
| Der vorliegende Artikel wurde für die DRV Sommerschule 2018 geschrieben (Romanistische Linguistik im Zeitalter der Digital Humanities: generative und kognitive Theorien, LMU, 4. – 7. September 2018). |
1. Ein Rahmen
Im Titel dieses Beitrags ist vom "Rahmen der digital humanities"1 die Rede. Die Ausdrucksweise verdient ernst, d.h. in diesem Fall: wörtlich, genommen zu werden; denn damit ist nicht gemeint, dass Etwas (Linguistische Theorien) vor dem Hintergrund von etwas Anderem (digital humanities) betrachtet wird. Es soll vielmehr eine Konzeption identifiziert werden, in der die digital humanities als solche, an und für sich, als ein spezifischer Rahmen für Forschung und Wissensvermittlung anzusehen sind. Diese Auffassung, die grundsätzlich auch vom Center for Digital Humanities der LMU (ITG) getragen wird, fasst die Digital Humanities also nicht als eine selbständige Disziplin in Ergänzung der bereits etablierten Disziplinen (wogegen im Übrigen schon die pluralische Form des englischen Ausdrucks spricht), sondern als einen Komplex methodologischer Grundeinstellungen und daraus resultierender Optionen, in den die bestehenden Disziplinen früher oder später transferiert werden2; in diesem Sinn mag man auch von einer ‘Bewegung’ sprechen, die allerdings in einer starken disziplinären Kontinuität zur analogen Forschungswelt steht – das darf neben der zu Recht, und oft emphatisch, hervorgehobenen methodologischen Neuheit nicht übersehen werden.
1.1. Ein digitaler Rahmen
Die vollkommen veränderten Rahmenbedingungen resultieren aus der umfassenden Digitalisierung; dafür ist der Einsatz elektronischer Datenverarbeitung notwendig, aber keineswegs hinreichend, denn die digital humanities stützen sich darüber hinaus grundsätzlich auf die - natürlich ebenfalls digitalen - Neuen Medien, genauer gesagt: auf Webtechnologie. Sie erfassen so zwangsläufig sämtliche Prozeduren und Dimensionen der Wissenschaftskommunikation (vgl. Krefeld 2017c) und stärken in substantieller Weise das immer schon zur Wissenschaft gehörende Kooperationsprinzip. Auch ambitionierte und durchaus repräsentative Projekte lassen gerade in dieser Hinsicht zu wünschen übrig. Ein lehrreiches Beispiel liefert der World Atlas of Linguistic Structures (WALS; vgl. Dryer/Haspelmath 2013). Diese typologisch außerordentlich weit angelegte Unternehmung bezieht ihre Dokumentation offenbar ausschließlich aus linguistischer Literatur und nicht direkt aus Korpora, bzw. aus dem Sprachgebrauch im Internet. Das Potential des Internets zur Datenerhebung bzw. zur direkten Datenextraktion wird also ebenso wenig genutzt wie die Option den Nutzern (seien sie Linguisten oder Sprecher) die Möglichkeit zu geben, Daten hinzu zu fügen. Die Dokumentation ist daher – nicht zuletzt im Hinblick auf hervorragend dokumentierte und weit verbreitete Standardsprachen äußerst lückenhaft (von deren Dialekten ganz zu schweigen). So wird bei der Erfassung des Vorhandenseins/Fehlens vorderer gerundeter Vokale das Italienische nicht berücksichtigt (Maddieson 2013b); berücksichtigt wird dagegen das Fehlen im (sehr gefährdeten) Rätoromanischen von Scharans (Sutselvisch) nicht jedoch das Vorhandensein im Rätoromanischen des Oberengadins (Puter) usw. Dergleichen leicht ermittelbare und durch Sprecher zuverlässig belegbare Informationen könnten wirklich in effizienter Weise vervollständigt werden.
Zugespitzt darf man sagen, das erst durch den konsequenten Einsatz von Webtechnologien die wissenschaftliche res im strengen Sinn publica wird. In ganz unmittelbarer Weise ergeben sich neben den medialen daher auch vielfältige und aktuell stark diskutierte institutionelle Implikationen; sie betreffen insbesondere das komplexe Forschungsdatenmanagement, das mindestens die folgenden Leistungen garantieren muss:
- inhaltliche Erschließung durch Metadaten,
- verläßliche Auffindbarkeit (z.B. durch eindeutige DOIs),
- Textstabilität der Publikation,
- permanente Zitierbarkeit,
- Datenaustauschbar und –erweiterbarkeit,
- dauerhafte Sicherung,
- wissenschaftliche Nachnutzbarkeit.
