Erweiterte Fassung eines Vortrags beim XXXII. Romanistischen Kolloquiums (RK) über 'Fachbewusstsein der Romanistik'
1. Webbasierte Forschungsumgebungen
| "Because something is happening here, but you don't know what it is, do you, Mr Jones?" (Dylan 1965) |
Man mag vom Nobelpreisträger für Literatur des Jahres 2016 halten, was man mag - im Eingangszitat hat Bob Dylan zweifellos eine Erfahrung festgehalten, die jeder Wissenschaftler schon einmal gemacht hat, oder bis zum Ende seines Forscherlebens gemacht haben wird: die mehr oder weniger vage Ahnung, eine Phase grundsätzlicher klimatischer Veränderung seiner Forschungslandschaft zu durchleben. Früher oder später gelangt diese Ahnung dann, wenn sie berechtigt war, ins Licht des Bewusstseins, so dass man sich dazu verhalten kann, sei es mit Zustimmung, mit Ablehnung oder auch mit Ignoranz. Der Autor dieser Zeilen hat so ein Erlebnis, gewissermaßen ein rationales (durch und durch unreligiöses) Konversionserlebnis im Jahre 2005 erfahren, während der Arbeit an einem sehr bescheiden dimensionierten Projekt zur italienischen, kalabresischen Dialektsyntax, dem Atlante sintattico della Calabria (AsiCa). Die Doktorandin, die das ganz analog, d.h. papieren konzipierte Projekt damals bearbeitete - Irmengard Salminger - suchte Hilfe für die digitale Verarbeitung und Verwaltung der erhobenen Audio-Daten und wandte sich an eine segensreiche Einrichtung der LMU (zu deren Gründung übrigens die Münchner Romanistik noch im Zustand vollkommener digitaler Unschuld beigetragen hatte), nämlich an die so genannte IT-Gruppe Geisteswissenschaften (ITG); geholfen wurde ihr von Stephan Lücke.
Daraus ergab sich eine bis heute sehr produktive Kooperation, in der jedoch bald klar wurde, dass dem ursprünglichen Projektentwurf des AsiCa im Nachhinein strenggenommen nicht zu helfen war; es kam also sofort zu einem weiteren, wiederum ganz kleinen Projektantrag, der das Atlasprojekt ganz konsequent in Webtechnologie refundierte. Es folgten ein, nur ganz am Rande romanistisches Projekt, der Audioatlas siebenbürgisch-sächsischer Dialekte (ASD), etwas ganz Experimentelles zur Erhebung von (italienischen) Sprachdaten mit einer Spieloberfläche (Metropolitalia) und schließlich, 2014, eine größere, aktuell in Arbeit befindliche Unternehmung zum ethnographisch relevanten Dialektwortschaft des gesamten romanisch-, germanisch- und slawischsprachgen Alpenraums (VerbaAlpina).
Diese Projekte spiegeln natürlich subjektive Forschungsinteressen wider; aber sie weisen auch auf die substantiell veränderten Rahmenbedingungen für den Umgang mit sprachlicher Empirie hin; da sie im Sinne etablierter und auch fachkonstitutiver Forschungsziele sind, wurden sie mindestens partiell schnell angenommen und werden sich ohne Frage bald als Standard durchgesetzt haben:
- die Digitalisierung;
- die quantitative Basierung;
- die direkte Einbindung von phonisch materialisierter Sprache.
Auf die gesprochene Sprache jenseits schriftlicher Tradition hat sich die Dialektologie, seit Ihrer Begründung zu Beginn des 19. Jahrhunders bezogen (übrigens sehr im Unterschied zur Indogermanistik), obwohl sie natürlich gezwungen war, sich dabei mit schriftlicher Transkription zu begnügen. Festzuhalten ist an dieser Stelle, erstens, dass die Linguistik - und nicht nur ihre dialektologische Sparte - insofern sie sich für gesprochene, nicht textuell verfasste Sprache interessiert, mit dem Etikett der 'Philologie' nicht zutreffend charakterisiert wird 1 und, zweitens, dass sich dieser unphilologische Forschungsstrang wohl rapide und massiv verstärken dürfte. Keineswegs im grundsätzlichem Gegensatz zur Philologie steht dagegen die quantitative Orientierung.
