Code-Switching in der computervermittelten Kommunikation.
Eine Analyse deutsch-italienischer Facebook Beiträge.
| Abb. | Abbildung |
| Anz. | Anzahl |
| CMC | Computervermittelte Kommunikation |
| CS | Code-Switching |
| de | deutsch |
| ebd. | ebendiese/r |
| en | englisch |
| it | italienisch |
| Kap. | Kapitel |
| nn | unbekannt |
| NP | Nominalphrase |
| ot | andere |
| SNS | Social Network Site |
| vgl. | vergleiche |
| VP | Verbalphrase |
1. Einleitung
[FB 1112_520]1
1.1. Gegenstand der Arbeit
Seit der Erfindung des Computers und erst recht seit der Entwicklung des Internets und des Web 2.0 spielt sich ein großer Teil unseres Lebens online ab. Dadurch hat sich der Alltag gewandelt und uns neue Möglichkeiten in (fast) allen Bereichen eröffnet. Auch die Kommunikation ist davon betroffen, denn es wurden viele neue Wege geschaffen, mit Hilfe von Computern miteinander zu interagieren. Dabei kann beobachtet werden, dass nicht nur das Schreiben auf einer Tastatur besondere Merkmale, wie beispielsweise die Verwendung der sogenannten Emoticons, hervorbringt. Auch der Gebrauch von Sprache scheint sich gegenüber den bis dato vorherrschenden Kommunikationsarten zu ändern. Besonders interessant ist dabei der alternierende Gebrauch mehrerer Sprachen – nicht nur aus Sicht der Mehrsprachigkeitsforschung, sondern auch in Hinblick auf deren automatisierten Auswertung und Untersuchung in der Korpus- oder Computerlinguistik. Es stellen sich somit folgende Fragen: Wie erfolgt Sprachwechsel in den Facebook Beiträgen? Warum wird zwischen Sprachen gewechselt? Und gibt es eine Methode, diese zuvor gestellten Fragen auf der Basis einer computergestützten Analyse durchzuführen?
Die Geschwindigkeit, mit der immer neue Programme und Anwendungen für die virtuelle Kommunikation geschaffen werden, ist teilweise so groß, dass diese bei dem Versuch, sie genauer zu untersuchen, schon wieder veraltet sein können. Das liegt auch an der Dynamik und der gegenseitigen Einflussnahme dieser, denn nicht nur die computergestützten Plattformen formen unsere Kommunikation, auch wir selbst beeinflussen diese, indem wir bestimmte kommunikative Strategien verwenden. Ein Ziel dieser Arbeit ist deshalb theoretischer und deskriptiver Natur, denn um den Untersuchungsgegenstand dieser Arbeit bestimmen zu können, muss zunächst eine eindeutige und systematische Beschreibung der Social Network Site (SNS) Facebook. Der Fokus liegt dabei auf den Möglichkeiten der Kommunikation, die den Nutzern dort angeboten werden.2 Bei der Beschreibung und Einordnung der Kommunikation auf Facebook als computervermittelte Kommunikation (CMC) fallen die fehlende Eindeutigkeit dieser Art der Kommunikation und die Heterogenität der verschiedenen Typen und Kriterien, nach denen diese klassifiziert werden, auf. Ein grundlegendes Problem stellt in der Forschungsliteratur dabei der Medienbegriff in Hinblick auf die CMC dar, der kaum oder nur ungenügend bestimmt und abgegrenzt ist. In der vorliegenden Arbeit wird deshalb zum einen der Begriff der CMC genauer bestimmt. Zum anderen wird auch der Begriff des digitalen Medienkomplexes eingeführt, der den Computer mit all seinen Komponenten, die zusammen an der CMC beteiligt sind, beschreibt und der auch den Prozess der Digitalisierung miteinbezieht. Eine dieser Komponenten stellt das Kommunikationsmedium dar, zu dem auch Facebook gerechnet werden kann. Davon ausgehend wird gezeigt, dass Facebook Beiträge eine bestimmte Form der Kommunikation innerhalb der CMC repräsentieren und somit einen berechtigten Untersuchungsgegenstand in der Linguistik darstellen.
Neben der genauen Bestimmung der externen Faktoren, soll diese Arbeit in diesem theoretischen Rahmen auch dazu beitragen, damit aufzuräumen, die CMC als eine Kommunikationsform „im Spannungsfeld zwischen Mündlichkeit und Schriftlichkeit“ zu betrachten. Die verschiedenen sprachlichen, aber auch nicht- und parasprachlichen Merkmale der Kommunikation in den Facebook Beiträgen, die den Gegebenheiten des digitalen Medienkomplexes als auch des Kommunikationsmediums geschuldet sind, zeugen davon. Eine Auflistung und Beschreibung aller Merkmale, die typischerweise der CMC zugerechnet werden und deren Existenz in Facebook beobachtet werden kann, vervollständigt die systematische Beschreibung der Charakteristika des Untersuchungsgegenstandes.
Vor dem Hintergrund der CMC zeigt sich auch, dass viele Theorien und Modelle der Linguistik nicht mehr haltbar sind und deswegen neu überdacht werden müssen. So steckt auch die Forschung in dem Bereich der Mehrsprachigkeits- und Sprachkontaktforschung hinsichtlich der CMC noch in den Kinderschuhen. In einem empirischen Teil dieser Arbeit wird deshalb Code-Switching (CS) als eines der besonderen Merkmale, das auch in der CMC vorkommen kann, herausgegriffen und genauer untersucht. Unter CS wird dabei das Wechseln zwischen mehreren Sprachen innerhalb eines Facebook Beitrags verstanden. Bei den Sprachen bzw. den Sprachkombinationen, die dabei untersucht werden sollen, handelt es sich vorwiegend um das Deutsche und das Italienische, mit einer Betrachtung des Englischen am Rande der Auswertungen.
Die Datenerhebung für die empirische Forschungsarbeit erfolgt dabei computergestützt. Die Grundlage stellt ein für diese Arbeit erstelltes, spezialisiertes Korpus dar, in dem Facebook Beiträge gespeichert und so aufbereitet sind, dass sie mit Hilfe von Korpusabfragen ausgewertet werden können. Auch die Metadaten dieser Beiträge sowie die autobiographischen Daten der Facebook Nutzer sind in dem Korpus hinterlegt. Die Korpusannotation der textbasierten Facebook Beiträge erfolgt computergestützt. Dabei stellt die Verwendung mehrerer Sprachen innerhalb eines Beitrags eine besondere Herausforderung dar. Mit Hilfe eines speziell für die Zwecke dieser Arbeit erstellten, kombinierten Annotationsprogramms werden die Beiträge tokenisiert und den einzelnen Token sowohl die Sprache als auch die Wortart hinzugefügt. Diese Annotation hilft schließlich zum einen dabei, die Sprachverwendung zu analysieren, zum anderen CS in Facebook Beiträgen zu klassifizieren. Somit leistet die Arbeit auch einen Beitrag im Gebiet der Digital Humanities, da sie eine neuartige Methode vorstellt, wie Daten gesammelt und annotiert werden können – auch wenn dabei mehrere Sprachen enthalten sind.3
Die Auswertung der Daten zeigt die Verteilung der Sprachen innerhalb des gesamten Korpus und bestätigt die Annahme, dass es in den Facebook Beiträgen CS gibt. Es kann gezeigt werden, dass die Sprachverwendung und -verteilung im gesamten Korpus mit der in einzelnen gemischtsprachigen Beiträgen in Zusammenhang steht. Letztere werden nach einem strukturellen Ansatz in den Beiträgen klassifiziert und quantitativ ausgewertet. Es ist dabei nicht das Ziel, aus den Ergebnissen auf alle Sprachpaare und Formen der CMC vorhersagbare Restriktionen zu ziehen. Vielmehr soll darauf hingewiesen werden, dass in der CMC im Allgemeinen und den Facebook Beiträgen im Besonderen spezielle Typen von Code-Switches bevorzugt werden. Es kann beispielsweise gezeigt werden, dass in den Facebook Statusmeldungen inter-sententiales CS sowie Nomen-Switches bevorzugt werden, was auf die Kommunikationsform und deren Charakteristika zurückzuführen ist. Schließlich wird ein Ansatz vorgeschlagen, bei dem davon ausgegangen wird, dass die Verwendung bestimmter CS Typen eine Strategie darstellt, von der ausgehend Rückschlüsse auf die intendierten kommunikativen Funktionen gezogen werden können. Deshalb werden die verschiedenen CS Typen im Rahmen eines sozio-pragmatischen Rahmens analysiert. Es stellt sich dabei heraus, dass bei den Wechseln zwischen Sätzen häufig die Funktion des Social Networking, eine wichtige Rolle spielt. Bei den Sprachwechseln innerhalb eines Satzes wird CS außerdem bewusst zur Selbstdarstellung eingesetzt, um die eigene Mehrsprachigkeit, aber auch den kreativen, spielerischen und humoristischen Umgang mit Sprachen zu demonstrieren.
1.2. Aufbau der Arbeit
Die Arbeit gliedert sich in drei große Teile: Während der erste Teil (Kapitel bis Kapitel ) den theoretischen Rahmen liefert, wird in Kapitel auf die Methode und Datensammlung eingegangen. Im letzten Teil (Kapitel bis Kapitel ) werden die Ergebnisse präsentiert und diskutiert.
Nach dieser Einleitung folgt Kapitel , das einen Überblick über die externen Faktoren der computervermittelten Kommunikation und Facebook liefert. Dazu gehört auf der einen Seite eine Übersicht, wie sich Facebook entwickelt und verbreitet hat und welche Rolle es bei der Internetnutzung spielt. Die angebotenen Nutzungsmöglichkeiten werden präsentiert und es wird gezeigt, dass es sich bei Facebook um eine Social Network Seite handelt, auf der sich Nutzer miteinander vernetzen können, um sich auszutauschen und Inhalte verschiedener Art zu teilen. Zudem werden auch die primären kommunikativen Funktionen der Facebook Beiträge vorgestellt. Auf der anderen Seite werden gängige Definitionen und Termini, die in Hinsicht auf die computervermittelte Kommunikation verwendet werden, eingeführt und einige Typisierungen und Abgrenzungskriterien auf deren Anwendbarkeit für Facebook Beiträge getestet. Schließlich wird die CMC in den medialen Diskurs eingebettet. Dafür werden gängige Medienbegriffe diskutiert, um schließlich eine adäquate Definition im Hinblick auf die CMC zu präsentieren.
Kapitel beleuchtet die internen Faktoren der CMC im Allgemeinen und der Facebook Beiträge im Besonderen. Dafür wird die laufende Diskussion, wo die CMC im „Spannungsfeld zwischen Mündlichkeit und Schriftlichkeit“ zu verorten sei, präsentiert und diskutiert. Eine mögliche Verortung von Facebook Beiträgen wird geprüft und Kritikpunkte an gängigen Modellen diskutiert. Darauf folgend werden nichtsprachliche, parasprachliche und sprachliche Merkmale der CMC, die auch in den Facebook Beiträgen zu finden sind, vorgestellt und deren Existenz anhand von Beispielen belegt.
Kapitel bildet den theoretischen Rahmen für die Untersuchung des Code-Switchings in Facebook Beiträgen. Relevante Konzepte der Code-Switching Forschung werden vorgestellt und der aktuelle Forschungsstand hinsichtlich der Sprachwechsel, soweit vorhanden, in der CMC diskutiert. Das Kapitel endet mit der Präsentation von Fragestellungen, die dieser Arbeit zugrunde liegen, und der Formulierung von Hypothesen.
Kapitel beschreibt die Datensammlung für das Facebook Korpus und die hierfür erarbeiteten Methoden. Die Vorüberlegungen und Kriterien, die zur Datensammlung der relevanten Elemente geführt haben, werden vorgestellt. Die einzelnen Schritte von der Extraktion der Daten über deren Bereinigung und Aufbereitung bis hin zur Erstellung einer Datenbank, auf der das Facebook Korpus hinterlegt ist, werden präsentiert. Es folgt ein kurzer allgemeiner Überblick über die gesammelten Daten bevor im Anschluss die Methode der Korpusannotation vorgestellt wird.
In Kapitel erfolgt schließlich die Auswertung der Daten und die Untersuchung der Sprachverteilungen im gesamten Korpus sowie in den einzelnen Beiträgen. Hiervon ausgehend können erste Schlüsse über die Verwendung von Code-Switching gezogen werden. Nach der Bestimmung der strukturellen Typen des CS erfolgt eine Übersicht über die quantitative Verteilung, der eine qualitative Beschreibung nach einem sozio-pragmatischen Ansatz folgt. In einem letzten Schritt wird noch das Vorkommen nicht- und parasprachlicher Merkmale als Strategie des CS in den Facebook Beiträgen festgehalten.
Kapitel fasst die Ergebnisse der vorangehenden Kapitel zusammen und diskutiert die daraus gewonnenen Erkenntnisse. Ein Ausblick sowie das Fazit bilden den Schluss der vorliegenden Arbeit.
2. CMC auf Facebook
Man mag Facebook gut oder schlecht finden – man muss aber über Facebook Bescheid wissen. (Brommer & Dürscheid 2013, 39)
2.1. Facebook
Die Rolle von Facebook und dessen Einfluss – nicht nur auf Einzelpersonen oder kleinere Gruppen, sondern auf die gesamte Gesellschaft – sind unumstritten. Dieser Abschnitt soll eine kurze Übersicht über Facebook geben. Dafür wird die Gründungs- und Entwicklungsgeschichte in groben Zügen vorgestellt. Ein Überblick über die Verbreitung im Netz soll die Wichtigkeit der Plattform am Beispiel von Deutschland und Italien untermauern. Außerdem sollen die verschiedenen Nutzungsmöglichkeiten zum Zeitpunkt der Entstehung dieser Arbeit umrissen werden, um schließlich näher auf die kommunikativen Funktionen einzugehen. Die Charakteristika von Online Social Networks sollen ebenfalls vorgestellt werden mit einer Begründung, warum Facebook zu diesen gerechnet werden kann.