Hier besteht großer Regelungsbedarf, der das Zusammenspiel von Forschungsprojekten, Bibliotheken und Repositorien (idealerweise bei großen Rechenzentren) betrifft (vgl. die Vorschläge in Krefeld/Lücke 2017a); jenseits der zeitlich befristeten Projekte und der physischen Aufbewahrung von Daten in Repositorien bleiben die großen Bibliotheken als grundsätzlich auf Dauer eingerichtete Institutionen der Wissensthesaurierung und Wissenserschließung auch in der virtuellen Forschungskommunikation unverzichtbar - entbehrlich geworden sind dagegen die Verlage, deren eigentliche Aufgabe ja in der Verbreitung und Vermarktung gedruckten Wissens und in nichts anderem bestand.3 Da nun all diejenigen, die sich schon jetzt auf das skizzierte Format einlassen de facto eine große und wachsende Kommunikationsgemeinschaft bilden, ist die Konventionalisierung elementarer Regeln im gemeinsamen Interesse; das gilt z.B. für die Nutzung standardisierter Formate und den Verzicht auf die Entwicklung proprietärer Lösungen. Die Teilnahme an der wissenschaftlichen Kommunikationsgemeinschaft bildet gewissermaßen ein forschungsethisches a priori, wie es von Karl Otto Apel 1973 in vielleicht allzu optimistischer Weise für jede Sprachgemeinschaft (vollkommen unabhängig von wissenschaftlichen Gegenständen) angenommen wurde. Dieses a priori verpflichtet alle Teilnehmer zur kontinuierlichen Verbesserung des Kommunikationsflusses; genau in diesem Sinne sind auch die bekannten FAIR-Prinzipien zu verstehen, die von Forschungsdaten fordern, findable (F), accessible (A), interoperable (I) und re-usable (R) zu sein.
Zu den Grundregeln gehört die Beachtung bestimmter Anforderungen hinsichtlich der Datenqualität. Denn das große Potential des medialen (und sehr bald hoffentlich auch institutionellen) Rahmens kann sich nur dann konstruktiv entfalten, wenn die Forschungsdaten - unabhängig von ihrer inhaltlichen Substanz - in transparenter Weise modelliert, strukturiert und formatiert werden. Dazu sagt Stephan Lücke aus Sicht des Projekts VerbaAlpina:
"Unter Datenmodellierung versteht VerbaAlpina die theoretische Entwicklung der Gliederung von zunächst unstrukturiertem Datenmaterial. Im Wesentlichen geht es dabei um die Definition von sog. Entitäten, also einer Klasse von Einzelobjekten, denen eine bestimmte Art und Anzahl von Attributen (= Eigenschaften) gemeinsam ist. Im Zuge der Datenmodellierung erfolgt auch die Festlegung der Beziehungen zwischen den unterschiedlichen Entitäten.
Von der Datenmodellierung sind zu unterscheiden die Datenstrukturierung und das Datenformat. Mit Datenstrukturierung ist die konkrete Anwendung des theoretischen Datenmodells auf einen Datenbestand gemeint, als deren Ergebnis eine strukturierte Repräsentation der Daten etwa in Gestalt einer oder mehrerer Tabellen vorliegt. Ein strukturierter Datenbestand kann wiederum in unterschiedlichen Datenformaten abgebildet werden (z.B. in Tabellenform = relationales Datenformat, XML-Format usw.), wobei häufig eine Transformation von einem in ein anderes Format möglich ist." (Lücke 2018)
Für das Fachverständnis ist die Datenmodellierung von grundlegender Bedeutung; denn von ihr hängt ab, ob und in welchem Ausmass eine disziplinäre Kontinuität zur analogen Forschungswelt aufrechterhalten werden soll. Darauf weist auch Fotis Jannidis nachdrücklich hin:
"Insgesamt kann man kaum überschätzen,wie wichtig Datenmodelle und die Datenmodellierung für die Digital Humanities sind. Es gibt einflussreiche Stimmen, die sie für den Kern der Digital Humanities halten (McCarty 2005), da die Modellierung der Punkt ist, wo das geisteswissenschaftliche Verständnis eines Weltausschnitts | und die Kompetenz zur formalen Modellierung zusammentreffen und im besten Fall neue Fragestellungen und neue Forschungen ermöglchen." (Jannidis 2017, 107f.)
Strukturierung und Formatierung dienen dagegen dem Funktionieren der Forschungskommunikation, deren Optimierung weithin in der Hand der einsichtigen Forscher liegt. Der wichtigste erste Schritt besteht darin, Forschungsdaten in Form eines strukturierten elektronischen Textes verfügbar zu machen (vgl. Lücke 2017). In erster Linie bieten sich relationale Formate in Gestalt von Tabellen an; sie setzen ja bereits Strukturierung voraus, denn jede Zeile/Spalte impliziert rein formal eine strukturierende Kategorie, die allerdings modellkonform spezifiziert werden muss; im Fall eines basalen binären Codes, z.b. im Graphikformat JPG, ist diese Voraussetzung noch nicht gegeben. Deshalb ist Folgendes festzuhalten:
- strukturierte Daten lassen sich leicht auswerten und konvertieren;
- nur strukturierte Daten erlauben fein granulierte Metadaten, so dass es möglich wird, auch eine einzelne Datensätze dauerhaft zu identifizieren (z.B. mittels einer DOI).
Selbstverständlich ist es unbedingt wünschenswert, sowohl bei der Strukturierung der Objekt- und Metadaten als auch bei der Formatierung auf standardisierte oder wenigstens quasi-standardisierte Entitäten und Attribute zurückzugreifen. Einige nützliche Angebote, die im Folgenden in kleiner Auswahl erwähnt werden, sind bereits verfügbar.
