
1. Geolinguistik
Geolinguistik, um die es geht, thematisiert Sprache in ihrer Verflechtung mit dem Raum. Diese Verflechtung ist eng, d.h. durchaus substantiell, und vielfältig: Sprachen prägen Räume insofern bestimmte Sprachen in bestimmten Räumen für bestimmte Zwecke vorgegeben sein können, wie es in staatlichen Territorien der Fall ist. In meist kleineren Arealen, d.h. in nicht staatlich verfassten Gebieten können lokale Sprachen und/oder Dialekte traditionell üblich sein. Andererseits setzen Räume, genauer gesagt: ihre Bewohner:innen Dynamiken frei, die zu sprachlicher Variation und zu Sprachwandel führen. Im Hinblick auf Sprachen sind Räume nicht als geographisch sondern als kommunikativ zu fassen und auf der Grundlage von drei Instanzen zu modellieren: den sozialen Institutionen, den darin agierenden Individuen und ihrem jeweiligen Verhalten. Zu unterscheiden ist, mit anderen Worten, der historische Raum verwandter und/oder unverwandter Sprachen, der epistemische Raum diverser Sprecher:innen sowie der pragmatische und mediale Raum des Sprechens (vgl. zur Anwendung dieses Modells auf die Romania Krefeld 2023a und Krefeld 2024a).
Eine isolierte Betrachtung sprachlicher Systeme kann den komplexen Ansprüchen einer raumorientierten Modellierung nicht genügen. Im Sinne der von Saussure fomulierten Alternative kann es in der Geolinguistik grundsätzlich nicht um “la langue envisagée en elle-même et pour elle-même” (Saussure 1972, 317) gehen, sondern ausschließlich um “une science qui étudie la vie des signes au sein de la vie sociale” (Saussure 1972, 33). Der Ort der Geolinguistik liegt somit im Schnittpunkt mehrerer linguistischer Teildisziplinen (und je nach Fachauffassung womöglich noch anderer mehr):
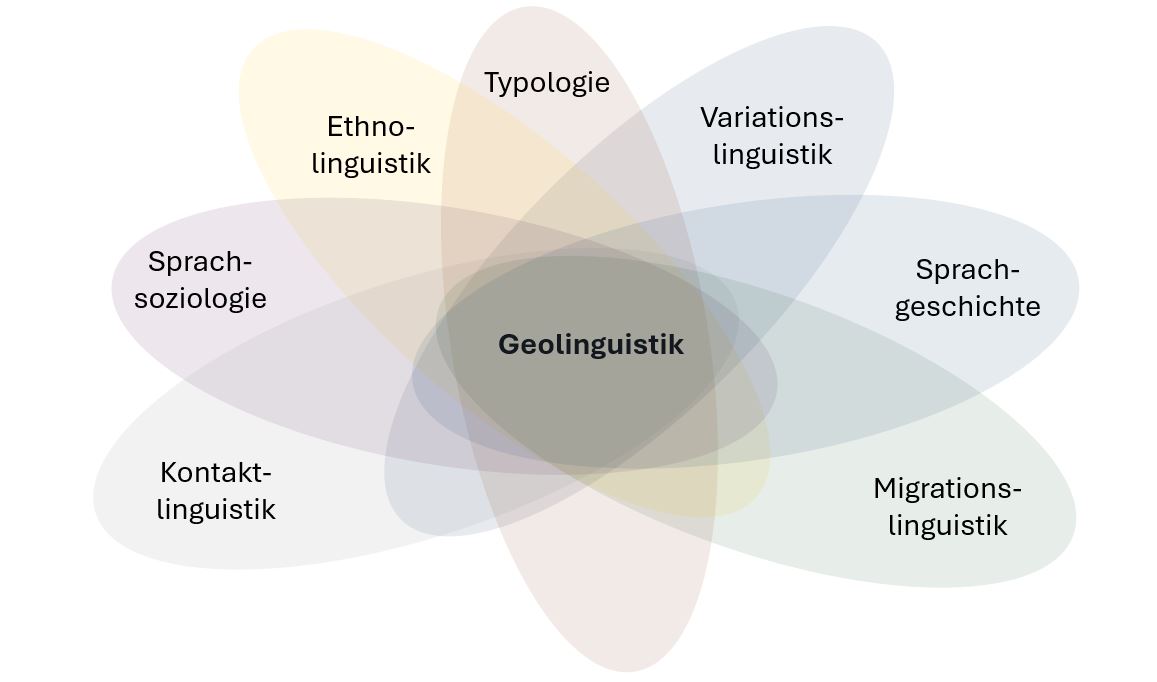
Der traditionelle Forschungskern der Geolinguistik ist indes in einem engen Teilbereich zentriert, nämlich in der Dialektologie. Sie beginnt etwa gleichzeitig in Italien und Bayern mit den großen Dialektwörterbüchern von Francesco Cherubini (1814) und Johann Andreas Schmeller (1821) und entwickelt einige Jahrzehnte später ihre Königsdisziplin in Gestalt der Sprachatlanten, einer Gattung, die sich in ihrer außerordentlichen Weitläufigkeit als sehr produktiv erwiesen hat (vgl. zum nicht mehr ganz aktuellen Überblick Winkelmann/Lausberg 2001, Cugno/Massobrio 2010a und Cugno/Massobrio 2010b). Andere Schwerpunkte der dialektologischen Forschung sind die bereits erwähnten Wörterbücher sowie grammatische Beschreibungen lokaler/regionaler Dialekte; das allgemein übergeordnete Ziel ist zweifellos die Sprachdokumentation.
2. Drei Generationen von Atlanten
In der genuin dialektologischen Gattung der Atlanten lassen sich recht deutlich drei Generationen unterscheiden (vgl. Krefeld 2021h). Die erste, gewissermaßen heroische Generation hat die großen, nationalen Referenzatlanten hervorgebracht (z.B. ALF, ALC, AIS). Die zweite Generation, die durch Harald Thun auf den Weg gebracht wurde, hat die dialektinterne, nämlich diagenerationelle, diastratische usw. Variation entdeckt und methodologisch in Gestalt pluridimensionaler Atlanten umgesetzt (z.B. ADDU, ALS und neuerdings ALiB 2014-); dabei kommt auch verstärkt die räumliche Dimension auf der Ebene der Dachvarietäten (italiani regionali, français régionaux usw.) in den Blick . Die dritte Generation steht ganz im Zeichen der digitalen Medien und arbeitet an der Überführung der Atlanten in die Digital Humanities (z.B. Verba Alpina). Es ist allerdings keineswegs so, dass eine nachfolgende die jeweils vorige Generation ersetzt; vielmehr werden aktuell Projekte aller drei Generationen parallel zueinander durchgeführt. Immerhin ist abzusehen, dass
- die Methodologie der ersten Generation bald allgemein als überholt angesehen werden wird;
- die Methodologie der zweiten Generation in der dritten weitergeführt wird;
- die jeweils erhobenen Datenbestände aller drei Generationen in der dritten zusammengeführt werden.
