1. Saving a cultural heritage
NavigAIS Online Version embedded in this document as a fully functional application (see Fig. 1b)
The paper deals with the design (DEFAULT), the methodology (DEFAULT, DEFAULT), the development (DEFAULT) and the state of art (DEFAULT) of three projects:
- NavigAIS, the navigable version of the AIS atlas, planned as an indispensable tool to realize the two following projects (Tisato 2010) (DEFAULT).
- AIS Reloaded (AISr) and AIS the Digital Turn (AISdt), the digital talking reincarnation of the AIS, implementing the first queryable and downloadable database of all AIS data (Loporcaro/Schmid/Zanini/Pescarini/Donzelli/Negrinelli/Tisato 2021b, Loporcaro/Donzelli/Garner/Idone/Salvi/Tisato 2021) (DEFAULT).
- AMDV ("Atlante Multimediale dei Dialetti Veneti" or "Multimedia Atlas of Veneto Dialects") (Tisato/Barbierato/Ferrieri/Gentili/Vigolo 2013), the lexical, ethnographic and etymological version of the AIS for the Veneto region, conforming to modern linguistic methodologies (https://www3.pd.istc.cnr.it/amdv, DEFAULT).
The three projects share a common source of inspiration: the AIS atlas, the Linguistic and Ethnographic Atlas of Italy and Southern Switzerland ("Sprach- und Sachatlas Italiens und der Südschweiz", abbreviated in Italian "Atlante Italo-Svizzero"), created by the Swiss linguists Karl Jaberg and Jakob Jud (Fig. 2) (Jaberg/Jud 1928-1940b).

First meeting of the AIS authors in Italy (Desenzano - 8/4/1921. Publishing permission by the Paul Scheuermeier archives - University of Bern):
The linguists Karl Jaberg (left), Jakob Jud (center) and Paul Scheuermeier (right)
The projects pursue two common objectives. First of all, the declared intention to save and promote the cultural heritage of the AIS. An endangered heritage, according to Pier Paolo Pasolini, for the fate of the dialects is despite all sealed (Pasolini 1975):
The fascism tried, during all the twenty years of power, to destroy the dialects.
It could not.
Instead, the consumerism power, which says he wants to preserve the dialects, is destroying them.(trans. Graziano Tisato, Italian original: "[...] il fascismo ha tentato per tutti i vent’anni che è stato al potere di distruggere i dialetti. Non c’è riuscito. Invece il potere consumistico, che dice di voler conservare i dialetti, li sta distruggendo."
At the same time, the three projects aim to develop linguistic resources that are freely available online, in line with the concepts of open data access recently formulated as FAIR principles.
The acronym FAIR stands for Findability (Morville 2005)1, Accessibility, Interoperability and Reusability, the characteristics that certain data2 must provide to face the challenges of an interconnected world (Wilkinson u.a. 2016, Lücke 2019, Krefeld/Lücke 2019) .
What is the goal? In simple terms, let the machines do what they do best (and humans do worst), i.e. all the operations on huge amounts of data, which are programmable, repetitive, analytical, probabilistic.
But what is the need for such an approach in the linguistic field? The author got the answer from the traumatic experience made in the realization of a dialectal atlas "Il Trentino dei Contadini" (DEFAULT, Fig. 3, 4, 5) by the "Museo degli Usi e Costumi della Gente Trentina"3 (MUCGT) (Mott/Kezich/Tisato 2003).
The aim of the work was to investigate the diachronic evolution of dialects from Trentino4, to compare the lexical materials acquired in 1921-1922 by the AIS with those recorded in the same localities to the present day (1996) by the MUCGT (see the inquiry points in Fig. 3).
Although the survey was limited to only 3200 words, the completion of the atlas required 5 years. In fact, to facilitate the data readability, the MUCGT researchers decided to replace the original AIS symbolism with a simplified phonetic set, causing, unfortunately, an endless series of troubles and delays.
A lot of time was also lost, during the lemma database creation, for the very trivial difficulty to consult the AIS maps. A typical nightmare was retrieving some kind of data (lemma, string, drawing, etc.) in the 8 volumes and 1705 pages of the AIS atlas, which could take an eternity compared to a digital query.
This kind of difficulty, en passant, explains why the AIS index was completed only in 1960, 20 years after the publication of the last AIS volume in 1940 (Jaberg/Jud 1960). The index could include only the prototypical forms of the lemmas, as it is impossible to list all the lexical and morphological variants: for ex., “zisila” (swallow) has 14 variants in the 26 AIS points of the Veneto region, investigated by the AMDV project: [ϑižilα, sī́ligα, ṣẹẓila, sįẓī́a, ṣiẓī́ɫa, sįzī́ẹ, ṣiẓíla, sizī́a, ϑī́ria, tsíriẹ, tsíɫa, ϑī́riga, sī́ligẹ, ϑī́liga].
Finally, delays occurred in the various phases of the project also because of the lack of automation in data collection and processing of all the audio-visual and textual documents.
The precious experience gained from the Trentino project on its own skin (DEFAULT), and the current developments in open source and open data access concepts, allowed to design the following projects on completely new bases.
From the project "Il Trentino dei Contadini", the AMDV project (DEFAULT) has taken the idea of studying linguistic dialect variation using the AIS transcriptions as the reference touchstone, and has been inspired by the FAIR principles for an innovative approach to geolinguistic methodologies (Tisato/Barbierato/Ferrieri/Gentili/Vigolo 2013).
When in 2009 the AMDV atlas was designed, however, the FAIR principles were not fully formulated5, and not yet widely known (Wilkinson u.a. 2016). On the other hand, paradoxically, not everybody could appreciate the meaning and importance that they could have in the linguistic field. A colleague of Alberto Zamboni (the great expert on Venetian dialects, Zamboni 1974, and member of the AMDV team), who learned of our intention to create an AIS digital atlas, didn't think this was a good idea:
Why ever embark on such a complex enterprise, when it is enough to enter the department library and consult the AIS volumes without the least effort?
Without the least effort? Considering the weekends, the countless Italian calendar holidays, the time periods reserved for researchers and students, the strikes and diseases of the guardians, the evening and night closure, there was little hope of entering the library.
The few remaining hours were to be divided with the 3-4 people of the AMDV team, who needed to consult the atlas at the same time.
On the other hand, what to tell people who, at that time, had to travel hundreds of kilometres to get to the library?
What's the problem? It is obviously possible to photocopy the atlas pages.
Obviously? It wasn’t imaginable to plan the AIS capture on a normal A4 or even A3 scanner without seriously compromise the integrity of the volumes. The scan did imply: turn upside down the volume with someone's help, give the correct orientation to the page, and then repeat this operation 4 times to cover the entire surface (44x58 cm) for each of the 1705 pages.
So, if we wanted to meet our project commitments and to avoid the Trentino misadventures, we were forced to give a turn to the linguistic karmic wheel.
2. Project chronology
1998-2003 – The Museo degli Usi e Costumi della Gente Trentina (MUCGT) carries out the "Il Trentino dei Contadini", the (little) talking atlas of the Trentino dialects (Mott/Kezich/Tisato 2003, Fig. 3, 4, 5, DEFAULT).
2009-2017 – Achievement of NavigAIS, a high resolution digital version of the AIS atlas, born to allow the fast and easy navigation of its 1705 maps, and to capture the whole AIS text by a custom integrated OCR (Optical Character Recognition) (DEFAULT).
The NavigAIS project developed in three phases:
-
-
- 2009 – A batch (or stand alone) Matlab version was implemented for the AMDV project which was then starting (DEFAULT) (Tisato 2010). NavigAIS had to guarantee the AMDV team real time consultation of the atlas in order to check the speaker’s answers in the field (Fig. 13, 14, 15), and, in a subsequent step, to create the AIS lemma database. The following year (2010) the software was publicly available for download (https://navigais.pd.istc.cnr.it).
- 2014 – The NavigAIS online version was delivered to give all researchers and students an easy and quick access to the AIS atlas, as stated by the FAIR principles (https://navigais-web.pd.istc.cnr.it) (Fig. 1, 1b, 16, 17) (DEFAULT).
- 2015-2017 – The NavigAIS final version integrated a Matlab software with an OCR (Optical Character Recognition), which was specifically developed for the AIS Reloaded project (DEFAULT) to complete the AIS text digitization in acceptable times (Tisato 2019). Half of the work (i.e. 880 maps out of a total of 1705, with a total of about 700,000 entries) has already been completed by the end of 2019, and the related database is now accessible and downloadable (DB current embedded working version, project page https://www.ais-reloaded.uzh.ch). At the time of writing this paper (November 2022), another 504 maps have been transcribed, and by the end of 2023 it can be expected that all the data will be available on the aforementioned website.
-
2009-2015 – AMDV – Multimedia Atlas of Veneto Dialects (Tisato/Barbierato/Ferrieri/Gentili/Vigolo 2013, Tisato 2015, Tisato/Vigolo 2016) (DEFAULT) (https://www3.pd.istc.cnr.it/amdv). The project has been realized at the Institute of Cognitive Sciences and Technologies (ISTC-CNR) and the Department of Linguistic Disciplines (Padua University) by an interdisciplinary team6, and has been funded by the Padua Cariparo Foundation. It offers a multimedia, ethnographic and etymological framework to investigate the diachronic evolution of Italian dialects that has taken place over 90 years in the Veneto region, through a recording campaign in the same locations as the AIS surveys and using the same AIS questionnaire.
Ch. discusses the approach used to capture, encode, index and retrieve information from the AMDV documents and the software tools developed to extract phonetic and spectral parameters from the audio material and make them available in accordance with the FAIR principles.
2016-2025 – AISr – AIS Reloaded (Loporcaro/Schmid/Zanini/Pescarini/Donzelli/Negrinelli/Tisato 2021b). The project is promoted by the Romanisches Seminar (RoSe), Zurich University, and funded by the Swiss National Science Foundation (DEFAULT).
AISr intends to:
-
-
- Achieve a searchable online database of all AIS lemmas. By the end of 2019, 880/1705 maps were acquired with about 700,000 entries. As said before, the data is now available on the AISr website: https://www.ais-reloaded.uzh.ch. By the end of November 2022 (date of this paper's update), another 504 maps have been accomplished by the AISdt - AIS the Digital Turn in continuation of the AISr (Loporcaro/Donzelli/Garner/Idone/Salvi/Tisato 2021). By the end of 2022 the AIS textual data will be available on the aforementioned website (see also the current embedded working version).
- Carry out an investigation on the AIS datapoints of Canton Tessin and Grisons (2017-2020), and in Lombardy and Piedmont (2021-2025), collecting data in the same AIS localities and using the same questionnaire. As described at http://www.rose.uzh.ch/de/forschung/forschungamrose/projekte/AIS-reloaded.html and https://www.rose.uzh.ch/de/forschung/forschungamrose/projekte/AIS,-the-digital-turn.html the project proposes, as in the Trentino atlas and in the AMDV atlas, to create a dialectal corpus to study the lexical evolution in these regions in one hundred years. Transcriptions and audio files are now accessible and downloadable at the project website https://www.ais-reloaded.uzh.ch (and embedded database version).
-

MUCGT custom lemma transcription used in the atlas "Il Trentino dei Contadini".
Example from Roncone [sigruSèl, manårìn] instead of [ṣį̀gruẓę́l, manαrī́n] as in the original AIS map n. 547 ("the hatchet" https://navigais-web.pd.istc.cnr.it/?map=547&loc=roncone).
3. Lesson to learn from the Trentino Atlas
In 2003 Antonella Mott, Giovanni Kezich, and Graziano Tisato, carried out the project of a talking atlas of the Trentino dialects at the Museo degli Usi e Costumi della Gente Trentina7 (Mott/Kezich/Tisato 2003, Fig. 3, 4, 5).
The atlas, known as "Il Trentino dei Contadini"8 (Fig. 3), was funded by the Cassa di Risparmio di Trento e Rovereto.
The atlas allows an exploration of the peasant world with some (at that time) interesting innovations in the field, in particular, the use of 'talking' photos (Fig. 4), and of interactive sonograms to study the phonetic features of the Trentino dialects (Fig. 5).