1.2. Ein digitaler Rahmen mit semantischem Netz
Bildquelle https://commons.wikimedia.org/wiki/File:L-Netze.png
Außerordentlich komplex und erst ansatzweise umgesetzt ist die in der Informationstechnologie als Ontologie bezeichnete, virtuell verlässliche und standardhafte Identifizierung außersprachlicher Wirklichkeit; vor allem zwei fundamentale Fragen sind noch immer unklar, einerseits wird die kategorische Trennung von außersprachlichen Realia und ihren einzelsprachlichen Bezeichnungen nicht konsequent durchgeführt und andererseits wird die enorme Sprachvielfalt nicht systematisch abgebildet. Illustrativ, man möchte sagen emblematisch für die Art und Weise, wie die ganze Problematik in der aktuellen medialen Übergangsphase behandelt wird, ist ist die Gemeinsame Normdatei der Deutschen Nationalbibliothek (GND);4 sie diente in der Welt der gedruckten Publikationen ausschließlich der Verschlagwortung von (wissenschaftlicher und nicht wissenschaftlicher) Literatur und gewinnt nun, darüber hinaus, auch in der Welt der virtuellen Publikation im Internet an Bedeutung als allgemeines, enzyklopädisches Referenzsystem:
"Die Gemeinsame Normdatei (GND) ist eine Normdatei für Personen, Körperschaften, Konferenzen, Geografika, Sachschlagwörter und Werktitel, die vor allem zur Katalogisierung von Literatur in Bibliotheken dient, zunehmend aber auch von Archiven, Museen, Projekten und in Webanwendungen genutzt wird. Sie wird von der Deutschen Nationalbibliothek, allen deutschsprachigen Bibliotheksverbünden mit den angeschlossenen Bibliotheken, der Zeitschriftendatenbank (ZDB) und zahlreichen weiteren Einrichtungen gemeinschaftlich geführt. Die Mitarbeit in der GND erfolgt entweder über Verbünde oder nach direkter Absprache mit der Deutschen Nationalbibliothek." (Quelle)
Hier werden zahlreiche spezifische Konzepte erfasst, wie die Recherche auf OGND zeigt. So wird mit dem GND-Eintrag 4039264-8 explizit ein Normdatum für den "Sachbegriff" MILCH5 etabliert, das mit zahlreichen, nämlich 386 verschiedenen Publikationen (Stand: 14.8.2018) verknüpft ist. Gleichzeitig wird das Konzept (der „Sachbegriff“) MILCH in ein ganzes Netz anderer Kategorien eingebunden, die als "Synonyme", "Oberbegriffe", "Systematik", "andere Normdaten" und "untergeordnet" bezeichnet werden und mindestens einen, teils aber auch zahlreiche andere "Sachbegriffe" beinhalten.
| Kategoriales Bezugssystem für den "Sachbegriff" MILCH in der GND | |
| "Synonyme" | "Konsummilch", "Kuhmilch", "Trinkmilch (Quasisynonym)" |
| "Oberbegriffe" | "Körperflüssigkeit" |
| "Thematischer Bezug" | "Milchwissenschaft" |
| "Systematik" | "32.7 Milchwirtschaft"; "31.11 Lebensmitteltechnologie" |
| "andere Normdaten" | LCSH: Milk, RAMEAU: Lait, LCSH: Cooking (Milk), RAMEAU: Cuisine (produits laitiers) |
| "untergeordnet" | "Buttermilch", "entrahmte Milch", "Eselsmilch", "Fettkügelchen', "H-Milch", "Kamelmilch", "Kondensmilch", "Magermilch", "Muttermilch", "Residualmilch", "Rohmilch", "Säuglingsmilch", "Sammelmilch", "Schafmilch", "Schulmilch", "Stutenmilch", "Teilentrahmte Milch", "Trockenmilch", "Vollmilch", "Ziegenmilch" |
| Tabelle 1 | |
Es wird also durch die Kategorien "Thematischer Bezug" und "Systematik" ein sachlicher Horizont (linguistisch gesprochen: ein Frame) abgesteckt, und weiterhin wird eine hierarchische Organisation auf drei Ebenen zu Grunde gelegt, so dass dem jeweiligen "Sachbegriff" jeweils eine Ebene über- und eine untergeordnet wird:
| "Oberbegriffe" | "Körperflüssigkeit" |
| "Sachbegriff" | "Milch" |
| "untergeordnet" | "Buttermilch", "Entrahmte Milch", "Eselsmilch", "Fettkügelchen", "H-Milch", "Kamelmilch", "Kondensmilch", "Magermilch", "Muttermilch", "Residualmilch", "Rohmilch", "Säuglingsmilch", "Sammelmilch", "Schafmilch", "Schulmilch", "Stutenmilch", "Teilentrahmte Milch", "Trockenmilch", "Vollmilch", "Ziegenmilch" |
| Tabelle 2 | |
Unübersehbar ist jedoch, dass die logisch scharf zu trennenden außersprachlichen Realia ("Sachbegriffe") und ihre einzelsprachlichen Bezeichnungen in der Modellierung des Datensatzes in schwer entwirrbarer Weise ganz grundsätzlich vermischt werden: Synonyme gibt es ausschließlich im Bereich der Bezeichnungen; in der Welt der Realia ist die Kategorie vollkommen sinnlos, denn so etwas wie den Planeten, auf dem wir leben, oder die Spezies der Lebewesen zu der wir gehören, die jeweilige Stadt, in der wir uns gerade aufhalten usw., gibt es doch nur einmal - vollkommen unabhängig davon, ob wir z.B . unsere Spezies etwa im Fra. als hommes oder aber mit einem synonymen Ausdruck als êtres humains bezeichnen usw.; synonymische Relationen gibt es nur zwischen sprachlichen Zeichen. Andere Relationen bestehen dagegen auch und zunächst zwischen außersprachlichen Realia und werden sekundär an deren Bezeichnungen ‘vererbt’, so z.B. taxonomische Relationen wie etwa die Inklusion von Mengen, denn Instanzen einer Teilmenge sind immer auch Instanzen der jeweiligen Obermenge: Alle Frauen sind Menschen und alle Menschen sind Lebewesen; die jeweiligen Bezeichnungen sind dann übergeordnete und abstraktere Hyperonyme oder untergeordnete und spezifischere Hyponyme. In diesem Sinne ist MILCH in der Tat eine KÖRPERFLÜSSIGKEIT (wie die GND angibt).