In diesem Sinne ist die folgende Graphik zu verstehen:
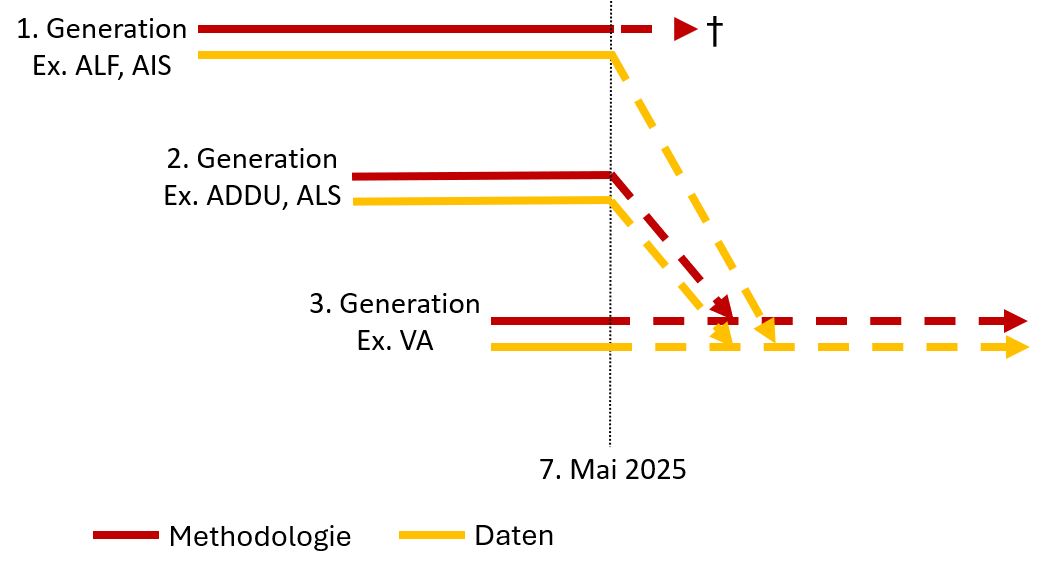
Die drei Generationen romanischer Sprachatlanten
Die romanischen Sprachatlanten bilden also insgesamt – sowohl im Hinblick auf die untersuchten Gebiete wie auch auf die erfassten Phänomenbereiche – ein einziges, unabgeschlossenes und unabschließbares Projekt; daher hat die integrative Perspektive, die durch die noch nicht sehr weit verbreitete Methodologie der dritten Generation eröffnet wird, besonderes Interesse verdient.
3. Die Perspektive der 3. Generation: ein virtuelles geolinguistisches Observatorium
Einstweilen kann man nicht umhin, eine deutliche Diskrepanz zwischen den technischen Möglichkeiten und ihrer tatsächlichen Nutzung zu konstatieren: So ist in letzter Zeit technisch vieles umgesetzt worden, was den etablierten Forschungszielen der zweiten und teils wohl auch schon der ersten Generation nicht nur entspricht, sondern ihre Verwirklichung ganz erheblich befördert. Das gilt insbesondere für das übergeordnete Ziel der Dokumentation räumlicher Variation. Denn während in traditionellen Atlanten fest begrenzte, statische Datenbestände erhoben und publiziert wurden, bietet sich nun die Chance offene, kontinuierlich erweiterbare Korpora bereitzustellen.1 Es lassen sich im Sinne der pluridimensionalen Dialektologie unterschiedliche Gruppen von Sprecher:innen und eine breite Palette onomasiologischer Felder erfassen. Die ganze Problematik lässt sich am AIS exemplarisch demonstrieren.
3.1. Retrodigitalisierung defizitärer Quellen
Der AIS ist der prototypische Atlas der ersten Generation (vgl. Krefeld 2019ar); er repräsentiert einen umnfangreichen Datenbestand, der für die Italoromania und darüber hinaus bis heute eine zentrale empirische Referenz geblieben ist. Er wurde mehrfach in unterschiedlichen Phasen retrodigitalisiert (vgl. NavigAIS und AISr) und bildet auch die Grundlage hoch elaborierter dialektometrischer Auswertungen, die in suggestiver Gestalt visualisiert werden (vgl. Scherrer 2019, Link). Man darf allerdings nicht vergessen, dass der Datenbestand aus den 20er Jahren des 20. Jahrhunderts stammt, und bereits zur Zeit der Erhebung überwiegend die ältere Generation der Sprecher:innen abbildete (vgl. Krefeld 2019ar, Link). Die Daten sind jedoch noch in anderer Hinsicht zu relativieren:
- Es wurde mit einem Fragebuch gearbeitet, das sich an der vorindustriellen bäuerlichen Lebenswelt orientierte; zwar wurden auch systematisch die Stadtdialekte erfasst, allerdings ohne die damalige städtische Lebenswelt zu berücksichtigen; ebenso vernachlässigt wurden die modernen Aspekte des zeitgenössischen ländlichen Lebens wie z.B. die Elektriztität, die Automobile, die Eisenbahn usw. (vgl. dazu Krefeld 2022h). Es wäre nämlich durchaus ein Irrtum zu glauben, dass im Fall moderner Konzepte keine räumliche Variation der Bezeichnungen aufträte2. Eine Beschränkung auf retrodigitalisierte Materialien kann daher zur unangemessenen Folklorisierung der Dialekte (und Kleinsprachen) beitragen.
- Es wurde das Nachkriegsitalien erfasst - einschließlich der Gegenden, die zum Zeitpunkt der Erhebung erst seit wenigen Jahren durch die italienische Standardsprache überdacht wurden, wie z.B. das Kerngebiet des Dolomitenladinischen. Inzwischen ist das in diesem Gebiet seit mehreren Generationen der Fall; alle Sprecher:innen sind je nach Provinz zwei- oder dreisprachig, so dass heute im individuellen Repertoire mit starker Dominanz des Italienischen und/oder – in der Provinz Bozen – des Deutschen und entsprechenden Entlehnungsvarianten zu rechnen ist.
Sobald die retrodigitalisierten Bestände jedoch in strukturierte und offene Korpora eingehen, können sie durch rezente Daten und eventuell durch onomasiologisch womöglich anders ausgerichtete zeitgenössische Daten einer anderer Quelle ergänzt werden, wie z.B. in vielleicht ferner, aber wünschenswerter Zukunft der AIS durch den immer noch vollkommen papierenen ALI. So würde die Dokumentation aus der jeweils projektspezifischen selektiven Verengung befreit. Das konsequente und realisierbare Ziel ist der Aufbau eines projektübergreifenden, allumfassenden geolinguistischen Observatoriums3 in Gestalt eines Online-Dienstes, und zwar nicht im Sinne einer reinen Musealisierung historischer Varietäten, sondern als dynamisches Observatorium aktueller sprachlicher Variation. Ein solches Observatorium böte auch Platz für die Dokumentation aktueller räumlicher Variation in der Schriftlichkeit, wie sie zum Beispiel das DWDS 2004 anbietet4. Es dürfte nun auch klar geworden sein, dass genau dieses Ziel den Fluchtpunkt, der im Titel des vorliegenden Beitrags indizierten Perspektive bildet.
3.2. Optionen und Voraussetzungen eines Online-Observatoriums
Mindestens vier Optionen werden durch ein Online-Observatorium eröffnet: (1) eine maximale Aggregation relevanter Quellen, (2) eine quasi unbegrenzte Kooperation mit anderen Wissenschaftlern und Projekten, (3) die Erhebung neuer Daten durch Crowdsourcing und schließlich (4) die direkte, verlagsunabhängige Publikation.
Trotz dieses ebenso naheliegenden wie vielversprechenden neuen Horizonts, der sich mit der Verlagerung der Forschungsarbeit ins Internet auftut, zögern viele Projekte sich die technischen und methodologischen Neuerungen in konsequenter Weise zu eigen zu machen. Der Grund dafür dürfte darin liegen, dass einige juristische, methodologische und institutionelle Voraussetzungen gegeben sein müssen. Die allgemeine juristische Vorbedingung besteht in der Verwendung offener Lizenzen, möglichst CC BY-SA (nicht NC!), anstatt des klassischen Copyrights ©.
Institutioneller Art sind die universitären Rahmenbedingungen, die einer intensiven und ausgewogenen Kooperation zwischen Linguisten/Romanisten und Spezialisten der Informationstechnik oft im Wege stehen. An der LMU München, wo ich bis zum Eintritt in den Ruhestand (1. April 2021) beschäftigt war, gab und gibt es eine IT-Gruppe Geisteswissenschaften (ITG), die sich (auch) als Center for Digital Humanities versteht (Link). Sie ist die Voraussetzung für die erforderliche paritätische Beantragung und Durchführung einschlägiger Projekte;5 das Interesse für genuin romanistische (und andere geisteswissenschaftliche) Projekte ist ansonsten weder in informatischen noch in computerlinguistischen Instituten keineswegs selbstverständlich.