Talking photo in "Il Trentino dei Contadini". Scheuermeier picture at Peio municipal dairy, 17 June 1921.
Moving the mouse over the objects reveals a label, and allows listening to the dialectal speaker.
The author was involved in the project in 1998, after the museum had lost two years in fruitless attempts to finish it. The completion took five years (1998-2003) for various reasons:
-
-
- The difficulties, mentioned above, to continuously manipulate and consult the AIS volumes.
- The trouble of assigning lemmas that are too close together on the map to the correct AIS data point.
- The time wasted in retrieving a lemma moved by the AIS compilers to the sides of the map due to the limited space near the corresponding data point, for example https://navigais-web.pd.istc.cnr.it/?map=1569&zoom=8&point=6400,12700,440,140).
- The problem of conducting the investigations by a non-dialect speaker with the consequences that, many times, the informant felt obliged to reply in Italian, despite all the recommendations to speak only in dialect.
- The decision of showing the subject a randomized series of images on flying sheets. So it happened that the operator had to search for the right image, wasting a lot of time, and disturbing the audio recording with random noises and rustles.
- Other problems and delays arose from the difficulties in the post-processing phases to find the desired word on a tape with 7-8 hours of continuous recording.
- Finally, the main difficulty: the task of transcribing the complex AIS phonetic inventory, with 71 vowels, 172 consonants, 40 diacritical symbols distributed on 7 different levels (Fig. 18), and 20 punctuation symbols (https://navigais-web.pd.istc.cnr.it/AIS_symbols.htm). The adoption of a simplified symbolism, instead of the AIS original one (Fig. 19), taken by the MUCGT for legibility reasons, ended up creating many more problems than it could solve.
-
Summing up, some delays in the atlas realization time were due to the first five points in the list, but the invention of a “simple” phonetic system proved to be a linguistic headache, for the lack of the 1921-1922 original speech records. Each time the transcribers wanted to replace a symbol instead of the AIS original one, they felt compelled to consult the dialectal expert(s), without any guarantee to solve the doubts.
See an example in Fig. 3, the Roncone transcription [sigruSèl, manårìn] instead of original text [ṣį̀gruẓę́l, manαrī́n] (https://navigais-web.pd.istc.cnr.it/?map=547&loc=roncone).

Waveform, sonogram, pitch (red) and intensity (blue) for a dialectal lemma of Mortaso.
4. NavigAIS - The AIS Navigator
4.1. NavigAIS stand alone version
The AMDV project started in 2009, after a seven-year search for funding (DEFAULT). Fortunately, meanwhile there had been time to digest the Trentino lesson.
The first decision was to create a high-resolution, navigable version of the entire AIS atlas, which was not initially planned, as the project intended to deal only with the dialects of the Veneto region.
Being aware that a lot of people could need such a resource, we decided, however, not to limit its implementation to the Veneto region or to the maps absolutely necessary for our project, but to extend it to all Italian regions and all 1705 AIS maps.
A batch version of the software, called NavigAIS, was available in late 2009, just in time for the field investigations to begin (Fig. 13, 14, https://navigais.pd.istc.cnr.it).
In order to create the digital atlas, it was necessary to spend several weeks searching for the right scanner, asking publishers, pressmen and photographers, until, by a lucky chance, a Zeutschel OS 10000 color scanner was discovered in the municipal archives of Padua. This kind of scanner can capture a double A2 page, at 600 dpi, can support the A1 format and, most importantly, is equipped with a book cradle (Fig. 6), allowing to place the book on two balanced plates, and to insert the book spine in the gap between the two surfaces. The machine applies an even pressure on the two opened pages against the surface of the scanning glass, reducing creases and deformations of the surface while avoiding any damage to these irreplaceable volumes.

The AIS maps were digitized by a Zeutschel OS 10000 scanner with 600 dpi resolution.
The resulting map size was about 10000x13000 px (420 MB/map and 716 GB total size).
To complete the task in acceptable times, before the start of the AMDV project, the entire processing chain was automated to require none or minimal human supervision (Fig. 7, DEFAULT).
The 1705 captured maps were subjected to a preliminary 6-step processing, which could be executed and inspected step by step, or carried out all together (Fig. 7, DEFAULT).
The procedure was designed to improve the rendering and the filtering of the noisy original maps (Fig. 12):
-
-
- Initial step - Scan the maps at 600 dpi (Fig. 8).
- Step 1 - Map rotation according to the image orange frame (Fig. 8b).
- Step 2 - Map cropping (Fig. 9).
- Step 3 - Enhancing the contrast (Fig. 9b).
- Step 4 - Automatical separation of the text (Fig. 10) from the background (Fig. 10b) into two distinct matrices, needed to assure the best results in the OCR step (DEFAULT). This is an indispensable trick to avoid that the borders and orographic lines, touching or overlapping the characters, could hinder the OCR recognition (see for ex. in the map 548, the points n. 71, 115, 116, 118, 231, etc., NavigAIS-web K. 548.71).
- Step 5 - Removing the background noise, etc. (see the map in Fig. 12 before and after the processing).
-

Building NavigAIS - The AIS map digitization procedure in six steps.
Step 1 - Image Rotation
The first step of the AIS map processing must try to correct the page rotation which is inevitable in the scanning process. This is important for a better map visualization but indispensable for the subsequent text recognition task. To achieve this job in an optimal way, the program exploits the orange borders present in all the AIS pages (except the prefaces). First of all, the Matlab procedure must separate, on the orange color basis, the background, the border lines, the location identifiers and the rectangle frame from the text. Then we extract the image edges using the Roberts method of approximation to the derivative (Roberts 1963b). The edges are defined at the points where the gradient of the input matrix is maximum. Then, the rotation angles of the frame sides can be computed with a Radon transform, which has the remarkable capacity to extract lines and curves from very noisy images. The Radon transform works by projecting (i.e. summing up) the image intensity onto a line whose angle of inclination varies within a specific range (in our case between -2° and +2° with an increment of .02°).
The original image is then rotated with each one of the 4 candidate angles, and the Radon transform is recalculated again to find the angle giving the best result (Fig. 8b). In this way we try to eliminate the errors induced by the deformation of the book spine, which could alter some of the page lines, but rarely all of them, and by the interference of the contiguous page, which is sometimes captured in the current image.

NavigAIS Processing - Initial scan (NavigAIS-web K. 225). fig. 8b: Step 1 - Map rotation.
Step 2 - Image Cropping
The procedure automatically cut out the image to reduce the size to the minimum possible, with the sufficient intelligence to avoid the inclusion of a part of the contiguous page (Fig. 9). Moreover, all the maps are aligned in the same way, so that, in a future version of the navigator, we can use one unique background for all the different maps.
Step 3 - Contrast Enhancement
We need then to prepare the map for the next step, adjusting the image contrast. In this case the intensity values of the rotated image are weighted to lower values to produce darker colors (Fig. 9b).

NavigAIS Processing - Step 2 - Map cropping (NavigAIS-web K. 225). fig. 9b: Step 3 - Enhance the map contrast.
Step 4 - Separating the foreground and background image components
In this stage, the background is singled out and isolated, thanks to its orange color (Fig. 10b), and then the resulting digital matrix is subtracted to the whole matrix image to achieve the text isolation (Fig. 10).

NavigAIS Processing - Step 4: Text sep. (NavigAIS-web K. 225). fig. 10b: Step 4 - Noisy background.
Step 5 - Filtering the noise
On the final step, we run a median filter (a nonlinear transformation, called “salt and pepper”) on the resulting image to eliminate noisy artefacts. The advantage of a median filter is that it is more effective than other algorithms (for ex., convolution), when the aim is to reduce the noise and at the same time preserve the edges (Fig. 11).
We repeat the same process on the two output images (foreground and background), to obtain the final components in Fig. 10 and Fig. 11.

NavigAIS Processing - Step 5: Salt and Pepper filtering. fig. 11b: Foreground-Background (red) overlay.
Step 6 - Saving the foreground and background map components
We obtain the display of the digital map with the overlay of the two resulting matrices (text (Fig. 10), and background (Fig. 11), which are logical masks made only of 0 and 1 bit, indicating the presence or absence of a certain color. In this way, a desired false color can be assigned a posteriori (for ex. in this case, black to the foreground and red to the foreground as in the real AIS maps).
Matlab for some historical reasons, inherited from Fortran, wants to store a logical variable in 8 bits instead of one only, wasting a lot of space. So, it was necessary to write a low-level compression routine that could force the efficient memorization of this kind of data. With this expedient, the size of the entire AIS shrank to 2.72 GB (about 270 times smaller than the total original size, 716 GB, of the scanned images).
Fig. 11b shows the final rendering of the map as overlay of the two images resulting from the processing chain. Fig. 12 allows comparing the initial image (on the left) and the final overlap (on the right) of the two processed components (foreground and background).

NavigAIS Processing - Original noisy map (left), and the map resulting from the superimposition of the foreground and background extracted components (right) (NavigAIS-web K. 547).
NavigAIS navigation software
A Matlab graphical user interface, called NavigAIS, was created to allow an easy navigation of the maps.
NavigAIS presents three windows (Fig. 14). To navigate around the AIS map, it provides an overview window that is a miniature of the entire map (left box, Fig. 14): a blue rectangle signals the map position and can be dragged to visualize the wanted zone in the main window. The main window displays the AIS maps at the desired magnification ratio. At the top of both these windows there is a toolbar with some buttons.
They allow: a) to zoom in and to zoom out of the map, b) to move from a locality to another in sequential or predefined order, and c) to print and save the current image. This functionality was also exploited in the AMDV realization to acquire an optimal reproduction of all the Boesch drawings at 600 dpi, later used in the AMDV atlas (NavigAIS embedded version and Fig. 16, 40).
The third window offers a string search on the AIS map index, and on the location names (Fig. 15). It is possible to preselect the points to explore. This functionality was created to automate the OCR programmed final phase, which required successively moving to the investigation points of a user scheduled list.
4.2. The role of the NavigAIS in the AMDV project
The first implementation of NavigAIS was a batch version (https://navigais.pd.istc.cnr.it), which played an essential role in the realization of the AMDV project, in two fundamental steps of the processing:
-
-
- First of all, since the start of the AMDV project in July 2009, NavigAIS was used in the real-time check on field of the informant answers (Fig. 13, 14). With the NavigAIS feedback, the linguist could instantaneously verify similarities and differences with the lemmas transcribed in the AIS maps 90 years before, in the examined point and also in nearby localities, and interact during the recording sessions (Fig. 13). This kind of facility, never used before in the investigation field, gave the AMDV researchers a great advantage both in terms of lexical precision, and in the speed of data acquisition. The number of AMDV collected lemmas (14500 for 430 maps in the Veneto region) turned out to be 25% higher than the 11600 answers for the same 430 maps transcribed by Scheuermeier in 1921-1922.
-
-
-
- Another important role played by NavigAIS was the AIS lemma database creation. In this case, the software gave the operator the possibility to examine the 26 spots of the Veneto region in a programmable order, and to transcribe the AIS sequences in the database. This could be simply obtained by selecting the Veneto region in the proper list box (box n. 12, Fig. 15), and then moving around to the previous or next spot in a liable way. After the insertion of the answer in the database, the NavigAIS visualized the saved data and the original graphic image, side by side, to allow the user to check its correctness (bottom box, Fig. 14). According to this procedure, the AIS database was completed in only two months with an error rate smaller than 2%.
-

On the field investigation with the NavigAIS Batch Version on 15th October 2009 in Romano d'Ezzelino. On the left, the linguist Alberto Zamboni compares the speaker answers with those transcribed on the AIS atlas (NavigAIS-web K. 547.354). The SyncRec software shows the informant (Angelo Dissegna) an image on the screen in front of him, which he is supposed to comment on. The audio manager (out of range) supervises the speech acquisition on his workstation (bottom left corner). The person responsible of the video footage doesn't appear in the picture.

