1. Once upon a time somewhere in Finland (or anywhere else)
Der Umgang mit elektronischen Datenbeständen ist im Hinblick auf Nachhaltigkeit und Nachnutzbarkeit eine große Herausforderung für den gesamten Wissenschaftsbetrieb. So geschieht es leider nicht selten, dass auch großangelegte Projekte, die über viele Jahre hinweg finanziert und betrieben wurden und die z.T. große Mengen an Material zusammengetragen haben, nach Ende der Finanzierung vor dem Aus stehen und es keine Möglichkeit gibt, die Projektdaten zu bewahren bzw. auch weiterhin zur Verfügung zu stellen. Dieses Problem ist weit verbreitet und nicht auf einzelne Länder beschränkt. Entsprechendes – diese Anekdote sei an dieser Stelle erlaubt, da sie die bestehende Gefahr sehr schön illustriert – kann z.B. die Inhaberin der Humboldt-Professur für die Alte Geschichte des Nahen und Mittleren Ostens an der LMU, Karen Radner im Zusammenhang mit einer Datenbank mit Keilschrifttexten berichten. Diese Datenbank war über Jahrzehnte hinweg an der Universität Helsinki erarbeitet worden. Nachdem der verantwortliche Wissenschaftler in den Ruhestand gegangen war, habe sich an der Universität Helsinki niemand für diesen einzigartigen Datenbestand interessiert. Zum Glück konnte Karen Radner ihn übernehmen und das Projekt fortführen.
Das geschilderte Beispiel verdeutlicht die grundsätzliche Problematik, die ganz organisch und ein Stück weit unmerklich aus dem konsequenten Einsatz der - nun nicht mehr ganz so - neuen Medien erwachsen ist. Es geht dabei vornehmlich um die Nachführung und Anpassung der die wissenschaftliche Produktion begleitenden Vorstellungen, Strukturen und Institutionen, nicht so sehr um die technischen Herausforderungen, die von den Akteuren zwischenzeitlich doch weitgehend souverän bewältigt werden. Im Zentrum stehen dabei die eingangs angesprochenen Erfordernisse der Nachhaltigkeit und Nachnutzbarkeit elektronischer Texte und anderer Daten, wobei es essentiell ist zu bedenken - und deswegen sei hier noch einmal ausdrücklich daran erinnert -, dass es sich bei elektronischen Daten ausnahmslos um die berühmten Nullen und Einsen handelt, die elektromagnetisch oder optisch auf geeigneten Datenträgern gespeichert werden. Vor diesem Hintergrund stellen sich hauptsächlich zwei Fragen bzw. Herausforderungen: Es müssen zuverlässige Konzepte und Verfahren entwickelt werden, die die korrekte Interpretation der spezifischen Zahlenabfolgen auch noch nach Jahrhunderten garantieren können, und es müssen Institutionen gefunden und entsprechend beauftragt werden, die mit der genannten zeitlichen Perspektive eben jenes Wissen durch die Zeiten transportieren und gleichzeitig den physischen Bestand der Daten selbst garantieren.
Wie wichtig die institutionelle Absicherung für die nachhaltige Bewahrung digitaler Projektdaten ist, kann eine andere Episode illustrieren, die sich in den 1980er und 90er Jahren an der Ludwig-Maximilians-Universität München zugetragen hat. Damals drohte den Daten des aus damaliger Sicht mit seiner konsequenten digitalen Ausrichtung besonders innovativen Projekts "Biblia Hebraica Transcripta" das gleiche Schicksal wie der finnischen Keilschriftdatenbank. Nur durch die Einrichtung und dauerhafte Etablierung der IT-Gruppe Geisteswissenschaften an der LMU, konnten diese Daten erhalten und dauerhaft verfügbar gemacht werden. Zwischenzeitlich erfuhr das Projekt und seine Daten eine inhaltliche und informatische Weiterentwicklung, die ohne die Bewahrung der Daten durch die ITG nicht möglich gewesen wäre (vgl. Riepl 2016).