2.1.1. Entwicklung, Verbreitung und die Rolle von Facebook im Netz
Die Entwicklung von Facebook hängt stark mit dessen Verbreitung im Netz und der steigenden Anzahl an Facebook Mitgliedern zusammen. Von Anfang an orientierten sich die Entwickler an den Wünschen und Bedürfnissen der Nutzer und die Entwicklung und Gestaltung beruht zu großen Teilen auf deren Mitwirkung. So halfen beispielsweise rund 300.000 Mitglieder beim Übersetzen der Plattform in rund 70 verschiedene Sprachen ( 2013). Über eine Programmierschnittstelle (Facebook API) können Nutzer mit Programmierkenntnissen zudem selbst Anwendungen in Facebook erstellen und tragen so zur Dynamik und Entwicklung der Seite bei.
Facebook – Entstehung und Entwicklung
Die Erfolgsgeschichte von Facebook beginnt im Jahr 2004. Eine Gruppe von Studenten um Mark Zuckerberg gründet thefacebook.com als eine Präsentations- und Vernetzungsplattform für Studenten der Harvard Universität. Sie sollte die Funktion eines Jahrbuchs übernehmen, auf dem sich Studenten mit Fotos und Beschreibungen ihrer Person eintragen. Bald darauf konnten sich auch die Studenten anderer US-amerikanischer Universitäten registrieren; erst die der Eliteuniversitäten Yale, Columbia und Stanford, später auch die anderer Universitäten. Mit der Einführung der Facebook Pinnwand (aus dem Englischen Facebook Wall) gaben die Entwickler den Nutzern die Möglichkeit, anderen, mit ihnen vernetzten Personen (den Facebook Freunden), Nachrichten zu hinterlassen. Es folgte schließlich auch die Öffnung für die nicht-studentische US-amerikanische Bevölkerung und 2006 hatte jeder weltweit die Möglichkeit, Facebook zu nutzen.
Facebook hat sein Aussehen in den Jahren seit seinem Bestehen immer wieder verändert und viele Funktionen und Anwendungen sind hinzugekommen. Tabelle 1 gibt einen kurzen Überblick über die Etappen der Entwicklung und stellt zudem eine Übersicht über die Einführung neuer Nutzungsmöglichkeiten dar. Die wichtigsten, und für diese Arbeit relevanten Anwendungen werden in den folgenden Abschnitten (siehe Kapitel ) näher beschrieben.
| Datum | Ereignis |
| Feb 04 | Mark Zuckerberg und die Co-Produzenten Dustin Moskovitz, Chris Hughes und Eduardo Saverin lancieren Facebook |
| Mrz 04 | Facebook expandiert von der Universität Harvard an die Universitäten Stanford, Columbia und Yale (alles USA) |
| Sep 04 | Die Facebook Pinnwand (en. Facebook Wall) wird eingeführt, damit Nutzer ihren Freunden Nachrichten hinterlassen können |
| Mai 05 | Facebook wird mittlerweile an 800 US-amerikanischen Universitäten verwendet |
| Sep 05 | US-amerikanische Highschool-Netzwerke bekommen Zugang |
| Sep 05 | Umbenennung von thefacebook.com in Facebook |
| Okt 05 | Öffnung für internationale Schul- und Uni-Netzwerke |
| Okt 05 | Implikation von Facebook Photos |
| Apr 06 | Facebook auch auf mobilen Geräten nutzbar |
| Mai 06 | Facebook öffnet sich für Arbeitsnetzwerke |
| Aug 06 | Facebook stellt die erste Version der Facebook API (en. application programming interface) vor |
| Sep 06 | Implikation von News Feed und Mini-Feed |
| Sep 06 | Registrierung für jeden möglich |
| Mai 07 | Implikation von Marketplace Anwendung |
| Mai 07 | Implikation von Platform |
| Jun 07 | Implikation von Facebook Video |
| Okt 07 | Implikation von Facebook Platform für mobile Geräte |
| Nov 07 | Implikation von Self-service Ads Platform und der Facebook Seiten (en. Facebook Pages) |
| Apr 08 | Implikation des Facebook Chat |
| Mai 08 | Facebook Connect wird angekündigt |
| Jul 08 | Implikation von Facebook für iPhones |
| Jul 08 | Umfassende Änderungen und Erneuerung von Facebook |
| Feb 09 | Einführung des Gefällt mir-Buttons (en. Like-button) |
| Mrz 09 | Einführung der neuen Facebook Startseite |
| Jun 09 | Implikation von Facebook Usernames |
| Jul 10 | Implikation von Facebook Questions |
| Aug 10 | Implikation von Facebook Places |
| Okt 10 | Facebook Gruppen werden eingeführt |
| Dez 10 | Implikation des neuen Profils |
| Jun 11 | Implikation von Facebook Video Calling |
| Sep 11 | Facebook Chronik (en. Timeline) wird eingeführt |
| Okt 11 | Facebook für iPad eingeführt |
| Apr 12 | Facebook kündigt Übernahme von Instagram an |
| Mai 12 | Facebook geht an die Börse |
| Mai 12 | Implikation von Facebook Camera |
| Sep 12 | Implikation von Facebook Gifts |
| Jan 13 | Implikation des Graph Search (Beta-version) |
| Feb 13 | Instagram hat mehr als 100 Millionen monatlich aktive Nutzer |
| Feb 13 | Facebook kündigt Übernahme von Atlas an |
| Apr 13 | Implikation von Home |
| Jun 13 | Implikation von Video für Instagram |
| Jul 13 | Mehr als 100 Millionen nutzen Facebook auf dem Mobiltelefon |
| Aug 13 | Facebook kündigt Internet.org an |
| Dez 13 | Implikation von Instagram Direct |
| Dez 13 | Implikation von Donate |
Die Gründer von Facebook zogen schon kurz nach Gründung nach Palo Alto, Kalifornien. Mit wachsenden Nutzerzahlen und der Implikation immer neuer Funktionen stieg auch die Anzahl der Mitarbeiter und der Firmensitz bezog größere Räumlichkeiten, zuletzt in Menlo Park Kalifornien im Dezember 2011, wo sich auch heute noch der Firmenhauptsitz befindet (vgl. o.J.). Außerdem musste Platz für die Masse an Daten geschaffen werden und so eröffneten diverse Datenzentren, wie im Jahr 2010 in Prineville, Oregon oder im Jahr 2011 in Altoona, Iowa. Facebook beschäftigt zurzeit 10.955 Mitarbeiter (Stand Juni 2015, vgl. o.J.) und verfügt über Standorte nicht nur in den USA, sondern auch weltweit, z.B. in Karlsruhe, Deutschland.
Entwicklung der Anzahl der Facebook Nutzer
Seit der Gründung von Facebook im Jahr 2004 ist die Anzahl der Nutzer rasant gestiegen. Waren es im ersten Jahr knapp 1 Millionen Studenten, die das Netzwerk nutzten, wurden Ende 2012 über 1 Milliarde registrierte Mitglieder verzeichnet.
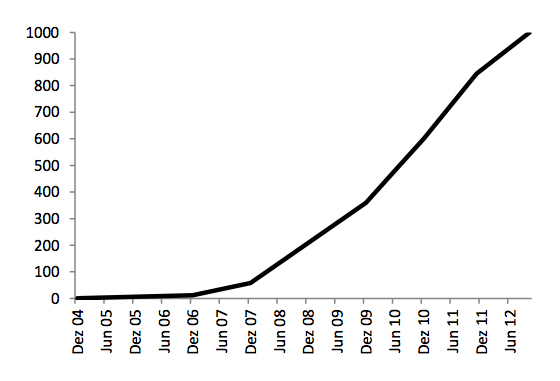
Anzahl Facebook Nutzer (in Millionen) von 2004 bis 2012 (vgl. o.J.).
(Lizenz: CC BY SA)
Im Juni 2013 gab es mehr als 26 Millionen registrierte Facebook Nutzer in Deutschland; in Italien waren es mehr als 24 Millionen (vgl. 2013).
Die Rolle von Facebook im Internet und dessen Nutzung in Deutschland und Italien
Die wachsende Anzahl der Facebook Nutzer hängt zum einen mit der wachsenden Anzahl an Internetverbindungen und den Möglichkeiten, sich überall mit dem Netz zu verbinden zusammen. Zum anderen lassen sich der große Erfolg und die rasante Verbreitung auch mit der Erweiterung des Nutzungsspektrums der Seite und den sprachlich spezifizierten Versionen erklären, die es seit 2008 gibt. So kann die Seite nämlich auch in zahlreichen anderen Sprachen, darunter auch Deutsch und Italienisch, verwendet werden (vgl. Kneidinger 2010, 59-60).
Facebook ist so zu einer der beliebtesten und am häufigsten aufgerufenen Webseite geworden:
| Rang | Deutschland | Italien | Weltweit |
| 1 | Google.de | Google.it | Google.com |
| 2 | Facebook.com | Facebook.com | Facebook.com |
| 3 | Amazon.de | Google.com | Youtube.com |
| 4 | Ebay.de | Youtube.com | Yahoo.com |
| 5 | Youtube.de | Amazon.it | Baidu.com |
| 6 | Google.com | Yahoo.com | Wikipedia.org |
| 7 | Wikipedia.org | Wikipedia.org | Amazon.com |
| 8 | Web.de | Libero.it | Twitter.com |
| 9 | Yahoo.com | Ebay.it | Taobao.com |
| 10 | T-online.de | Repubblica.it | Qq.com |
Der Rang, der von Alexa Ranking (1996-2016) vergeben wird, wird monatlich aktualisiert und basiert auf einer Kombination von der durchschnittlichen Anzahl der täglichen Besucher einer Seite und der Anzahl der Aufrufe der Seite innerhalb eines Monats. Die Suchmaschine Google führt sowohl in Italien als auch in Deutschland mit ihrer jeweiligen landesspezifischen Adresse (.de und .it) die Rangliste an, ist aber auch weltweit (mit der .com Adresse) auf dem ersten Platz. Auf dem zweiten Platz folgt dann, in Deutschland, in Italien sowie weltweit Facebook.
Ab dem dritten Platz unterscheiden sich die Ergebnisse für die beiden Länder und im weltweiten Vergleich. In Deutschland folgen zwei Seiten, die dem Erwerb neuer sowie gebrauchter Güter dienen (amazon.de und ebay.de). Es folgt die Videoplattform Youtube und schließlich ist Google außerdem mit seiner .com-Adresse in der Rangliste für Deutschland und Italien unter den ersten Plätzen zu finden, gefolgt von Wikipedia, einer enzyklopädischen Wissensplattform. Die letzten der drei hier abgebildeten Rangplätze werden von Anbietern von (hauptsächlich) E-Mail Postfächern belegt (sogenannte E-Mail Provider). In Italien hingegen folgt schon an dritter Stelle die .com-Adresse von Google und an vierter Stelle Youtube. Während dann kommerzielle Seiten, E-Mail Provider und die Wikipedia Seite folgen, wird einer der ersten zehn Plätze von der Online-Version der italienischen Tageszeitung La Repubblica belegt (in Deutschland schafft es die erste Onlinezeitung – bild.de – nur auf Platz 12). Weltweit gesehen unterscheidet sich die Rangliste ab Platz drei dahin gehend, dass hier drei der größten chinesischen Internetseiten mit in die Gewichtung fallen: baidu.com, eine Suchmaschine, taobao.com, eine Verkaufs- und Kaufplattform und Qq.com, ein Anbieter verschiedenster Dienste. Außerdem befindet sich auf Platz 8 eine weitere Social Network Seite, nämlich twitter.com, die in Deutschland und in Italien erst auf den Rängen 23 und 15 zu finden ist.
Diese Ranglisten zeigen deutlich, welche Rolle Facebook heutzutage bei der Internetnutzung in Deutschland, in Italien, aber auch weltweit spielt. In Deutschland und Italien konnte Facebook – wie schon in Tabelle 1 gesehen – erst seit 2008 Erfolge verbuchen. Es hatten sich zwar mittlerweile kleinere länderspezifische Netzwerke etabliert, wie beispielsweise das deutsche StudiVZ, die aber trotz ihrer großen Ähnlichkeit zu Facebook den Nachteil hatten, dass sie im Ausland kaum bekannt waren und so eine Vernetzung mit internationalen Kontakten nicht möglich war.4 So stiegen nach der weltweiten Öffnung die Registrierungen von europäischen Nutzern bei Facebook rasant an.
Im Jahresbericht Facebook – The Annual (2013) finden sich für Deutschland und Italien folgende Statistiken zur Nutzung:
| Deutschland | Italien | |
| Täglich | > 19 Millionen | > 17 Millionen |
| Monatlich | > 25 Millionen | > 23 Millionen |
| Prozentsatz aller Internetnutzer | 43 % | 71 % |
| Täglich (Mobiltelefon) | > 13 Millionen | > 10 Millionen |
| Monatlich (Mobiltelefon) | > 18 Millionen | > 16 Millionen |
| Prozentsatz der Mobiltelefonnutzer | 27 % | 32 % |
| Prozentsatz der monatlich aktiven Nutzer, die täglich Facebook aufrufen | 76 % | 74 % |
In Italien ist der Prozentsatz der täglich oder monatlich aktiven Internetnutzer, die auch Facebook verwenden, mit 70% um einiges höher als in Deutschland, wo nur ungefähr jeder zweite Internetnutzer Facebook verwendet. In beiden Ländern ist der Prozentsatz der aktiven Facebook Nutzer, die täglich Facebook verwenden, mit 76% in Deutschland und 74% in Italien recht hoch. Auch die Anzahl an Facebook Nutzern, die sich über internetfähige Mobiltelefone Zugang zu den Facebook Anwendungen verschafft, ist beträchtlich.
2.1.2. Nutzungsmöglichkeiten und Kommunikationsfunktionen
Es gibt eine sehr große Anzahl von Funktionen und Nutzungsmöglichkeiten auf Facebook. Eine Besonderheit dieser Plattform ist, dass sie sehr dynamisch ist, sich ständig weiter entwickelt und auch von der Mitwirkung der Nutzer lebt, die sie zu einem gewissen Maße selbst mit gestalten können.5 Im Folgenden sollen nur die wichtigsten und für diese Arbeit relevanten Bereiche vorgestellt werden.6 Dazu zählen die verschiedenen Möglichkeiten der Kommunikation – private Nachrichten, Chat und Facebook Statusmeldungen – aber auch die übergeordneten Anwendungen, in die diese kommunikativen Anwendungen eingebettet sind.