NavigAIS Batch Version: AIS map n. 225 (NavigAIS-web K. 225.35) centered on the point 35, Bivio (Grisons, Switzerland), with the names of the AIS localities highlighted in blue.
The navigation box (left), and search box (right), overlap the map.
During the database check, the OCR sequence appears in the left bottom box to compare with the original text.

NavigAIS Batch Version with the map (arrow n. 1, 2, 4, 16) and locality (9, 11, 13) search boxes,
the point selection by province and region (12), the button to move to the previous or next map (3), and previous
or next point (5), to display the inquiry names (7), the background (6), the OCR window (14),
the current map (15), and the window with the configuration options (17).
4.3. NavigAIS online version
In 2014, an online version of NavigAIS was created to meet many requests from people who did not use the Windows operating systems or had difficulties installing the stand alone version on a virtual machine (NavigAIS embedded version, Fig. 1, 16, 17).
The software is written in pure JavaScript and Microsoft Ajax (Asynchronous JavaScript And XML, which is a dominant technology for web services), to simplify the web software implementation. In this way, the data exchange with the server takes place asynchronously, without interfering with the client side processing and allows to refresh only the part of the map that is being visualized. The original maps were resampled at 15 levels of resolution and the resulting images were then divided in a mosaic of 256x256 px tiles, overlapping by 1 px the neighboring ones, with a total of 2622 images per map and a resulting amount of 4,470,510 (1705*2622) files for the entire atlas.

NavigAIS Online Version showing some Paul Boesch drawings on the AIS map n. 1329
https://navigais-web.pd.istc.cnr.it?map=1329&point=3400,6600&zoom=2.5
The NavigAIS online architecture had the advantages to avoid the software installation procedure but, more important, to give world wide access to the AIS making NavigAIS compliant with the FAIR principles.
As to regards the language field, the syntactic interoperability is the capacity to process the interchanged information with simple or no conversion. Semantic interoperability refers to the ability to interpret exchanged linguistic data in a coherent way according to a common protocol. NavigAIS implements an elementary structure of the metadata that avoids ambiguity in the interpretation: map name, and map number identifier, inquiry locality name, and inquiry number identifier, point coordinates [x, y], rectangle coordinates [x, y, width, height], zoom factor, string search in the map index.
The database containing the map subjects (6900 items), the numeric labels of the 1705 AIS maps, the database of the AIS 407 inquiry locality names and the related numeric labels are all integrated in a JavaScript software file of 370 KB, downloaded and cached on the side client. The total size, adding the HTML document and the CSS style file, is smaller than 400 KB.

NavigAIS Online Version Direct access to a conjugation (remote past tense of the verb “essere”, to be)
https://navigais-web.pd.istc.cnr.it?map=1700&point=3500,6900&zoom=3
Queries to the software are created simply by adding string parameters (or URL variables) to the usual web URL (Uniform Resource Locator) as follows:
4.3.1. Optional Parameters
1 - map=[xxxx] (xxxx n. of the AIS map [1-1705]), for ex.:
http://navigais-web.pd.istc.cnr.it?map=1401
(Open the map n. 1401 at the 1° inquiry location, Brigels)
2 - find=[str] (string to search), for ex.:
http://navigais-web.pd.istc.cnr.it?find=botte
(Search the index list for a map containing the string "botte" and displays it).
3a - point=[yyy] (yyy is the ID point [0=Legend, 1-990]), for ex.:
http://navigais-web.pd.istc.cnr.it?map=1434&point=336
(Open the map n. 1434 at the locality n. 336 - Ponte nelle Alpi)
3b - point=[x,y] (x,y absolute coordinates of the point in px in the range x=[1-10000], y=[1-13000]), for ex.:
http://navigais-web.pd.istc.cnr.it?map=1329&point=1500,6000
(Open the map n. 1329 centered on the point with coordinates x=1500, y=6000)
3c - point=[x,y,w,h]
x,y abs. coordinates of the left corner rectangle in px x=[1-10000], y=[1-13000];
w width and h height of the rectangle in px w=[1-10000], h=[1-13000], for ex.:
http://navigais-web.pd.istc.cnr.it?map=1569&zoom=6&point=6400,12700,440,140
(Open the map n. 1569 centered on the point x=6400, y=12700, and draw a blue rectangle around a word moved off the map)
4a - loc=[location name] (location name is the inquiry location name).
http://navigais-web.pd.istc.cnr.it?map=547&loc=Teolo
(Open the map n. 547 centered on Teolo).
4b - loc=[cardinal direction] (nw/northwest, nh/north, ne/northeast, we/west, ce/center, et/east, sw/southwest, sh/south, se/southeast).
http://navigais-web.pd.istc.cnr.it?map=547&loc=nw
(Open the map n. 547 centered on the northwest quadrant).
5 - zoom=[zoom factor] (0.1-40).
http://navigais-web.pd.istc.cnr.it?map=1329&point=2000,6000&zoom=10
(Open the map n. 1329 on the point with coordinates x=2000, y=6000, and a zoom factor of 10x)
4.4. How to embed NavigAIS into a user document
The online version of NavigAIS was designed to conform to the FAIR reusability requirement. In this way, the entire AIS atlas can be embedded as an object in HTML documents as WordPress, Visme, Google Slides, etc., with a single line of code. It is possible to get a string example from the top right "Embed Code" button in the NavigAIS window (Fig. 1, and NavigAIS embedded version). The code can be customized with the parameters (map number "map", locality "loc", size and position "point", search string "find", zoom factor "zoom") described in the previous DEFAULT and in the following two paragraphs (see also https://navigais-web.pd.istc.cnr.it/navigais_embed.htm or https://navigais-web.pd.istc.cnr.it).
Copy and paste the following code in your HTML page
<iframe src="https://www3.pd.istc.cnr.it/navigais-web?map=547&point=374" width:"100%" height:"500"></iframe>
Optional parameters
● The dimensions of the NavigAIS container [width:"1000" height:"500"] can be modified as required.
● The NavigAIS call accepts 5 optional parameters (map, find, point, loc, zoom) described in the previous chapter DEFAULT.

Levels of the AIS diacritics with respect to the basic glyph (magenta).
5. AISr - The AIS reloaded project
The first step in the project to capture the entire AIS text was to evaluate the advantages of a software approach compared to manual transcription.
As mentioned before, the time required to transcribe 11600 AIS lemmas in our database was about 60 working days, which means an approximate time of 150 seconds per lemma (i.e. 11600 lemmas x 150 seconds = 1.740.000 seconds which corresponds to approximately 60 working days of eight hours each). Considering that the number of lemmas in 880 maps is about 770,000, and therefore presumably 1,400,000 for the entire atlas, the total duration will be ~210,000,000 s, i.e. ~7,291 days, or ~20 years (working every day of the year!), at a rate of 85 maps per year.
But the academic reality may prove even worse. When I wrote to Edgar Radtke (University of Heidelberg) for a possible collaboration on the acquisition of the AIS, he told me they were doing everything by hand, at a rate of roughly ten maps per year. This meant that they could finish the work around the year 2200!
There was no doubt that the task required a different solution.
Fortunately, in 2016, Michele Loporcaro and Stephan Schmid of the Romanisches Seminar of the University of Zürich accepted the author's proposal to capture the text of the entire AIS, and, for the first time, create a queryable and downloadable database.
The project, with the name AISr - AIS Reloaded, submitted to capture half of the entire atlas within three years (2016-2019), was funded by the Swiss National Science Foundation with 684,000 CHF (http://www.rose.uzh.ch/de/forschung/forschungamrose/projekte/AIS-reloaded.html). The expected result was achieved on schedule by the end of 2019 and all data was made freely available (https://www.ais-reloaded.uzh.ch).
An additional funding (996,000 CHF) has been obtained for the completion of the work in a related project (AISdt, AIS the Digital Turn [2021-2025; https://www.rose.uzh.ch/de/forschung/forschungamrose/projekte/AIS,-the-digital-turn.html]).
The AISr and AISdt projects also aim to create a corpus for the dialects of southern Switzerland, Lombardy and Piedmont by collecting new data at the same AIS sites a hundred years after the AIS collection, an indispensable prerequisite for documenting diachronic change in the corresponding dialects in the century that has passed.
Transcriptions and the audio recordings are freely available for download at https://www.ais-reloaded.uzh.ch or in the below embedded version of the database.
The website allows filtering the data by map number, place of investigation, period (from the AIS and/or from the AISr and AISdt projects), searching a string within the transcripts, and displaying the data in map or tabular mode. The original data is coded both with the AIS and IPA transcription system, and the transcriptions of the new data are accompanied by the related audio.

AIS Phonetic Inventory (extracts from https://navigais-web.pd.istc.cnr.it/AIS_symbols.htm)
5.1. How to OCR the AIS
How is it possible to extract the text from an image represented in the digital dimension as a numeric matrix of pixels9?
A possible approach is the pattern matching. In the preliminary stage of the OCR training we need to build the templates, i.e. the algorithmic vector describing the prototype of all the characters to be recognized. In the second stage, an unknown input character is identified, following certain criteria, as the most close to one of the templates.
In the elementary example of Fig. 20, the red colored matrices A, B, C on the right represent the generated prototypes. The input character to be recognized appears on the leftmost column.
Each square in the matrix represents a pixel (px) of the image, with its numeric identifier (in this case, for convenience, 0=blue=background, 1=red=text).
Then, applying a very basic pixel matching rule, the input matrix is compared with all the templates simply counting the number of pixels that do not coincide (indicated with "x" in the second row of Fig. 20): the template which scores the least number of non-coincidences (i.e. the maximum number of coincidences) could be the character we are looking for.
With this rule, we count 17 px non-coincident pixels for the first template (A), 6 px non-coincident for the third template (C), while all the pixels in the second template (B) are coincident, identifying the incognito input as B (green oval in Fig. 20).
Such a recognition system, obviously, would have some interest that is limited exclusively to characters of unchangeable shape and size. In the case of ancient documents and handwritten characters, this matching criterion can't really work. The OCR needs an algorithmic description of the glyph shape (for ex. by a polygonal approximation, blue oriented lines in Fig. 21) that consents the matching despite the size, shape, slant and degradation conditions of the characters (for ex. ruined [o] in Fig. 21). In this way, a feature vector is extracted, which allows to measure a distance in an N-dimensional space of the unknown character from the prototypes (the black [o] at the top of the Fig. 21).
The realization of efficient algorithms to extract the feature vector, and the developments of innovative methodologies and technologies involve now a large number of research areas, as ICR (Intelligent Character Recognition), Machine Learning, Pattern Recognition, Deep Learning, etc.
Without going into the details, which can be found in the specific literature, we just mention the state of the art, giving here the results (obtained just before the start of the AISr project by Vithlani and Kumbharana in 2015 (Vithlani/Kumbharana 2015) of a test to recognize a sequence of 36 characters (English, alpha-numeric, capital, isolated), repeated ten times, handwritten from seven people of various ages. The sequence was processed by six stand alone and online OCR software. The Custom OCR Online gave the best results with an recognition accuracy of about 44% or a CER (Character Error Rate) of 56%, very far from the rate close to 100%, obtained in the case of printed characters (when obviously they are not degraded or affected by noise).
In reality, the results of common OCRs on the AIS atlas are much worse than those of the described test.
In fact, the AIS phonetic inventory contains a very large number of low-frequency symbols (Fig. 19), with a pattern that can be described by the Zipf law (Zipf 1949a). The inevitable consequence of this distribution is the degradation of CER in any OCR based on a probabilistic engine.
This is a problem that also prevents the approach with neural networks because of the enormous time required for the OCR training phase, which must be based on a representative number of real samples extracted from the whole atlas. In the case of the AIS, the number of symbols to be recognized is very high (~300), as they correspond to languages of many regions and a great linguistic variability. If we want to take even a sample of the 300 symbols for each of the eight AIS volumes, the minimum representative set should consist of 2400 images.
The AIS symbolism presents other features that make the use of normal OCRs inefficient: the glyphs are italics with a 70° inclination, overlapping the neighboring characters (Fig. 29), traced by hand by different people, and using 25 diacritics arranged on seven different levels (Fig. 18).