2. Was sind eigentlich 'Forschungsdaten'?
Zwischen 1303 und 1305 verfasste Dante Alighieri 1948 sein berühmtes und wortgewaltiges Plädoyer für den schriftlichen Gebrauch der Volkssprache - in der Abfassung dieses Textes in lateinischer Sprache darf man das prototypische Merkmal einer Übergangszeit von der lateinischen zur romanischen Schriftlichkeit sehen. In einer anderen, nämlich medialen Übergangszeit befinden wir uns heute, so dass es niemanden (jedenfalls keinen Romanisten) überrascht, wenn eine wichtige Einführung in die Digital Humanities (vgl. Jannidis & Kohle & Rehbein 2017) in gedruckter Form erscheint: Auch auf dem Weg von traditionellen und analogen hin zu vollkommen digitalen Verfahren koexistieren Forschungsformate, die nicht nur durch unterschiedliche Digitalisierungsgrade, sondern eben auch durch ganz unterschiedliche Formen von Hybridität gekennzeichnet sind; darunter dominieren solche, die Datenbankauswertungen in Texte einfließen lassen, die ausschließlich in gedruckter Form veröffentlicht werden; unter 'Text' verstehen wir genauer gesagt ausschließlich die Information, die durch die Verknüpfung natürlichsprachlicher Zeichen gemäß den entsprechenden natürlichsprachlichen grammatischen Regeln ausgedrückt wird. Je stärker sich ein Projekt jedoch auf digitale Informationstechnologie verlässt, umso schwerer fällt die Antwort auf die Frage, was eigentlich mit 'Forschungsdaten' gemeint ist: In webbasierter Kommunikation ist jede Information ein digitales Datum. Genau aus dieser Perspektive, nämlich aus der Sicht einer virtuellen webbbasierten Forschungsumgebung in Gestalt des DFG-Projekts VerbaAlpina sind die folgenden Ausführungen zu verstehen. Die aufgeworfenen Fragen sind jedoch keineswegs projektspezifisch, sondern ganz grundsätzlicher Natur.
Formal ist also der inhaltliche Unterschied zwischen den gleichermaßen als Code realisierten Objektdaten, Metadaten und analytischem Text gar nicht zu greifen. Insofern kann man sich - möglicherweise speziell aus geisteswissenschaftlicher Sicht - nicht mit der Definition von "Forschungsdaten" einverstanden erklären, wie sie jüngst von der Bibliothek der Technischen Universität München in einem Statement zum "Forschungsdatenmanagement" formuliert wurde , denn dort wird expressis verbis und kategorisch zwischen "Textpublikationen" und "Forschungsdaten" unterschieden. Zentral ist die Tatsache, dass die unterschiedlichen Inhaltstypen in der Präsentation und Analyse oft eng mit einander verwoben sind, denn es ist ja nicht nur möglich, sondern wünschenswert, die verbalen Ausführungen direkt auf die annotierten Objektdaten sowie deren Visualisierung zu beziehen; gerade aus dieser Verschränkung gewinnen zeitgemäße Publikationsformen ihren Mehrwert und ihre Attraktivität (vgl. das Editorial des hier genutzten Publikationsportals Korpus im Text, [KiT]). Bei konsequenter Nutzung von Webtechnologie ist eine klare Trennung zwischen Dokumentation, Visualisierung, Wissenschaftsdiskurs ('Text') kaum möglich und häufig gar nicht sinnvoll; daher lassen sich die im Rahmen eines Projekts zusammenkommenden Daten vernünftigerweise nur im Verbund speichern und konservieren.
3. Wo und wie sollen Forschungsdaten abgelegt werden?
Nun erhebt sich allerdings die alles andere als triviale Frage, wo digitale Projekte dauerhaft gespeichert werden sollen. Die rein physische Bewahrung der digitalen Daten stellt dabei eigentlich keine besondere Herausforderung dar. Hier geht es lediglich um technische Aspekte, und wenigstens im Umfeld der Münchner Hochschullandschaft existiert mit dem Leibniz-Rechenzentrum (LRZ) auch eine Institution, die die unbefristete Speicherung der elektronischen Daten sowie deren Integrität garantieren kann. Allerdings betont das LRZ, dass sich diese Garantie ausschließlich auf die rein physische Dimension der Daten erstreckt: Derjenige, der dem LRZ digitale Daten überantwortet hat, kann mit Sicherheit davon ausgehen, dass er diese zu einem beliebigen Zeitpunkt Bit für Bit und Byte für Byte vom LRZ zurückerhält. Im ungünstigsten Fall kann es aber dazu kommen, dass die Kenntnis über die Bedeutung bzw. Interpretation dieser Bits und Bytes verloren gegangen ist. Immerhin lässt sich festhalten, dass es, zumindest in Deutschland, für die Aufgabe der physischen Datenbewahrung eine prädestinierte Kategorie von Institutionen gibt: eben die Rechenzentren, die mit regional aufgeteilten Zuständigkeiten in der ganzen Republik vertreten sind.