Private Kommunikation in Facebook: Nachrichten und Chat
Seit der Gründung von Facebook können sich Nutzer gegenseitig Nachrichten schreiben. Diese sind einer klassischen E-Mail recht ähnlich: Es gibt eine Art Postfach, in denen diese gespeichert werden und es können Anhänge wie Fotos, Videos und Dateien bei Verwenden hinzugefügt werden. Nachrichten sind privat, also nur für Adressat(en) und Absender sichtbar, und eine sie können an mehrere Personen gleichzeitig gesendet werden. Im Gegensatz zur klassischen E-Mail kann beim Antworten einer Nachricht jedoch nicht entschieden werden, ob diese nur an den Absender oder an alle in der Nachricht enthaltenen Adressaten gesendet wird, sondern letzteres ist automatisch der Fall. Außerdem wird in einer Nachricht markiert, ob diese von den oder dem Adressaten gelesen wurde und zu welcher Zeit (die Nachrichten sind mit einer Art „Zeitstempel“ versehen).
Die Chatfunktion gibt es bei Facebook seit 2008. In einer Chatleiste werden dem Nutzer die Freunde angezeigt, die gerade online sind und er kann diese direkt anschreiben (in kleinen Pop-up-Fenstern, die am unteren Browserrand zu sehen sind). Der Empfänger wird durch ein akustisches sowie visuelles Zeichen darüber informiert, dass ihm jemand geschrieben hat. Anders wie in anderen Chaträumen muss der Empfänger die Nachricht aber nicht sofort lesen. Diese wird, sobald er offline geht, als Nachricht in seinem Posteingang gespeichert und auch beim Antworten ist es nicht erforderlich, dass beide Kommunikationspartner gleichzeitig online sind. Die Grenzen zwischen Nachricht und Chat in Facebook verschwimmen also, was sie von klassischen E-Mails oder Chats unterscheidet.7
Facebook Statusmeldungen
Die wichtigste kommunikative Funktion nehmen bei Facebook die Statusmeldungen (en. status messages) ein.8 Auf der Facebook Pinnwand, die später zur Facebook Chronik wurde (siehe Tabelle 1), kann der Nutzer kurze Beiträge (en. posts) verfassen. Dies kann er sowohl auf der Chronik eines mit ihm vernetzten Nutzers tun, als auch auf seiner eigenen. Obwohl Post im Allgemeinen als ein Überbegriff für eigene, als auch fremde Beiträge verwendet wird, sollen für eine bessere Unterscheidung ab sofort die Beiträge, die ein Nutzer auf dem Profil eines Facebook Freundes hinterlässt, als Posts bezeichnet werden und die Beiträge, die ein Nutzer auf seiner eigenen Chronik online stellt, als Statusmeldungen.9
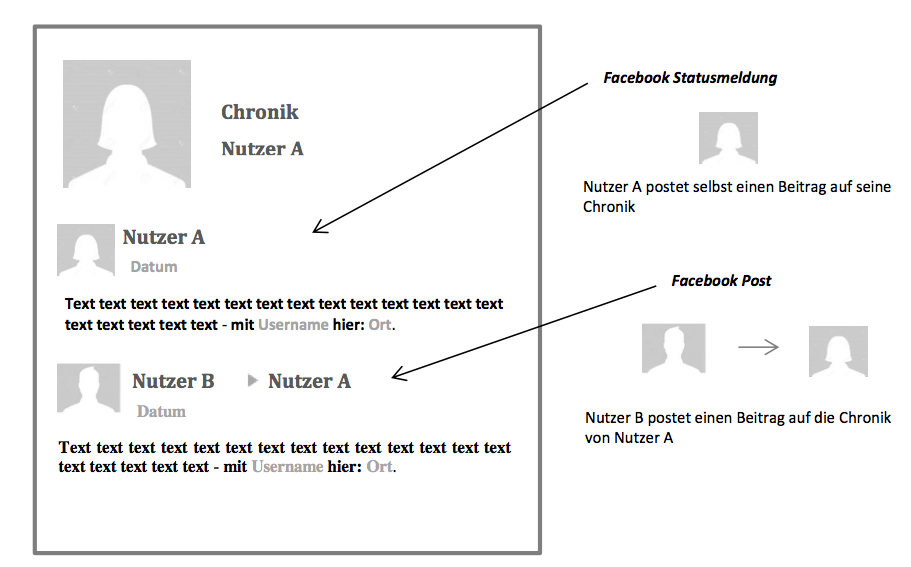
Facebook Statusmeldung und Facebook Post.
(Lizenz: CC BY SA)
Facebook Statusmeldungen orientieren sich stark am Microblogging, das auch von Twitter bekannt ist.
Microblogging refers to the writing of short messages on the web designed for self-reporting about what one is doing, thinking, or feeling at any moment. (Lee 2011, 111).
Der Nutzer wird auch bei Facebook aufgefordert, eine Art Statusbericht zu verfassen. Dies geschieht mit Hilfe eines Prompts, einer Aufforderung meist in Form einer Frage, die den Nutzer dazu verleiten soll, über sich, seine Gedanken und sein Leben zu berichten.
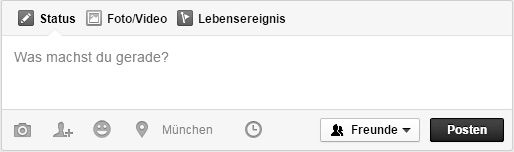
Ansicht des Fensters, das zum Verfassen einer Statusmeldung dient.
(Lizenz: CC BY SA)
In dem weißen Kasten, der als Anwendung in die Facebook Seite der Nutzer implementiert ist, kann der Text für die Statusmeldung geschrieben werden. Die Länge der textbasierten Statusmeldungen war anfangs auf eine Zeichenanzahl von 420 beschränkt, die im Jahre 2011 auf 5000 Zeichen erhöht wurde (vgl. Barton & Lee 2013, 38). Trotzdem ist die Größe des Schreibfeldes limitiert – gerade einmal ungefähr 150 Zeichen würden in diesen Kasten passen – und erst während des Schreibens vergrößert sich das Schreibfeld. Das suggeriert, dass Statusmeldungen auf (sehr) kurze Texte beschränkt seien und verleitet die Nutzer trotz der vergrößerten Zeichenlimitierung dazu, kurze Texte zu verfassen.
Auch der Prompt hat sich seit Bestehen von Facebook immer wieder geändert. Eine Zeit lang band er Vor- und Nachname des Nutzers mit ein und führte so zu einer häufigen Verwendung der dritten Person Singular, wie die folgenden Beispielen aus dem Jahr 2008 von der Chronik der Autorin zeigen:
Vorname Nachname cerca di studiare…
Vorname Nachname versucht zu lernen…
Vornamen Nachname va a casa domani…
Vorname Nachname geht morgen nach Hause…
Später forderte der Prompt mit einem einfachen „Schreib etwas…!“ den Nutzer zum Verfassen eines Textes auf. Ab Ende 2012 wurden im Wechsel verschiedene Vorschläge gegeben, über was der Nutzer schreiben könnte, wie beispielsweise „Was ist los, Nutzername?“, „Wie geht es dir, Nutzername?“ oder „Wie fühlst du dich, Nutzername?“. Diese änderten sich bei jedem erneuten Aufrufen der Seite (vgl. 2012).
Aktuell werden je nach der in den Einstellungen von Facebook ausgewählten Sprache folgende Aufforderungsfragen angezeigt:
| Deutsch | Italienisch | Englisch |
| Was machst du gerade? | A cosa stai pensando? | What’s on your mind? |
Interessant hierbei ist, dass während im Italienischen und Englischen nach der Introspektive gefragt wird, also über was sich der Nutzer Gedanken macht, wird der Nutzer im Deutschen hingegen dazu aufgefordert, seine aktuelle Tätigkeit zu beschreiben.
Es kann davon ausgegangen werden, dass diese Prompts den Inhalt und die Art und Weise der Statusmeldungen beeinflussen.10 So wird zum einen angenommen, dass häufig immer noch eine unpersönliche Form, die der dritten Person Singular, gewählt wird. Zum anderen könnte man davon ausgehen, dass Personen, die eine deutsche Facebook Einstellung gewählt haben, häufiger über ihre Tätigkeiten berichten und Nutzer mit einer italienischen und englischen Spracheinstellung dazu tendieren, ihre Gedanken zu teilen. Allerdings ist das kaum oder gar nicht überprüfbar, da Spracheinstellungen beliebig oft gewechselt werden können und sich außerdem viele der Nutzer noch gut an die sich ständig wechselnden Aufforderungen erinnern dürften.
Allgemein lässt sich allerdings sagen, dass die Statusmeldungen verschiedene kommunikative Funktionen erfüllen (vgl. Lee 2011, 116–117):11
- was man gerade macht
- Alltägliches
- Meinungen
- Information über Befinden (emotionalen Status)
- Start einer Diskussion
- Zitate
- Humor
Eine Statusmeldung kann des Weiteren unterschiedliche Formen annehmen. Zum einen können sprachliche Zeichen, hier Text in schriftlicher Form, verwendet werden. Zum anderen hat der Nutzer auch die Möglichkeit, Bilder und Videos hochzuladen oder ein Lebensereignis aus einer Liste auszuwählen (siehe Symbole in der unteren und oberen grauhinterlegten Zeile in Abbildung 3).12 Der Nutzer kann auch Facebook Freunde in seinen Texten oder Fotos markieren sowie angeben, an welchen Orten er sich aufgehalten hat. Seit Mai 2013 können Emotionen und die aktuelle Gefühlslage aus einem Katalog an Vorschlägen ausgewählt werden und diese dann als Statusmeldung auf die Facebook Chronik gepostet werden.13 Diese Möglichkeiten können schließlich miteinander kombiniert werden. Beispielsweise kann ein Foto mit einem Text und dem Ort, an dem es aufgenommen worden ist, versehen werden. Außerdem können Personen, die zum Zeitpunkt der Aufnahme gegenwärtig waren oder darauf abgebildet sind, ebenso darauf markiert werden, wie die Abbildung 4 zeigt.
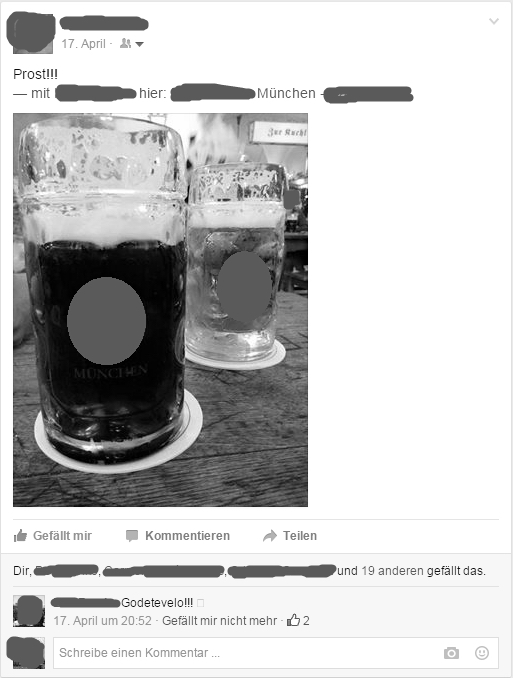
Beispiel einer Facebook Statusmeldung (vgl. 2016b).
(Lizenz: CC BY SA)
Hier ist zudem eine weitere kommunikative Funktion zu sehen, nämlich die Möglichkeit, Kommentare auf Statusmeldungen zu verfassen. Diese können von dem Nutzer selbst oder von seinen Facebook Freunden stammen. Außerdem können Beiträge (jeder Art) bei Facebook „gelikt“ werden, also von Freunden mit einem Aktivieren des „gefällt mir“-Symbols positiv bewertet werden (siehe hierzu vgl. ).
Ein Facebook Post, also ein Beitrag, der nicht auf der eigenen Facebook Seite, sondern auf der eines anderen Nutzers hinterlassen wird, unterscheidet sich in der Erstellung und seinem Aussehen nur geringfügig von der Facebook Statusmeldung. Die Anwendung zum Verfassen eines Posts sieht ähnlich aus, nur dass der Prompt hier dazu auffordert „Schreib etwas…“ und kein Lebensereignis aus einem Katalog gewählt werden kann. Aber auch hier können sowohl textbasierte Beiträge verfasst, Bilder oder Videos hochgeladen, als auch Orte, Personen und Emotionen ausgewählt werden. Trotzdem ist zu erwarten, dass sich die Posts in Hinblick auf Inhalt und dessen Form (beispielsweise Gerichtetheit an Adressaten) von den Facebook Statusmeldungen unterscheiden. Der Nutzer wird hier beispielsweise direkt angesprochen und es ist zu erwarten, dass hier viel eher Dialoge entstehen.