Die methodologischen Optionen und Voraussetzungen werden im Folgenden mit Referenz auf das Projekt Verba Alpina skizziert, wo die Realisierbarkeit grundsätzlich unter Beweis gestellt und vor dem Hintergrund der Wissenschaftskommunikation im Web (vgl. Krefeld 2023n) reflektiert wurde.
3.2.1. Voraussetzung: die FAIR-Prinzipien
Mit dem nützlichen englischen Akronym FAIR werden vier generelle Voraussetzungen für konstruktive web-basierter Forschung identifiziert, die auch wissenschaftsethischen Prinzipien entsprechen. Sie fordern, dass alle Forschungsdaten findbar (F = findable), zugänglich (A = accessible), interoperabel (I = interoperable) und nachnutzbar (R = reusable) sein müssen. Diese Attribute sind zwar intuitiv einleuchtend, aber nicht trennscharf, sondern miteinander verflochten (vgl. Englmeier/Lücke 2023 und Krefeld/Lücke 2023a). In der Entwicklungsperspektive der Digital Humanities lässt sich ihr Verhältnis wie folgt skizzieren: Den wissenschaftlichen Kern bildet zweifellos die Interoperabilität (I); sie ist freilich nur dann gewährleistet, wenn die Daten auch aus rechtlicher Sicht zugänglich sind und genutzt werden dürfen (A). Da ein Projekt jedoch, wenn überhaupt, nur bedingt absehen kann, wer die bereitgestellten Daten und Ergebnisse nutzen möchte, muss ihre Findbarkeit (F) für menschliche Nutzer und für Maschinen gegeben sein. Für die jeweilige Disziplin ist jedoch entscheidend, dass die Verfügbarkeit der Forschungsdaten und -ergebnisse über das Projektende hinaus langfristig gesichert ist; deshalb ist die Nachnutzbarkeit (R) das eigentlich übergeordnete Ziel. Sie liegt jedoch letztlich nicht mehr in der Hand der jeweiligen Projektleiter, sondern in der Verantwortung der Personen, besser: Einrichtungen, von denen die Daten gehostet werden:
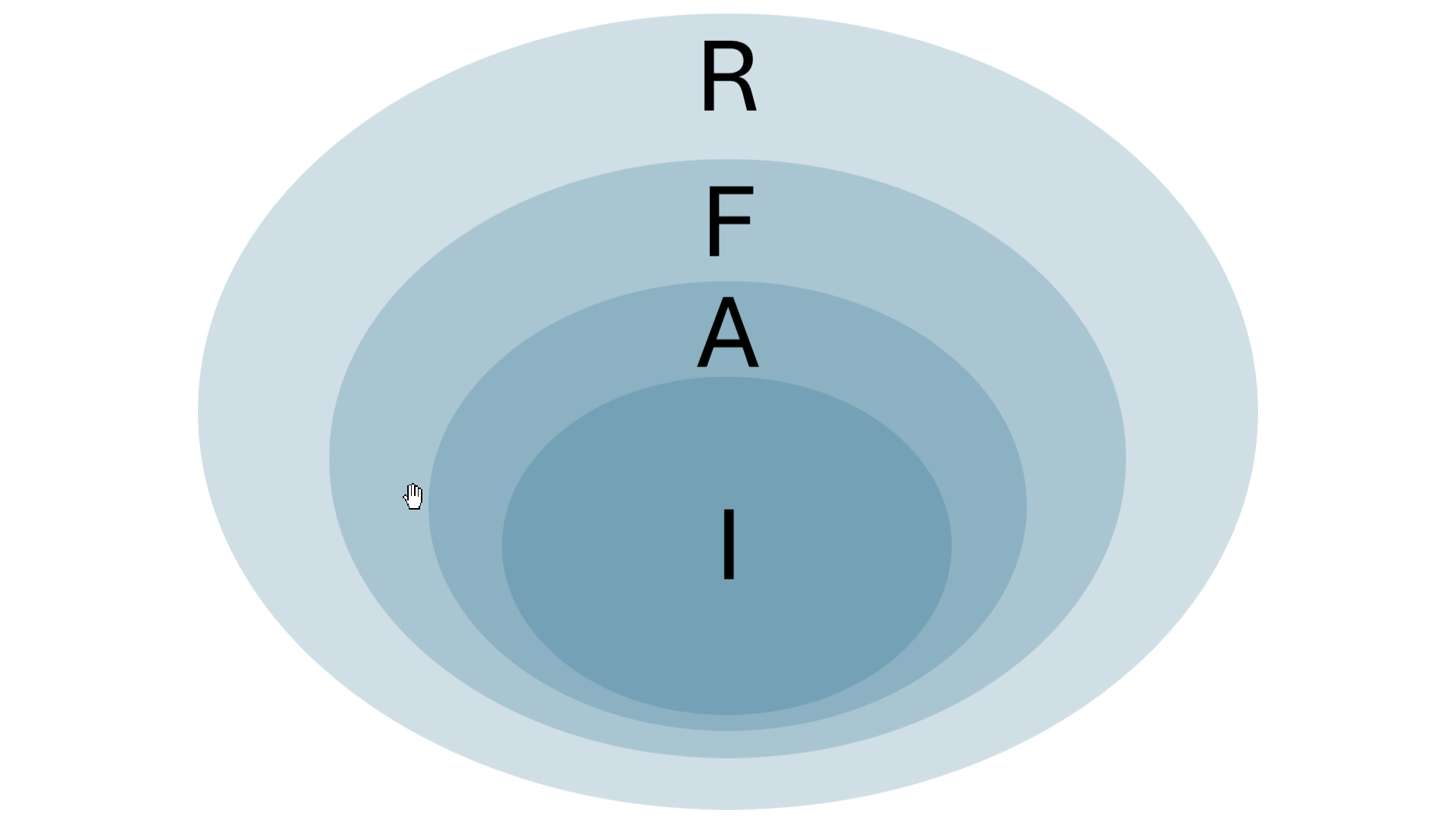
Interoperabilität (I) als Kern web-basierter empirischer Forschung
Die technische Umsetzung de FAIR-Prinzipien wird in der folgenden Skizze der vier Optionen präzisiert (vgl. auch Krefeld/Lücke 2022c).