Wesentlich komplexer ist die Anforderung, die korrekte Interpretation der Nullen und Einsen in einer dergestalt 'robusten' Weise zu dokumentieren, dass sie möglichst unabhängig von technischen Rahmenbedingungen, Vorkenntnissen und unabhängig von Zeit und Ort rekonstruierbar und verständlich ist. Die entsprechende Dokumentation hat man sich in Schichten vorzustellen, die vom ganz Elementaren (den Nullen und Einsen) über (bei Texten; Bild und Ton entsprechend übertragen) die Zeichenkodierung bis hin zu den höchsten Abstraktionsstufen wie z.B. dem Gesamtgegenstand oder zuweisbaren Schlagworten reichen. All diese Informationen kann man unter dem Schlagwort 'Metadaten' zusammenfassen. Die Vergabe, Erfassung und Verwaltung von Metadaten ist ein Aufgabengebiet, für das die Rechenzentren eigentlich nicht prädestiniert erscheinen, und es stellt sich die Frage nach Institutionen, die genau dafür geeignet wären.
In Betracht kommen in diesem Zusammenhang die in den letzten Jahren mit teils massiver Förderung entstandenen Strukturen, die meistens als Repositorien (nach engl. repositories) bezeichnet werden. Zu nennen sind hier in erster Linie wohl der Clarin-D-Verbund, DARIAH-DE oder auch die D-Grid-Initiative, die „eine nachhaltige Grid-Infrastruktur in Deutschland aufbaut, um Informations- und Wissenstechnologien dezentral für die Wissenschaft nutzbar zu machen“. Im Einzelnen ist das Verhältnis der drei Initiativen zueinander nicht sehr transparent.
Es steht vollkommen außer Frage, dass hier grundlegende und wegweisende Modelle entwickelt wurden. Dennoch ist die Situation beunruhigend, denn es handelt sich in allen Fällen um per definitionem befristete Projekte und damit um durchaus prekäre Provisorien, die man nicht als 'Lösungen' betrachten kann. Die Verantwortung für Bewahrung, Verfügbarkeit und Pflege von Forschungsdaten (im oben skizzierten Sinn) müssen jedoch auf Dauer gestellte und - so weit das absehbar ist - maximal beständige Institutionen übernehmen. Prädestiniert für diese wirklich zentrale Aufgabe erscheinen die Bibliotheken, die seit Jahrhunderten für die Bewahrung von Wissen zuständig gewesen sind; unabhängig von der Veranwortlichkeit ist dagegen die Frage, ob entsprechende Repositoriumsdienstleistungen dann bibliotheksintern oder in Kooperation mit den großen Rechenzentren durchgeführt werden:
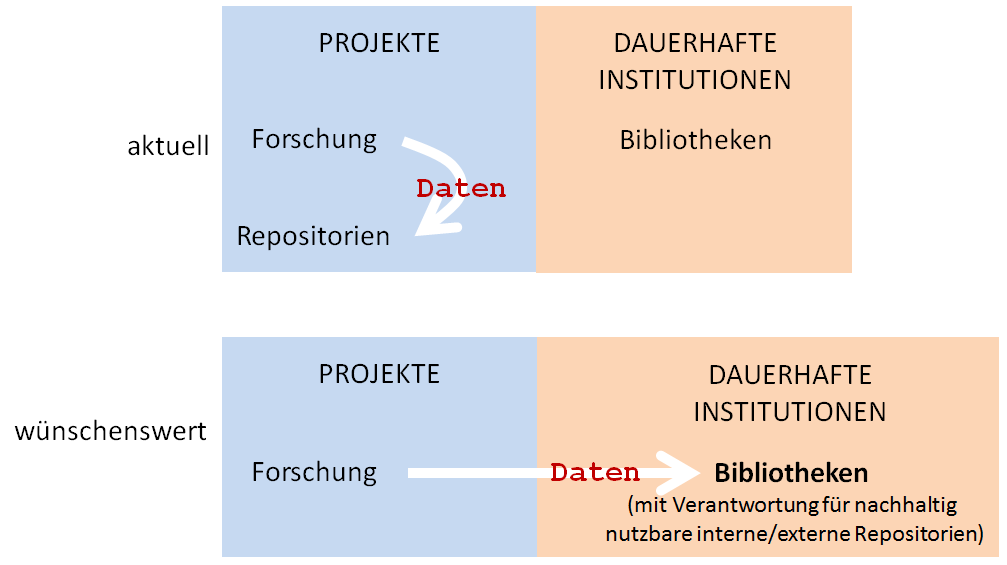
Institutionalisierung der Verantwortung für Nachhaltigkeit