Die Facebook Chronik
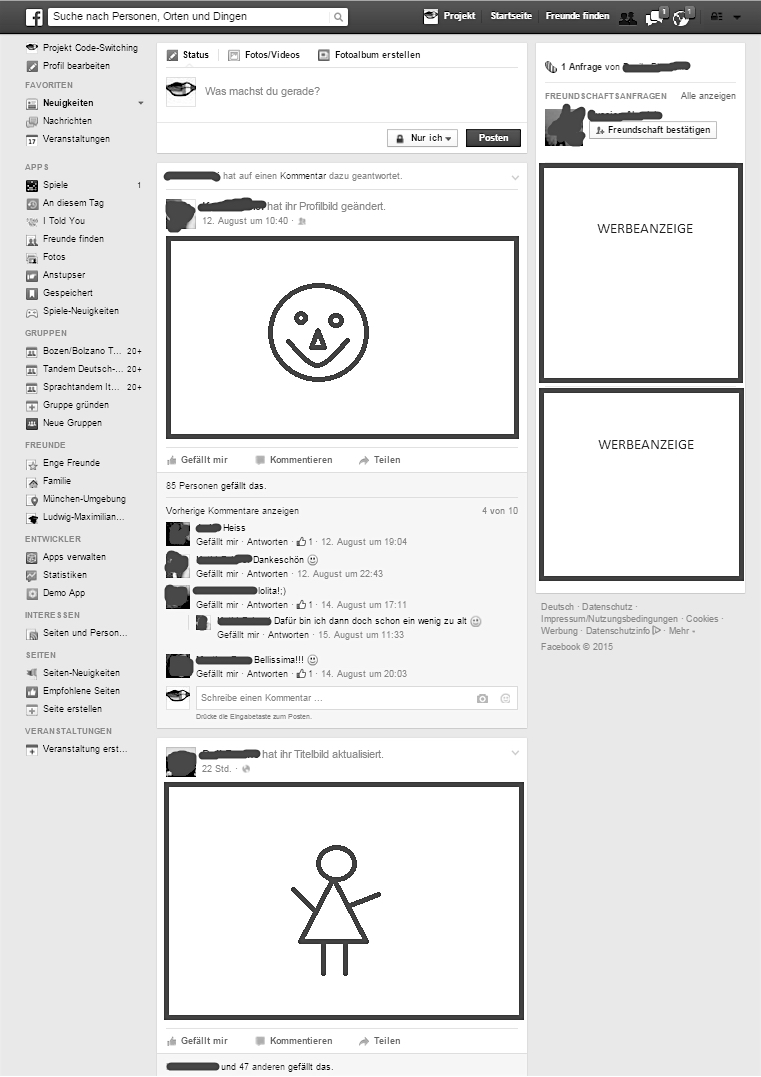
Nach dem Login wurde dem Facebook Nutzer bis 2011 die Facebook Pinnwand (en. Wall) angezeigt. Diese Pinnwand stellte das persönliche Profil des Nutzers dar und zeigte eigene Statusmeldungen sowie Posts, die Freunde auf der Seite hinterlassen haben. Nur über Benachrichtigungen oder den direkten Aufruf der Pinnwand eines anderen Nutzers konnte man dessen Aktivitäten beobachten. Heute sieht der Nutzer nach dem Einloggen die Facebook Chronik (en. Timeline), auf der umgekehrt chronologisch (d.h. beim Aktuellsten beginnend) die eigenen Statusmeldungen und Aktivitäten, aber auch die von Freunden und Facebook Seiten, von denen man Fan ist, zu sehen sind.14
Die Abbildung 5 zeigt die Facebook Chronik direkt nach dem Login. Die eigentliche Facebook Chronik befindet sich in der Mitte. Hier sieht der Nutzer die neuesten Aktivitäten seiner Facebook Freunde, deren Statusmeldungen, hochgeladene Fotos oder Posts von Seiten, die ihn interessieren. Der Nutzer bekommt hier schon die Möglichkeit, eine eigene Statusmeldung mit Hilfe einer Anwendung zu verfassen. Auf der linken Seite befinden sich die Links zu der Nachrichtenübersicht und zu einer Liste aller Veranstaltungen, zu denen der Nutzer eingeladen wurde oder für die er sich interessiert. Die Chronik kann hier außerdem aktualisiert werden (unter dem Link Neuigkeiten). Am linken Browserrand befindet sich ebenfalls eine Übersicht zu Anwendungen (Apps) und Spielen, die der Nutzer über Facebook verwendet sowie über die Gruppen, in denen er Mitglied ist.15 Zu den Freunden, die in verschiedene Listen geordnet werden können, gelangt man ebenfalls über einen Link auf der linken Seite.
Über den eigenen Nutzernamen gelangt der Nutzer auf seine persönliche Chronik, wo er nur selbst verfasste Statusmeldungen und direkt an ihn gerichtet Posts sehen kann. Zudem werden hier alle Facebook Freunde angezeigt, die Gruppen, in denen man Mitglied ist, und eine Übersicht über die Informationen, die der Nutzer bei Facebook über sich hinterlassen hat.16 Zu den Chroniken von Facebook Freunden gelangt man nur über das Aufrufen der persönlichen Chroniken dieser Freunde.
2.1.3. Facebook als Online Social Network Site (SNS)
Mit dem Aufkommen des Web 2.0 (siehe Kapitel ) spielt die Interaktion der Nutzer eine wichtige Rolle. So ist es nicht weiter verwunderlich, dass Plattformen geschaffen wurden, deren primäre Ziele die Vernetzung mit anderen Internet-Nutzern und die Interaktion mit diesen ist: sogenannte Online Social Network Sites (SNS). Bei diesen, im Deutschen auch oft als Soziale Netzwerke bezeichneten SNS handelt es sich um internetbasierte Anwendungen, die es ihren Mitgliedern erlauben, dort öffentliche oder für eine bestimmte Personengruppe zugängliche Profile zu erstellen, sich mit anderen Benutzern zu vernetzen und die zudem die Möglichkeit bieten, die Profile anderer Mitglieder zu sehen.18
We define social network sites as web-based services that allow individuals to (1) construct a public or semi-public profile within a bounded system, (2) articulate a list of other users with whom they share a connection, and (3) view and traverse their list of connections and those made by others within the system. The nature and nomenclature of these connections may vary from site to site. (boyd & Ellison 2007, 211)
Schon 1997 entstanden die ersten SNS, wie beispielsweise SixDegree.com, ein von Andrew Weinreich gegründeter Onlinedienst, mit dem soziale Netzwerke durch das Erstellen von Profilseiten und dem Aufzeigen von Freundschaftsbeziehungen zu anderen Benutzern aufgebaut werden konnten.19 In seiner Hochphase hatte dieser Dienst zwar schon fast eine Million Mitglieder, wegen seiner Probleme mit Spam und der geringen Rentabilität für die Betreiber wurde die Seite aber im Jahre 2001 wieder eingestellt (vgl. boyd & Ellison 2007, 214, Plymale 2012). In den folgenden Jahren wurden einige ähnliche Seiten, wie AsianAvenue, BlackPlanet oder MiGente, online geschalten, die privaten Zwecken oder dem Online Dating dienen (vgl. boyd & Ellison 2007, 214–215). Es folgten Seiten wie Ryze.com, LinkedIn oder Xing, die vor allem zur Vernetzung mit beruflichen Kontakten erstellt wurden. Die Seiten, die wohl den größten Erfolg auf internationaler Ebene erreichten, sind Friendster, MySpace, Twitter und Facebook.20 Für Deutschland sei zudem noch StudiVZ und für Italien superEva zu nennen, die aber beide mit der Verbreitung von Facebook hohe Einbußen an Nutzerzahlen zu verzeichnen hatten.
All diesen SNS ist gemein, dass der Nutzer die Möglichkeit hat, sich ein Profil zu erstellen. Darin kann er für den jeweiligen Zweck der SNS relevante Angaben über die eigene Person machen. Bei beruflichen Netzwerkseiten wären das beispielsweise Angaben zum beruflichen und schulischen Werdegang, bei SNS, die vor allem im privaten Bereich genutzt werden, sind das Angaben aus dem Privatleben, wie Geburtsdatum oder auch Hobbys und Interessen. Des Weiteren können Personen, die ebenfalls dieses Netzwerk nutzen, als Kontakte hinzugefügt werden. Kontakte heißen bei Facebook Freunde und werden bei anderen, wie zum Beispiel Twitter oder Instagram, Follower oder Abonnenten genannt.
Weitere wichtige Merkmale, die der Definition von boyd & Ellison (2007, 211) fehlen, die aber bei fast allen SNS eine wichtige Rolle spielen, werden in der Definition von Wilson et al. (2009, 1) aufgegriffen: Demnach sind SNS „[…] popular infrastructures for communication, interaction, and information sharing on the Internet.” Kommunikation beinhaltet aber schon Interaktion und das Teilen von Informationen – oder „Inhalten“ wie es bei Facebook heißt (siehe Tabelle 5) – und so lässt sich zusammenfassen, dass SNS durch Kommunikation verschiedener Art charakterisiert wird.21 Diese „Inhalte“ (als Übersetzung aus dem Englischen contents), beziehen sich auf Informationen verschiedener Natur, die die Nutzer mit ihrem Netzwerk teilen können. So sind es bei Twitter meist kurze Textnachrichten oder Verlinkungen mit Personen und verwandten Themen.22 Es können außerdem Fotografien, Videos sowie Links zu Webseiten, anderen Netzwerk-Nutzern oder Spielen und Umfragen geteilt werden.
Die Gründe, warum sich Menschen bei einer SNS registrieren, sind vielfältig, und genauso vielfältig sind auch die Funktionen, die diese SNS für ihre Nutzer erfüllen können. Richter & Koch (vgl. 2008, 1242) definieren nach einer Analyse mehrerer offener und geschlossener Systeme sechs Funktionalitätsgruppen:
- Identitätsmanagement: bewusste und kontrollierte Selbstdarstellung
- (Experten-)Suche: Wissen wird gesucht und genutzt
- Kontext-Awareness (Kontext/Vertrauensaufbau): ein gemeinsamer Kontext ist ein zentraler Bestandteil menschlicher Beziehungen. Unter dieser Voraussetzungen muss Vertrauen aufgebaut werden, um diesen Kontext zu schaffen
- Kontaktmanagement: Pflege und Verwaltung persönlicher Kontakte
- Netzwerk-Awareness: Interesse an Aktivitäten und Neuigkeiten im Netzwerk
- Gemeinsamer Austausch (Kommunikation): verschiedene Anwendungen ermöglichen den kommunikativen Austausch, beispielsweise über Chats und Nachrichten oder Microblogging-ähnlichen Anwendungen, wie den Facebook Statusmeldungen. Die Kommunikation kann zum einen sprachlich stattfinden, aber auch non- oder para-sprachlich durch das Hochladen und Teilen von Bildern beispielsweise.
Zusammenfassend lässt sich also festhalten, dass eine SNS eine Plattform darstellt, auf der der Nutzer sich ein (privates oder öffentliches) Profil erstellen kann, auf dem er sich selbst darstellt indem er persönliche Angaben zu seiner Person macht. Außerdem kann ein Nutzer sich mit anderen vernetzen und so diesen die Möglichkeit geben, sein eigenes Netzwerk einzusehen, um gemeinsame Kontakte zu ermitteln. Informationen in Form von Beiträgen verschiedener Art können mit dem Netzwerk geteilt werden.
Facebook ist demnach eine SNS und auch auf der Beschreibung der Facebook Webseite heißt es, dass es sich hierbei um ein solches soziales Netzwerk handelt. Die Möglichkeit der Vernetzung mit Menschen aus Privatleben und Beruf sowie das Bewahren von Kontakten und Verbindungen werden dabei hervorgehoben:
| Deutsche Spracheinstellung | Italienische Spracheinstellung | |
| Beschreibung | Facebook ist ein soziales Netzwerk, das Menschen mit ihren Freunden, Arbeitskollegen, Kommilitonen und anderen Mitmenschen verbindet. Nutzer verwenden Facebook, um mit ihren Freunden in Verbindung zu bleiben, eine unbegrenzte Anzahl an Fotos hochzuladen, Links und Videos zu posten sowie mehr über die Personen zu erfahren, die sie kennenlernen. ( 2016b) [deutsche Spracheinstellung] | Facebook è una piattaforma sociale che ti consente di connetterti con i tuoi amici e con chiunque lavori, studi e viva vicino a te. Puoi usare Facebook per rimanere in contatto con i tuoi amici, caricare tutte le foto che vuoi, pubblicare link e video o per saperne di più sulle persone che incontri. ( 2016b) [italienische Spracheinstellung] |
| Login-Seite | Facebook ermöglicht es dir, mit den Menschen in deinem Leben in Verbindung zu treten und Inhalte mit diesen zu teilen. ( 2016b) [deutsche Spracheinstellung] | Facebook ti aiuta a connetterti e rimanere in contatto con le persone della tua vita. ( 2016b) [italienische Spracheinstellung] |
Bei Facebook kann der Facebook Nutzer sich ebenfalls ein Profil erstellen, auf dem er sich selbst darstellt und persönliche und berufliche Informationen mit seinem Netzwerk teilt. Er vernetzt sich mit anderen Nutzern (Facebook Freunde) und gibt diesen so die Möglichkeit, sein Netzwerk einzusehen und gemeinsame Kontakte zu ermitteln. Somit entspricht Facebook der Definition einer SNS nach boyd & Ellison (2007, 211). Ebenso sind die Möglichkeiten des Teilens von Inhalten hier gegeben. Innerhalb seines Netzwerkes hat der Nutzer bei Facebook auch die Möglichkeit, Interessen zu bekunden („gefällt mir“) und so können sich innerhalb der Kontakte Nutzer in Gruppen aller Art zusammenfinden, um dort Informationen zu verschiedenen Themen mit einem bestimmten Personenkreises miteinander zu teilen.
Facebook ist also eine SNS auf der Nutzer
- sich ein (privates oder öffentliches) Profil erstellen, auf dem sie sich selbst darstellen indem sie persönliche Angaben zu ihrer Person machen
- sich mit anderen Nutzern vernetzen und so diesen die Möglichkeit geben, das Netzwerk einzusehen und gemeinsame Kontakte zu ermitteln
- innerhalb des Netzwerkes Interessen bekunden und zu Interessensgemeinschaften zusammenfinden
- Informationen in Form von Beiträgen mit dem Netzwerk teilen und ebenfalls solche von Kontakten empfangen.
Jede Art des Teilens von Informationen mit anderen Facbook Nutzern hat kommunikativen Charakter. Aber vor allem wegen des Austauschs von textbasierten Informationen mit Hilfe des Facebook Chats, der Nachrichten oder Beiträge spricht man hierbei von computervermittelter Kommunikation, wie das nächste Kapitel zeigen soll.
2.2. Computervermittelte Kommunikation (CMC)
Seit der Entwicklung und der rasanten Verbreitung des Computers und des Internets wird deren Einfluss auf den Menschen untersucht. Wie gerade schon am Beispiel der SNS gesehen, ist die Kommunikation eine der Hauptfunktionen von Computern, des Internets und vor allem auch des Web 2.0. Dazu zählt nicht nur die Kommunikation zwischen zwei (oder mehreren) Computern oder zwischen Mensch und Computer (siehe a) und b) in Abbildung 6), sondern auch die Kommunikation zwischen Menschen, die Computer und Internet benutzen (siehe c)).