In der Kategorie „untergeordnet“ der GND werden jedoch vollkommen unterschiedliche Relationen zusammengebracht:
- "Eselsmilch", "Kamelmilch", "Muttermilch", "Residualmilch", "Rohmilch", "Schafmilch", "Stutenmilch", "Ziegenmilch" bezeichnen echte Teilmengen von MILCH und konsequenterweise auch von KÖPERFLÜSSIGKEITEN; sie unterscheiden sich nur durch die produzierende Spezies und die Gewinnung;
- "Schulmilch" bezeichnet dagegen eine institutionalisierte Verwendung einer Teilmenge von MILCH.
- "Vollmilch", "Buttermilch", "entrahmte Milch, "Kondensmilch", "Magermilch", "H-Milch", "Teilentrahmte Milch", "Säuglingsmilch", "Trockenmilch" bezeichnen keine echten Teilmengen, denn es handelt sich nicht einfach um "Milch" im Sinne einer "Körperflüssigkeit", sondern um manipulierte Arten oder gar um Produkte, die aus MILCH gewonnen werden;
- zwischen "Fettkügelchen" und MILCH besteht eine Teil-Ganzes-Relation.
Die sprachliche Vielfalt deutet sich lediglich im minimalistischen Hinweis auf "andere Normdateien", genauer: auf englische und französische an.6 Sehr wichtig und unbedingt notwendig ist die von der DNB angestrebte Überführung der GND-Daten in Linked Data und damit die Referenz auf eindeutig sprachunabhängige KONZEPTE. Wie dieser Transfer jedoch konkret bewerkstellingt werden wird, ist nicht sehr transparent und vor dem Hintergrund der skizzierten Inkonsistenzen erscheint eine automatisierte Umsetzung in die erforderlichen prädikatenlogischen Tripel aus Klassen, Instanzen und Relationen noch problematisch; mindestens ein Set von semantisch eindeutig spezifizierten Relationen müsste doch wohl vorgegeben sein.
Sehr konsequent hat sich dagegen die 'naturwüchsige' Wikipedia von der einzelsprachlichen Beschränkung und Beschränktheit der bibliothekarischen 'Sachschlagwörter' befreit, denn die diversen einzelsprachlichen Artikel der Wikipedia zum Beispiel zur Sache MILCH (187 an der Zahl, mit Stand vom 14.8.2018) haben sämtlich eine Identifikationsnummer gemeinsam, die eben dieses außersprachliche Produkt sprachunabhängig identifiziert; die entsprechende ID (vgl. milk) ist in der linken Randspalte der Wikipedia-Artikel unter dem Button Wikidata item (bzw. auf deu. unter Wikidata-Datenobjekt) abrufbar.
Diese Wikidata Q-IDs sind Einheiten einer im Entstehen begriffenen umfassenden Ontologie, indem sie über sogenannte Statements mit anderen Q-IDs bzw. anderen im Internet eindeutig identifizierbaren Einheiten verknüpft werden (die ihrerseits wiederum in Form von Statements mit anderen Einheiten verknüpft sind usw.). Alles Statements haben die Gestalt von Tripeln aus 'items', 'properties' und 'values', in denen das mittlere Element die logische oder auch semantische Relation spezifiziert. Im Fall von MILCH ergeben sich u.a. die folgenden Verknüpfungen.