3.2.2. Option I: Maximale Aggregation relevanter Quellen
Bereits erwähnt wurde die maximale Aggregation geolinguistisch relevanter Quellen, d.h. solcher Quellen, deren Material georeferenzierbar ist; Referenzeinheit ist die politische Gemeinde.6 In Verba Alpina wurden unterschiedliche Typen derartiger Quellen zusammengeführt. Geradezu selbstverständlich waren zunächst bereits publizierte Sprachatlanten des Alpenraums; darüber hinaus wurden auch die Wörterbücher ausgewertet, deren Daten räumlich hinreichend präzise spezifiziert werden (vgl. den Überblick unter https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=232&tk=5191. Tatsächlich wurden die exemplarischen romanischen Dialekt- und Kleinsprachwörterbücher tatsächlich in der der Logik von Atlanten angelegt, so dass sich die Materialien im Zuge ihrer Retrodigitalisierung auch georeferenzieren und kartographisch visualisieren lassen. Die folgende Karte zeigt die sehr dichten Erhebungsnetze des DRG und des VSI, die im Rahmen von Verba Alpina georeferenziert wurden, in Verbindung mit den AIS-Punkten, so dass Daten beider Wörterbücher gemeinsam mit Atlasdaten gezeigt werden können:
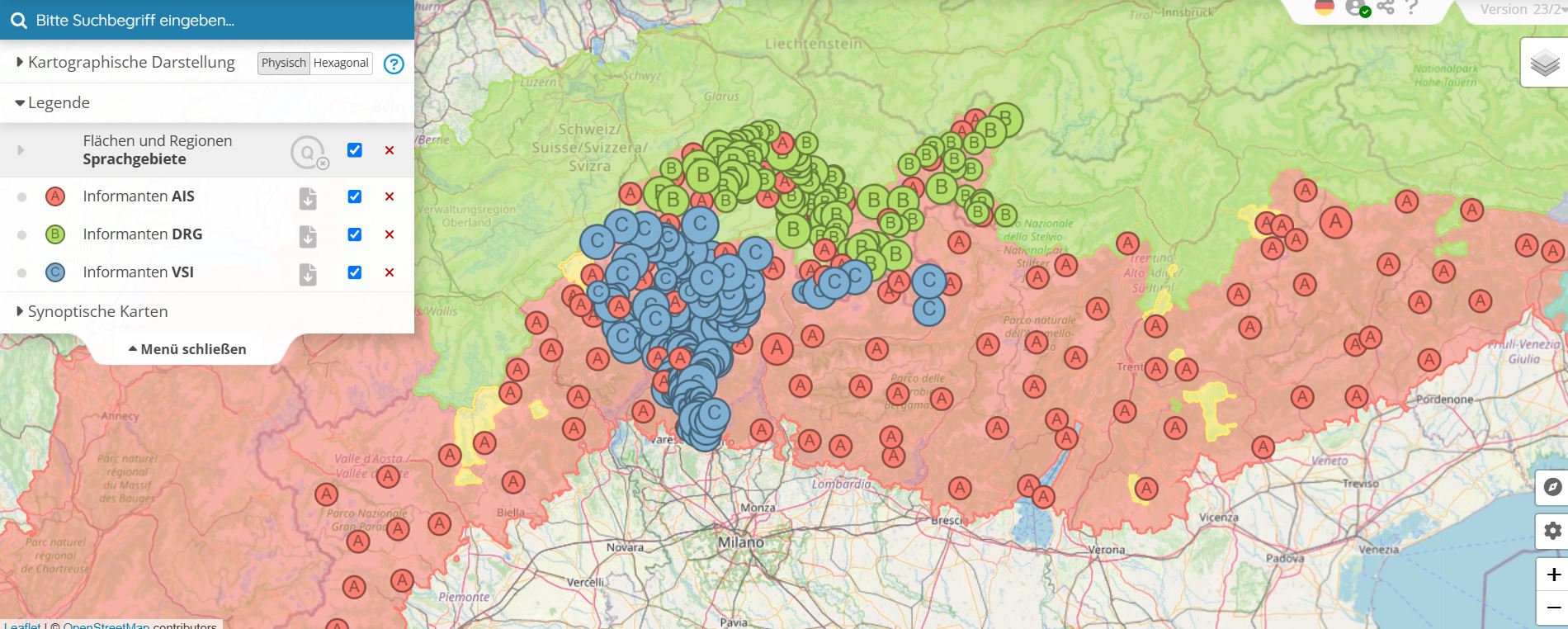
Beispiel einer synoptischen Karte ausgewählter Erhebungsnetze von Wörterbüchern (DRG, VSI) und eines Atlas’ (AIS)
Als dritter Typ kommen die über das Projektportal mittels Crowdsourcing neu erhobenen Daten hinzu (vgl. u. Option III).
Es muss grundsätzlich zwischen Input-Daten und Output-Daten unterschieden werden. Die umfangreichen nicht selbst erhobenen Input-Materialien wurden zu einem großen Teil erst von Verba Alpina im Zuge der Retrodigitalisierung in digitale Daten verwandelt, die im Output, an der Nutzerschnittstelle von Verba Alpina, den FAIR-Prinzipien entsprechen; für dies Aufbereitung, die größten Teils ‘von Hand’ erfolgen musste, wurden spezielle Tools entwickelt. So ist es bei der Aggregation wichtig, Regeln für den Umgang mit den oft unterschiedlichen Transkriptionssystemen der Quellen zu entwickeln. Es wird eine Doppelstrategie empfohlen, einerseits im Sinne der Quellentreue die Originaltranskription zu erhalten und andererseits im Sinne der Nutzerfreundlichkeit eine Einheitstranskription anzubieten (vgl. Krefeld 2023o). Ein Einzelbeleg (hier aus dem ALF) präsentiert sich in der folgenden Art (das Fenster öffnet sich durch Anklicken des Kartensymbols):
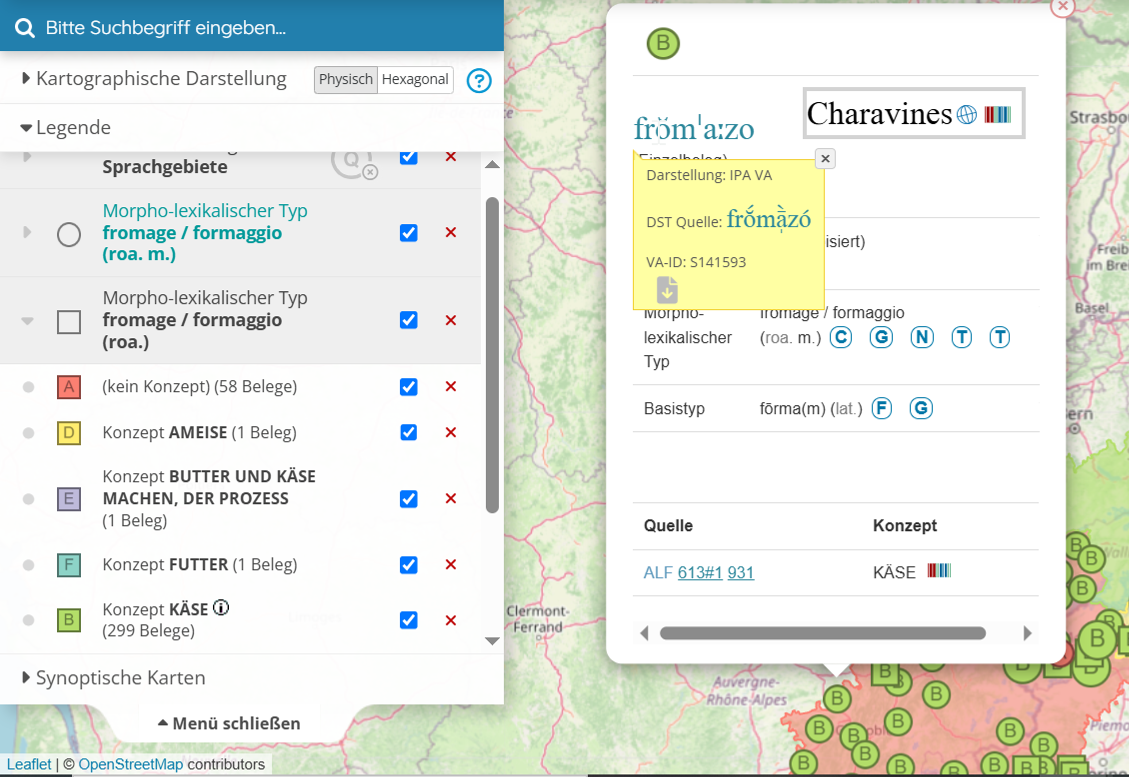
Proprietäre Input- und einheitliche Output-Transkription (IPA) in Verba Alpina (Original https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=232&tk=5188)
Das Belegfenster aus Abb. 4 gibt zahlreiche Hinweise auf die Strukturierung der Daten im Sinne der Interoperabilität (I) und damit indirekt auch der Nachnutzbarkeit (R). Ein wichtiges Kriterium ist zunächst die feine Granulierung der Daten sowie der Einsatz von Identifikatoren oder ‘Normdaten’ (vgl. Zacherl 2023c); dabei kommen projekteigene (VA-ID ...) und importierte, projektexterne Identifikatoren (IDs) zum Einsatz, speziell aus den Diensten geonames.org (![]() ) und Wikidata.org (
) und Wikidata.org (![]() ) . Die Abb. 5 zeigt, dass auch die sprachlichen Typen, mit denen VerbaAlpina operiert, im Sinne der Interoperabilität (I) und der Nachnutzbarkeit (R) durch IDs angesprochen werden:
) . Die Abb. 5 zeigt, dass auch die sprachlichen Typen, mit denen VerbaAlpina operiert, im Sinne der Interoperabilität (I) und der Nachnutzbarkeit (R) durch IDs angesprochen werden:
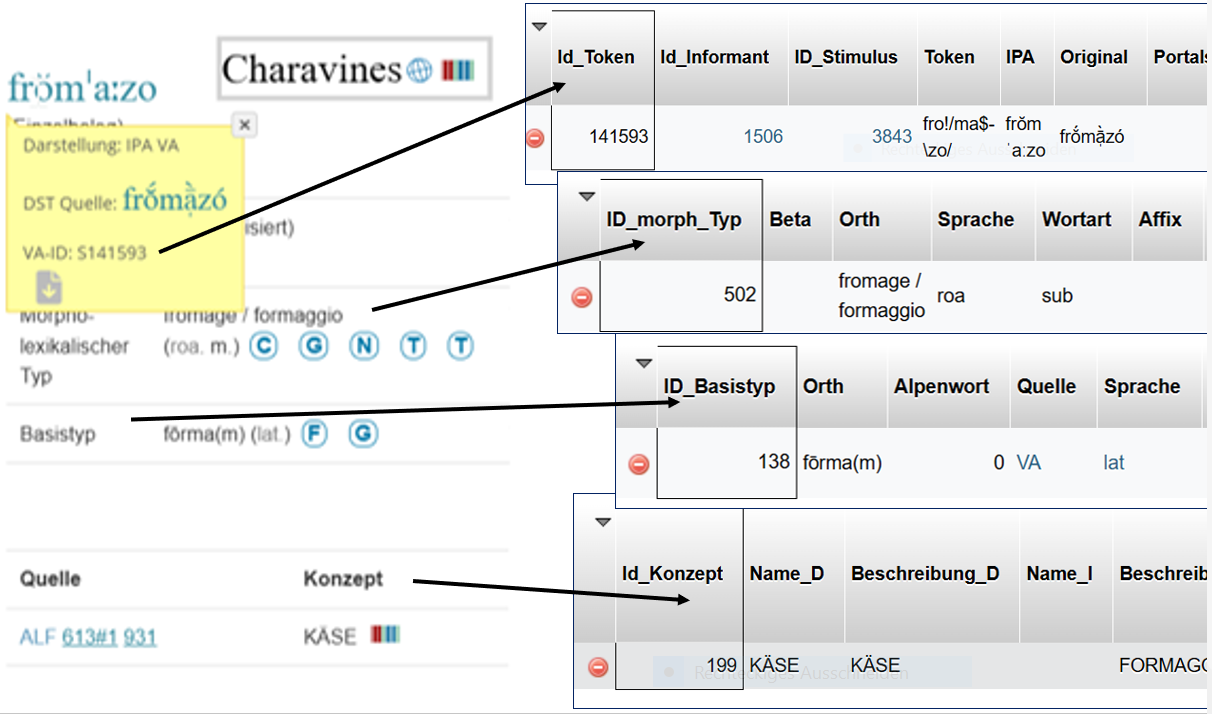
Belegfenster aus Abb. 4 und die zugeordneten IDs
3.2.3. Option II: Kooperation von Projekten