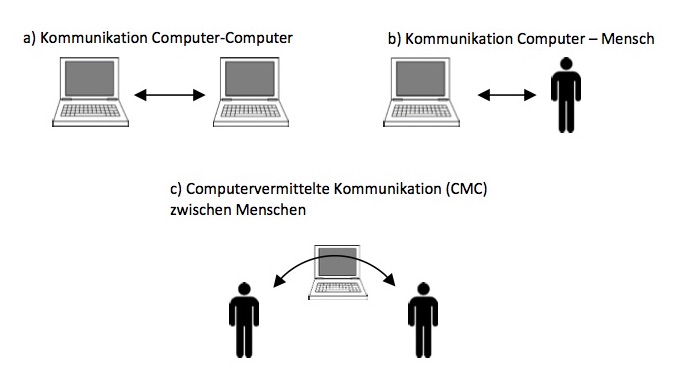
Möglichkeiten der Kommunikation, bei denen Computer involviert sind.
(Lizenz: CC BY SA)
Für die Art der Kommunikation in c) hat sich der Begriff der computervermittelnden Kommunikation (aus dem Englischen computer-mediated communication, abgekürzt mit CMC) etabliert, der auch in den Sprach- und Kommunikationswissenschaften zu einem weit verbreiteten Untersuchungsgegenstand geoworden ist.
Im Allgemeinen wird CMC an Computern produziert und rezipiert, aber auch die Distribution erfolgt über technische Hilfsmittel, welche sich in den letzten Jahren rasant entwickelt und verändert haben. Um überhaupt mit Hilfe eines Computers kommunizieren zu können, und dementsprechend sprachliche Produkte, die sich der CMC zurechnen lassen, zu erzeugen, müssen verschiedene technische Rahmenbedingungen gegeben sein. Für eine bessere Übersicht sollen diese hier anhand ihrer Entwicklungsgeschichte wiedergegeben werden.
2.2.1. Die technischen Voraussetzungen: Computer, Internet und Web 2.0
Ein Computer dient dem Mensch als Instrument, Maschine und Werkzeug (vgl. Schelhowe 1997, 10) und bezeichnet damit allgemein ein Gerät, das mit Hilfe von programmierbaren Algorithmen Daten verarbeitet.23 Der Begriff Computer ist dabei als Oberbegriff zu sehen und schließt damit den Personal Computer (PC), die wohl bekannteste Form eines Computer, als auch Server, große, leistungsstarke Computer, auf die nur über ein Netzwerk zugegriffen werden kann, mit ein (vgl. Patterson & Hennessy 2013, 5-6). Außerdem fallen unter diesen Begriff kleinere Varianten, wie die eingebetteten Computer (en. embedded computer), zu denen auch die Mikroprozessoren in Autos und Fernsehern zählen, und schließlich die in Smartphones verwendeten Computer (personal mobile device) (vgl. Patterson & Hennessy 2013, 5-7). Ein Computer besteht dabei nicht nur aus der Hardware, also den mechanischen und elektronischen Komponenten, sondern auch aus programmierbaren Bestandteilen, der Software, die in Form von Programmen und Anwendungen (en. applications) auf dem Computer ausgeführt wird. Die Einsatzbereiche und Funktionen von Computern haben sich in den Jahren seit der Erfindung des Computers stark gewandelt. Die Verbreitung und Entwicklungen wären allerdings nicht so erfolgreich gewesen, wenn nicht auch Möglichkeiten der Vernetzung geschaffen worden wären.
„Einzelne Computer sollten in die Lage versetzt werden, in einen <Dialogbetrieb> zu treten, also miteinander zu kommunizieren.“ (Runkehl & Schlobinski & Siever 1998, 9) [Hervorhebung im Original] und schon Mitte der 1960er Jahre wurden mit der Entwicklung der entsprechenden Techniken die Grundlagen gelegt. Im Jahre 1965 wurden dann, basierend auf einer Idee von Leonard Kleinrock, die ersten Computer über Telefonleitungen miteinander vernetzt (vgl. Leiner & Cerf & Clark 2012, 2). Das Problem dieser Netzwerke war allerdings, dass diese mit einem Großrechner (en. mainframe) verbundenen, peripheren Terminals zentral organisiert waren und bei einem Ausfall dieses Großrechners das gesamte Netzwerk zusammengebrochen wäre (vgl. Runkehl & Schlobinski & Siever 1998, 11-12). Im Laufe der 1960er Jahre und vor dem Hintergrund weltgeschichtlicher Ereignisse wurden die militärischen Möglichkeiten solcher Netzwerke erkannt. Im Rahmen von DARPA wurde ein dezentral aufgebautes Netzwerk entwickelt, das ARPANET genannt wurde, und dazu diente, Daten von einem Computer zum anderen übertragen zu können (vgl. Marx & Weidacher 2014, 65).24
Einen wichtigen Beitrag zum Erfolg des Internets leistete 1972 die Demonstration von ARPANET auf der International Computer Communication Conference (ICCC), organisiert von Bob Kahn, einem der Mitentwickler des ersten Protokolls, Telnet genannt, das den Dialog zwischen mehreren Rechnern erlaubt.
It was also in 1972 that the initial „hot“application, electronic mail, was introduced. […] From there email took off as the largest network application for over a decade. (Leiner & Cerf & Clark 2012, 3) [Hervorhebung im Original].
Neben der Erfindung der elektronischen Post (E-Mail) wurde auch der akademische Nutzen des Internets erkannt und das Netzwerk Computer Science Research Network (CSNET) gegründet, dem sich viele US-amerikanische Informatikfakultäten anschlossen (vgl. Runkehl & Schlobinski & Siever 1998, 11-12).
Der „eigentliche Siegeszug des Internets“ (Marx & Weidacher 2014, 65) begann 1973, als Kahn zusammen mit Viton Cerf einheitliche Protokolle für die Datenübertragung entwickelt: das Control Protocol (TCP) und das Internet Protocol (IP). 1989 war schließlich das Geburtsjahr des vom europäischen Kernforschungszentrum CERN entwickelten Hypertext-Übertragungsprotokolls: das Hyptertext Transfer Protocol (HTTP). 1993 folgte der von Marc Andreessen entwickelte Webbrowser NCSA Mosaic (vgl. Runkehl & Schlobinski & Siever 1998, 11-12) und in diesem Zusammenhang entstand schließlich das World-Wide Web (WWW).25
In den 1990-er Jahren begann die kommerzielle Phase des Internets und es entstanden neue Möglichkeiten der Kommunikation. Die Anzahl der Internet-Hosts, der mit dem Internet verbundenen Rechner, stieg in diesem und im folgenden Jahrzehnt rasant an.
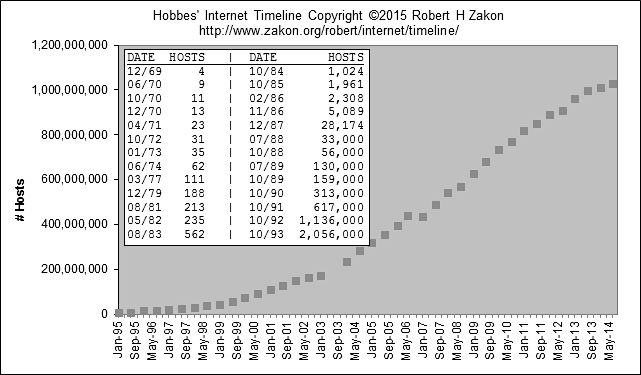
Entwicklung der Anzahl der Internet-Hosts von 1995 bis 2014 (Zakon 2015).
(Lizenz: CC BY SA)
Zu Beginn des 21. Jahrhunderts fiel schließlich zum ersten Mal der Begriff Web 2.0. Darunter versteht man
[…] web-based platforms that emerged as popular in the first decade of the twenty-first century, and that incorporate user-generated content and social interaction, often alongside or in response to structures or (multimedia) content provided by the sites themselves. (Herring 2013, 4).
So kann bei einer chronologischen Betrachtung der Entwicklung von Internetseiten und -anwendungen im Rahmen des Web 2.0 leicht festgestellt werden, dass diese vor allem ab dem Jahre 2000 entstanden sind (vgl. Herring 2013, 3). Ihnen allen ist gemein, dass die Inhalte von den Benutzern selbst erzeugt werden und dass sie soziale Interaktionen zulassen, die in einem von der Seite vorgegebenen Rahmen stattfinden. In einer Gegenüberstellung von Web 2.0 und dem bisher dagewesenen Web, das ab dem Zeitpunkt auch als Web 1.0 bezeichnet wird, stellt O’Reilly (2007, 18) Charakteristika dieser beiden heraus und vergleicht Anwendungen, Plattformen und Programm dieser miteinander. Einige dieser Merkmale zeigt die folgende Tabelle:
| Web 1.0 | Web 2.0 |
| DoubleClick | Google AdSense |
| Ofoto | Flickr |
| Akamai | BitTorrent |
| mp3.com | Napster |
| Britannica Online | Wikipedia |
| personal websites | blogging |
| evite | upcoming.org and EVDB |
| domain name speculation | search engine optimization |
| page view | cost per click |
| screen scraping | web services |
| publishing | participation |
| content management systmes | wikis |
| directories (taxonomy) | tagging („folksonomy“) |
| stickiness | syndication |
So ist Britannica Online beispielsweise die Online-Version einer englischsprachigen Enzyklopädie; Wikipedia hingegen funktioniert nach dem Prinzip, dass dort jeder Nutzer zu jedem Thema Beiträge erstellen kann, die dann von anderen Nutzern bearbeitetet, geändert und geprüft werden können. Als ein weiteres Beispiel sei hier die Gegenüberstellung von persönlichen Homepages des Web 1.0 und den im Web 2.0 existenten Blogging-Seiten genannt. Hier werden nicht nur Inhalte von einem Nutzer veröffentlicht, sondern es wird anderen Nutzern die Möglichkeit gegeben, Kommentare dazu zu schreiben oder diese zu bewerten. Ohne nun auf alle in der Tabelle angeführten Punkte einzugehen, wird schnell der wichtigste Unterschied deutlich: Während das Web 1.0 eine Plattform ist, auf der Einzelpersonen, aber auch Unternehmen, Institutionen oder Nachrichtenagenturen Inhalte veröffentlichten, lebt das Web 2.0 von der aktiven Teilnahme der Nutzer. Dabei ist festzuhalten, dass das Web 2.0 das Web 1.0 nicht ersetzt oder ablöst, sondern dass es zu einer Koexistenz kommt, beziehungsweise dass Möglichkeiten des Web 2.0 in schon im Web 1.0 vorherrschende Formen eingebunden werden.26
2.2.2. Begriffsklärung: CMC, DMC, Cyberspeak oder Internetsprache?
Die CMC sei gleich zu Beginn abzugrenzen von der Kommunikation, die mit dem Computer stattfindet (siehe die Typen a) und b) in Abbildung 6). Das schließt die Verwendung von Auszeichnungssprachen, die beispielweise dazu verwendet werden, Internetseiten zu strukturieren (wie Hypertext Markup Language (HTML)), aus. Ebenso sollen hier Programmiersprachen, die dem Computer Aktionen verschiedener Art abverlangen (beispielsweise php, Java, C++ oder Python, um nur einige zu nennen), nicht weiter Beachtung finden.
Die Definition des Begriffs CMC ist alles andere als eindeutig, da er sich oft auf verschiedene (Unter-) Bereiche bezieht. Eine recht allgemeine Definition liefert Herring (2010, 1), wonach CMC als “communication that takes place between human beings via the instrumentality of computers“ angesehen wird. Allerdings handelt es sich bei der CMC nicht nur um die Kommunikation, die über einen Computer, im Sinne eines Personal Computers (PC), einem ortsgebundenen, rechteckigen, Daten verarbeitenden Kasten, erfolgt. Der technische Fortschritt hat mittlerweile auch andere, mobile Geräte hervorgebracht, wie Notepads, Tablets oder Smartphones, die dem PC technisch in nichts nach stehen. Auch Herring (2007) reagiert auf diese Entwicklung und weitet ihre Definition der CMC auf Mobiltelefone aus.27 Es wurden auch Begriffe wie electronically mediated communication (EMC) oder digitally mediated communication (DMC) vorgeschlagen, um dem technischen Fortschritt gerecht zu werden und diese neue Art der Kommunikation nicht nur auf die über ortsgebundene PCs stattfindende zu beschränken (vgl. Crystal 2011, 2). Diese Unterscheidung ist für eine Definition aber eigentlich redundant, da all diesen Geräten Computer, im Sinne von Geräten, die durch programmierbare Algorithmen Daten verarbeiten, zugrunde liegen (siehe Kapitel ).
Neben dem Computer als Hilfsmittel, also als Produktions- und Rezeptionsgerät von Kommunikation, ist jedoch auch die Art der Distribution, die in den meisten Fällen über das Internet erfolgt, von Bedeutung.28 Es gab einige Vorschläge, wie sprachliche Äußerungen bezeichnet werden können, die mithilfe von Computern (oder ähnlichen, das Internet benutzenden Geräten) produziert, distribuiert und rezipiert werden. Es fielen dabei Begriffe wie „Cyberjargon“, „Cyberspeak“, „E-Speak“ und „Netspeak“ (vgl. Crystal 2011, 2) oder eben “computervermittelte internetbasierte Kommunikation“ (Beisswenger 2007).
Der Begriff CMC, der vor allem dank des gleichnamigen Journals weite Verbreitung fand, hat jedoch neben fehlender Eindeutigkeit bezüglich des technischen Hilfsmittels und der Distributionsart noch weitere Schwachstellen.29 Zum einen suggeriert er, dass es eine homogene Art der Kommunikation unter Verwendung von Computern gibt. Diese Kommunikation kann allerdings auf verschiedene Art und Weise erfolgen, da CMC “[…] all forms of communication, such as music, photographs, line-drawings, and video, as well as language in the strict sense of the word“ (Crystal 2011, 1) miteinbezieht. Zum anderen könnte man bei der Verwendung dieses Begriffs zu dem Schluss kommen, dass diese Art der Kommunikation nur im digitalen Bereich, auf dem Computer, dem Smartphone oder Tablet stattfinden kann und eine Übertragung in einen nicht-elektronischen Kommunikationsbereich ausgeschlossen sei. Allerdings ist dies aufgrund der großen Verbreitung und dem wachsenden Einfluss von Computer und Internet auf das tägliche Leben und die dort stattfindende Kommunikation schwer vorstellbar.