OCR rudimentary engine, based on the pixel matching between prototypes (columns 3-5) and a submitted character (first column). The unknown character (with a scoring of 0 no-coincident pixels) matches the B template (green oval).
Moreover it must be added that:
-
-
- The OCR accuracy depends on the quality of the scanned maps that are almost a century old and in poor conditions.
- There is no model of language(s) available which could give the probability of a character string (e.g. bi-grams, tri-grams, n-grams) and word succession, helping the OCR in the right sequence selection.
- There is no dictionary10 which could list all the existing words in the dialect(s) and could assign the correct form among various candidates.
- The task requires long execution times, both for the number of entries to be captured (approx. 1705 maps x 407 examination points), and for the training and implementation of the OCR, as well as for the final result validation.
-
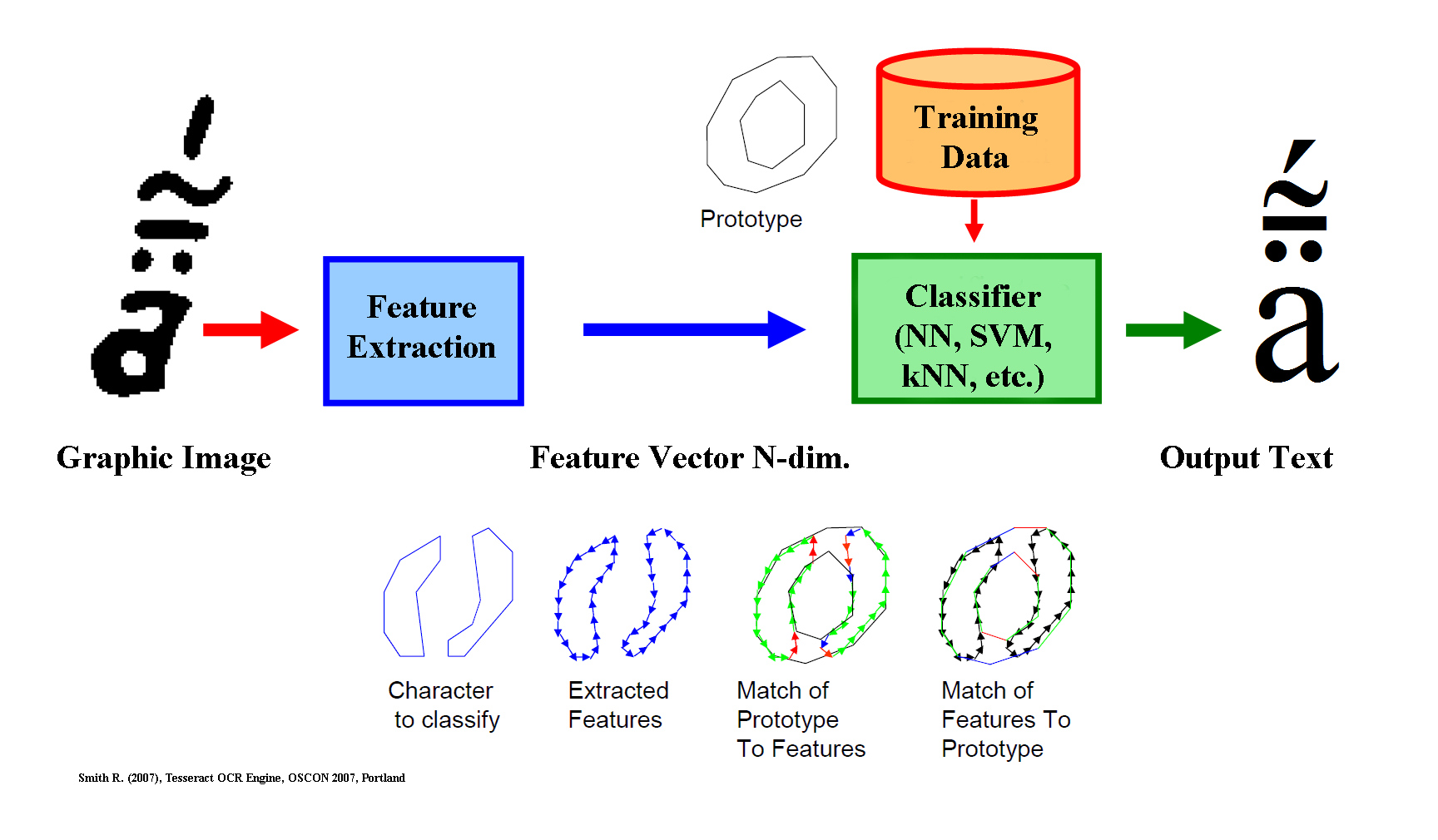
OCR Scheme. The classifier find the distance in feature space to the ideal prototype vector (for ex. by kNN - Nearest Neighbor), or divides feature space into regions related to different classes (for ex. by SVM - Support Vector Machine).
Before implementing NavigAIS, three OCRs were considered: the two most popular commercial softwares at that time, Omnipage (Nuance, www.nuance.com) and FineReader (ABBYY, www.abbyy.com) and a free software, Tesseract (developed by Hewlett Packard between 1985 and 1994, which became open source in 2005 under Apache 2.0 license, sponsored by Google for about ten years and now downloadable from the repository: https://github.com/tesseract-ocr).
A first examination revealed that Omnipage did not ensure an adequate management of the diacritics requested for the AIS symbols and was discarded. FineReader allowed the coding of AIS characters and diacritics according to the Unicode standard. As for the training phase, the software accepted the graphic images of anomalous characters with the related identity, although the mechanism was very laborious: in fact, for the result to be acceptable, the identification operation had to be repeated on thousands of glyphs. It should also be observed that this processing was fairly approximate, as the images captured by FineReader could not be cleaned up of the lines belonging to the neighboring characters, with relative effects of worsening the CER errors.
However, the shortcoming of FineReader was that it was not possible to integrate the software into the overall processing. In fact, the possible automation consisted in depositing the desired user graphic images in a so called 'Hot Folder', subsequently taken and recognized by the program. Unfortunately, the action of the OCR, programmed for the normal Office Automation functions, was asynchronous and triggered at discrete time intervals with a minimum delay of 1 minute. Such a limitation resulted in unacceptable acquisition times for the 1.4 million words of the AIS and ended up making manual transcription more advantageous.
Finally, it was discovered that the automation mechanism only provided for the use of predefined standard languages and prevented the use of a user-trained language as the AIS.
5.2. Embedding an OCR in NavigAIS
Tesseract offered competitive advantages in comparison with other software:
-
-
- It provided all the source code.
- It could be easily integrated into the processing chain.
- It had a CER error rate comparable with the most prestigious commercial software.
-
A Tesseract version was compiled as a Mex Matlab file and incorporated in the NavigAIS processing loop to obtain immediate results.
In this way, the software recursively moves to the AIS locality(ies) selected by the supervisor and waits for interactions. The main task of the supervising person is to choose the right candidate for recognition between the possible lemmas near the current point. As anticipated, this is not always a trivial task (DEFAULT). With the indication of the supervisor, the software can proceed automatically selecting the zone containing the phonetic sequence (blue resizable rectangle in Fig. 23, 25) and processing the chosen image by the OCR.
The Tesseract engine was properly trained to recognize the AIS symbols on different sets of real characters taken from the maps, or artificial AIS-like font, that allows easily preparing the test sequences (Fig. 27).
Obviously, the CER was still unacceptable, despite the training phase: as you can see in the third column of Fig. 27 (OCR only), the CER error rate was about 28% , still too high, considering that the OCR output strings required long checking and correction times.
5.3. The Solution: Decompose the problem
The approach was then to decompose the problem into a more manageable one, according to the concept of decision tree. The AIS symbols are separated into the base glyphs, easily recognizable by a normal OCR, and the diacritics, which are then processed with an adequate Matlab software integrated in the NavigAIS interface. The diacritics are processed on the basis of their geometric properties and relative positions to be more easily identified (Fig. 24-25).
In this way, it was possible to use Tesseract for what it was able to do: in a first step, to segment the graphic sequences, and in a second step to recognize the base glyphs alone with an optimal CER error rate. Finally, as told before, a Matlab software was programmed to recognize the diacritics, and in the final step to apply a set of rules appropriate to the AIS symbolism to process the base glyphs and the diacritics together (Fig. 26).
The image undergoes three processing phases (Fig. 22, 29):
-
-
- A pre-processing step is performed to discard the lines belonging to nearby lemmas and/or touching the blue borders, and to eliminate noise and anomalous spots (with the so called 'Salt & Pepper' filtering) (Fig. 24).
- Then, with a segmentation-then-recognition approach, we get from Tesseract the character bounding boxes (blue draggable resizable rectangles in Fig. 29), useful in the training phase and in the next post-processing step and useful for the preliminary classification of the characters.
- We execute then the final post-processing with a set of Matlab rules, based on geometric and topological properties, and specially designed to process the diacritics (Fig. 25-26). This phase also provides for the diacritic check (i.e. relative position and compatibility with the basic glyph), and, in general, for the conformity of the resulting character with the phonetic inventory. Faults and errors are highligthed in red color (Fig. 25).
-
At the end, the supervisor validates the OCR output and intervenes only if deemed necessary to manually correct the error(s) with the virtual keyboard. It then lets the software memorize the sequence in the database (Fig. 22-23).
After saving, NavigAIS automatically moves to the next point and repeats the procedure.

NavigAIS OCR Scheme. On the left: the map n. 1325, “la botte” (barrel) with the navigation window navigais-web.pd.istc.cnr.it/?map=1325&point=10. The OCR (red blocks) receives as input the graphic matrix containing the string to recognize (green rectangle). On the right: the virtual keyboard to correct the OCR sequence (if the operator deems it necessary). The output sequence is automatically saved in the database (shown as an Excel sheet, fig. top right) [using the symbol ◌̋ instead of ◌̓ ́ for a better graphic rendering]
5.4. OCR result evaluation
For the evaluation of the recognizer's performance, various tests were carried out involving both the stages of the OCR training and the actual recognition step.
For the training phase, a minimal test was prepared with fifty words (approximately 500 characters in total) from the AMDV database.
The test was intentionally limited to quickly test the effects of the changes occurred over time in the test set and to compare the accuracy of the various trained languages and of a specific language with each other.
Fig. 27 summarizes the OCR results with languages trained on different training sets, taken on their own or in combination with each other. The three vertical columns report the CER for the three main test modes:
The increase of the character spacing brings a 2% CER improvement from 28% to 26% (central column, Fig. 27) and, finally, a Matlab post-processing with 350 appropriate rules produces a more significant gain of about 25% and a final CER equal to 1.41%.
The best result (error of 1.41%) is gained by the combination of various training sets (ais01, ais09, ais10, ais11, ais12) and by the execution of the post-processing step, while the worst result, CER = 25.93%, is obtained by a set artificially built with a font similar to AIS but evidently quite far from the complex reality of the AIS.
Without the post-processing phase but with the expansion of the characters, the CER increases and varies from 22% to 40%, while without the post-processing phase and without the expansion of the characters the CER increases from 24% to 40%, with a worsening of 2‑3% compared to the case of character dilation.
Fig. 27 also reports the WER (Word Error Rate), the error on whole words, which is of no interest for AIS in the absence of a reference vocabulary.
The acquisition time per point was less than 14 seconds for sequences of about 8.36 characters, more than halved compared to 30 seconds, initially valued acceptable for the project to avoid the manual transcription of the AIS text (which required 150 seconds/lemma building the database, DEFAULT). Obviously, the sequence length must be taken into account. In fact, as the number of characters increases, the acquisition time tends to increase.
The error rate, instead, does not depend on the length of the sequence recognized by the OCR and remains unaltered. The CER error can increase by a few percentage decimals in the "anomalous" sequences, in which the lines of the characters touch each other and the deterioration of the characters is high. In these cases, in fact, the lack of a dictionary of dialectal terms prevents the OCR from correctly interpreting the damaged characters.
An acquisition test on real data from 14 complete AIS maps for a total of 100,000 characters obtained an average CER error rate of 3.65% with the so-called Levenshtein Distance (Levenshtein 1966) that includes any insertion, omission and replacement of characters and diacritics.