| Item | Property | Value |
| MILCH (=Q8495) | instance of (=Property:P31) | food ingredients (=Q25403900) |
| liquid (=Q11435) | ||
| subclass of (=Property:P279 | food (=Q2097) | |
| body fluid (=Q1058795) | ||
| drink (=Q40050) | ||
| color (=Property:P462) | white (=Q23444) | |
| produced by (=Property:P2849) | mammary gland (=Q189961) | |
| natural product of taxon (=Property:P1582) | mammal (=Q7377) | |
| cattle (=Q830) | ||
| has part (=Property:P527) | water (=Q283) | |
| [...] | ||
| [...] | ||
| Tabelle 3 | ||
Merkwürdigerweise finden sich hier keine 'subclasses' von MILCH, d.h. MILCH wird nicht als Oberbegriff erfasst, obwohl die spezifischen Ausprägungen ihrerseits jeweils als 'subclasses' von Milch beschrieben werden:
| Item | Property | Value | ||
| KUHMILCH (=Q10988133) | 12 Artikel | subclass of (=Property:P279) | MILCH (=Q8495) 187 Artikel | |
| MUTTERMILCH (=Q22728) | 53 Artikel | |||
| KOLOSTRUM (=Q192746) | 52 Artikel | |||
| SCHAFMILCH (=Q2736146) | 15 Artikel | |||
| ZIEGENMILCH (=Q1418287) | 11 Artikel | |||
| [...] | ||||
| Tabelle 4 | ||||
Es ist unnötig darauf hinzuweisen, dass der Identifikation der außersprachlichen Realia (zu denen selbstverständlich auch Abstracta zähen) eine grundlegende Bedeutung zukommt. Im Detail muss die Granulierung stark verfeinert werden; sprachwissenschaftliche Projekte z.B. aus der Lexikologie, Lexikographie oder kognitiven Linguistik sollten daher - im Sinn der 'digital-humanitären' Kooperation - die Wikidata-Plattform und 'linked open data' mit entsprechende neuen Q-IDs und auch Tripeln anreichern. Allerdings lässt sich nicht übersehen, dass die Konzeption der 'properties' wegen ihrer unklaren, reichlich beliebig erscheinenden Vermischung logisch elementarer Relationen und semantischer Spezifizierungen zu schwerwiegenden Inkonsistenzen führt.
Aus prädikatenlogischer Sicht ist die uniforme Tripeldarstellung von vorneherein problematisch, da sie suggeriert, jede 'property' entspräche einem zweistelligen Prädikat, dem jeweils 'item' und 'value' als Argumente zugeordnet wären. Davon kann jedoch nicht die Rede sein, wie schon die wenigen in Tabelle 4 genannten 'properties', ganz eindeutig zeigen:
- 'Instance', 'subclass' und 'has part' stehen nicht für 'Prädikate' im logischen Sinn; die Ausdrücke geben zwei grundverschiedene Informationen, die jedoch nicht formal als verschieden gekennzeichnet sind.
- bei den durch diese 'properties' angeschlossenen 'values' handelt es sich im zitierten Beispiel um einstellige Prädikate; diese 'properties' drücken also die Funktion des 'value' aus, ohne eine eigene prädikatenlogische Funktion zu besitzen;
- die einstelligen Prädikate implizieren bestimmte logische Relationen, die durch die 'properties' beschrieben werden: Im Fall von 'instance' wird der 'item' als einzelnes Exemplar/einzelne Ausprägung einer Klasse (= 'value') behandelt; es handelt sich, mit anderen Worten, um eine nicht quantifizierte Prädikation (formal etwa: φ(x) bzw. value(item), d.h. 'item' ist ein 'value'.) Im Fall von 'subclass' liegt dagegen eine quantifizierte Allaussage vor, da alle Exemplare des 'item' gleichzeitig Exemplare des 'value' sind (formal: ∀x 'value'x,d.h. 'alle Exemplare der Klasse 'item' sind auch Exemplare der Klasse 'value''). Die Relation ist taxonomisch und hierarchisch, da die Klasse 'item' der Klasse 'value untergeordnet ist. Mit 'has part' wird ebenfalls eine einstellige, jedoch weder quantifizierte, noch taxonomisch-hierarchische Relation ausgedrückt, denn 'item' ist nicht ein Exemplar/eine Ausprägung, sondern eine Konstituente von 'value'; es handelt sich, semantisch gesagt, um Teil-Ganzes-Beziehungen;
- die 'properties' 'produced by'/'product of' stehen dagegen für zweistellige Prädikate, deren Argumente von 'item' und 'value' gebildet werden; formal also etwa φ(x, y) , bzw. property(item, value);
- wiederum vollkommen anders ist 'color' zu beurteilen; diese 'property' macht überhaupt keine Aussage über die einstellige Prädikation value(item), d.h. white(milk), sondern nur über die 'value', indem sie eine übergeordnete Klasse dazu identifiziert.
Es wäre nun absolut wünschenswert, wenn diese funktional heterogenen 'properties' wenigstens in transparenten Gruppen zusammengefasst und entsprechende leicht abrufbar wären. Das ist jedoch nicht zu erkennen; die Gruppierung ist sehr unübersichtlich und primär gerade nicht an logischen Funktionen und Relationen, sondern vielmehr an enzyklopädischen Feldern ausgerichtet; konsequenter wäre es, enzyklopädische Inhalte (Realia) ausschließlich mit 'values' und 'items' und niemals mit 'properties' zu verbinden. Schon diese Bezeichnung ist für Einheiten, die prädikative Relationen ausdrücken sollen, sehr unglücklich.