Das letzte der oben genannten Projekte führt die früheren methodologisch weiter, aber in einem ganz wesentlichen Punkt unterscheidet es sich von ihnen, denn VerbaAlpina legt sehr viel Wert auf die explizite Selbstreflexion und Dokumentation der sprachwissenschaftlichen und informationstechnischen Forschungsarbeit (vgl. die Beiträge unter Methodologie). Unter anderen wurde die zentrale Frage diskutiert, was denn unter Digitalisierung zu verstehen sei (vgl. Lücke 2017).
Es kam im Zusammenhang damit bald die grundlegende Frage auf, wo das Format dieses mehrsprachigen dialektologischen Projekts im Spektrum der traditionellen Gattungen 'Atlas', 'Wörterbuch', 'Monographie' und 'Korpus' zu verorten sei. Die Antwort zeigte sofort, dass es - umgekehrt - darum ging, die Leistungen der traditionellen Gattungen im Rahmen einer Vorgehensweise zu verankern, die als webbasierte, virtuelle Forschungsumgebung bezeichnet werden kann.
Vollkommen unabhängig von der thematischen Ausrichtung des spezifischen Projekts (hier: VerbaAlpina) können die Leistungen solcher Umgebungen den folgenden, allgemeinen Funktionsbereichen zugeordnet werden:
(1) Dokumentation, die in unzulässiger Vereinfachung oft mit Forschungsdaten gleichgesetzt wird;
(2) Kooperation, womöglich in unterschiedlichen epistemischen Horizonten, nämlich mit Laien und Wissenschaftlern;
(3) Publikation;
(4) Datenerhebung durch Crowdsourcing.
Aus dem Zusammenspiel von (1)-(4) ergibt sich schließlich unter guten Umständen
(5) ein virtuelles Forschungslabor.
Wirklich obligatorisch ist bei der Verwendung von Webtechnologie nur Funktion (3), d.h. die Publikation, denn das Internet ist ein einziger, gewaltiger Publikationsapparat. Gleichzeitig ist diese Funktion aber auch diejenige, die in den Forschergemeinschaften mancher Disziplinen, womöglich auch in der Romanistik, noch ein beträchtliches Polarisierungspotential entfaltet; immerhin muss präzisiert werden, was genau publiziert wird, oder: was unter 'Publikation' mittlerweile zu verstehen ist. In umfassendem Sinne gehören dazu:
- sprachliche Objektdaten;
- strukturierende Metadaten;
- wissenschaftlicher Text, der traditionell allein als 'Publikation' bezeichnet wird;
- Code und seine Dokumentation.
2. Verbreitete Vorbehalte gegenüber Webpublikationen
Die teils beharrlichen Vorbehalte gegenüber Publikationen im Web werden durch ganz unterschiedliche Gründe getragen, die allesamt nicht substantiell, sondern akzidentiell zu sehen sind. Am schwersten wiegt das Argument der prekären Nachhaltigkeit (vgl. dazu Krefeld & Lücke 2017a), das durch ein Paket konzertierter Maßnahmen bewältigt werden kann; dazu gehören:
- die Schaffung textstabiler und insofern dauerhaft zitierfähiger Versionen;
- die Auszeichnung mit Metadaten, die sowohl durch Suchmaschinen wie in Bibliothekskatalogen leicht auffindbar sind;
- die Ablage auf institutionell betriebenen Servern mit zuverlässiger Aussicht auf langfristige Verfügbarkeit (große Rechenzentren).
