene Linguistic Atlas (SLA) in Connection with VerbaAlpina and Other Geolinguistic Projects
Beitrag/contributo/contribution
Slovenian Linguistic Atlas (SLA) is a long-term Slovenian dialectological and geolinguistic project established in 1934. The first two volumes were published in 2011 (SLA 1 – Man) and 2016 (SLA 2 – Farm), whereas the next volume is going to be published in 2020 (farming tasks and tools, alpine meadow, shepherd etc.). SLA 1 and SLA 2 have also been published as e-publications, i.e. in HTML format on www.fran.si (dictionary portal of the Fran Ramovš Institute of the Slovenian Language) and as pdf files on <http://sla.zrc-sazu.si/#v>.
The main goal of the new ongoing project e-SLA is to establish an interactive linguistic atlas with the database suitable for long-term preservation of data, that are useful also for other geolinguistic projects (smaller/regional as well as bigger – international and multilingual ones). One of the most important partial goals of the research is to connect geolinguistic research on the Slovenian language with research on similar topics in other languages of the Alpine region, e.g. the cooperation with the international project VerbaAlpina. The experience gained through collaboration in this international project (presentation of the material, collection of material through crowdsourcing, making connections with findings from related disciplines) will be valuable for the development of the e-SLA. The completed project, on the other hand, will enable incorporation of Slovenian dialect lexicon into this international geolinguistic project and thus enrich it.
Interoperability of research data, collected or generated by individual projects, could be gained by:
- common transcription system (national transcription systems should be translated into IPA),
- common database for long-term preservation of data accessible to all project partners who are willing to contribute their material,
- common e-maps accessible to all project partners,
- common guidelines about display of dialect data on the maps (symbols, words, lines, polygons),
- common program tools for mapping dialect material.
Practical experience and visions in dealing with these issues will be presented by the SLA map and its database for the question V455 alpine meadow (Germ. die Alm, Slov. planina), the OLA map and its database for the question F 2477 wind from the sea (Germ. borawind, Slov. burja) (see: <http://ola.zrc-sazu.si/OLB15ENG-uvod.htm>) and the ALE map and its database for the question 340 potato (Germ. Grundbirne, Erdapfel, Kartoffel, Slov. krompir) (see: <https://www.lingv.ro/index.php?option=com_content&view=article&id=81&Itemid=107>), which will be compared with the map of Slovenian dialect geographical names in the Alpine area and its database of proper names collected in the project FLU-LED (see: <http://www.flurnamen.at/en/startseite-en>).
11. Roberto Sottile: Il “Lessico dei Pastori delle Madonie” e il “Vocabolario-atlante delle pratiche venatorie in Sicilia”. Due progetti di “cartografia interattiva” e di interazione tra ALS e VerbAlpina
Beitrag/contributo/contribution
Dopo il CD-ROM sui nomi della trottola, primo esperimento di carta sonora realizzato già nel 1997, nell'ambito dell'“Atlante Linguistico della Sicilia” (???), e dopo il recupero e il riadattamento per il web dei contenuti di tale supporto (<http://atlantelinguisticodellasicilia.it/cms/home/cartasonora/>), sono in corso di lavorazione ulteriori esempi di carte interattive fruibili tramite il web, riguardanti alcuni campi semantici relativi alle attività pastorali e alle pratiche venatorie.
Quanto alla cultura pastorale, a seguito della messa a punto di un’interfaccia cartografica che riprende quella del progetto “VerbaAlpina” (ideato e diretto da Thomas Krefeld e Stephan Lücke dell’Università di Monaco di Baviera), è già possibile interrogare all’indirizzo web <https://www.als-online.gwi.uni-muenchen.de/carta/> una carta concernente le attività pastorali delle Madonie. Il relativo data base, attualmente in fase di popolamento, si fonda sul “Repertorio italiano-dialettale” del “Lessico dei pastori della Madonie” (???). Il sistema di interrogazione, organizzato per concetti e tipi lessicali, consente di proiettare su una carta digitale interattiva (OpenStreetMap) le risposte degli informatori alle domande del questionario sulla pastorizia in corrispondenza dei punti nei quali sono state svolte le inchieste. Con riferimento alla cartografazione/georeferenziazione dei lessotipi, la visualizzazione della loro trascrizione sulla carta interattiva sarà presto accompagnata dalla possibilità di ascoltare l’etnotesto all’interno del quale essi sono stati prodotti.
Riguardo alle pratiche venatorie siciliane, anche in questo caso è in corso di realizzazione un’interfaccia cartografica secondo il modello utilizzato per la pastorizia madonita, fruibile sul web. Essa consentirà la visualizzazione georeferenziata dei concetti e dei tipi lessicali sui seguenti ambiti: terreno di caccia, battuta di caccia, cacciatore, strumenti, selvaggina, cane, furetto. La carta interattiva delle pratiche venatorie si costituirà, dunque, come la controparte informatica del modulo venatorio dell’“Atlante Linguistico della Sicilia” (“Vocabolario-atlante delle pratiche venatorie in Sicilia”).