1.3. Ein Rahmen für die humanities
Mit den humanities wird eine Gruppe akademischer Disziplinen adressiert, die sich in der traditionellen Organisation der europäischen, oder wenigstens: kontinental europäischen Forschungs- und Lehrfächer nicht abbildet; dazu werden im angloamerikanischen Raum die Disziplinen gerechnet, die sich mit Aspekten der menschlichen Kultur(en) und und ihrer Geschichte befassen; im Kern sind also die Geisteswissenschaften und Gesellschaftswissenschaften sowie die (Sozial)Geographie und im Grunde auch die Jurisprudenz gemeint. Eine trennscharfe, positive Bestimmung der zugehörigen Fächer ist jedoch schwierig und wahrscheinlich auch gar nicht sinnvoll; wichtiger ist aus sprachwissenschaftlicher Sicht vielmehr der Umstand, dass die engere, in Europa und hier vor allem in der deutschsprachigen Tradition verwurzelte Kategorie der philology/Philologie bzw. der daraus hervorgegangenen, noch spezifischeren Gruppe der linguistics/Linguistik vermieden wird. Es muss aber gleich hinzu gesetzt werden, dass der weitere Horizont der humanities keinesfalls den Verzicht auf Bereitstellung genuin disziplinärer Daten impliziert; die Disziplinen sind, ganz im Gegenteil, in der Pflicht spezifische Korpora zu schaffen, bestehende Korpora zu erweitern und in ihrer Nutzbarkeit zu verbessern.7 Entscheidend ist vielmehr, dass der über Philologie und Linguistik hinausreichende Gesichtskreis dazu einladen will sprachliche Daten in sinnvoller Weise mit nicht sprachlichen Daten abzugleichen und sie womöglich gemeinsam zu kumulieren. Die disziplinär getrennten Forschungsdaten und ihre jeweilige Struktur müssen deshalb gemeinsame Kategorien aufweisen. Sehr elementare und keineswegs triviale Gemeinsamkeiten sind Geo- und/oder Chronoreferenzierungen; sie sind von großer Bedeutung für die Variationslinguistik und für die Sprachgeschichtsschreibung.
Ein illustratives Beispiel liefert der diachrone Sprachkontakt, denn die Rückführung dialektaler (und später womöglich standardsprachlicher) Formen auf Substrat- oder Superstrateinflüsse ist oft hypothetisch. Archäologische Evidenz kann hier oft gute, unterstützende Argumente liefern. So zeigt z.B. diese Karte einige österreichische Dialektbelege von Keller < lat. cellarium und von Kaser < lat. casearea, beide in der Bedeutung 'Almhütte', gerade dort, wo auch römische Inschriften und antike Ortsnamen überliefert sind. Dadurch wird die Annahme einer direkten Entlehnung aus dem lateinisch-romanischen Substrat plausibel.
