The topic of this article is the impact of VerbaAlpina on eHumanities. eHumanities is a joint project of the university libraries of Friedrich-Alexander-Universität Erlangen-Nürnberg and Ludwig-Maximilians-Universität München (UB LMU) and the IT-Group for the Humanities (ITG). The project run three years, from May 2018 to April 2021. One of the work packages shared by the UL LMU and ITG is the development and establishment of services for the management of research data. This task gave rise to the idea of setting up a data center for research data from the Digital Humanities at the LMU. The services of the data center are based on the paper "Geisteswissenschaftliche Datenzentren im deutschsprachigen Raum“ (DHd AG Datenzentren 2018b). It is a kind of framework for the cooperation between ITG and UL LMU in the field of research data management. A look at the figure below shows that the services of the data center cover the entire lifecycle of a research project – from application consulting to data storage and preservation of the data; and, if research data management is successful, the research data from one project can be the starting point for another.
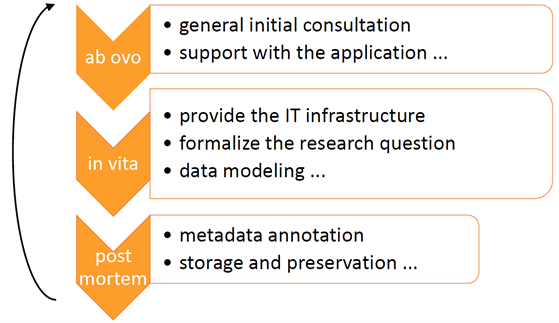
Lifecycle of a research project
Until the VerbaAlpina pilot project, however, this was only theory. It was the requirements of VerbaAlpina and the efforts of eHumanities to implement them that filled the construct with life. The following is an overview of this process, focusing on the two core topics of the VerbaAlpina workshop 2019: Interoperability and sustainability.
One of VerbaAlpina's main requirements is to be able to clearly identify and quote the individual information units. Therefore, each unit of information has been given a unique, project-specific identifier: A* stands for communities, C* for concepts, L* for morpho-lexical-types and G* or S* for instances. Each of these units is considered a distinct research data item. This means that each item gets its own PID (persistent identifier) , making it easy to cite; and each is provided with metadata, making it easier to find. The information units of VerbaAlpina are spread over three levels of description: At the top is the overall project, which includes all items. At the bottom are the instances, about 72.000, and the level in between aggregates instances into communities, concepts and ML types. The relationships between the different levels can be described with the relation types hasPart and isPartOf. For example: The concept C1 hasPart the instance G8; and vice versa: The instance G8 isPartOf the concept C1. By adding structural metadata, the implicitly existing structure can be made explicit and thus searchable.
One of the biggest challenges for the eHumanities project members was dealing with the semi-annual versioning of VerbaAlpina. Twice a year, VerbaAlpina is „frozen“ into an electronic copy and is given a version number. 18/2, for example, stands for the second version of VerbaAlpina in 2018. This practice is necessary to be able to unambiguously cite the project results already in vita and not only post mortem. To meet this challenge three things have been done: First, the version of the record has been added to the dataset ID, for example C1_v5. Second, each version of a record is treated as an independent research data item. And third, the version relationship has been made explicit – like the hasPart relation mentioned above.
VerbaAlpina wants its data to be found and reused. Therefore, the data is not locked in the repository of the UL LMU (https://discover.ub.uni-muenchen.de/help), but made available to other research data aggregators such as GeRDI, Base, or Google, via open interfaces. The reusability of the data is also supported by liberal licensing. VerbaAlpina, for example, uses the CC-BY-SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/deed.de).
1. Interoperability
One of the two main topics of the VerbaAlpina workshop was interoperability and the question of how data can be linked. Within the scope of eHumanities, this question was approached from the perspective of VerbaAlpina. The VerbaAlpina data can be interlinked with other data if …
- … a standard metadata model (= DataCite) is used for the description of the research data,
- … known relationships to other (research) data are made explicit,
- … norm data / controlled vocabulary (GND, Wikidata, GeoNames, etc.) is used,
- … the VerbaAlpina data is provided as Linked Open Data.