Die zentrale und grundlegende Bedeutung der FAIR-Prinzipien zeigt sich auch in anderen der hier herausgestellten Optionen. Ganz evident ist ihre Bedeutung für die Kooperation; denn sie repräsentieren eigentlich Kooperationsregeln. Allerdings sind verschiedene Formen der Zusammenarbeit zu unterscheiden. Die prototypische Ausprägung ist zweifellos interaktiver Natur: Daten und Reflexionen werden zwischen Projekten und/oder einzelnen Wissenschaftlern ausgetauscht. Nach dem bereits Ausgeführten ist klar, das dieser gegenseitige Wissenstransfer ganz selbstverständlich funktionieren kann, sobald die Zugänglichkeit (A) und Interoperabilität (I) gewährleistet sind. Projekte können auf der Basis ihrer Findbarkeit (F) aktive Akquise von Projektpartnern betreiben oder aber gewissermaßen passiv ihrerseits als Partner gefunden werden.
VerbaAlpina hat mit zahlreichen anderen Projekte formelle Kooperationsvereinbarungen getroffen (vgl. die Übersicht unter https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=185&db=xxx sowie das Textformular unter 2016_definitive_fassung_kooperationsvereinbarung_dt). Daraus hat sich in einigen Fällen eine sehr produktive Zusammenarbeit ergeben; genannt seien der ALD, VinKo und AlpiLink. Allen Partnerprojekten wurden in der virtuellen Umgebung von VerbaAlpina eigene Datenbanken eingerichtet, mit der Option Daten hochzuladen und zu bearbeiten; die Spielregeln sahen vor, dass jeder Partner alle Daten eines jedes Partners nutzen konnte, ohne sie jedoch irgendwie ändern zu können. Manche Partner haben ihren gesamten Datenbestand zur Verfügung gestellt haben,obwohl nur ein Teil der Daten überhaupt relevant war. Exemplarisch war der ALD, der über diese Art der Kooperation einen redundanten Speicherort seines Materials erhalten hat. So dient diese Kooperation nicht nur der Datenaggregation sondern auch einer konstruktiven Weiterentwicklung der Disziplin. Es erscheint deshalb im Hinblick auf die Nachnutzbarkeit (R) sinnvoll, den Begriff der Kooperation sehr weit, nämlich im Sinne eines virtuellen Kooperationsangebots zu fassen, das sich an alle Projekte mit hinreichenden empirischen und/oder methodologischen Überschneidungen richtet. Es ist ja gar nicht abzusehen, wer sich - unter Umständen viele Jahre - nach dem Auslaufen eines Projekts für die Projektdaten interessiert wird. In dieser Hinsicht unterscheiden sich Daten aus den Humanities sehr scharf von naturwissenschaftlichen Daten, die unter Umständen vollkommen veralten und irrelevant werden können.7
3.2.4. Option III: Crowdsourcing
Seit Durchsetzung der sozialen Medien und speziell der flächendeckenden Verbreitung von Smartphones, hat sich auch ein vollkommen neuer Horizont für Datenerhebungen ergeben. Denn es ist möglich direkt aus der Forschungsumgebung heraus Informant:innen zu suchen und darüber hinaus über einen längeren Zeitraum mit ihnen in Kontakt zu bleiben. Es bietet sich weiterhin an, die Nutzer für andere Zwecke einzusetzen, wie es in der Citizen Science-Bewegung (oder Bürgerwissenschaft) praktiziert wird. So können bereits vorhandene Daten perzeptiv evaluiert, durch Audiofassungen angereichert oder womöglich in umgekehrter Richtung vorhandene Audiodaten transliteriert, wenn nicht transkribiert werden usw. Die Einbindung von Internetnutzern für die Gewinnung von Forschungsdaten wird gewöhnlich als crowdsourcing bezeichnet. Im Rahmen von VerbaAlpina wurden auf diese Weise zwischen 2017 und 2023 insgesamt 33179 sprachliche Formen von 2475 Teilnehmern erhoben (vgl. https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=4629&db=xxx sowie die Darstellung der Vorgehensweise unter https://www.verba-alpina.gwi.uni-muenchen.de/en/?page_id=1741&db=xxx).