NavigAIS OCR Scheme
In the upper right corner (box 2), the map and locality search window.
At the bottom, the virtual keyboard (box 7) to edit the string returned by the OCR (box 5).
The blue names on the AIS map (NavigAIS-web K. 548.71) are those not yet processed by the OCR.
At the top left, the current Excel sheet, where the OCR saves the lemmas (box 1).

NavigAIS OCR operates by separating the characters from the diacritic symbols. The post-processing phase uses a set of ad hoc rules in the absence of dictionary(ies) and language model(s).

NavigAIS OCR post-processing. The ten red colored errors (characters + diacritics), present in the Tesseract output, have been automatically corrected by the final post-processing phase.

NavigAIS OCR Scheme of the rules applied in the post-processing phase.

NavigAIS OCR - Comparative results with different training sets. The three columns report the CER for the three main test modes: OCR Tesseract alone without character spacing (right) with a CER=28.1%, OCR Tesseract alone with character spacing (in the center), OCR with Matlab post-processing (left) CER=1.7%.

NavigAIS OCR - The CER error results on 14 AIS maps for a total of 100,000 characters. The average CER is 3.65% for the 14 maps and ranges from 1.35% to 5.87%. The acquisition time per lemma is on average lower than 20 s per AIS entry and varies between 13.63 s and 25.31 s according to the number of characters recognized [3095-9057].

NavigAIS OCR - Processing results for a single string: with Tesseract alone the CER error is 67%. With the character spacing (without post-processing on the OCR results) the CER error is reduced to 40%. Finally, with spacing and post-processing, all characters are recognized with CER = 0% (NavigAIS-web K. 1327.177).

NavigAIS OCR – SyncRec control score: the lines 5 to 14 command an image sequence in an initial learning session while the lines 16 onward provide the actual audio recording session. Each item in the list controls an event (displaying a text, an image, or listening to a sound file) and the entry is used to label the informant recordings in an unambiguous and explicit way.
6. The AMDV - the Multimedia Atlas of Veneto Dialects
The Multimedia Atlas of Veneto Dialects (AMDV, acronym for "Atlante Multimediale dei Dialetti Veneti") is an interdisciplinary project which brought together a team of dialectology, etymology, and voice processing researchers, with the purpose to create a linguistic atlas of the dialects of the Veneto region (North East of Italy), exploiting the current geolinguistic methodologies.
The AMDV is mainly focused on the diachronic comparison of the AIS lexical data with those collected in the same AIS localities at the present time.
The AMDV was inspired by the similar digital atlases ALEPO (Telmon/Canobbio 1985), ALD (Goebl 1998), VIVALDI (Kattenbusch 1998-2016b), etc., and, as mentioned in DEFAULT, particularly by a work done some years ago on the Trentino dialects by the "Museo degli Usi e Costumi della Gente Trentina".

AMDV Atlas. On the top right, NavigAIS (online version) launched by the button with the top red arrow.
On the right bottom, a Scheuermeier talking photo of a farmhouse taken on February 2, 1922, in Tarzo (Treviso).
On the bottom left, a card with the etymologies of the Veneto words to indicate the barn.
The AMDV purpose was the creation of a talking atlas which could give back the phonic reality behind the more or less questionable transcriptions of the traditional maps (Goebl 1994).
The speech sound wants to be the 'added value' of the project for it allows:
-
-
- To study in an effective way the relationships between the lexical, phonetic and phonological aspects of the complex dialectal reality.
- To give the user all the current processing tools useful to characterize the dialects (extracting the appropriate parameters as pitch, sonogram, formants, mapping the vocoids in a reference space, etc.) (Fig. 36).
- To turn the unalterable transcription of the traditional atlases in a work in progress, subject to modifications and improvements by the user itself listening to the audio records.
- To transform the historical pictures (Fig. 31, 35, 41) and drawings (Fig. 1, 16, 39) in talking documents which integrate the ethnographic and linguistic aspects of material culture in a powerful way.
-
The relevant aspect of the AMDV project was the development of a methodology appropriate to the large amount of linguistic data required:
The AMDV documents contain:
- 2 dialectal databases (11650 AIS lemmas and 14521 AMDV lemmas with IPA and AIS-like transcription);
- 355 lexico-etymological files, which exploit the patrimony developed at Padua University by G. B. Pellegrini (1921 – 2007) and A. Zamboni (1941 – 2010);
- 2300 ethnographic comments and related transcriptions;
- 580 pictures by P. Scheuermeier (1888 – 1973) and U. Pellis (1882 – 1943);
- 647 drawings by P. Boesch (1889-1969) et al.;
- 5870 annotated objects;
- 355 AIS legends;
- 71 videos with the interviews to P. Barbierato, C. Gentili, G. Sanga, J. Trumper; and with ethnographic clips;
- 26 biographic clips of the 26 AMDV informants;
- 12 paintings on the Veneto material culture by the painter L. Viola;
- 2 folk songs (Venice and Chioggia).
A great effort was made at the beginning to organize the data in a manageable way and to introduce in all the planned steps the highest possible degree of automation, with regard to: the database building, the file labelling and saving, the post-processing of the audio-visual documents, the editing of pictures and drawings, etc.
In fact, the automation of a trivial operation as opening and saving a file, which could take about ten seconds, can lead to an enormous gain of time if repeated tens of thousand of times.
As regards the automation process, we solved the tedious task of searching a desired word or comment in a continuous audio session, which could last many hours, segmenting the audio material directly on the field. A software, SyncRec, was programmed to present an image sequence (top right, Fig. 13), optionally randomized, and to launch the synchronous recording process. At the completion of the answer or comment for that image, the speech file was automatically labelled and numbered with the name used in the SyncRec image list (Fig. 30) and saved in the directory of the investigated locality. The software accepts an Excel or text file with the score items and allows different sources (audio files, written texts, videos and images) to be mixed on a random or sequential schedule to minimise subject interference.
Indeed the SyncRec software could offer limited interest, if it was designed only as a recording tool. Adding the possibility to schedule the desired audio-visual events during the interview, and the automation to submit the questionnaire, and to save the records, gave the necessary flexibility to use it in different contexts and applications. The use of this tool allowed the collection of 14521 audio files and 2300 speech comments of very high quality without pops and clicks, without background noise, codified as the standard IEEE Float 32 bits, 96 KHz sampling rate, and normalized at -1 dB avoiding clipping and distortion effects to provide the best conditions for the acoustical data extraction. For the same reason, the audio of the AMDV words were also recorded in isolation and not extracted from the informant comments to avoid the coarticulation effects and the cropping problems due to the continuous speech.
Even before an official release, the SyncRec has been used to acquire the audio material in a joint project of the University of Western Sydney and the Italian Research Council (CNR), Italian roots in Australian soil: Tracing regional linguistic heritage in first and second generation bilinguals, which aims to identify the cultural and linguistic elements of Italian regional origins in the first, second and third generations in Australian-Italian families. The project exploited also the AMDV database to extract the phonetic data references from AIS 1921-1922 and AMDV 2009-2010 data and used the AMDV comments to introduce the SyncRec training sessions.

AMDV Atlas. The orographic map in the AMDV background (Fig. 31) can be replaced by the one showing the Veneto dioceses.

AMDV Atlas. On the top left, the toolbar to increase the font size, to access the annotated object list (Fig. 35), the phonetic search window (Fig. 37-38), the sonogram (Fig. 36), the informant biography (Fig. 45), the page print, the map zoom, the configuration options, the switch orographic(Fig. 31)/diocese(Fig. 32) map , the language interface, etc.
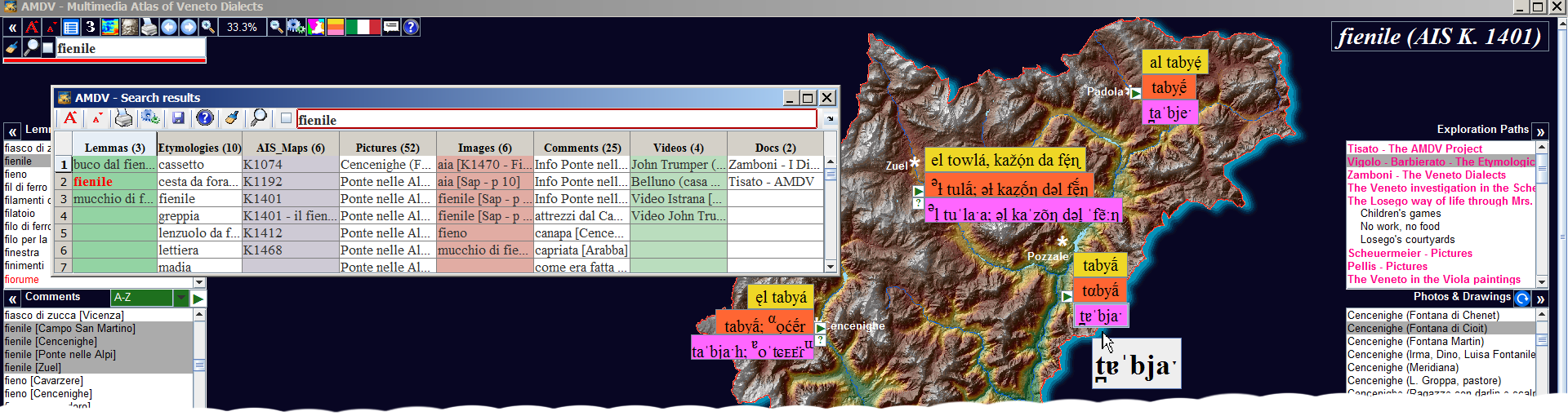
AMDV Atlas. The fig. shows the search results for the string "fienile" (barn) in all AMDV documents.
The implementation of these tools made it possible to efficiently carry out the data collection in the 26 localities, which lasted from July 2009 to the end of January 2010, and the first phase of audio post processing from February 2010 to July 2010. We undertook a second recording round, which kept us busy from July to the end of October 2010, to correct some errors, substitute the noisy or poor sound quality lemmas, resolve doubtful cases and insert other interesting lemmas, increasing the lexical corpus of about 20%.
The completion of the audio processing was followed by the phonetic transcription of the captured material by Giacomo Ferrieri (a collaborator of Luciano Canepari) and finally by the database implementation which lasted about one year.
As mentioned in the introduction, the purpose of the AMDV was to provide a useful instrument for the study of linguistic changes in the Veneto region between 1921-1922 and 2009-2010. For this reason, in addition to the standard IPA transcription, we had to work out a parallel transcription according to the AIS convention. In this way, as we can see in Fig. 31 and 32, it is possible to effectively compare the diachronic results using the same code: the yellow background color indicates the AIS word from 1921-1922, the orange colour shows the AMDV transcriptions from 2009-2010 with the AIS-like symbolism, and the magenta colour indicates the AMDV data from 2009-2010 with the IPA convention. The software gives the user the possibility to choose which of the three transcriptions must be optionally displayed and the possibility to modify the font size, to zoom in and out and to drag the Veneto map.
The core of the AMDV software was implemented from January to November 2011 and was subjected to a thorough revision and refinement that lasted until September 2012.
In Fig. 31, 32 and 33 we can see the AMDV main screen: in the top left corner, the buttons allow: to modify the size of the lemma font, to gain access to the annotated object list (Fig. 35) and the phonetic tree and search engine (Fig. 37-38), to display the sonogram and the vowel space (Fig. 36), to display the informant biographies (Fig. 45), to print the documents and images, to go to the next or previous map, to zoom in and out the Veneto map, to configure the AMDV parameters, to switch between the orographic (Fig. 31) and diocese maps (Fig. 32), to hide all the list boxes and to choose the interface language. Below the buttons you find the string search box and the list boxes with the lemma main index, the ethnographic audio comments, the AIS legends and the etymological files (Fig. 40). On the right side, you can see the list boxes to choose drawings, video interviews, pictures and AMDV relevant documents and to follow some discovery paths of AMDV audio-visual documents.
The AMDV software offers a computationally efficient phonetic search engine (Fig. 37-38) which is a salient feature for the AMDV database exploration.
To facilitate the implementation of the related code, we avoided the use of a proprietary font to represent the phonetic symbols, which had two undesirable side effects: the need for a font installation step and a much more complex search algorithm. The optimal solution was to represent the phonetic symbols using a standard Unicode font, which is installed by default on all PCs today and has a set of diacritics large enough to cover the entire phonetic corpus. In this way, we can easily search for a string with or without diacritics and without knowing the specific character code. In the root search, the entire database could be examined in few seconds, with hundreds of phonetic variants included or omitted.
In the same way, you can search for the linguistic features associated with a diacritical mark (nasality, degree of vocal closure and opening, lengthening, accent, etc., corresponding to the bottom green keys in Fig. 37-38), independently from the basic symbol.
The AMDV also includes a database of all annotated 5870 objects in the pictures and the drawings. The related list can be ordered by item name, file name, author, AIS number of the locality, AIS locality name and date (Fig. 35).
The software provides a large number (70) of optional parameters, which allow to: switch the default language of the interface (Italian or English); set the directory and database paths; decide which lemma transcriptions must appear; change the visualization effects (zooming, fading, object contours, slide timing, full screen for the images, etc.); set the analysis parameters, etc., and reset all the changed parameters to a default and, of course, save them.
Moreover, the user can manually configure all the elements (font size, type, color and dimension, etc.) of the AMDV interface with an initialization file.