1.1. Standard metadata model
DataCite is well suited for describing research data because DataCite is a quasi-standard – and DataCite is generic. It is a kind of " lowest common denominator" for the description of research data from different disciplines. Thus, DataCite enables research data aggregators to make research data from the digital humanities, medicine, geosciences, etc. accessible via one common search index, which in turn allows users to perform interdisciplinary searches. For example, VerbaAlpina data can be correlated with weather data if the location information in the DataCite datasets matches. In order to describe VerbaAlpina datasets with DataCite, a conceptual mapping of VerbaAlpina.xml to DataCite.xml was made and then translated into a xslt transformation. At the same time, a working group with Tobias Weber of Leibniz Rechenzentrum (LRZ) was set up to improve the reusability of research data by “standardizing the standard”; the result, the DataCite Best Practice Guide, is now available at Zenodo
1.2. Relationships
Research data are characterized by a variety of relationships to other (research) data. The hasPart and hasVersion relations have already been mentioned in the context of VerbaAlpina, but there are many more relation types. The declaration of these relationships is a great gain in information: By explicitly indicating these relationships, the scientist gives an insight into the underlying research process, what can be seen as a step towards Open Science. In VerbaAlpina there are two main relation types: hasPart and hasVersion. These two relation types form the basic dimensions of the internal data model. The enrichment of the metadata with this structural information takes place in different stages of the ingest workflow: The hasPart relationship is defined during data transformation, the isPartOf relationship during ingest into the repository of UL LMU and the isPreviousVersionOf and isNewVersionOf relations during ingest of a subsequent VerbaAlpina version.
1.3. Norm data / Controlled Vocabulary
Controlled Vocabulary is very useful for three reasons: First, to ensure that people are talking about the same thing; if used uniformly, it ensures unambiguity. Second, norm data are anchor points through which relationships between (research) data can be identified. Third, standard data vocabularies store identifying information about an entity. Thus, users do not have to copy and store that information on their own, but can retrieve it via a reference to the entry. VerbaAlpina collects information about three entity types, communities (A*), concepts (C*) and ML types (L*). The common goal of VerbaAlpina and eHumanities is to provide all entities with norm data. Some of the concepts have already been linked to Wikidata Q-IDs, and a greater part of the communities have GeoNames IDs. Only the ML types have not been linked to a controlled vocabulary yet.
1.4. Linked Open Data
By using norm data, the things, facts and ideas that are the subject of research data can be uniquely identified. If we now also specify their type and identify the edges (= relations) with Uniform Resource Identifiers (URIs), the information can be processed directly by machines – without first having to be interpreted by humans. The integration of VerbaAlpina data into the Semantic Web would enable the derivation of new, unforeseen relationships. eHumanities distinguishes between three levels of abstraction. The most specific data model is the project-specific data model, for example the one of VerbaAlpina. This contains most of the content information. The most generic one, which abstracts most from the content, is the cross-domain data model, in the case of eHumanities, DataCite. For DataCite there is already a crosswalk from xml to rdf. However, more interesting, in terms of interlinking VerbaAlpina data with other (linguistic) data, is the domain-specific data model, which is closer to the content of VerbaAlpina. Finding or modeling a suitable ontology for VerbaAlpina is one of the major tasks of the project.
2. Sustainability
The second core topic of the VerbaAlpina workshop was sustainability. The project believes that libraries are well suited for the permanent storage of research data, as they have centuries of experience in storing and making information accessible and have access to permanent funding. This mindset also gave rise to the idea of assigning a permanent, institution-specific identifier in addition to the Digital Object Identifier (DOI). The new lmUB-ID can be seen as a kind of “fallback layer”. It reduces the dependence on the further development of the DOI, in particular its allocation practice and business model.
Another major work package for the research data management at LMU will be the preservation subject. From the author`s view, this work package can be divided into a more conceptual, metadata-focused part and a technical part.
- The challenges for the conceptual part would be:
-
-
- Describing the archived data so comprehensively that they are completely interpretable with the help of the metadata.
- Adding technical metadata such as checksums.
- Tracking (meta-)data changes.
- Adding provenance information.
-
-
- The challenges for the technical part include:
-
-
- Using the provided checksums to find out if bits have been corrupted.
- Transforming the data, if necessary.
- Making regular backups.
-
-
But that will still be a long way to go – perhaps with VerbaAlpina as a pilot project.
Bibliography
- DHd AG Datenzentren 2018b = DHd AG Datenzentren (2018): Geisteswissenschaftliche Datenzentren im deutschsprachigen Raum - Grundsatzpapier zur Sicherung der langfristigen Verfügbarkeit von Forschungsdaten (Link).
- Kümmet/Lücke/Schulz/Spenger/Weber = Kümmet, Sonja / Lücke, Stephan / Schulz, Julian / Spenger, Martin / Weber, Tobias: DataCite Best Practice Guide, 2019 (Link).