2. Linguistische Theorien - fallen teils aus dem Rahmen, teils durch das Netz
| Präposition | Q4833830 |
| specifier | Q2309573 |
| Tabelle 5 | |
Auch eine ganze Reihe spezifisch linguistischer 'properties' existiert bereits (vgl. diese Liste), aber hier wurde allenfalls ein Anfang gemacht. Die beide exemplarisch genannten Kategorien sind symptomatisch für den Status der Linguistik in dieser Ontologie des semantischen Webs. Präposition wurde immerhin mit den folgenden 'statements' eingebunden:
| Item | property | value |
| instance of | part of speech | |
| subclass of | adposition | |
| part of | ||
| opposite of | postposition | |
| Tabelle 6 | ||
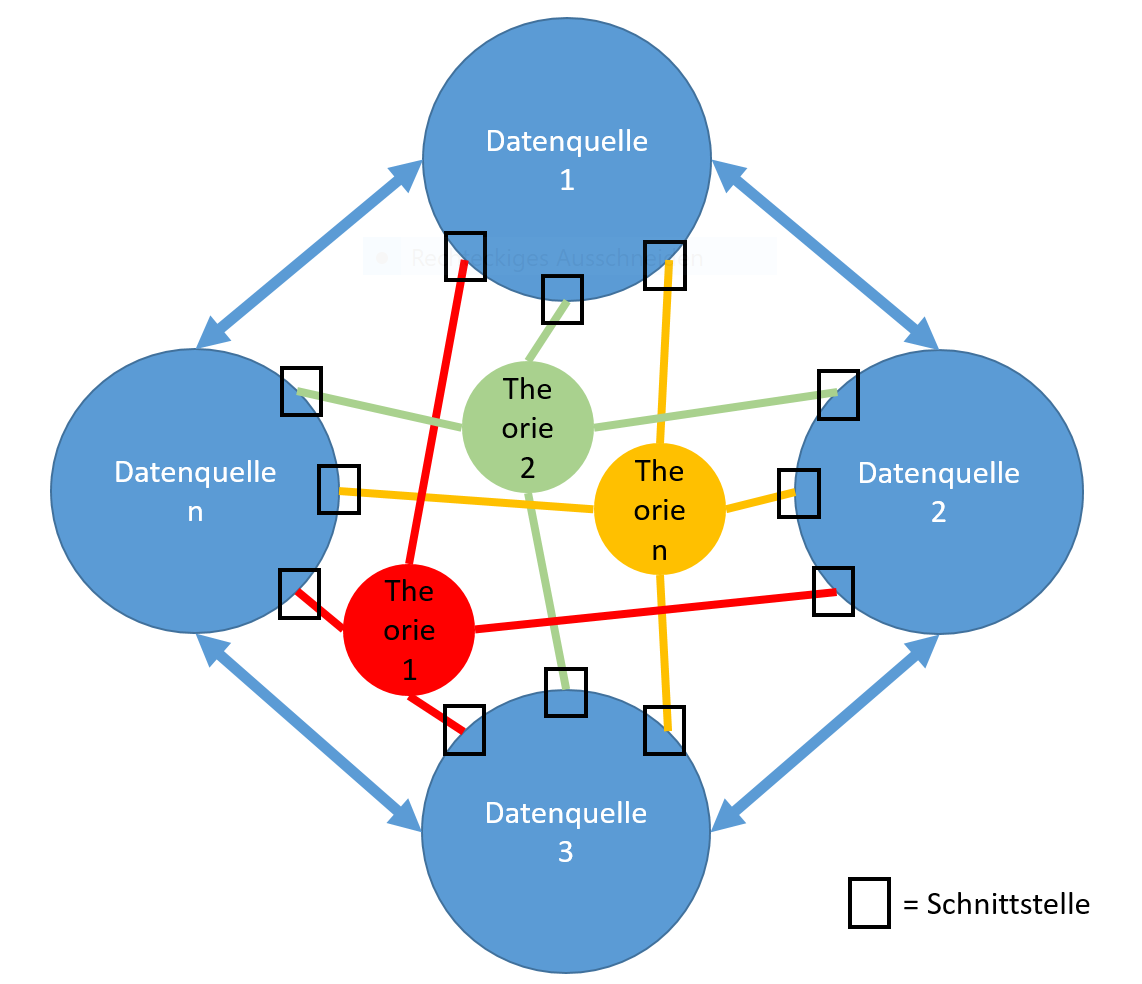
Multiple Schnittstellen
nicht als Verbindung einer Nominalphrase (NP) in Subjektsfunktion und einer Verbalphrase (VP) analysiert, wie:
[SATZ [NP] el estudiante][VP aprobarà el examen]],
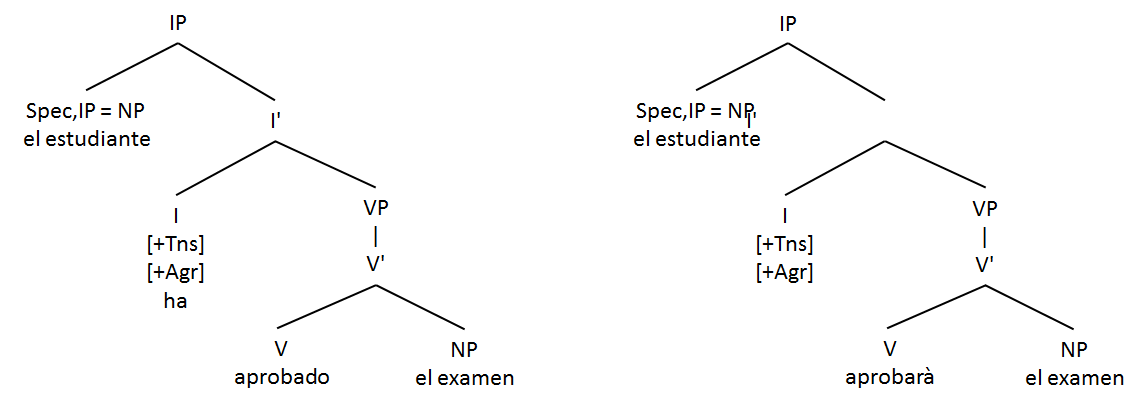
Strukturbaum aus Gabriel u.a. 2018, 42, Beispiel 12 b. (rechts) und eigener Baum zum Beispiel 12 a. (links)
| [SATZ [NP] [VP ]] | ||
| SUBJEKT | VERB | DIREKTES OBJEKT |
| el estudiante | aproberà | el examen |
| der Student | besteht | das Examen |
| Tabelle 7 |
||
| mit Komplementierer: | ich glaube, | dass dieser Student das Examen besteht |
| [CP [[C][S][O][V]]] mit finalem V | ||
| ohne Komplementierer: | ich glaube, | dieser Student besteht das Examen |
| [CP [[S][V][O]] mit V2 | ||
| Tabelle 8 | ||
Die Konstruktion der Variante ohne Komplementierer ist nur mit dem Verb an zweiter Stelle (V2) möglich und entspricht deshalb genau der Syntax des einfachen deu. Deklarativsatzes. Hauptsatz. Gabriel u.a. 2018b ziehen daraus den Schluss:
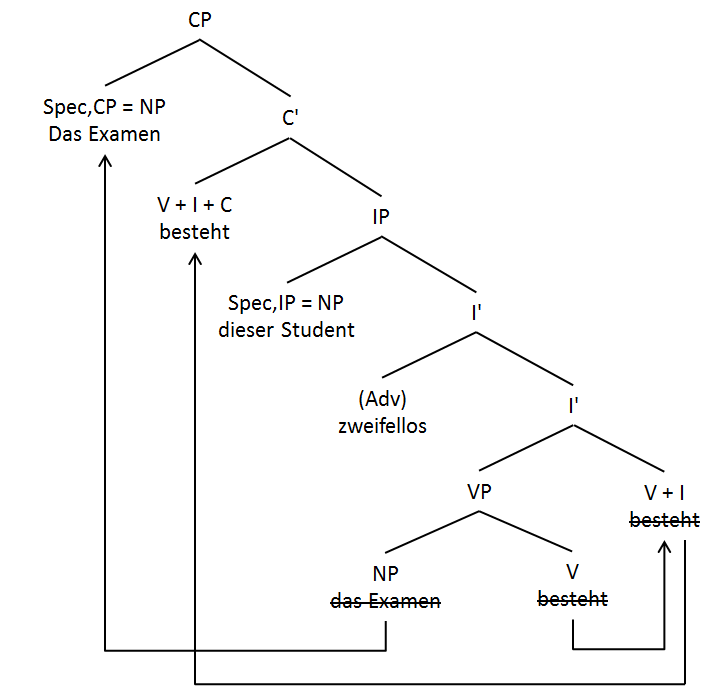
Strukturbaum eines deutschen Hauptsatzes mit initialem Objekt (aus Gabriel u.a. 2018, 45)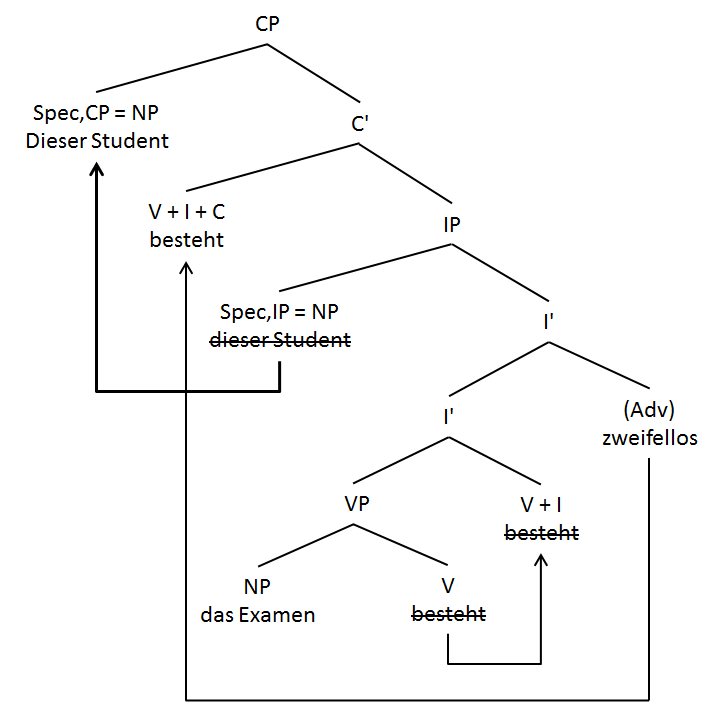
Bibliographie
- Apel 1973 = Apel, Karl Otto (1973): Das Apriori der Kommunikationsgesellschaft, in: Transformation der Philosophie, vol. 2, Frankfurt am Main, Suhrkamp.