Tatsächlich haben sich etliche Bibliotheken dieser wichtigen Aufgabe bereits gestellt, wie z.B. die UB der LMU München, so dass gewissermaßen parallele Strukturen, polemisch gesagt: konfessionell getrennte Datenfriedhöfe, entstehen, die zudem nicht miteinander verknüpft sind. So werden die in sich gut strukturierten Metadaten von Clarin nicht systematisch in die Recherchedienste der Bibliotheken ('Kataloge') eingespeist. Vielmehr werden die Clarin-Metadaten über eine öffentliche Schnittstelle exportiert (OAI-PMH) und es bleibt den Bibliotheken überlassen, was sie in ihre Rechercherdienste übernehmen. Hier dürfte eine informationstechnisch nicht mehr gerechtfertigte (s.o.) Präferenz auf 'Publikationen' im Sinne von analytischem Fließtext liegen. Es bedarf zwar keiner Erinnerung, dass die großen Suchmaschinen des Internets mittlerweile zu einer Parallelwelt der Bibliothekskataloge geworden sind; das ist aber noch kein Grund, sogar solche Forschungsumgebungen aus den Katalogen auszuschließen, die sie selbst mit einem Digital Object Identifier (DOI) versehen.
Im Hinblick auf die Archivierung sind die inhaltlich verschiedenen Datenklassen (Objektdaten, Metadaten, Textdaten) also gleichzusetzen; damit soll jedoch die Bedeutung des Fließtextes keineswegs abgewertet werden. Das Gegenteil ist der Fall. Es gilt ja, nicht nur die Daten zu konservieren, sondern die eigentliche Herausforderung besteht darin, sie in langfristig nachnutzbarer Weise verfügbar zu halten. Für diesen Zweck ist die Archivierung 'nackten' Programmcodes jedoch nicht hinreichend; es ist vielmehr unbedingt erforderlich, die Codeentwicklung, d.h. die jeweils innovativen Teile auch verbal zu kommentieren; dazu lässt sich gut sogenannter Pseudocode verwenden. Wenn die Bibliotheken also die Verantwortung für die Thesaurierung digital gefassten Wissens in der skizzierte Weise übernehmen, dürfen sie die Autoren auch darauf verpflichten, eine verbale Dokumentation der Programmierung zu liefern.
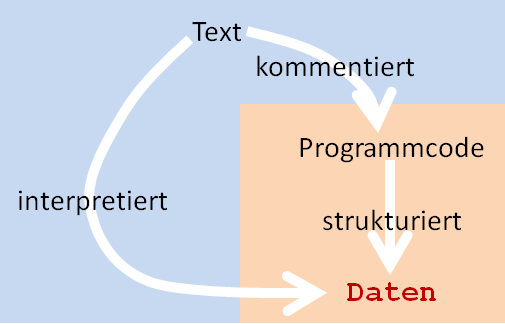
Text und Code
Die nötige Institutionalisierung der Forschungsdatensicherung sollte also auf einem möglichst transparenten und verlässlichen Weg erfolgen; auch im Hinblick auf die Verlässlichkeit haben die Autoren ihren Beitrag zu leisten: Sie sind in der Pflicht, stabile und daher gut zitierbare Versionen ihrer Projekte zu produzieren.
Keinesfalls sachdienlich wäre es dagegen, wenn die Institutionalisierung mit einer strengen Reglementierung oder gar mit der Vorgabe eines spezifischen Standards einherginge.
Sehr viel wäre jedoch gewonnen, wenn sich die Förderungseinrichtungen, insbesondere die DFG, entschließen würden, den Projekten einerseits und den Bibliotheken andererseits allgemeine Richtlinien zu empfehlen; das wäre zweifellos auch im Sinne der Begutachtung.