Für die sprachwissenschaftliche Untersuchung von Äußerungen im Internet fand der Vorschlag des Begriffs der „Internetlinguistik“ von Crystal (2011, 2) große Zustimmung. Dieser Begriff (vgl. auch die gleichnamige Einführung von Marx & Weidacher 2014) bietet den Vorteil, dass er den Fokus auf die verwendete Sprache – die „Sprache des Internets“ – als einen Teil der menschlichen Kommunikation richtet.30 Meist werden unter diesem Begriff aber nur getippte Texte untersucht; Kommunikation im Internet kann aber auch mündlich erfolgen, wie beispielsweise über Internettelefonie oder ähnliche Voice-over-IPs (VoIP). Außerdem kann – und sollte – nicht immer strikt getrennt werden zwischen sprachlicher und nichtsprachlicher Kommunikation. Häufig werden getippte Texte mit Bildern kombiniert, wie es bei den Facebook Statusmeldungen und Posts der Fall sein kann (siehe Kapitel und Kapitel ). Außerdem spielt gerade die Verwendung von Emoticons und ähnlichen para- oder nichtsprachlichen Zeichen in der Sprache des Internets eine zentrale Rolle, wie Kapitel zeigen wird.31
Obwohl weitere Begriffe oder Abgrenzungen vorgeschlagen wurden, wird der Terminus CMC aber weiterhin in der Forschungsliteratur verwendet und soll auch hier beibehalten werden. Er soll dabei als Überbegriff für jede Art der Kommunikation, die mit Hilfe von internetfähigen, computerbasierten Geräten zwischen Menschen stattfindet, betrachtet werden. Dies schließt auch die „Sprache des Internets“ ein, also die Kommunikation, die hauptsächlich sprachlich durch schriftliche, oder besser gesagt getippte, Texte erfolgt und durch para- oder nichtsprachliche Zeichen angereichert werden kann.
2.2.3. CMC auf Facebook
Die Kommunikation, die über die verschiedenen Anwendungen auf Facebook erfolgt, findet mit Hilfe von internetfähigen, computerbasierten Geräten zwischen Menschen stattfindet. Sie kann sprachlich ablaufen, in Form von getippten Texten sowie nichtsprachlich durch das Senden oder Veröffentlichen von Bildern oder Videos oder parasprachlich durch die Verwendung von Phoneticons.32 Somit kann auch in Bezug auf Facebook von CMC gesprochen werden.
Allerdings reicht schon ein kurzer Vergleich von Beiträgen in diesen Kategorien, um feststellen zu können, dass sich die Formen der Kommunikation und die darin verwendete Sprache voneinander unterscheiden.
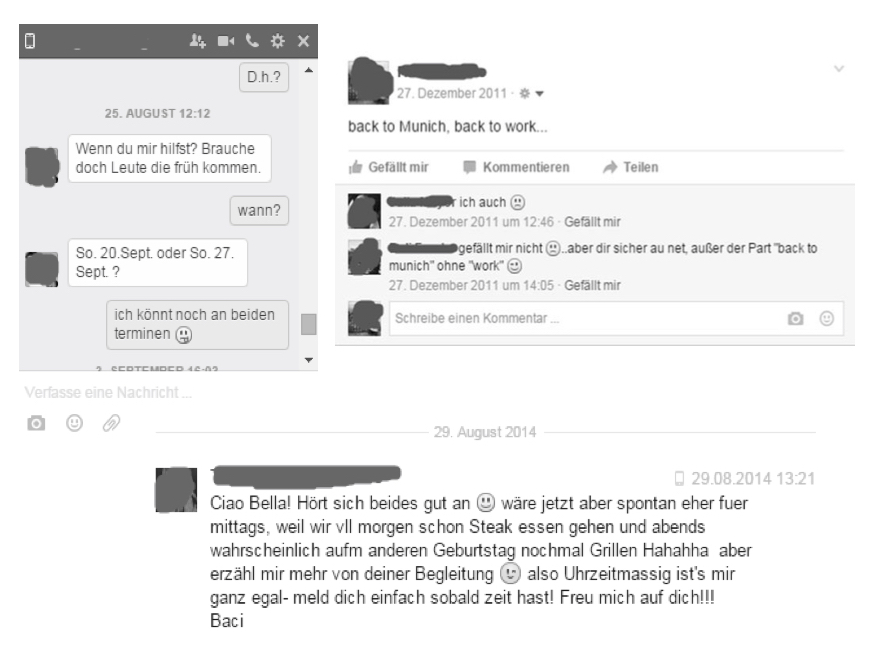
Facebook Chat (oben links), Statusmeldung (oben rechts) und Nachricht (unten) im Vergleich ( 2016b).
(Lizenz: CC BY SA)
Hieran lässt sich erkennen, dass es bei der CMC auf Facebook Gemeinsamkeiten, aber auch Unterschiede gibt. So ist zwar die Verwendung von Emoticons bei allen gegeben, aber im Inhalt und im Aufbau der Texte gibt es Unterschiede: So werden nur bei der Facebook Nachricht Grußformeln verwendet. Während sowohl beim Chat als auch in der Nachricht der Adressat direkt angesprochen wird, ist das bei der Statusmeldung nicht der Fall. Im Chat fällt zudem der Gebrauch von Abkürzungen auf. Der Zweck der Statusmeldung ist in einem übergeordneten Sinne die Selbstdarstellung und verweist auf den Aufenthaltsort und die Wiederaufnahme der Arbeit des Verfassers, während es beim Chat und der Nachricht wohl um Terminabsprachen geht.
Die Formen der Kommunikation sind somit nicht homogen. Das betrifft nicht nur Facebook, sondern auch viele andere Formen des Kommunizierens, die unter den Begriff der CMC fallen. Um diesen gerecht zu werden, sollte zunächst eine Klassifizierung der CMC angestrebt werden. Dieses Unterfangen ist sehr komplex und, wie wir in dem nächsten Unterkapitel sehen werden, nach bisher angewandten Unterscheidungskriterien nicht ohne weiteres möglich.
2.2.4. Typen der CMC
2.2.4.1. Ein erster Versuch der Typisierung der CMC nach Crystal
Crystal (2001) unterscheidet vier Haupttypen der CMC, beziehungsweise der „Sprache des Internets“, wie es bei ihm heißt. Dazu zählen E-Mail, Chatgruppen, virtuelle Welten und das World Wide Web (WWW), das hier dem Web gleichgesetzt ist. Bei den E-Mails handelt es sich um eine dem Brief ähnliche, aber elektronisch übertragene Form der Kommunikation, bei der ein E-Mail Provider benötigt wird, also ein ‚virtuelles Postfach‘, von wo aus der Nutzer diese Post verschicken und auch selbst erhalten kann. Ein Chat erfolgt meist über einen Chatdienst, der den Nutzern die Möglichkeit bietet, sich in Chaträumen (en. chatrooms) miteinander zu unterhalten.33 Virtuelle Welten sind online erschaffene Mikrowelten, die sich die Nutzer aufbauen können (oder zumindest zu deren Aufbau beitragen). Sie nehmen in diesen als Computerspiel aufgebauten Welten (wie Dungeons and Dragons oder World of Warcraft) einen bestimmten Charakter (Avatar) an. Sie schlüpfen dann in dessen Rolle, um sich ein Leben und eine Lebensform aufzubauen. Es kann auch mit anderen Avataren kommuniziert werden (dabei handelt es sich zum einen um vom Hersteller des Spiels vorgegebene Charaktere oder von anderen Mitspielern kreierte). Unter WWW versteht Crystal (2001, 13) schließlich „the full collection of all the computers linked to the Internet which hold documents that are mutually accessible through the use of standard protocol (the HyperText Transfer Protocol, or HTTP)”. Das WWW stellt nach Crystals sehr weiten Definition (ebd.) die Vernetzung aller Computer dar, in denen Dokumente, die sprachliches Material verschiedener Art enthalten, durch die Verwendung des Datenübertragungsprotokolls in einem Internetbrowser sichtbar gemacht werden können. Es handelt sich hierbei also weder um das sprachliche Produkt, noch um die Plattform zur Erstellung dieses, vielmehr geht es hierbei um die technischen Rahmenbedingungen für die Erstellung von Plattformen, auf denen sprachliches Material angezeigt oder erstellt werden kann.
Eine Vergleichbarkeit dieser Typen und der darin stattfindenden Kommunikation, die zu einer näheren Beschreibung von CMC bzw. der Sprache des Internets führt, ist in diesem Kontext nicht möglich. Es handelt sich bei den vier von Crystal vorgeschlagenen Typen zum einen um virtuelle Plattformen, innerhalb welcher Kommunikation stattfindet (Chatgruppen und virtuelle Welten als Online Spiele), aber auch um die Form der Kommunikation selbst (E-Mail). Schließlich wird sogar das WWW als technische Rahmenbedingung mit den anderen Typen verglichen. Es fehlen somit gemeinsame Kriterien, als Voraussetzung für eine Vergleichbarkeit.
2.2.4.2. Typisierung der CMC nach dem Kriterium der Synchronität
Das Kriterium der Synchronität, die Unterscheidung zwischen synchronen und asynchronen Situationen bei der Kommunikation im Netz, wird häufig als eines der wichtigsten Kriterien bei der Klassifikation der CMC herangezogen (vgl. Döring 2003).34 Zu der synchronen CMC wird dabei die Kommunikation aus Chaträumen, in denen Personen in „Echtzeit“ miteinander kommunizieren sowie Instant Messaging und VoIP-Kommunikation gezählt. Zu den Interaktionen der CMC, die auch zeitlich versetzt, also asynchron stattfinden können, gehören E-Mails, Blogs, Wikis und andere.
Allerdings kann beim Chatten nie eine wirkliche Synchronität erreicht werden, da ihr ein wichtiges Merkmal, nämlich die „Simultaneität von Produktion und Rezeption der Äußerung“ (Dürscheid 2005, 8), fehlt. Der Chatter verfasst den Text, welcher aber dem Empfänger nicht schon während des Schreibeprozesses angezeigt wird, sondern erst nachdem der Produzent diesen (meist durch das Drücken der Eingabetaste oder das Klicken auf einen Sende-Button) verschickt hat. Und auch der Empfänger muss den Text nicht sofort nach dem Empfangen lesen. Wenn er beispielsweise gerade andere Seiten (d.h. Tabs) in seinem Internetbrowser geöffnet hat, muss er erst wieder zu dem Chatfenster zurückkehren. Bei einem Vergleich des Chat mit einem Face-to-Face-Gespräch, kann festgestellt werden, dass hier wichtige Merkmale des Letzteren fehlen: der Empfänger kann nicht schon während der Produktion von Äußerungen das Gesagte verfolgen und er kann den Sprecher auch nicht unterbrechen oder intervenieren.35
Trotzdem kann die Kommunikation im Chat nicht als asynchron betrachtet werden, da hierbei die gleichzeitige Anwesenheit der Gesprächspartner im Chatraum (oder auch in der VoIP-Anwendung) Voraussetzung ist. Das heißt, alle Gesprächsteilnehmer müssen online sein, damit Kommunikation stattfinden kann. Das Merkmal der Synchronität betrifft also nicht die zeitliche Dimension bei der Übertragung, sondern die gleichzeitige virtuell-räumliche Anwesenheit von Produzent und Empfänger in der jeweiligen Gesprächssituation.
Das führt dann zu der Frage, was eigentlich unter asynchroner CMC gemeint ist. Als Gegensatz zur Synchronität erfolgt die Kommunikation hier zeitlich und räumlich versetzt. Allerdings kennt wohl mittlerweile ein jeder Inhaber eines E-Mail-Postfachs Situationen, in denen er just in dem Moment, in dem er sich einloggt, neue E-Mails erhält, die sofort gelesen und beantwortet werden.36
Alternativ wurden im Rahmen der CMC-Forschung Begriffe wie semi-synchron (vgl. Antonelli 2007, 147) oder quasi-synchron (vgl. Beisswenger 2005, Dürscheid 2005) verwendet.
La fondamentale differenza tra il sincrono e il semi-sincrono sta nella peculiarità di quest’ultimo di lasciare al ricevente la discrezionalità del quando ricevere la comunicazione (Pietro Montefusco, zitiert ohne Angaben in Antonelli 2007, 147) [Hervorhebungen im Original].
Das Konzept der Semi-Synchronität soll den Umstand berücksichtigen, dass der Empfänger selbst entscheiden kann, wann er eine Nachricht erhält (und ob er darauf mit einer Antwort reagiert). Die Bezeichnung als quasi-synchron soll der Abwesenheit von Simultaneität von Produktion und Rezeption gerecht werden, dass also bei der Entstehung von Äußerungen diese nicht mit verfolgt werden können und Interventionen, Überlappungen von Äußerungen und Unterbrechungen nicht möglich sind. Der Chat wäre damit sowohl semi- als auch quasi-synchron. Die Konzepte Semi-und Quasi-Synchronität treffen nun aber eigentlich auf alle Formen der CMC zu. Denn nur wenn der Rezipient die Entscheidung trifft, den Computer einzuschalten, sich mit dem Internet zu verbinden und die entsprechende Anwendung, mit der er die Äußerungen des Produzenten lesen kann, zu öffnen, kann er das Geäußerte letztendlich empfangen. Das trifft genauso auf das Empfangen von E-Mails als auch auf Chattexte zu. Ebenso fehlt sowohl bei der E-Mail als auch dem Chat die Simultaneität von Produktion und Rezeption. Das würde bedeuten, dass eine Unterscheidung von synchron und asynchron redundant ist, wenn eine eindeutige Zuweisung nicht möglich ist und wenn alle Arten der CMC sowohl als semi- als auch als quasi-synchron bezeichnet werden können. Das Merkmal der Synchronität ist deshalb für eine Kategorisierung der CMC nicht sinnvoll. Wenn überhaupt sollte sich der Fokus hier auf die Sende- und Empfangsentscheidungen von Produzenten und Rezipienten richten (vgl. Jakob 2015).