3.2.5. Option IV: direkte, verlagsunabhängige Publikation
Die FAIR-Prinzipien sind - wie oben gesagt - nicht nur Kooperationsregeln; sie implizieren auch einen radikalen Bruch mit den traditionellen Publikationsgewohnheiten, denn das gesamte Internet ist eine gigantische Publikationsmaschine, die Code, Daten, analytischen Text, Audio- und Videodokumente zur Verfügung stellt. Während Findbarkeit (F) und Zugänglichkeit (A) auch im Fall von Printpublikationen gegeben sein müssen, ist eine direkte Interoperabilität zwischen papiergebundener Forschung und web-basierter Forschung nicht möglich. Die vierte Option eines geolinguistischen Online-Observatoriums, d.h. die Online-Publikation, ist also eigentlich selbstverständlich (vgl. Krefeld 2023b). Dennoch findet die verlagsunabhängige Publikation von wissenschaftlichem Diskurs, die ja ohne weiteres direkt aus den Projekten heraus erfolgen kann, noch keine mehrheitliche Akzeptanz. Das gilt erstaunlicherweise auch für Forscher:innen, die ansonsten Webtechnologie durchaus nutzen. Wie es scheint, ist diese Zurückhaltung Ausdruck mehrerer, zusammenwirkender Faktoren, so die Vorstellung fehlender Qualitätssicherung, textueller Instabilität. prekärer Dauerhaftigkeit sowie das überkommene Prestige des gedruckten Buchs. Am schwersten wiegt jedoch vermutlich eine historisch tief verwurzelte Medienvergessenheit der Sprachwissenschaft: Medien werden von romanistischen (und anderen) Linguisten traditionell als etwas Sekundäres, Akzidentelles betrachtet, das mit der eigentlichen Forschungsarbeit nichts zu tun habe und lediglich nach deren Abschluss für die Publikation benötigt werde. Diese Haltung hat dazu geführt, dass die Chancen der virtuellen Publikation methodologisch unreflektiert bleiben. Symptomatisch ist der Umgang der wenigen verbliebenen wissenschaftlichen Verlage, die von den Wissenschaftlern in der Regel sämtliche Rechte einfordern und die ihre Printpublikationen parallel oder zeitlich nachgeordnet auch im pdf-Format veröffentlichen. Dieses Format hat zwar den Vorzug schnell und einfach produziert werden zu können; aber es bleibt letztlich der Tradition des linear von einer Seite zur nächsten voranschreitenden Textes verbunden, wie er durch den Druck kanonisiert wurde. Der virtuellen Publikation einzig angemessen ist jedoch die hypertextuelle Konzeption der Veröffentlichung. Referenzeinheit ist in diesem Rahmen nicht die rein materiell definierte Seite, sondern eine inhaltlich definierte Einheit, die als digitales Objekt gezielt angesprochen werden kann, also z.B. ein Absatz8, ein Stichwort, ein Wörterbuchartikel, ein Begriff, eine Karte usw. Alle diese digitalen Einheiten können leicht miteinander verknüpft werden, so dass die scharfen Gattungsgrenzen aufgehoben werden: Wörterbüchern, Atlanten, Korpora und analytische Diskurse (‘Abhandlungen’) werden zu lexikographischen, kartographischen, diskursiven usw. Funktionen in einer integralen Publikationsumgebung.
In dieser Logik wurde die Plattform von Verba Alpina konzipiert, die eine enge Verflechtung der genannten Funktionen vorsieht:
| Funktion | Reiter auf der Menüleiste des Projekts |
| Kartographie | Interaktive Karte |
| Lexikographie | Lexicon Alpinum |
| Diskurs | Methodologie |
| Beiträge | |
| Crowdsourcing | Mitmachen! |
Die jeweiligen Einträge sind darüber hinaus in hypertextueller Weise wechselseitig verlinkt, wie die mehr oder weniger zufällig ausgewählte Karte des Konzepts ALM zeigt:
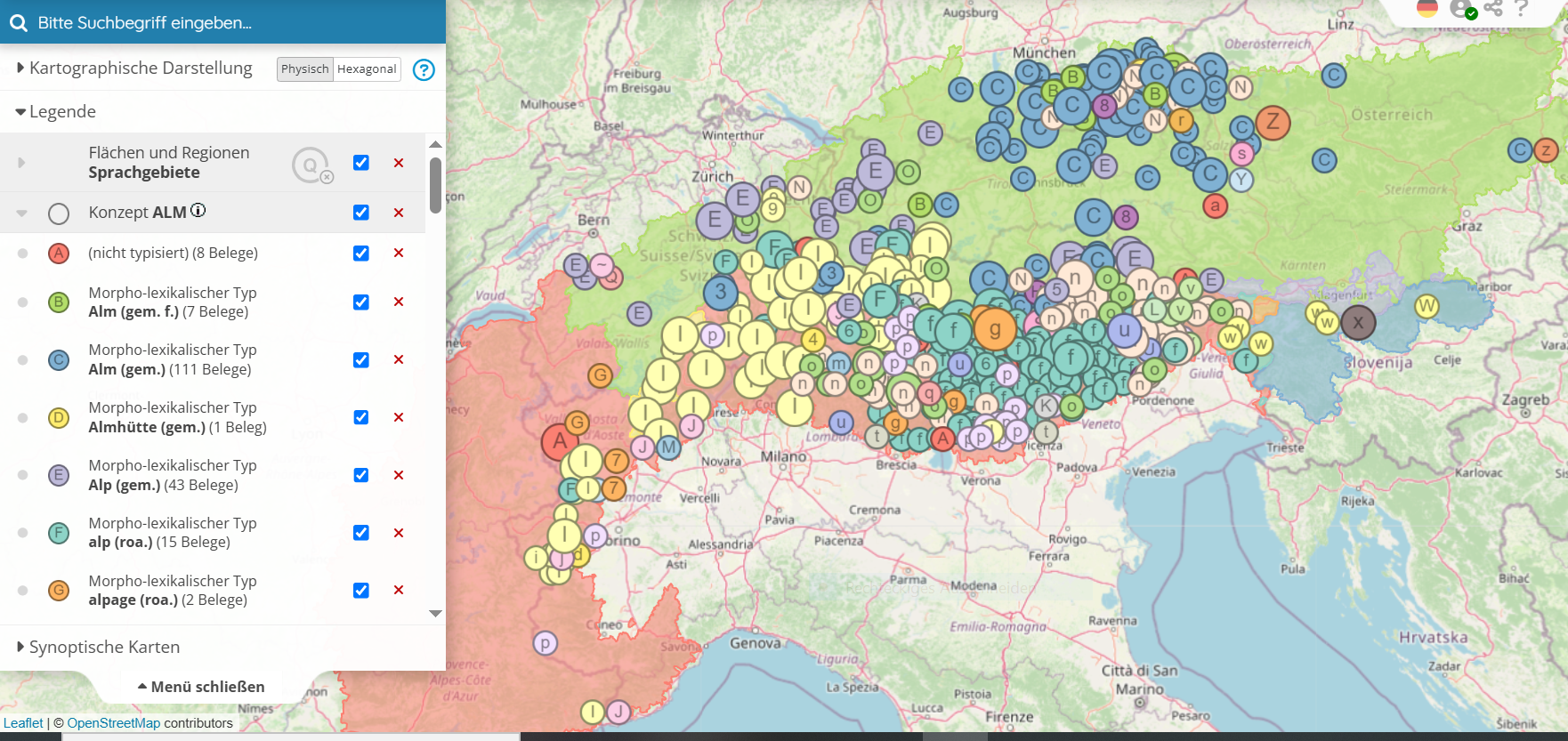
Bezeichnungen des Konzepts ALM (interaktive Originalkarte https://www.verba-alpina.gwi.uni-muenchen.de?page_id =133&db=232&tk=5194)
Jedes Kartensymbol ist interaktiv, wie in Abb. 4 beschrieben, und mit externen lexikographischen und anderen Informationen verlinkt (vgl. z. B. das geöffnete Belegfenster unter https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=232&tk=5197). Darüber hinaus findet sich ein lexikologischer Eintrag zur Kategorie der ‘Alpenwörter’ im der Funktion Lexicon Alpinum (vgl. Krefeld 2023g, Link).