AMDV Atlas. Searchable list of all 5870 AMDV annotated objects.
The cells contain the direct links to the related object in the audio-visual documents.

AMDV Atlas. Sonogram, pitch and intensity contours in the word “ditale” (thimble) [el̝ ˈd̪jaˑal̝] by a female subject (mean pitch 213 Hz), from Raldon (VR). In the left window we can see a 150 ms /ja/ transition in 10ms steps, mapped in the Italian vowel space: the beginning of each arrow indicates the formant F1, F2 positions, the arrow length measures the instantaneous articulatory speed.

AMDV Atlas. Phonetic database search for an interdental /θ/ followed by /i/.
The 41 cases matching the sequence are displayed on the left, highlighting the searched string.
The results are delivered on demand in a HTML document (left).
The user can search for non-contiguous sequences, can limit the look up to a single or multiple locations, can require the exact matching or can accept all the diacritic variants.

AMDV Atlas. Search of all VCV sequences with a bilabial occlusive (orange) followed by a high vowel (blue) and a nasal consonant (green), for a total of 420 search loops. The tree on the left allows the selection of a phonetic group. The 20 results (displayed pressing the "Results" button) are delivered on demand in a HTML doc (left).
6.1. The heritage of etymological studies
One of the most significant tasks in the AMDV project regarded the preparation of the lexical, phonetic and etymological files related to the dialectal items, which distinguishes the AMDV from similar lexical atlas. The study had the aim to identify lemma convergences and divergences with respect to Italian, their areal distribution, and to highlight their historical significance (Fig. 39).
The research on the lexical types took into account both the results of AIS and AMDV investigations, displayed in the AMDV side by side, and exploited also the possibility to listen to the real sound source, allowing a better analysis of the relationship between the lexical, phonetic and phonological aspects. As mentioned before, the straight comparison with the audio has the further advantage to make the possible transcription less definitive, which can be in this way modified and improved and, moreover, helps to characterize the kind of auditory perception of the transcriber, which also in an excellent collector as Scheuermeier could lead to systematic errors.
Another important source of information for the lexical comments were both the Scheuermeier and Pellis pictures, and the Boesch drawings, which were used to disambiguate the identification of objects and to understand, at the same time, their function and use.
The approach used in the research of lexical types corresponds to an etymological-historical framework derived from the studies of A. Zamboni (Zamboni 1974, Zamboni 1984) and G. Pellegrini, which aimed at solving the near and far etymologies of the Venetian and Ladin lexicon in an exemplary way.
Other landmarks were the studies of Kramer, in particular the Etymologisches Wörterbuch des Dolomitenladinischen (EWD) (Kramer 1991) and the Italian Etymological Lexicon (LEI) of M. Pfister and M. Schweickard (Pfister/Schweickard 1979- b).

AMDV Atlas. Search for the string “cesta” (basket) in all the AMDV documents. The selection of a cell allows opening the related image, picture or document. Below, the related HTML that was supplied on request.
6.2. Ethnographic research
The AMDV reserves a particular emphasis to ethnographic research because it complements the linguistic aspect in a functional and indivisible way.
In fact, the AIS turns out to be an inexhaustible mine of ethnographic information, which include the legends of the AIS maps, the Paul Boesch drawings (Fig. 1, 16, 40) and the Paul Scheuermeier pictures (Fig. 31, 35, 41) and also the volume on the material culture published by Scheuermeier in 1943 (Scheuermeier 1943).
A philological approach was adopted to collect all the sources of information (paper documents, audio-visual testimonies, etc.), and original processing methodologies were applied to automate all the possible control loops to digitize, convert, transcribe, translate and index the documents.
This approach regards the interoperability required by the FAIR principles. In fact, we followed a criterion that is consistent with the etymological meaning of the words. In our opinion, the basic criterion, operability, must be achieved before the subsequent one, inter-operability. In other words, the system, that pretends to interact with the multidimensional World Wide Web, must be natively "operative", i.e. it must first ensure the FAIRness functionalities to the local environment itself.
This is the reason why NavigAIS followed two implementation phases: first, as a batch version (https://navigais.pd.istc.cnr.it) and then an online application (https://navigais-web.pd.istc.cnr.it).
So the operability criterion, applied in our projects, was to automate all the possible processing chains which required none or minimal human supervision and in particular:
-
-
- The complete automation was realized for all the NavigAIS implementation phases, with the result that they could be executed (and inspected) one at a time or carried out all together without the need for any human intervention (DEFAULT).
- The on-field audio acquisition automation (DEFAULT). A specific software, SyncRec, followed a user-programmed sequence that displayed the image to be commented on the informant's display and, at the same time, showed the NavigAIS-related map on the screen of the linguist, allowing him to interact effectively with the dialect speaker (Fig. 13). For each entry in the list, the audio material was automatically labelled and saved with the same image name and a sequential number (for any possible repetitions), thus avoiding the waste of time and valuable data in the recording and segmentation phase.
- The automation in the creation of the AIS and AMDV database.
- The automatic indexing of all the texts.
- A supervised procedure to trace the contours of the interesting objects in the photos and drawing (Fig. 41).
- The automatic phonetic inventory extraction based on the real data. This allows to automate the validation of the output OCR character sequence, marking the symbols not listed in the inventory (Fig. 47) and also to automate the error checking of the database content (Fig. 48).
- The automatic insertion of links between the lemmas saved in the database and the related physical position on the NavigAIS maps. The links allow quickly inspecting and correcting the errors in the inventory and error lists of Fig. 47-48.
-

AMDV Atlas. Example of a (partial) lexical-etymological document. It deals with the roots of dialectal terms to indicate “l’aratro” (the plow). The drawings are the work of the expert graphic xylographer Paul Boesch.
As seen in previous chapters, the creation of a digital and navigable AIS atlas has been the primary source for all three projects and enabled the realisation of the AMDV and the AIS Reloaded projects, which in turn will make the AIS database publicly available.
All the AIS secondary sources have been acquired, including the text of the AIS legends, the AIS images (photos by Paul Scheuermeier and drawings by Paul Boesh) and the related annotation cards (Fig. 41), the Scheuermeier diary, the letters and postcards written by the AIS team, etc.

AMDV Atlas. Scheuermeier photo taken on April 3, 1921, in Cerea (Verona). The objects of linguistic interest are annotated and marked with a polygonal contour to allow the exploration of the picture. In the top right corner the caption (transcribed by Robert, son of Paul Scheuermeier (in the left corner, the corresponding AMDV HTML document, web ready).
Other data have been collected from textual, graphic and photographic documents and videos of various origins. After the death of Alberto Zamboni (January 25, 2010, a few months after the start of the AMDV project), his fundamental essay on the Veneto dialects (Zamboni 1974) has been digitized, integrated in the AMDV atlas and enriched with the AMDV recordings from 2009-2010 (Fig. 42).

AMDV Atlas. The digital edition of the Zamboni essay on Veneto dialects with sound examples from the AMDV.
At low level, all documents are formatted as standard HTML documents, using Unicode (Universal Coded Character Set) and encoded as multi-byte characters UTF-8 (8-bit Unicode Transformation Format), so that they become independent of the system that hosts them and can be searched and delivered online without conversion.
The same Unicode encoding was also applied to the linguistic information, that means a unique universal numeric identifier for each symbol and diacritic used, discarding the use of ASCII code as this forces a non-Latin symbol to be encoded with a combination of characters.
This approach greatly simplifies the software coding which:
-
-
- Natively handles and returns Unicode strings.
- Avoids conversion and interpretation of information.
- Simplifies implementation of the indexing and retrieval engines.
- Assures the compliance with the FAIR principles of the exchanged documents.
-
The AMDV reproduces all the AIS drawings and all the pictures and documents related to Veneto, as we can do in a traditional printed volume, but obviously it also uses the specific aspect of multimedia technology, which is able to literally transform them in talking and navigable documents. We create a database with all the picture and drawing information: the author, the locality where the photo was taken, the Scheuermeier annotations and, moreover, the graphical contour of all the relevant 5870 objects represented (Fig. 41), to allow the interactive exploration of the documents with the mouse, in order to “discover” and listen to the related dialectal lemmas or to listen to the comments made during the interviews.
The AMDV was also enriched by the postcards that Scheuermeier regularly sent to Jaberg and Jud (Fig. 2) during his fieldwork in the Veneto region, which are a precious testimony of his linguistic and ethnographic adventures (and sometimes misadventures!).
The AIS atlas was not the unique ethnographic source in the AMDV, as we have included the pictures made by Ugo Pellis for the Atlante Linguistico Italiano during the same period and the pictures and drawings found in public and private collections, including some very interesting documents provided by AMDV informants.11
It is worth mentioning the contribution of Serafina Prest (one of the AMDV informants), who created an extraordinary series of drawings illustrating all the aspects of life in her native village, Losego (Fig. 43), including the children's games, the work in the fields and the reproduction of the courtyards of Losego village (Fig. 44).
The AMDV allows the information retrieval in all the indexed audio-visual and textual sources (Fig. 39). The table columns can be sorted by different document typologies and delivered in a HTML document.
6.3. Phonetic characterization of dialects
As regards the features that are useful to characterize the dialectal lemmas from an acoustic and phonetic point of view, the AMDV provides the traditional representations (sonogram, pitch and intensity contours, formant extraction and phonetic segmentation, Fig. 36), but also an F1-F2 formant plot to map the dialectal sounds to the Italian vowel space (top left window, Fig. 36), based on Franco Ferrero's fundamental research on Italian vowels at ISTC (Ferrero/Genre/Boe/Contini 1979). The user has the possibility to choose the metric of the vowel space between linear Hz, Bark (corresponding to the 24 critical auditory bands proposed by E. Zwicker, Zwicker 1961), or Erb (the Equivalent Rectangular Bandwidth scale by B. Moore and B. Glasberg (Moore/Glasberg 1996)).
In the near future, it is also planned to segment and phonetically label all sound files in order to visualise them in the sonogram window. Some experimental tests have been made with Sonic, a quite sophisticated speech recognizer by Brian Pellom (Pellom 2001) developed at the Colorado University, and tested with very promising results. In this particular case, Sonic is obviously not used to recognize a dialectal language, but to find the phonetic segments and word boundaries through automatic processing that doesn't require human intervention.

AMDV Atlas. Serafina Prest - "il bucato" (the laundry), when there were no washing machines.