Bei den Facebook Anwendungen, die der Kommunikation dienen, werden die Nachteile dieser Kategorisierung in synchrone und asynchrone CMC ebenso deutlich. Der Facebook Chat wandelt sich zur Facebook Nachricht – nicht nur bei fehlender gleichzeitiger Anwesenheit beider Gesprächspartner, sondern immer, wenn sich der Nutzer dazu entschließt, anstelle eines Chatfensters lieber ein Nachrichtenfenster zu verwenden und/oder eine Chatnachricht nicht gleich lesen und beantworten möchte. Außerdem kann der Kommunikationspartner im Chat zwar erkennen, wann der andere schreibt (es erscheint dann der Schriftzug „schreibt…“), allerdings kann er den Schreibprozess nicht aktiv beeinflussen. So kann es beim Schreiben zu Überlappungen kommen; trotzdem erfolgt die Rezeption nicht simultan, auch wenn beide Kommunikationspartner gleichzeitig schreiben. Das spricht somit ebenfalls dafür, dass es nicht so sehr auf die Synchronität ankommt, sondern darauf, wann und ob der Empfänger einer Nachricht diese liest.
Die Schwachpunkte zweierlei Typisierungen wurden hier aufgezeigt: Die Klassifikation nach Crystal (siehe Kapitel ) hat deutlich gemacht, dass genau darauf geachtet werden muss, was miteinander verglichen wird. Auch das gängige Unterscheidungsmerkmal Synchronität führte zu keiner überzeugenden Kategorisierung der CMC. In einem nächsten Schritt soll geprüft werden, ob die CMC in Bezug zur Medienbegrifflichkeit und der Einführung von Kommunikationsformen besser kategorisiert werden kann.
2.3. CMC im medialen Diskurs
Eine grundlegende Diskussion der Computer-mediated communciation (CMC) sollte bei der Konstituente M ansetzen, also bei der Frage, was unter mediated ‚vermittelt‘ überhaupt zu verstehen ist. Ein wichtiger Aspekt dabei muss sein, dass Medien nicht nur Informationen vermitteln oder überliefern, sondern diese auch mitgestalten. So heißt ein von McLuhan (2001, Titel) verfasstes Statement aus dessen gleichnamigen Werk „The medium is the message“, was – wenn auch etwas überspitzt formuliert – bedeutet, dass das Medium die Art und Weise bestimmt, wie die Kommunikation vonstatten geht. Außerdem nimmt sie Einfluss darauf, was gesagt wird und welcher Kode verwendet wird. Auch Schmitz (1995, 11) geht davon aus, dass sich „mit dem Medium […] auch die Inhalte ändern“. Deshalb ist eine geeignete Definition und Abgrenzung des Medienbegriffs für die Linguistik im Allgemeinen und für diese Arbeit im Besonderen von Bedeutung.
Bezeichnungen wie das Medium Computer, die Medien des Computers (beispielsweise das Medium E-Mail), oder auch Soziale Medien sind im täglichen Gebrauch recht häufig zu finden. Diese neu entstandenen Medien werden auch häufig mit dem Begriff Neue Medien bezeichnet. In der Alltags- und Pressesprache werden mit dieser Bezeichnung computergestützte Medien von den traditionellen Massenmedien wie Radio und Fernsehen abgegrenzt. (vgl. Schmitz 1995, 13). Bei einem zeitlichen Rückblick zeigt sich, dass Anfang des 20. Jahrhunderts mit Neuen Medien das Radio, später das Fernsehen, gefolgt von CDs und DVDs bezeichnet wurden, während damit heutzutage der Computer, aber auch das Internet sowie die Produkte des WWW und des Web 2.0 gemeint sind. Das bedeutet, dass jeder Zeitabschnitt seine eigenen „neuen“ Medien hervorgebracht hat und hervorbringt, je nach Stand der technologischen Entwicklung. Der Begriff Neue Medien ist nach Ratzke (1982) 37 dabei zu verstehen als
[…] der einzige tragfähige Oberbegriff für alle die Verfahren und Mittel (Medien), die mit Hilfe neuer oder erneuerter Technologien neuartige, also in dieser Art bisher nicht gebräuchliche Formen von Informationserfassung und Informationsbearbeitung, Informationsspeicherung, Informationsübermittlung und Informationsabruf ermöglichen […]. (Ratzke 1982, 14)
Ein Blick in die Literatur zum Thema reicht, um festzustellen, dass der Medienbegriff zuweilen sehr überladen ist und ihm verschiedene Definitionen zugrunde liegen. Je nachdem in welchem Bereich er gebraucht wird – von der Physik zur Nachrichtentechnik, von den Kommunikationswissenschaften bis hin zur Parapsychologie38 – lassen sich durchaus sehr unterschiedliche Auslegungen und nicht klar umrissene Gebrauchsweisen finden. Im Folgenden sollen deshalb zunächst die gängigsten Medienbegriffe betrachtet werden.
2.3.1. Gängige Medienbegriffe und die Frage nach ihrer Anwendbarkeit für Computer, Internet und CMC
Generell lassen sich die Medientheorien in vier große Bereiche teilen (vgl. Faulstich 2000, 22). Zu den Einzelmedientheorien gehören vor allem die Theorien zu Radio, Film und Fernsehen, die nur ein einziges Medium, wie beispielsweise das Medium Film thematisieren. In der „kommunikationstheoretischen Medientheorie“ werden Medien als Teile von übergeordneten Kommunikationsprozessen behandelt während bei der „gesellschaftskritischen Medientheorie“ das Medium im Zusammenhang mit anderen (Einzel-)Medien gestellt wird, als Teil eines Kommunikationsprozesses, der der Kultur und Gesellschaft unterzuordnen ist (ebd.). Zum vierten und letzten Block gehört die systemtheoretische Medientheorie, bei der das Kommunizieren „als Teil oder Form des übergeordneten gesellschaftlichen Handelns“ (ebd.) aufgefasst wird. Die im Folgenden thematisierten Mediendefinitionen leiten sich aus den ersten beiden theoretischen Ansätzen her, wie sich noch zeigen wird.
Es soll im Folgenden gezeigt werden, wie sich medientheoretische Definitionen und Kategorisierungen hinsichtlich des Computers, des Internets und der Neuen Medien verhalten und inwieweit diese noch tragbar sind. Schließlich wird eine für diese Arbeit brauchbare Definition und Abgrenzung vorgeschlagen, welche anschließend nach einem kommunikationstheoretischen Ansatz für die CMC überprüft werden soll.
2.3.1.1. Der Medienbegriff nach McLuhan
In einer recht weit gefassten Definition, die auf McLuhan zurückgeht, heißt es „all media are extensions of some human faculty – psychic or physical” (McLuhan & Fiore 1967, 26). Alle Hilfsmittel, die die körperlichen oder geistigen Eigenschaften des Menschen erweitern, wären demnach als Medien zu bezeichnen. So auch beispielsweise ein Mikroskop oder eine Brille, die Extensionen der visuellen Wahrnehmung des Menschen darstellen (vgl. Marx & Weidacher 2014, 48). Besonders der Computer, der in verschiedenen Bereichen als Extension (oder gar als Ersatz) menschlicher Fähigkeiten und Eigenschaften gilt, kann nach dieser Definition als Hilfsmittel und somit als ein Medium betrachtet werden. Allerdings könnten nach dieser Definition auch viele Dinge, die nach dem allgemeinen Verständnis nicht als Medien bezeichnet werden würden, nach McLuhan doch als solche verstanden werden (wie etwa Messer und Gabel als Extensionen der Hände beim Essen). Aber schon beim Autor selbst steht das Medium als Erweiterung kognitiver und kommunikativer Fähigkeiten im Zentrum, weshalb seine Definition entsprechend eingeschränkt werden müsste, wenn damit nur Dinge wie Buchdruck, Fernsehen und eben auch der Computer bezeichnet werden sollen.
2.3.1.2. Primäre, sekundäre und tertiäre Medien nach Pross
Pross (vgl. 1972) wählt für seine Kategorisierung einen Ansatz, der die kommunikativen Fähigkeiten in den Fokus rückt. Nach Pross (vgl. 1972, 127–128) kann zwischen primären,
sekundären und tertiären Medien unterschieden werden.
Unter primären Medien werden solche verstanden, bei denen Kommunikation auch ohne technische Hilfsmittel möglich ist. Sie ist also auf körpereigene Darstellungsmittel, wie Rede, Mimik, Gestik und Körpersprache, angewiesen. Diese „Mittel des menschlichen Elementarkontaktes“ (Pross 1972, 128-144) sind auf kopräsente Situationen, wie sie in der Face-to-Face-Kommunikation vorherrschen, beschränkt. Sekundäre Medien benötigen technische Geräte oder Hilfsmittel zur Produktion und Distribution von Informationen, oder besser gesagt „[d]er Kommunikator braucht ein Gerät“ (Pross 1972, 145-223). Bei tertiären Medien sind diese Hilfsmittel ebenfalls auf der Seite der Rezipienten von Nöten, es gilt „Kommunikatoren und Rezepienten [sic!] brauchen Geräte“ (Pross 1972, 224–262). So zählen beispielsweise Rauchzeichen, von Hand geschriebene Notizen bis hin zu gedruckten Büchern zu sekundären Medien, da bei der Produktion ein technisches Mittel – hier Feuer, ein Stift oder eine Druckmaschine – notwendig sind. Das Telefon, das Radio oder auch das Fernsehen hingegen zählen zu den tertiären Medien, da sowohl der Sender bei der Produktion von Informationen, als auch der Rezipient beim Empfangen dieser ein technisches Hilfsmittel benötigt. Auch E-Mails oder andere über den Computer übertragene Arten der Kommunikation werden oft zu dieser Kategorie gezählt, da in diesem Fall ein Computer von Nöten ist (vgl. Ziegler 2002, 25). Faßler (1997, 117) spricht bei Letzteren von quartären Medien, die er als „computerbasierten und -verstärkten Medienbereiche netztechnischer und elektronisch-räumlicher Konsumtion, Information und Kommunikation“ definiert.
Die Mediengeschichte kann nach dieser Kategorisierung in vier große Etappen eingeteilt werden, die allerdings in ihrer Dauer stark variieren (vgl. Faulstich 2000, 31):39 Während bis zur Erfindung des Buchdrucks die Primärmedien (oder „Mensch-Medien“) die Kommunikation dominieren, waren das bis zum 20. Jahrhundert die Sekundärmedien (oder „Druckmedien“), später auch in Form von Massenmedien (ebd.). Mit dem technischen Fortschritt des 20. Jahrhunderts übernehmen die tertiären (oder „elektronischen Medien“40) die Führung, die schon bald von den „Quartär- oder digitalen Medien'“ abgelöst werden könnte (ebd.). Auch wenn sich die Wichtigkeit der verschiedenen Medientypen im Laufe der Jahre verschoben hat, stellt Faulstich (1994, 29) fest, „daß [sic!] bislang noch kein Medium von einem anderen überflüssig gemacht oder verdrängt worden wäre.“. Allerdings revidiert er diese Aussage später und weist darauf hin, dass sich Medien zwar „weder nach ihrer Zahl noch nach ihrer Bedeutung von den Medien früherer Perioden“ unterscheiden, „wohl aber nach ihrer Art, Form und Funktion“ (Faulstich 2000, 32).41 Auch Holly (1997, 74) weist das Aussterben bestimmter Medientypen durch das Aufkommen neuer zurück: „Keine Angst. Nicht einmal die ältesten Medien werden obsolet. Wir ritzen sogar immer noch Herzen in Bäume und Schrift in Stein [..].“
Pross‘ Definition von primären Medien als Kommunikation ohne Hilfsmittel widerspricht dem allgemeinen Verständnis von medial im Sinne von ‚übertragen‘ oder ‚vermittelt‘ (siehe unten). Außerdem wird der Schrift – vor dem Buchdruck – keine besondere Stellung beigeräumt, da sie nicht zu den primären Medien gezählt wird. Nach dem Verständnis des Autors zählen außerdem nur die Kommunikationsmittel zu den Medien, während die Hilfsmittel zur Produktion, Rezeption und Distribution nur die Kategorien bestimmenden Kriterien sind. Der Computer und das Internet sind somit keiner Kategorie zuordnenbar. In Bezug auf die computergestützten Mittel der Kommunikation kann davon ausgegangen werden, dass es sich dabei um tertiäre Medien handelt, da hier immer ein technisches Hilfsmittel bei der Produktion, Distribution und Rezeption erforderlich ist. Eine Unterscheidung zwischen tertiären und quartären Medien ist zwar für den mediengeschichtlichen Verlauf wichtig, allerdings nicht bei der Unterscheidung der einzelnen Kommunikationsmittel. Heutzutage laufen sowohl Radiosendungen als auch Filme computerbasiert oder -verstärkt ab und auch die Internettelefonie ist mittlerweile weit verbreitet. Eine Differenzierung ist somit redundant, da der Computer fast in allen Bereichen der tertiären Medien eine Rolle spielt (oder spielen könnte – auch wenn das von Produzenten und Rezipienten gar nicht so bewusst wahrgenommen wird).
Eine weitere Frage, die sich bei dieser Kategorisierung stellt, ist, was genau unter einem Kommunikationsmittel verstanden wird. Nach Pross‘ Kategorisierung werden sowohl mündliche Gespräche zwischen zwei Personen, als auch Bücher und Briefe sowie die Telefonie als Kommunikationsmittel bezeichnet. Nach McLuhans Definition des Medienbegriffs (siehe Kapitel ) kann es sich dagegen bei den primären Medien gar nicht um Medien handeln, da die Stimme nicht als Hilfsmittel zur Intensivierung der Informationsverbreitung erachtet werden kann – ebenso wenig ist die Luft als Hilfsmittel zur Schallübertragung anzusehen.
Es stellt sich hierbei außerdem die Frage, welche Rollen die Hilfsmittel einnehmen. Gerade bei den computergestützten tertiären Medien ist unklar, wie Computer, Internet und die einzelnen Kommunikationsmittel definiert oder auch voneinander unterschieden werden können, da es hier in vielen Bereichen zu Überschneidungen kommt. Diese Kategorisierung mag für Einzelmedien nach einem kommunikationstheoretischen Ansatz stimmen, lässt aber viele Bereiche des Spektrums der tatsächlichen Verwendung des Medienbegriffs außen vor.