Weiterhin ist es möglich, beim Aufrufen eines Webtextes den jeweils aktuellen Stand eines dynamischen Datenkorpus zu zeigen, ohne den Text als solchen zu verändern; ein Beispiel liefern die Buttons Livedaten und Live Stat. auf der Home-Seite des Portals von Verba Alpina. Spätestens hier sehen viele Nutzer das Problem der (In)Stabilität der gelieferten Informationen. In der Tat ging die Plattform des Projekts bereits kurz nach dem Beginn der Arbeit (2015) online und wurde fortlaufend angereichert. Entscheidend ist jedoch, dass seit 2016 im halbjährigen Abstand stabile Versionen erzeugt wurden (vgl. Lücke 2022c), die allesamt verfügbar geblieben sind (zuletzt die Version 23/2); ältere Versionen wurden nicht durch die jeweils neuere ersetzt, sondern ergänzt. Alle Links auf Projektinhalte bleiben daher stabil, da die jeweilige Version Bestandteil der zitierten permanenten URL ist. So zeigt der Ausschnitt [...]db=232[...] im soeben zitierten Link https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=232& tk=5197) auf die Version 23/2. Der Vorbehalt textueller Instabilität von Web-Publikationen ist damit entkräftet.
Die Problematik der Qualitätssicherung soll hier nicht weiter erörtert werden; grundsätzlich sind dieselben Verfahren (meistens peer reviewing) möglich, die auch bei Print-Publikationen verwandt werden. Dem nicht nur virtuellen, sondern auch sozialen Medium des Internet angemessen wäre es jedoch, die Einschätzung der Qualität einer Publikation nicht vorab einem oder zwei anonym bleibenden Expert:innen anzuvertrauen (was einer ‘Sicherung’ keineswegs genügt), sondern der offenen und mehr oder weniger starken Rezeption aufzufassen. Es ist ja leicht, jede Publikation mit einem Kommentarfenster zu versehen.
Bleibt die schwierige und auch beunruhigende Frage nach der Dauerhaftigkeit von Webpublikationen, die in rundum zufriedenstellender Weise noch nicht beantwortet werden kann. Immerhin wurden schon die ersten verlässlichen Schritte unternommen. Das wichtigste Prinzip besteht zweifellos darin, Lösungen jenseits der per definitionem prekären Welt der Projekte zu suchen (und zu finden): Jedes ‘Projekt’ ist ja grundsätzlich befristet. Aus diesem Grund müssen Projektpublikationen (Daten, Code, Text) auf Servern gesichert werden, die von dauerhaft eingerichteten Institutionen betrieben werden. Im Fall von Verba Alpina haben sich die Projektleiter für eine enge Anbindung an die Universitätsbibliothek der LMU entschieden, die in jahrelanger Kooperation vorbereitet wurde. Sie führte zu dem Ergebnis, dass alle Daten des Projekts sowie die im Projekt veröffentlichten Texte über eine spezielle Suchmaschine der UB gefunden werden können (vgl. https://discover.ub.uni-muenchen.de/). Dauerhaftigkeit scheint dafür garantiert; prekär bleiben jedoch alle eingebetteten externen Links, auf deren Persistenz die hostende Einrichtung (hier: die UB) keinen Einfluss hat. Dieses grundlegende Problem wird von vielen Internetautor:innen nicht hinreichend beachtet.
Über diese Kooperation mit der UB der LMU hinaus wurden der Computercodes für Funktionalitäten von Front- und Backend des Webportals auf Github unter einer offenen Lizenz abgelegt (https://github.com/VerbaAlpina/), eine API (u. a. für den XML-Export) eingerichtet und älterer Versionen des VA-Web-Portals auf archive.org abgelegt (https://web.archive.org/web/*/http://verba-alpina.gwi.uni-muenchen.de/). Nachgenutzt wurden die Entwicklungen von VerbaAlpina das Projekt VerbaPicardia [VP-Karte]).
4. Fazit: Da fehlt uns doch was...
Das Fazit dieses Beitrags ergibt sich ganz unmittelbar aus dem vorletzten vorhergehenden Absatz, denn die skizzierte best practice eines einzelnen Projekts kann zwar, womöglich, eine Perspektive eröffnen, aber natürlich keine sofortige Lösung für eine ganze, zudem sehr produktive Disziplin wie die Romanische Geolinguistik liefern. Dazu fehlt ein wichtiger und im Hinblick auf die kontinuierliche Nachnutzbarkeit gar der wichtigste Mitspieler: eine Einrichtung, die ein umfassendes Observatorium horten könnte. Sie dürfte nicht kommerziell sein und müsste mit einer hohen Wahrscheinlichkeit auf Dauer bestehen. Zudem – und das ist die eigentliche Herausforderung – müsste ein solcher Host, der auch ein Netzwerk von Einrichtungen sein könnte, die zur Verfügung gestellten Projekte kontinuierlich an veränderte Web-Bedingungen (z.B. Serve-Updates) anpassen und idealerweise, zumindestens im Hinblick auf aktive wissenschaftliche Nutzer moderieren, damit dauerhafte Erweiterbarkeit der Datenbasis garantiert ist.

Bibliographie
- ADDU = Thun, Harald / Elizaincín, Adolfo (2000-): Atlas lingüístico diatópico y diastrático del Uruguay, Kiel, Westensee.
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, vol. 8 vol., Zofingen, Ringier [Reprint: Nendeln: Krauss 1971] (Link).
- AISr = Loporcaro, Michele / Schmid, Stephan / Pescarini, Diego / Tisato, Graziano / Donzelli, Giulia / Negrinelli, Stefano / Zanini, Chiara (2019): AIS, reloaded (AISr), Zurich, University of Zurich, University of Zurich (Link).
- ALC = Griera i Gaja, Antoni (1923–1964): Atlas lingüístic de Catalunya. 8 Bände, Barcelona.
- ALD = Goebl, Hans / Bauer, Roland / Haimerl, Edgar (Hrsgg.) (1998-2002): (ALD) Atlant linguistich dl ladin dolomitich y di dialec vejins. Atlante linguistico del ladino dolomitico e dei dialetti limitrofi. Sprachatlas des Dolomitenladinischen und angrenzender Dialekte, vol. Part I: 4 voll., Wiesbaden, Reichert [3 CD-ROMs, 1 DVD].
- ALF = Gilliéron, Jules / Edmont, Edmond (Hrsgg.) (1902-1910): Atlas linguistique de la France (ALF), vol. 10 vol., Paris, Champion [Reprint: Bologna: Forni 1968] (Link).
- ALI = Bartoli, Matteo (1995-): Atlante linguistico italiano, a cura di U. Pellis & L. Massobrio, vol. 7, Roma, Istituto Poligrafico e Zecca dello Stato (Link).
- ALiB 2014- = ALiB (2014-): Atlas Linguístico do Brasil, Londrina.
- AlpiLink = Rabanus, Stefan / Kruijt, Anne / Alber, Birgit / Bidese, Ermenegildo / Gaeta, Livio / Raimondi, Gianmario (2023): AlpiLinK. German-Romance language contact in the Italian Alps: documentation, explanation, participation. In collaboration with Paolo Benedetto Mas, Sabrina Bertollo, Jan Casalicchio, Raffaele Cioffi, Patrizia Cordin, Michele Cosentino, Silvia dal Negro, Alexander Glück, Joachim Kokkelmans, Andriano Murelli, Andrea Padovan, Aline Pons, Matteo Rivoira, Marta Tagliani, Caterina Saracco, Emily Siviero, Alessandra Tomaselli, Ruth Videsott, Alessandro Vietti & Barbara Vogt. (Link).
- ALS = Ruffino, Giovanni (Hrsg.) (1991-): Atlante linguistico della Sicilia, Palermo, Centro di studi filologici e linguistici siciliani.