Ein Format, das diesen Ansprüchen genügen kann, wurde an der LMU mittlerweile entwickelt. Es ist so angelegt, dass die jeweilige textstabile Version in der URL angezeigt wird und weiterhin durch die Nummer eines Abschnitts, auf den man sich bezieht oder den man wörtlich zitiert, spezifiziert werden kann. Hier die empfohlene Zitierweise eines Artikels in der 7. Version (...v=7):
- Thomas Krefeld & Stephan Lücke (2017): Nachhaltigkeit – aus der Sicht virtueller Forschungsumgebungen. Korpus im Text. Version 7 (10.03.2017, 12:27). url: http://www.kit.gwi.uni-muenchen.de/?p=5773&v=7
sowie die URL seines ersten Abschnitts (...p:1):
3. Printausgabe - eine nachgeordnete Option
Das Verhältnis von Webpublikation der skizzierten Art und traditioneller Publikationsweise muss ein wenig genauer bestimmt werden. Es geht keineswegs darum, einen billigen Behelf durch graphische Abbildung von Text (meist im Format PDF) zu schaffen, weil man sich die verbleibenden,und zunehmend monopolistisch auftretenden Verlage nicht leisten kann. Vielmehr muss das Web als eine medial autonome und in ihrer Komplexität ebenso attraktive wie anspruchsvolle Form ernst genommen werden. Eine 'billige' Lösung sucht man unter diesen Bedingungen allerdings vergeblich: Webtechnologie erfordert vielmehr teure Spezialistenarbeit, die bei der Budgetierung eingeplant werden muss. Dieser Faktor ist grundlegend, denn man darf nicht vergessen, dass eine webtechnologisch konzipierte Realisierung keineswegs die ästhetische ansprechende Printausgabe ausschließt, wie exemplarisch die Funktion Stampa des wunderbaren TLIO (vgl. Leonardi 2017) zeigt; jedes virtuelle Lemma, z.B. amore, läßt sich über einen Button als traditionelle Wörterbuchseite anzeigen und ausdrucken, wie der Anfang des Artikels illustriert:

/var/cache/html/kit/html/wp content/uploads/TLIO amore
Der umgekehrte Weg ist dagegen versperrt, denn analog, also für den Druck konzipierte Publikationen lassen sich nur mit erheblichem Mehraufwand in seriöse Webauftritte verwandeln. Hybride Formen sind also möglich und gelegentlich auch sinnvoll, etwa dann, wenn Prüfungsämter ihren papierenen Tribut einfordern. Aber wer das Internet als Publikationsform sui generis anerkennt, muss die Print-Option konsequenterweise als konzeptionell nachgeordnet und daher als sekundär einstufen.
Ein derartiges, den Rahmenbedingungen der Neuen Medien angemessenes Verständnis von 'Veröffentlichung' impliziert zwar nicht per se und kategorisch, aber doch in der Praxis die Auseinandersetzung mit den oben genannten Funktionsbereichen (1), Dokumentation, und (2), Kooperation, die sich als ebenso selbstverständliche wie nützliche Optionen anbieten. In der zunehmenden Annahme und konkreten Ausgestaltung dieses Angebots liegt nun ein großes Potential für die die Entwicklung neuer fachlicher Kooperation, die auch über die Grenzen der weitgehend verselbständigten Teilgebiete hinausgeht. Die Tendenz ist eindeutig, obwohl sie durch unterschiedliche Institutionen, wie z.B. die Einrichtungen der Forschungsförderung (allen voran die DFG) und die Fachverbände zweifellos besser stimuliert und auch effizienter koordiniert werden könnte (ein Sektionsvorschlag zur Abstimmung zwischen webbasierten romanistischen Forschungsvorhaben für den Romanistentag 2017 wurde z.B. abgelehnt).
4. Das Beispiel der Lexikographie (und ihres langsamen Abschieds vom Buch)
Wie ein solcher Konsens praktisch umgesetzt werden könnte, lässt sich am bereits gestreiften Komplex der Lexikographie in sehr augenfälliger Weise skizzieren. Die aktuelle Situation dieser, für Linguisten, Literaturwissenschaftler und viele andere grundlegenden Disziplin ist durch das unvermittelte Nebeneinander ganz unterschiedlicher medialer Formate gekennzeichnet, die sich im Lichte der Digitalisierung auf einem Kontinuum abbilden lassen, wie die folgenden vier, wichtigen Wörterbücher illustrieren:
| Varvaro 2014 | REW | FEW | TLIO | |
| Digitalisierungsgrad | 0 | 1 | 1/3 | 3 |
Besonders charakteristisch für die aktuelle Übergangsphase ist das FEW, dessen allergrößter Teil, die Artikel, auf der untersten Digitalisierungsstufe zugänglich sind; eine Volltextsuche, wie sie etwa für den Vocabolario degli Accademici della Crusca ( 1612) verwirklicht wurde, ist daher nicht möglich. Für die Online-Version wurden aus dem lexikalischen Bestand aber wenigstens zwei Gruppen von Ausdrücken extrahiert, offenkundig in Tabellenform gebracht und damit auf die Digitalisierungstufe 3 gehoben. So wird bereits eine sehr elementare Suche gestattet, nämlich nach Etyma einerseits und ausgewählten französischen Kognaten andererseits; im Grunde sind damit drei Kategorien etabliert, da die Germanismen in speziellen Bänden zusammengestellt wurden:
- fra. Kognaten,
- lateinische Etyma,
- germanische Etyma.