Aus Sicht von Nachhaltigkeit und Nachnutzbarkeit stellen komplexe Webanwendungen, die der Sammlung, Verwaltung und Publikation von Forschungsdaten dienen, so wie dies etwa bei VerbaAlpina der Fall ist, eine besondere Herausforderung dar. Die entsprechenden Portale sind zwar nicht Bestandteil der Forschungsdaten selbst, sie sind jedoch mit ihren administrativen und analytischen Funktionen für deren Nutzbarkeit mehr oder weniger unerlässlich. Somit ist die Bewahrung der Funktionalität dieser Webanwendungen eigentlich ebenso bedeutsam wie die nachhaltige Sicherung der Forschungsdaten selbst. Das zentrale Problem dabei besteht darin, dass die dauerhafte technische Funktionsfähigkeit nur durch ständige Anpassungen an die Weiterentwicklung der im Web verwendeten Rahmentechnologien gewährleistet werden kann. Die Übernahme der Verantwortung für die nachhaltige Bewahrung von Forschungsdaten erfordert daher zwangsläufig auch die Einrichtung eines für die entsprechende Pflege der Webanwendungen zuständigen Dienstes, der mit einigem Aufwand verbunden ist und entsprechend dauerhaft finanziert werden muss.
Versuchscharakter in diesem Umfeld hat das Unterfangen, das vollständige VerbaAlpina-System, also sämtliche Daten und Module, in einer lauffähigen Serverinstallation auf einem Server der Universitätsbibliothek München in einer gekapselten Umgebung dauerhaft verfügbar zu halten; Benutzername: „verba“, Passwort: „-hNK\8SS“), unabhängig von der Weiterentwicklung der Serversoftware. Unter der genannten Internetadresse ist aktuell (März 2017) die eingefrorene VerbaAlpina-Version 16/2 abrufbar. Diese Version wird bei Abschluss des Projekts durch die dann letzte VerbaAlpina-Version ersetzt werden. Ob und inwieweit dieses in Zusammenarbeit mit der UB gewählte technische Verfahren erfolgreich sein wird, lässt sich aus jetziger Sicht nicht sagen. Zweifellos problematisch ist die vielfältige Vernetzung webbasierter Forschungsumgebung, denn die in sich dynamische Verflechtung mit umgebungsexternen anderen Projekten und Webdiensten kann selbstverständlich nicht mit 'eingefroren' werden.
4. Ein mögliches Szenario