- ASD = Krefeld, Thomas / Lücke, Stephan (Hrsgg.) (2010-2013): Audioatlas siebenbürgisch-sächsischer Dialekte, München (Link).
- AsiCa = Krefeld, Thomas / Lücke, Stephan (2006-2017): Atlante sintattico della Calabria, München, LMU (Link).
- AsiCa2.0 = Krefeld, Thomas / Lücke, Stephan (Hrsgg.) (2019): Atlante sintattico della Calabria. Rielaborato tecnicamenta da Veronika Gacia e Tobias Englmeier, München, online, LMU (Link).
- Cherubini 1814 = Cherubini, Francesco (1814): Vocabolario milanese-italiano, 2 voll., Milano, Milano, Stamperia reale (Link).
- Cugno/Massobrio 2010a = Cugno, Federica / Massobrio, Lorenzo (2010): Atlanti linguistici, in: Enciclopedia dell'Italiano (Link).
- Cugno/Massobrio 2010b = Cugno, Federica / Massobrio, Lorenzo (2010): Gli atlanti linguistici della Romània, Alessandria, Edizioni dell'Orso.
- DRG = Melcher, Florian / De Planta, Robert (Hrsgg.) (1939-): Dicziunari Rumantsch Grischun, Cuoira, Società Retorumantscha (Link).
- DWDS 2004 = DWDS (2004): Das digitale Wörterbuch der deutschen Sprache. , Berlin, Berlin-Brandenburgische Akademie der Wissenschaften.
- Englmeier/Lücke 2023 = Englmeier, David / Lücke, Stephan (2023): FAIR-Prinzipien, in: Methodologie, VerbaAlpina-de 23/2 (Link).
- Krefeld 2019ar = Krefeld, Thomas (2019): Der Sprach- und Sachatlas Italiens und der Südschweiz (AIS) – ein Prototyp, in: Lehre in den Digital Humanities, München, LMU (Link).
- Krefeld 2021h = Krefeld, Thomas (2021): Vom Feld ins Netz: Drei Generationen von Sprachatlanten, in: Lehre in den Digital Humanities, München (Link).
- Krefeld 2022h = Krefeld, Thomas (2022): Methodik aus etischer Perspektive: die Atlanten, in: Lehre in den Digital Humanities, München, LMU (Link).
- Krefeld 2023a = Krefeld, Thomas (32023): Sprecher:innen, Gemeinschaften – und Grenzen? Zur Modellierung des kommunikativen Raums, in: Korpus im Text, Serie A, 84354, München (Link).
- Krefeld 2023b = Krefeld, Thomas (2023): ‘Publikation’ geht in Revision, in: Korpus im Text, Serie A, 104645, München, LMU (Link).
- Krefeld 2023g = Krefeld, Thomas (2023): Alpenwörter, in: Methodologie, VerbaAlpina-de 23/2 (Link).
- Krefeld 2023n = Krefeld, Thomas (2023): Wissenschaftskommunikation im Web, in: Methodologie, VerbaAlpina-de 23/2 (Link).
- Krefeld 2023o = Krefeld, Thomas (2023): Transkription, in: Methodologie, VerbaAlpina-de 23/2 (Link).
- Krefeld 2024a = Krefeld, Thomas (2024): Romània migratoria, in: Korpus im Text, Serie A, 107182, München, LMU (Link).
- Krefeld/Lücke 2014- = Krefeld, Thomas / Lücke, Stephan (Hrsgg.) (2014-): VerbaAlpina. Der alpine Kulturraum im Spiegel seiner Mehrsprachigkeit, online [Ultimo accesso 20/01/2019 ore 16:02] (Link).
- Krefeld/Lücke 2022c = Krefeld, Thomas / Lücke, Stephan (2022): VerbaAlpina going FAIR – Was ein Projekt zu seiner Nachhaltigkeit beitragen kann (und was nicht), VerbaAlpina-de 23/1 (Link).
- Krefeld/Lücke 2023 = Krefeld, Thomas / Lücke, Stephan (2023): Sketching out a Virtual Framework for Romance Geolinguistics,, in: Weiland / Quijada van den Berghe / Pustka (2023).
- Krefeld/Lücke 2023a = Krefeld, Thomas / Lücke, Stephan (2023): FAIRNESS – Medien im methodologischen Zentrum der Geolinguistik, in: Krefeld/Lücke/Mutter 2023, München (Link).
- Lo Piparo/D'Agostino/Ferreri/Pennisi/Ruffino/Vecchio 1990 = Lo Piparo, Franco / D'Agostino, Mari / Ferreri, Silvana / Pennisi, Antonino / Ruffino, Giovanni / Vecchio, Sebastiano (1990): La Sicilia linguistica oggi, in: Osservatorio linguistico siciliano, vol. 3, Palermo, Centro di studi filologici e linguistici siciliani.
- Lücke 2022c = Lücke, Stephan (2022): Versionierung, in: Methodologie, VerbaAlpina-de 23/2 (Link).
- NavigAIS = Tisato, Graziano (2017): NavigAIS. AIS Digital Atlas and Navigation Software, Padua, Istituto di Scienze e Tecnologie della Cognizione (ISTC) - Consiglio Nazionale delle Ricerche (CNR) [Online-Version von Jaberg/Jud, 1928-1940, Sprach- und Sachatlas Italiens und der Südschweiz (AIS)] (Link).
- REWOnline 2022 = REWOnline (2022): Zacherl, Florian: Digitale Aufbereitung des Romanischen etymologischen Wörterbuches von Wilhelm Meyer-Lübke, München (Link).
- Saussure 1972 = Saussure, Ferdinand de (1972): Cours de linguistique générale [1916], Paris, Payot.
- Scherrer 2019 = Scherrer, Yves (2019): Dialektkarten (Link).
- Schmeller 1821 = Schmeller, Johann Andreas (1821): Die Mundarten Bayerns : grammatisch dargestellt ; beygegeben ist eine Sammlung von Mundart-Proben, d.i. kleinen Erzählungen, Gesprächen, Sing-Stücken, figürlichen Redensarten u. dergl. in den verschiedenen Dialekten des Königreichs, nebst einem Kärtchen zur geographischen Übersicht dieser Dialekte, in: Die Mundarten Bayerns : grammatisch dargestellt ; beygegeben ist eine Sammlung von Mundart-Proben, d.i. kleinen Erzählungen, Gesprächen, Sing-Stücken, figürlichen Redensarten u. dergl. in den verschiedenen Dialekten des Königreichs, nebst einem Kärtchen zur geographischen Übersicht dieser Dialekte, München, Karl Thienemann.
- Sottile 2019b = Sottile, Roberto (2019): L’Atlante Linguistico della Sicilia (ALS), in: Roland Bauer & Thomas Krefeld (a cura di) (2019): Lo spazio comunicativo dell’Italia e delle varietà italiane (Korpus im Text 7), Versione 90 (Link).
- Verba Alpina = Krefeld, Thomas / Lücke, Stephan (2014-): VerbaAlpina. Der alpine Kulturraum im Spiegel seiner Mehrsprachigkeit, München (Link).
- VinKo = Rabanus, Stefan / Kruijt, Anne / Tagliani, Marta / Tomaselli, Alessandra / Padovan, Andrea / Alber, Birgit / Cordin, Patrizia / Zamparelli, Roberto / Vogt, Barbara Maria (2022): VinKo (Varieties in Contact) Corpus v1.1, University of Verona, Eurac Research CLARIN Centre (Link).
- VSI = Sganzini, Silvio (1952-): Vocabolario dei dialetti della Svizzera italiana., Lugano, Tipografia la Commerciale.
- Winkelmann/Lausberg 2001 = Winkelmann, Otto / Lausberg, Uta (2001): Romanische Sprachatlanten / Les atlas linguistiques des langues romanes, in: LRL, vol. I/2, 1004-1068.
- Zacherl 2023c = Zacherl, Florian (2023): Identifikatoren, in: Methodologie, VerbaAlpina-de 23/2 (Link).