Mit diesen drei Gruppen, die hier provisorisch als FEWfra, FEWlat und FEWgerm bezeichnet werden, ist der ganz rudimentäre Nukleus eines relationalen Datengefüges gegeben, deren Einträge jeweils für sich ansprechbar und verknüpfbar sind, ganz unabhängig von dem spezifischen Datenformat, das angewendet wurde.
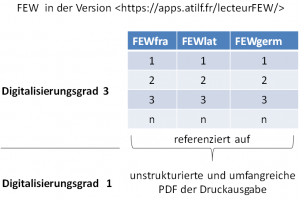
Die Online-Version des FEW
Es ist weiterhin evident, dass die Kategorien FEWgerm und - vor allem - FEWlat für zahlreiche andere (nicht nur) romanistische Wörterbuchprojekte (und andere Unternehmungen) außerordentlich wertvoll sind. Es wäre daher vernünftig, weil nützlich, diese Tabellen so zu organisieren, dass sie der Lexikographie und Lexikologie im Ganzen als virtuelle Referenz zur Verfügung gestellt würden. Sie könnten so sehr leicht zum Nukleus umfassender und permanent erweiterbarer Tabellen erhoben werden. Technisch dürfte das kein Problem sein; es wäre allenfalls erforderlich dieses lexikographische Modul auf einem Server zu hosten, der maximale Aussicht auf Dauerhaftigkeit verspricht.
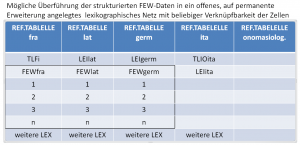
FEW-Module als möglicher Nukleus eines weitgespannten lexikographischen Netzes
In keinem der genannten Wörterbücher ist bislang eine Kooperation vorgesehen; es ist andererseits evident, dass die Digitalisierungsstufe 3 eine systematische Zusammenarbeit leicht ermöglichen würde; sie könnte in der Vervollständigung der angelegten und der Erweiterung um zusätzliche Module bestehen. Insbesondere ein onomasiologischer 'Dienst', wenn man so sagend darf, wäre wichtig, denn von einer umfassenden onomasiologischen Erschließung sind wir noch weit entfernt; einen noch verschwindend kleinen Ausschnitt bietet der .
Ein entsprechendes Kooperationsmodell wurde, ebenfalls im kleinen Rahmen, im Projekt VerbaAlpina verwirklicht Krefeld 2017b; hier steht jedem Projektpartner eine spezielle Datenbank zur Verfügung zu individuellen Nutzung zur Verfügung; auf die dort abgelegten Daten haben alle Partner des Konsortiums Zugriff. Jedoch kann eine spezifische Partnerdatenbank selbst nicht durch andere Partner modifiziert werden; hier ein nicht vollständiger Überblick der Partnerdatenbanken (mit dem Kürzel pva_...) zu denen teils umfangreiche Bestände gehören, wie etwa diejenigen des ALD :
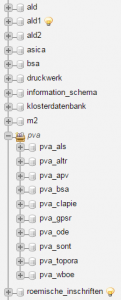
Selbstverständlich wird bei der komplementären Verwendung unterschiedlicher Quellen die Identität/Herkunft der Daten jederzeit gewahrt.