- Dryer 2013 = Dryer, Matthew S. (2013): Expression of Pronominal Subjects, in: Dryer, Matthew S. / Haspelmath, Martin (Hrsgg.), The World Atlas of Language Structures Online, Leipzig, Max Planck Institute for Evolutionary Anthropology (Link).
- Dryer/Haspelmath 2013 = Dryer, Matthew / Haspelmath, Martin (Hrsgg.) (2013): The World Atlas of Language Structures Online, Leipzig, Max Planck Institute for Evolutionary Anthropology [Accessed on 2018-04-20] (Link).
- Gabriel u.a. 2018b = Gabriel, Christoph u.a. (2018): Grundlagen der generativen Syntax - Französisch, Italienisch, Spanisch, Berlin/Boston, de Gruyter.
- Jannidis 2017 = Jannidis, Fotis (2017): Grundlagen der Datenmodellierung, in: Jannidis u.a., 99-108.
- Jannidis u.a. 2017 = Jannidis, Fotis u.a. (2017): Digital Humanities. Eine Einführung, Stuttgart.
- Krefeld 2017c = Krefeld, Thomas (2017c): Wissenschaftskommunikation im Web, in: 17/1, VerbaAlpina-de (Hrsg.), Methodologie (Link).
- Krefeld 2018f = Krefeld, Thomas (2018): VerbaAlpina – oder: der Transfer der Geolinguistik in die digital humanities, in: VerbaAlpina 18/1, Online (Link).
- Krefeld/Lücke 2017a = Krefeld, Thomas / Lücke, Stephan (2017a): Nachhaltigkeit – aus der Sicht virtueller Forschungsumgebungen, in: Korpus im Text (Link).
- Lücke 2017 = Lücke, Stephan (2017): Digitalisierung, in: 17/1, VerbaAlpina-de (Hrsg.), Methodologie (Link).
- Lücke 2018 = Lücke, Stephan (2018): Datenmodellierung, in: VerbaAlpina | Methodologie, Online (Link).
- Maddieson 2013b = Maddieson, Ian (2013): Front Rounded Vowels, in: Dryer, Matthew S. / Haspelmath, Martin (Hrsgg.), The World Atlas of Language Structures Online, Leipzig, Max Planck Institute for Evolutionary Anthropology (Link).
- Rizzi 2016 = Rizzi, Luigi (2016): Linguistic knowledge and unconscious computations, in: Rivista internazionale di filosofia e psicologia (Link).
- Rizzi forthcoming = Rizzi, Luigi (forthcoming): The left periphery: Cartography, Freezing, Labeling, in: In Proceedings of the International Workshop on Syntactic Cartography, Beijing, Beijing Language and Culture University (Link).
- Rubino 2013 = Rubino, Carl (2013): Reduplication, in: Dryer, Matthew S. / Haspelmath, Martin (Hrsgg.), The World Atlas of Language Structures Online, Leipzig, Max Planck Institute for Evolutionary Anthropology (Link).

{kind=link}
{kind=link}