AMDV Atlas. Serafina Prest - Courtyard of the Losego village.
6.4. Outlook on the development
The most obvious continuation of the AMDV project will be the creation of an AMDV online version, which would allow interaction via the web and follow current scientific and technological developments, in agreement with the FAIR principles. The audio-visual resources have been prepared to ensure appropriate access and delivery on the web while maintaining the optimal quality of the AMDV material.
Of course, the metadata structures and the web query protocols still need to be improved and completed according to the recent theoretical and technological progress and the recommendations of the W3C (World Wide Web Consortium). The Web Services, i.e. software designed to support interoperability between different computers, are quickly developing simpler REST (Representational State Transfer based communications) compliant systems which use a uniform syntax, self-descriptive metadata and explicit typing for message structure, fields, etc., and can expose any number of facility operations (Fielding/Taylor 2002).
As a minimal example of the REST approach, the syntax of the input/output arguments in a query string to obtain the results as in the documents in Fig. 37-38-39 could be expressed with self-explanatory, unambiguous metadata:
"Search_string": {
"inputs": [
{"name": "string_to_search",
"type": "char",
"purpose": "Search the string in the database"}
],
"outputs": [
{"name": "sorted_output",
"type": "string array",
"purpose": "Return the sorted list of database entries containing the searched string"}
]
}

AMDV Atlas. Some biographical data of the AIS and AMDV informants.
Extraction of the phonetic inventory of the AIS from the real data.
The following lines are the partial output of an automatic procedure to extract all the phonetic symbols of the items captured by the NavigAIS OCR (DEFAULT) and stored in the AISr database. The second column shows the AIS symbol followed by the occurrence number, the hexadecimal and decimal code of the characters and diacritics and a link to graphic examples on the AIS maps.
......................
79 - [ ć ] n. occ.: 606 - code: [Hex: 0063 0301 - Dec.: 99 769 ] link: navigais-web.pd.istc.cnr.it/?map=1187&point=715
80 - [ ć̣ ] n. occ.: 9 - code: [Hex: 0063 0301 0323 - Dec.: 99 769 803 ] link: navigais-web.pd.istc.cnr.it/?map=1187&point=322
81 - [ ć̨ ] n. occ.: 1 - code: [Hex: 0063 0301 0328 - Dec.: 99 769 808 ] link: navigais-web.pd.istc.cnr.it/?map=39&point=333
82 - [ ć̩ ] n. occ.: 3 - code: [Hex: 0063 0301 0329 - Dec.: 99 769 809 ] link: navigais-web.pd.istc.cnr.it/?map=32&point=625
84 - [ c̋ ] n. occ.: 41 - code: [Hex: 0063 030B - Dec.: 99 779 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=319
85 - [ c̩̋ ] n. occ.: 1 - code: [Hex: 0063 030B 0329 - Dec.: 99 779 809 ] link: navigais-web.pd.istc.cnr.it/?map=357&point=29
86 - [ c̩ ] n. occ.: 1 - code: [Hex: 0063 0329 - Dec.: 99 809 ] link: navigais-web.pd.istc.cnr.it/?map=39&point=330
87 - [ d ] n. occ.: 1685 - code: [Hex: 0064 - Dec.: 100 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=818
88 - [ ḍ ] n. occ.: 86 - code: [Hex: 0064 0323 - Dec.: 100 803 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=875
90 - [ e ] n. occ.: 387 - code: [Hex: 0065 - Dec.: 101 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=943
91 - [ è ] n. occ.: 20 - code: [Hex: 0065 0300 - Dec.: 101 768 ] link: navigais-web.pd.istc.cnr.it/?map=1187&point=553
92 - [ ẹ̀ ] n. occ.: 31 - code: [Hex: 0065 0300 0323 - Dec.: 101 768 803 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=581
93 - [ ę̀ ] n. occ.: 35 - code: [Hex: 0065 0300 0328 - Dec.: 101 768 808 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=545
94 - [ è̩ ] n. occ.: 1 - code: [Hex: 0065 0300 0329 - Dec.: 101 768 809 ] link: navigais-web.pd.istc.cnr.it/?map=32&point=354
95 - [ è͈ ] n. occ.: 1 - code: [Hex: 0065 0300 0348 - Dec.: 101 768 840 ] link: navigais-web.pd.istc.cnr.it/?map=712&point=271
96 - [ é ] n. occ.: 67 - code: [Hex: 0065 0301 - Dec.: 101 769 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=792
97 - [ ẹ́ ] n. occ.: 300 - code: [Hex: 0065 0301 0323 - Dec.: 101 769 803 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=765
98 - [ ẹ̫́ ] n. occ.: 1 - code: [Hex: 0065 0301 0323 032B - Dec.: 101 769 803 811 ] link: navigais-web.pd.istc.cnr.it/?map=48&point=329
99 - [ é̤ ] n. occ.: 9 - code: [Hex: 0065 0301 0324 - Dec.: 101 769 804 ] link: navigais-web.pd.istc.cnr.it/?map=430&point=14
100 - [ ę́ ] n. occ.: 362 - code: [Hex: 0065 0301 0328 - Dec.: 101 769 808 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=865
101 - [ é̩ ] n. occ.: 2 - code: [Hex: 0065 0301 0329 - Dec.: 101 769 809 ] link: navigais-web.pd.istc.cnr.it/?map=712&point=44
102 - [ é͈ ] n. occ.: 12 - code: [Hex: 0065 0301 0348 - Dec.: 101 769 840 ] link: navigais-web.pd.istc.cnr.it/?map=1647&point=708
.....................
Output of the automatic procedure for checking the errors in the AIS database
The figure shows the partial output of an automatic check of the content of the AIS Reloaded database (created by the OCR described in DEFAULT). The corresponding link leads to the AIS map and location to check the phonetic sequence and modify it if necessary.
In certain cases, the software can automatically make the correction as in the last line (map 192 point 947) :
192.947 - [ aϑϑoppiçā́re ] Illegal symbol(s): Substitute [ ç ] with [ ʕ ] navigais-web.pd.istc.cnr.it/?map=192&point=947
.....................
Map: K0014 - Char n.= 12137 - Entries n.= 395
...
14.3 - [ sǭrαs̩ ] Check accent: navigais-web.pd.istc.cnr.it/?map=14&point=3
14.11 - [ tųαyα ] Check accent: navigais-web.pd.istc.cnr.it/?map=14&point=11
14.58 - [ suręllį ] Check accent: navigais-web.pd.istc.cnr.it/?map=14&point=58
14.314 - [ tuǜα sọ́; tuǖ̀s sọruǖ́s̩ ] Illegal symbol(s): Substitute [ ü ] with [u] + diacritic: navigais-web.pd.istc.cnr.it/?map=14&point=314
...
Map: K0100 - Char n.= 7001 - Entries n.= 370
...
100.243 - [ ind ̨el pų̄́ls ] Check diacritic sequence: navigais-web.pd.istc.cnr.it/?map=100&point=243
100.311 - [ bọwṣį ] Check accent: navigais-web.pd.istc.cnr.it/?map=100&point=311
...
Map: K0105 - Char n.= 8767 - Entries n.= 396
...
105.142 - [ lāvre ] Check accent: navigais-web.pd.istc.cnr.it/?map=105&point=142
105.190 - [ lä́rfi; ̥ɳ lǟ́rfu ] Check diacritic sequence: navigais-web.pd.istc.cnr.it/?map=105&point=190
...
Map: K0191 - Char n.= 6622 - Entries n.= 369
...
191.58 - [ tsǫp ] Check accent: navigais-web.pd.istc.cnr.it/?map=191&point=58
191.327 - [ s̑wẹ́t; -ẹ́s̑ ̣m. p. ] Check diacritic sequence: navigais-web.pd.istc.cnr.it/?map=191&point=327
191.716 - [ tso pp ] Illegal special char(s) [26, 26,]: navigais-web.pd.istc.cnr.it/?map=191&point=716
...
Map: K0192 - Char n.= 7993 - Entries n.= 360
...
192.73 - [ andā ] Check accent navigais-web.pd.istc.cnr.it/?map=192&point=73
192.947 - [ aϑϑoppiçā́re ] Illegal symbol(s): Substitute [ ç ] with [ ʕ ] navigais-web.pd.istc.cnr.it/?map=192&point=947
.....................
7. Difficulties, solutions and results
The methodology developed to realize the AMDV goals can be briefly summarized in the following table that shows for each topic the related problem(s), the adopted criteria and the given solution(s):