5. Kerne der digital romance humanties (DromH)
Die Lexikographie ist also gewissermaßen das bereits fest gegossene Fundament eines Pfeiler, der das entstehende Gebäude der webbasierten virtuellen Romanistik trägt. Sie steht jedoch keineswegs allein, denn es lassen sich bereits einige andere potentielle Kern identifizieren, zu denen sicherlich die folgenden genannten, aber womöglich noch andere gehören:
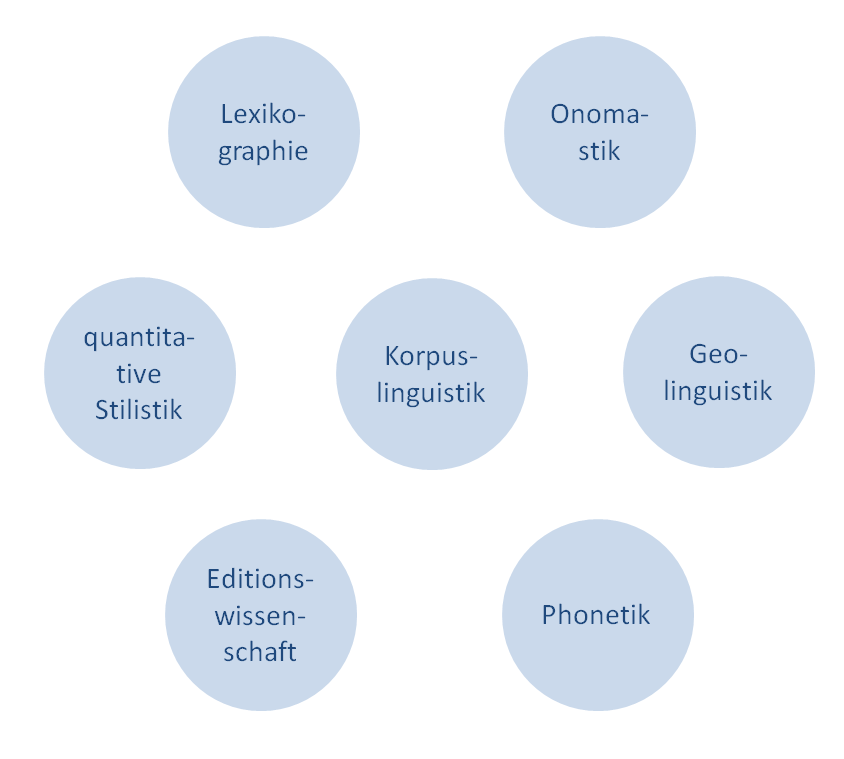
Kerne einer zukünftigen DromH
Die eigentliche Herausforderung besteht nun darin, diese mehr oder weniger isolierten Kerne so zu integrieren, dass ein offener Zugriff und maximaler wechselseitiger Austausch gewährleistet wird; die technischen Mittel sind gegeben. Es gilt aus der Perspektive des Fachs eigentlich nur zwei grundlegende Prinzipien zu beachten, oder - besser gesagt - ihre Beachtung durch geeignete Maßnahmen, wie z.B. Vorgaben bei der Projektförderung, einzufordern.
- Daten müssen in strukturierter Weise in zugänglichen und auf Dauerhaftigkeit angelegten Repositorien abgelegt werden. Die Einhaltung der open access-Regeln sowie die Verwendung standardisierter Formate werden vorausgesetzt. Die Zugänglichkeit muss durch formalisierte Vereinbarungen geregelt werden.
- Für den Zugriff (upload und download) müssen geeignete Schnittstellen eingerichtet werden. Institutionell ist die kontinuierliche Pflege der Schnittstellen zweifellos neuralgisch, denn sie kann nicht automatisiert werden und setzt den Einsatz verantwortlicher Personen voraus.