Vorstellbar wäre folgende Konstruktion, die sich im Grunde an dem altbewährten Zusammenspiel zwischen Autor(en), herausgebender Institution und Verlag(en) der vordigitalen Welt orientiert: Die Rolle der Verlage könnten die wissenschaftlichen Bibliotheken übernehmen, die die Qualitätssicherung an wissenschaftliche Institutionen/Partner delegieren könnten. Die Etablierung eines entsprechenden Labels mit Wiedererkennungswert, mit dem diese Partner gekennzeichnet würden, wäre wünschenswert. In Abstimmung mit der DFG sollten u.a. Art und Umfang der jeweils zu erfassenden Metadaten festgelegt werden. Das Verfahren könnte allgemein ungefähr folgendermaßen graphisch abgebildet werden:
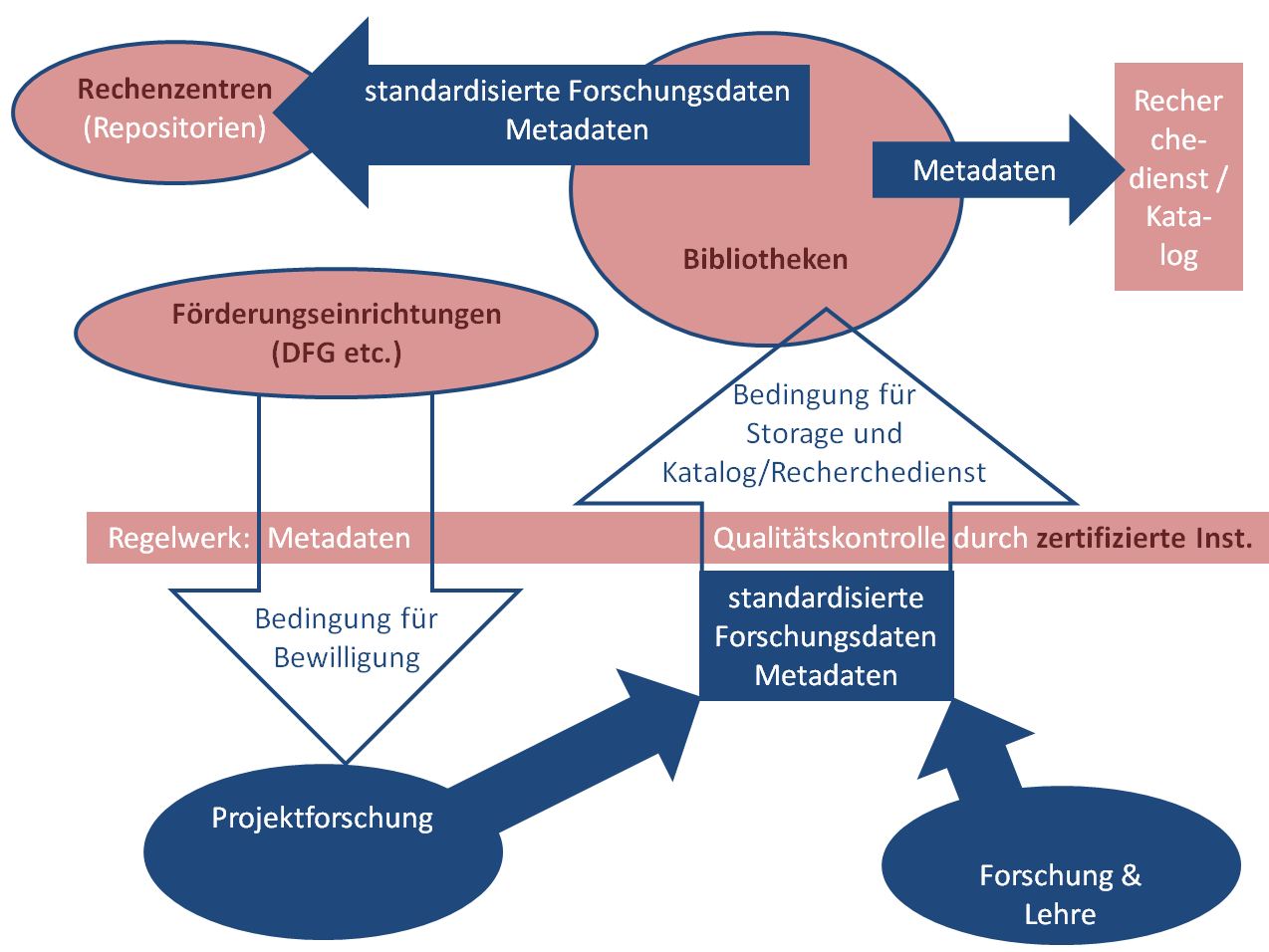
/var/cache/html/kit/html/wp content/uploads/Nachhaltig Regelwerk 2
Speziell für die Erfassung von Programmcode, der, wie dargelegt, ganz wesentlicher Bestandteil einer wissenschaftlichen Publikation sein kann, könnte ein Verfahren empfohlen werden, wie es jüngst in einem Entwurf zu einem Merkblatt für die Abfassung von sog. Mediendissertationen an den geisteswissenschaftlichen Fakultäten der LMU niedergelegt wurde:
Sofern es sich um die Entwicklung eines Computerprogramms handelt, besteht die eigentliche Promotionsleistung dabei nicht in der Programmierungsarbeit, sondern in der Entwicklung von Konzepten und Algorithmen, die, bezogen auf den fachwissenschaftlichen Gegenstand, eine signifikante Innovation darstellen.
Der dauerhafte Nachweis der Promotionsleistung erfolgt zum einen durch eine ausführliche verbale Beschreibung der Konzepte und Algorithmen in einer für den technischen Laien verständlichen Form. Zusätzlich müssen die Teile des Programmcodes, die die o.g. signifkante Innovation darstellen, in sogenanntem Pseudocode illustriert und kommentiert werden. Diese Kommentierung muss in einer Weise erfolgen, die es einem erfahrenen Programmierer ermöglicht, die volle Funktionalität der entwickelten Konzepte auch ohne Kenntnis des konkreten Programmcodes neu zu realisieren oder auf andere Bereiche zu übertragen. Soweit möglich und sinnvoll, sollten Funktionalität und (ästhetische) Gestaltung samt Usability durch Abbildungen (Screenshots) dokumentiert werden.