Problem(s) encountered, adopted criteria and related solution(s)
As regards the difficulties, a significant delay in the planned project development was due to the sudden loss of Alberto Zamboni in January 2010. This unexpected event caused the lack of an irreplaceable linguistic-etymological expertise, and also a series of institutional-administrative consequences for the partners of the project (mainly Padua University and ISTC).
A second source of trouble, as regards the ethnographic aspect, was the very limited time that the person in charge of the task (G. Sanga) could devote to the project. The generous cooperation of people, as Carla Gentili (Scheuermeier and AIS study specialist), and the researchers of the "Atlante Linguistico Italiano", the "Museo Etnografico della Provincia di Belluno", and the Bern AIS archives, led to the solution of the problem.
Last but not least, we had to face the difficulties of finding good informants. The selection process involved several people (linguists, students, amateurs, friends, priests, majors, etc.), and, in some occasion, reserved surprises: for example, a 84 old, very interesting subject from the dialectal point of view, was unable to bear the fatigue of the interview for more than one hour. On another occasion, we discovered, at the very beginning of the interview, that the person was incapacitated to speak fluently, having been subjected to a stroke. These misadventures are the consequences of the rapid aging of the population still able to speak in dialects. As it is possible to see in Fig. 45, the average age of the subjects found in the 1921-1922 and 2009-2010 investigations for the Veneto region is respectively 55 and 73 years, with an increase of 18 years for the AMDV project.
Experience has shown that the probability of finding a candidate, who would fit the prerequisites, was inversely proportional to the number of people who have led to the speaker, and, finally, that the best way was to go on site in person and talk to different possible speakers.
The NavigAIS, AMDV and AISr projects integrated old and new perspectives and methodologies:
- A more traditional approach on the basis of the geolinguistic framework, to study the linguistic transformations that occurred in Veneto and Southern Switzerland dialects between 1921-1922 and 2009-2010.
- A more innovative and experimental approach to develop automatic or supervised procedures to collect large amounts of linguistic data, to implement the databases and the related search mechanisms, to segment the audio material and to extract the relevant speech parameters and phonetic mapping data.
- An attempt to implement a system of resources that can grow in accordance with the FAIR principles.
The results obtained go beyond the initial expectations and prove that the synergic combination of these approaches can be very effective to obtain results in a quite limited time, considering that the time could be a decisive factor in the case of dialects and languages in danger of extinction.
The cornerstone of the three projects was the implementation of the NavigAIS, the digital navigable version of the AIS atlas, born to solve some contingent problems of the AMDV project but developed to serve the general interest of the linguistic community independently from the original context.
As to regard the AMDV project, NavigAIS allowed a relevant methodological innovation with on field real time control of the informant responses, and also providing a powerful tool to build the AMDV and AIS Reloaded database.
From the linguistic point of view, the main characteristic of AMDV is the fusion of a set of powerful features (diachronic comparison of the AIS and 2009-2010 lexical corpus, search engine, phonetic tools, etc.), and the integration of the lexical, phonetic, etymological and ethnographic documents, in a homogeneous environment that can express the complexity and richness of the material culture.
Finally, the most significant result obtained so far is the open access to the AIS corpus given by the AIS Reloaded project. The task of indexing the 1.4 million words of the AIS atlas, unthinkable 100 years ago, can now be accomplished.
To conclude, the NavigAIS, AMDV and AIS Reloaded projects are a little, but precious, contribution to rediscover, and save from oblivion, the inestimable heritage of our cultural roots.
8. Acknowledgements
Thanks to:
- Alberto Zamboni, who dedicated the last days of his life to the AMDV project.
- Michele Loporcaro and Stephan Schmid, who believed in the mad enterprise to digitize the entire AIS.
- The whole AIS Reloaded team (Chiara Zanini, Giulia Donzelli, Stefano Negrinelli), and Giacomo Ferrieri, for their help in improving the OCR functionality and for preparing the AIS phonetic inventory.
- The whole AIS Digital Turn team (Giulia Donzelli, Alice Idone, Lisa Gasner, Adriano Salvi) for the final OCR setup.
- Alberto Benin (ISTC), who, despite the Covid-19 pandemic, assured the ISTC server configuration for the NavigAIS needs.
Bibliography
- Ferrero/Genre/Boe/Contini 1979 = Ferrero, F. / Genre, A. / Boe, L. / Contini, M. (1979): Nozioni di fonetica acustica, Torino.
- Fielding/Taylor 2002 = Fielding, Roy / Taylor, Richard (2002): Principled Design of the Modern Web Architecture, in: ACM Transactions on Internet Technology, vol. 2, New York, Association for Computing Machinery, 115-150.
- Goebl 1994 = Goebl, Hans (1994): L’Atlas linguistique du ladin central et des dialectes limitrophes (première partie, ALD-I)., in: Mouton, P.G. (Ed.), Geolingüística. Trabajos europeos., Madrid: Consejo Superior de Investigaciones Científicas, 155-168.
- Goebl 1998 = Goebl, Hans (1998): Atlant linguistich dl ladin dolomitich y di dialec vejins, 1a pert/Atlante linguistico del ladino dolomitico e dei dialetti limitrofi, 1a parte/Sprachatlas des Dolomitenladinischen und angrenzender Dialekte, 1. Teil, Wiesbaden, Reichert.
- Jaberg/Jud 1928 = Jaberg, Karl / Jud, Jakob (1928): Der Sprach- und Sachatlas als Forschungsinstrument. Kritische Grundlegung und Einführung in den Sprach- und Sachatlas Italiens und der Südschweiz, Halle (Saale), Niemeyer.
- Jaberg/Jud 1928-1940b = Jaberg, Karl / Jud, Jakob (Hrsgg.) (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz (AIS), vol. 8, Zofingen, Ringier .
- Jaberg/Jud 1960 = Jaberg, Karl / Jud, Jakob (1960): Index zum Sprach- und Sachatlas Italiens und der Südschweiz. Ein propädeutisches Wörterbuch der italienischen Mundarten., Bern, Stämpfli & Cie.
- Kattenbusch 1998-2016b = Kattenbusch, Dieter (Hrsg.) (1998-2016): Vivaio Acustico delle Lingue e dei Dialetti d'Italia, Berlin, Humboldt-Universität [Ultimo accesso 12/01/2019 ore 10:34] (Link).
- Kramer 1991 = Kramer, Johannes (1991): Etymologisches Wörterbuch des Dolomitenladinischen (EWD), vol. IV, Hamburg, Helmut Buske.
- Krefeld/Lücke 2019 = Krefeld, Thomas / Lücke, Stephan (2019): FAIRNESS – Medien im methodologischen Zentrum der Geolinguistik, in: Berichte aus der digitalen Geolinguistik (II), vol. KIT 9 (Link).
- Levenshtein 1966 = Levenshtein, Vladimir (1966): Binary codes capable of correcting deletions, insertions, and reversals, vol. 10, 8, Soviet Physics Doklady, 707-710 (Link).
- Loporcaro 2009 = Loporcaro, Michele (2009): Profilo linguistico dei dialetti italiani, Bari/Roma, Laterza.
- Loporcaro/Donzelli/Garner/Idone/Salvi/Tisato 2021 = Loporcaro, Michele / Donzelli, Giulia / Garner, Lisa / Idone, Alice / Salvi, Adriano / Tisato, Graziano (2021): AIS, the digital turn (AISdt), University of Zurich.
- Loporcaro/Schmid/Zanini/Pescarini/Donzelli/Negrinelli/Tisato 2021b = Loporcaro, Michele / Schmid, Stephan / Zanini, Chiara / Pescarini, Diego / Donzelli, Giulia / Negrinelli, Stefano / Tisato, Graziano (2021): AIS, reloaded: A digital dialect atlas of Italy and southern Switzerland., in: In: Thibaut, André; Avanzi, Matthieu; Lo Vecchio, Nicolas; Millour, Alice. "Nouveaux regards sur la variation dialectale.", Strasbourg, Editions de Linguistique et de Philologie, 111-136 (Link).
- Lücke 2019 = Lücke, Stephan (2019): Principi FAIR, in: Metodologia, VerbaAlpina-it 19/1 (Link).
- Moore/Glasberg 1996 = Moore, Brian / Glasberg, Brian (1996): A Revision of Zwicker's Loudness Model, vol. 82, Acta Acustica, 335-345.
- Morville 2005 = Morville, Peter (2005): Ambient Findability, O’Reilly Media (Link).
- Mott/Kezich/Tisato 2003 = Mott, Antonella / Kezich, Giovanni / Tisato, Graziano (2003): Il Trentino dei contadini. Piccolo Atlante sonoro della cultura materiale. Le parole e le cose della ricerca di Paul Scheuermeier (1921/1931) e la voci della tradizione di oggi (1998), Museo degli Usi e Costumi della Gente Trentina, San Michele all’Adige (TN) [CDRom - Sistema operativo Windows 95, 98, 98SE, ME, 2000, XP, NT] (Link).
- Negrinelli 2019 = Negrinelli, Stefano (2019): Il progetto AIS reloaded: un archivio sonoro per 36 varietà dialettali della Svizzera meridionale, Arezzo, Proc. XV Conf. AISV 2019 [In Print] (Link).
- Papadopoulos 2005a = Papadopoulos, Alkis (2005a): The Key to Enterprise Search, KM World.
- Pasolini 1975 = Pasolini, Pier Paolo (1975): Pier Paolo Pasolini, Stockholm interview, 30/10/1975, Stockholm, Espresso [From the transcript of Pier Paolo Pasolini's interview, released in Stockholm on 10/30/1975, and published for the first time in the magazine "Espresso" (www.espresso.repubblica.it) on 12/16/2011 - https://espresso.repubblica.it/visioni/cultura/2011/12/16/news/cosi-pasolini-previde-l-italia-di-b-1.38582/] (Link).
- Pellom 2001 = Pellom, Brian (2001): Sonic: The University of Colorado continuous speech recognizer, in: Technical Report TR-CSLR-2001-01, University of Colorado, USA.
- Pfister/Schweickard 1979- b = Pfister, Max / Schweickard, Wolfgang (1979-): Lessico etimologico italiano, bisher 12 Bände, Wiesbaden, Reichert (Link).
- Roberts 1963b = Roberts, Lawrence (1963): Machine perception of three-dimensional solids, Massachusetts Institute of Technology, Dept. of Electrical Engineering (Link).
- Scheuermeier 1943 = Scheuermeier, Paul (1943): Bauernwerk in Italien, der italienischen und rätoromanischen Schweiz, vol. 1-2, Rentsch, Erlenbach-Zürich.
- Telmon/Canobbio 1985 = Telmon, Tullio / Canobbio, Sabina (Hrsgg.) (1985): Atlante Linguistico ed Etnografico del Piemonte Occidentale - ALEPO, Torino, CELID, Regione Piemonte.
- Tisato 2010 = Tisato, Graziano (2010): NavigAIS – AIS Digital Atlas and Navigation Software, Naples, Bulzoni ed., Roma, Proc, IX Conf. AISV 2010, 451-461 (Link).
- Tisato 2015 = Tisato, Graziano (2015): Documenti etnolinguistici navigabili e ‘parlanti’: l’approccio di NavigAIS e dell’Atlante Multimediale dei Dialetti Veneti, vol. Atti del Convegno Intern. di Studi Archivi Etnolinguistici Multimediali, Vol. 39, Torino, F. Cugno, L. Mantovani, M. Rivoira., eds, Bollettino dell'Atlante Linguistico Italiano, Proc. of “Lingue e le Culture della Montagna”, 59-82.
- Tisato 2019 = Tisato, Graziano (2019): Acquisizione Digitale dell’Intero AIS, Arezzo, Proc. XV Conf. AISV 2019, 131-153 [In Print] (Link).
- Tisato/Barbierato/Ferrieri/Gentili/Vigolo 2013 = Tisato, Graziano / Barbierato, Paola / Ferrieri, Giacomo / Gentili, Carla / Vigolo, Maria Teresa (2013): Atlante Multimediale dei Dialetti Veneti, Venezia, Bulzoni ed., Roma, Proc. IX Conf. AISV 2010, 445-462.
- Tisato/Vigolo 2016 = Tisato, Graziano / Vigolo, Maria Teresa (2016): Dagli Atlanti storici agli Atlanti multimediali: il NavigAIS e l'AMDV (Atlante Multimediale dei Dialetti Veneti), in: Francesco Avolio e Antonino Cigno ed. - Atti del Convegno Internazionale di Studi - Archivi Etnolinguistici Multimediali, Pescara, Museo delle Genti d’Abruzzo, 96-123.
- Vithlani/Kumbharana 2015 = Vithlani, Purna / Kumbharana, C.K. (2015): Comparative Study of Character Recognition Tools, vol. 118, 9, International Journal of Computer Applications, 31-36 (Link).
- Wilkinson u.a. 2016 = Wilkinson, Mark D. / Dumontier, Michel / Aalbersberg, IJsbrand Jan / Appleton, Gabrielle / Axton, Myles / Baak, Arie / Blomberg, Niklas / Boiten, Jan-Willem / da Silva Santos, Luiz Bonino / Bourne, Philip E u.a. (2016): The FAIR Guiding Principles for scientific data management and stewardship, in: Scientific data, vol. 3, Nature Publishing Group (Link).
- Zamboni 1974 = Zamboni, Alberto (1974): Veneto, Pisa, Pacini Editore [Profilo dei dialetti italiani 5].
- Zamboni 1984 = Zamboni, Alberto (1984): I dialetti cadorini, in: B. Pellegrini e S. Sacco ed., Il ladino bellunese. Atti del Convegno Internazionale (Belluno 2-4 giugno 1983). , Belluno, 45-83.
- Zamboni/Vigolo 2011 = Zamboni, Alberto / Vigolo, Maria Teresa (2011): Tra nomi e cose. Commenti lessicali e onomasiologici allo Scheuermeier veneto, in: Perco D., Sanga G., Vigolo M. T., Ed., Paul Scheuermeier, Il Veneto dei contadini 1921-1932, Vicenza, 67-87.
- Zipf 1949a = Zipf, George Kingsley (1949): Human Behavior and the Principle of Least Effort. An Introduction to Human Ecology, Cambridge.
- Zwicker 1961 = Zwicker, Eberhard (1961): Subdivision of the audible frequency range into critical bands, vol. 33, The Journal of the Acoustical Society of America.
- Graziano Tisato (AMDV project & direction, database and software implementation)
- Maria Teresa Vigolo, Paola Barbierato (etymological research)
- Alberto Zamboni, Laura Vanelli, Enzo Croatto, Vincenzo Galatà, Giovanni Tomasi, John Trumper, Giorgio Vedovelli (linguistic supervision)
- Vincenza Castellani (AIS lemma transcription)
- Giacomo Ferrieri (phonetic transcription)
- Carla Gentili (AIS legend translation)
- Daniela Perco, Glauco Sanga (ethnographic consultants)
It had also the merit of rediscovering the Scheuermeier work from an ethnographic point of view.
• "Il Trentino dei Contadini"- Piccolo atlante sonoro della cultura materiale: le parole e le cose della ricerca di Paul Scheuermeier (1921-1931) e le voci della tradizione di oggi (1998).
(English translation):
• "The Trentino of the Peasants" - Small talking atlas of material culture: the words and the things of the Paul Scheuermeier research (1921-1931) and the voices of today's tradition (1998).
Oh Lord! If I'm guilty of anything, it's only right that I die, but, if I'm innocent, you must save me!
At that same moment the machine gun jammed!
The priest, who had confessed the condemned, came forward and said that no one else was to die that day.
And Giorgio survived!