Bei Beachtung diese beiden Grundprinzipien müsste ein groß angelegtes Wörterbuchprojekt wir der TLIO die umfangreichen Textedition nicht nur selektiv, in Form von minimalen Kontexten der einzelnen Lemmata aufscheinen lassen, sondern als ganze in einem Repositorium zur Verfügung. So könnten Computerlinguisten daraus ein konsistentes Korpus extrahieren, taggen und auch morphosyntaktisch auswerten. Geolinguisten könnten im TLIO exhaustiv ermittelten Varianten diatopisch visualisieren, chronoreferenzieren und mit rezenten Daten abgleichen usw. Schematisch ergäbe sich also:
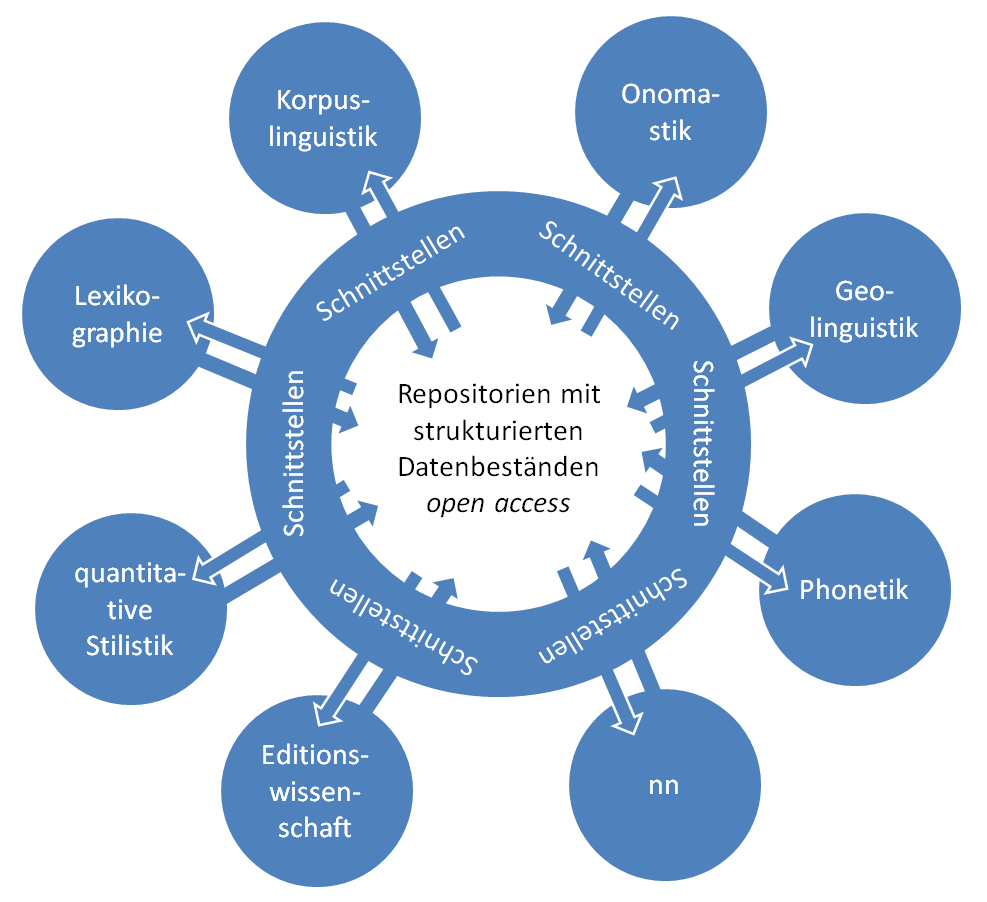
Kerne verknüpft
Es zeichnet sich bereits ab, dass die Initiativen der Fächer durch neue Dienste der großen Referenzbibliotheken flankiert werden. Als den traditionell etablierten Institutionen mit dem Auftrag das Wissen zu thesaurieren kommt ihnen auch im Hinblick auf Auffindbarkeit, Zitierbarkeit und Nachhaltigkeit der webbasierten Projekte eine zentrale Rolle zu. Sie sollten die Verantwortung übernehmen für
- die Entwicklung von Metadatenschemata,
- die Vergabe von darauf basierenden Metadaten an einzelne virtuelle Publikationen,
- die Auffindbarkeit dieser "Publikationen" über einen zentralen Metadatenkatalog (= OPAC?),
- die dauerhafte Bewahrung der Daten (Delegierung an möglichst mehrere Repositorien).
In diesem Rahmen (oder: 'framework') entsteht eine neue Verfassung für die alte Vorstellung der Gelehrtenrepublik, indem die res, hier diejenige der Romanisten, sich in einem substantiell neuen Verständnis wirklich als publica> etablieren würde.
6. Fazit
Im Sinne der Romanistik (und der Geisteswissenschaften überhaupt) brauchen wir mehr digitale Aufklärung. Frei nach Immanuel Kant2 ist digitale Aufklärung der Ausgang des Romanisten aus seiner selbstverschuldeten digitalen Unorganisiertheit. Unorganisiertheit ist das Unvermögen, sich seiner eigenen Forschungsdaten ohne Abstimmung mit den Daten anderer zu bedienen. Selbstverschuldet ist diese Unorganisiertheit, wenn die Ursache derselben nicht am Mangel der Forschungsdaten, sondern der forschungspolitischen Bereitschaft liegt, sich seiner eigenen Daten ohne Abstimmung mit den Daten der anderen Fachkollegen zu bedienen.