2.3.1.3. Die verschiedenen Medienbegriffe nach Posner
Der erste Schritt aus dem begrifflichen Chaos muß [sic!] darin bestehen, die verschiedenen Kriterien auseinander zu halten, die den Verwendungen des Wortes „Medium“ zugrunde liegen […]. (Posner 1986, 293–297)
Posner (1986, 293) versteht unter einem Medium „ein System von Mitteln für die Produktion, Distribution und Rezeption von Zeichen, das den in ihm erzeugten Zeichenprozessen bestimmte gleichbleibende Beschränkungen auferlegt“ und hält ferner eine Präzisierung des Medienbegriffs für nötig. Ein Medium ist somit nicht nur ein aus dem Kotext und Kontext gerissenes Einzelmedium, sondern ihm liegen verschiedene Mittel zugrunde, die Zeichen aller Art (wie eben auch Sprache) vom Sender zum Empfänger übermitteln.
Posner (vgl. 1986, 293–297) führt deshalb eine Reihe von Kriterien ein, nach denen sich für das Medium als System von Kommunikationsmitteln verschiedene Medienbegriffe ergeben: biologisch, physikalisch, technologisch, soziologisch, kulturbezogen und kodebezogen.
| Medienbegriff | Medium | Kriterium |
| biologischer | sinnliches Medium | Sinnesmodalität |
| physikalischer | physisches Medium | Kontaktmaterie |
| technologischer | technisches Medium | verwendete Apparate und ihre Produkte |
| soziologischer | soziales Medium | Institution |
| kulturbezogener | kulturelles Medium | Textsorte |
| kodebezogener | Kodierungsmedium | Kode |
Unter dem biologischen Medienbegriff versteht man die Charakterisierung der Zeichensysteme nach den Sinnesorganen (vgl. Posner 1986, 293). Ein Medium muss demnach Signale vermitteln, die von mindestens einem der Sinnesorgane verarbeitet werden können. Als Sinnesmodalitäten werden der Sehsinn (visuell), der Hörsinn (auditiv), der Geruchssinn (olfaktorisch), der Geschmackssinn (gustatorisch) und der Tastsinn (taktil) unterschieden. Gesprochene Sprache wäre beispielsweise ein solches sinnliches Medium. Der physikalische Medienbegriff betrifft die Verbindung zwischen Produktions- und Rezeptionsorgan, in Form chemischer Elemente oder physikalischer Zustände (vgl. Posner 1986, 294). Diese physikalische Verbindung wird teilweise auch Kanal genannt (vgl. Marx & Weidacher 2014, 52).42 Dabei können optische, akustische und haptische Kanäle zur Übertragung von visuellen, auditiven und taktilen Medien unterschieden werden. Unter technischen Medien werden Hilfsmittel bezeichnet, die der Modifikation der Kontaktmaterie dienen. Dazu gehören beispielsweise Brillen oder Hörgeräte, aber auch eine Druckmaschine oder eine Videokamera stellen solche technischen Hilfsmittel dar (vgl. Posner 1986, 294). Der soziologische Medienbegriff hängt stark von den Institutionen ab, die sich die Vermittlung von Informationen zur Aufgabe gemacht haben. Zu nennen wären hier Museen oder Pinakotheken, aber auch Verlage oder Telefonanbieter (vgl. Posner 1986, 295). Ein kulturelles Medium hängt stark von gesellschaftlichen Konventionen und kulturellen Praxen ab, die zu bestimmten Formen der Kommunikation geführt hat, wie beispielsweise der Herausbildung von Textsorten. Hier steht der Zweck der Kommunikation im Vordergrund (vgl. Posner 1986, 296). Der kodebezogene Medienbegriff schließlich fokussiert die Regeln, nach denen Zeichensysteme charakterisiert sind (ebd.). Dieser Kode, auch semiotischer Modus genannt (vgl. Marx & Weidacher 2014, 53), bezeichnet eine konventionalisierte Zeichenressource, wie beispielsweise die Verwendung einer bestimmten Schriftart oder einer bestimmten Sprache.
Eine Kategorisierung der Medien, die bei Computer, Internet und CMC eine Rolle spielen könnte nach Posners Kategorisierung folgendermaßen aussehen: Es werden vor allem visuelle und auditive Sinnesmodalitäten angesprochen, wie bei getippten Texten (in E-Mails, Chats, etc.) oder bei Übertragungen von gesprochener Sprache (VoIP, Videos). Dabei werden zum einen der optische und zum anderen der akustische Kanal verwendet. Die zugrunde liegenden technischen Medien sind auf der Seite des Produzenten der Computer und die Tastatur sowie die Computermaus zum Absenden des Geschriebenen. Auf der Seite des Rezipienten gehören dazu ebenfalls ein Computer und Bildschirm zum Empfangen der Nachricht. Die Übertragung erfolgt über das Internet, womit auch dieses zu einer der technischen Voraussetzungen der Distribution von Informationen oder Zeichen zählt. Die sozialen Medien, also die Institutionen, die die Vermittlung ermöglichen, sind zum einen der Internetanbieter sowie die unterschiedlichen Plattformen, Programme oder Seiten (beispielsweise der E-Mail Provider).43 Die Form der Kommunikation unterliegt speziellen (teilweise sicher von der Institution vorgegebenen) Konventionen und der Kode ist die spezifische Sprache mit all ihren linguistischen Besonderheiten (siehe Kapitel ).
Allerdings sind bei dieser Kategorisierung zu sehen, dass die hierbei angesetzten Definitionen der Medienbegriffe ziemlich weit gefasst und teilweise recht abstrakt. Es können nach dieser Typisierung zum einen (über-) natürliche Phänomene als Medien miteinbezogen werden, die nicht von Menschenhand gemacht sind (dazu zählen sinnliche und physische Medien, wie beispielsweise ein Sonnenuntergang). Auch die Unterscheidung zwischen dem biologischen und physikalischen Medienbegriff ist fraglich, da den Sinnesmodalitäten auch chemische und physische Vorgänge und Zustände zugrunde liegen. Bei dem soziologischen oder kodebezogenen Medienbegriffen stellt sich die Frage, inwieweit diese darunter gefassten Medien definiert werden können: beispielsweise „die soziale Medien wie Galerien, Museen und Bibliotheken“ (Posner 1986, 295) oder die kulturellen Medien wie „Nachricht, Kommentar, Kritik, Reportage, Kritik“ (Posner 1986, 296) als „Mittel zur Produktion, Distribution und Rezeption von Zeichen“ (Posner 1986, 293).
Trotz der eben genannten Kritikpunkte bietet dieser Ansatz den Vorteil, dass mit dem technologischen Medienbegriff nun auch die Hilfsmittel, also die technischen Geräte, als Medien bezeichnet werden können (im Gegensatz zu Pross). Allerdings sollte weiter zwischen den verschiedenen technischen Medien unterschieden werden, denn die Hilfsmittel auf der Seite des Senders und des Empfängers unterscheiden sich, wie exemplarisch für den Computer gezeigt, und so gibt es beispielsweise auf der einen Seite zur Produktion ein Mikrofon und auf der anderen Seite einen Lautsprecher zur Rezeption. Die Übermittlung, die hier meist über das Internet läuft, unterscheidet sich ebenfalls von anderen technischen Medien. Eine Differenzierung von Produktions-, Rezeptions- oder Distributionsmedien fehlt und auch den Eigenschaften von Computern als Speichermedium wird die Medienkategorisierung nach Posner nicht gerecht.
2.3.1.4. Die Unterscheidung von Medien, Zeichentypen und Kommunikationsformen nach Holly
Holly (1997, 65) mahnt ebenfalls zur Vorsicht bei den „sehr weitgefassten Gebrauchsweisen“ in der Verwendung des Medienbegriffs und schlägt eine „Rückbesinnung auf die Strukturen von Zeichensystemen und von Kommunikation“ vor. In Hollys (2000)44 technisch-kommunikationsbezogenen Definition des Medienbegriffs heißt es
Medien sind technische Artefakte; sie dienen der Zeichenherstellung, -speicherung oder -übertragung und damit der zwischenmenschlichen Kommunikation, deren raumzeitliche Beschränkungen durch sie überwunden werden kann. (Holly 2000, 84)
Vor diesem Hintergrund unterschiedet er zwischen 1) Zeichentypen, 2) Medien und 3) Kommunikationsformen (vgl. Dürscheid 2003, 2-3):
- Bei der Kommunikation verarbeiten Medien verschiedene Zeichentypen, die Holly (vgl. 1997, 65) nach den folgenden Kriterien kategorisiert: (1) körperlich/technisch, (2) verwendeter Kanal (vor allem optisch und akustisch), (3) dynamisch/statisch und (4) räumliche und zeitliche Anordnung. Allerdings braucht es meist Hilfsmittel, um Informationen zu übertragen. Ausnahme stellt die direkte Face-to-Face-Kommunikation dar.45 In einem Brief bedient sich der Schreiber einer Schrift, dabei ist die „Schrift selbst nicht als ein Medium anzusehen“, sondern als ein technisches Zeichensystem, das vor allem den optischen Kanal anspricht (Holly 1997, 67). Neben der Schrift führt Holly weitere für die mediale Kommunikation relevante Zeichentypen ein, zu denen unter anderem reale Laufbilder (Videos) zählen sowie Bildartefakte (Fotos) oder Tonartefakte (übertragene oder aufgenommene Stimmlaute und Töne). Das verwendete Zeichensystem ist ein grundlegendes Merkmal, bei dem zum einen zwischen nichtsprachlichen und sprachlichen Zeichen unterschieden wird. Zum anderen kann innerhalb der sprachlichen Zeichen zwischen Laut- oder Schriftzeichen, also zwischen gesprochener und geschriebener Sprache, differenziert werden (oder zwischen „Sprech-/ Schriftsprache“ (Androutsopoulos & Schmidt 2001, 5)).
- Die Schrift landet nicht ohne Hilfsmittel auf dem Brief, es wird ein Stift oder ein anderes Schreibgerät dazu benötigt. Dieses wiederum ist nach Hollys Verständnis als ein (technisches) Medium anzusehen, denn „Medien sind nur die materiellen Hilfsmittel, die wir im Zusammenhang mit Schrift verwenden“ (ebd.). Medien sind zudem nicht nur nach den von ihnen verwendeten Zeichensystemen kategorisierbar, sondern auch nach ihrem Verhalten zu Raum und Zeit. Hierfür werden die Begriffe Speicher- und Direktübertragungsmedien angeführt (Holly 1997, 68).
- Kommunikationsformen sind schließlich die Realisierungen durch unterschiedliche Medien, den „virtuellen Konstellationen von einem bestimmten Zeichenspeicherungs- oder Übertragungspotenzial“ (Holly 1997, 69). Bei dem Beispiel des eben genannten Briefes wäre demnach die tatsächliche Realisierung des Briefes die Kommunikationsform.46
Wie lässt sich diese Unterscheidung von Zeichensystemen, Medien und Kommunikationsformen auf den Computer, das Internet und die CMC anwenden? Die vom Computer vermittelten Zeichensysteme können ganz unterschiedlicher Art sein. Zumeist sind sie technisch, aber durch die Möglichkeiten der Videotelefonie oder -konferenzschaltungen können körperliche und technische Zeichensysteme miteinander verschmelzen.47 Auch bei den verwendeten optischen und akustischen Kanälen sowie bei der Unterscheidung zwischen statisch und dynamisch, ist eine klare Differenzierung nicht immer möglich (beispielsweise bei hochgeladenen und schriftlich kommentierten Videos). Diese verschiedenen Zeichensysteme bilden schließlich die Grundlage für die Kommunikationsformen, die sich daraus herausgebildet haben und auf die in Kapitel in Bezug auf die CMC näher eingegangen werden soll.
Diese große Vielfalt an Zeichensystemen führt auch zu einem breiten Spektrum an Medien, die diese verwenden: die verschiedenen Plattformen, Programme und Internetseiten mit Hilfe derer die Produktion und Rezeption stattfindet. Nach einer Kategorisierung hinsichtlich der Kriterien Raum und Zeit kann sowohl der Computer, als auch das Internet als Speicher- und Übertragungsmedium angesehen werden.
Der Computer dient zwar als Produktions-, Speicher- und Distributionsmedium von Zeichensystemen, das Ziel ist dabei allerdings nicht immer die zwischenmenschliche Kommunikation, wie die Definitionen von Holly und Habscheid vermuten lassen. Denn nur weil mit „dem vom Menschen hergestellten Apparat“ (Habscheid 2000, 137) die Herstellung, Verbreitung und Speicherung von Zeichen ermöglicht wird, heißt das nicht automatisch, dass es sich dabei um „zwischenmenschliche Kommunikation“ (Holly 2000, 84) handeln muss. Man denke beispielsweise an Computer, die in Fabriken Maschinen steuern, die zwar von Menschen hergestellt und mit Hilfe von Zeichensystemen bedient werden, aber deren Ziel nicht die zwischenmenschliche Kommunikation darstellt (siehe Typ b) in Abbildung 6). Schelhowe (1997, 10) spricht deshalb von einem „instrumentalen Medium“, um den Computer als Instrument, Maschine und Werkzeug miteinzubeziehen.48
Trotzdem erscheint dieser Ansatz als vielversprechend für die Kategorisierung der CMC im Allgemeinen und der Facebook Statusmeldungen im Besonderen.
2.3.2. Der Medienbegriff in Bezug auf die CMC
Die letzten Abschnitte zusammenfassend, lässt sich festhalten: Während sich McLuhans weite Definition sowohl für den Computer, das Internet und schließlich die CMC als Erweiterungen und Intensivierungen der menschlichen Fähigkeiten eignet, wird dabei jedoch nicht zwischen Instrumenten und Vermittlungsinstanzen, die an den kommunikativen Prozessen beteiligt sind, differenziert. Nach Pross Typisierung lässt sich feststellen, dass es sich bei den computergestützten Kommunikationsmitteln um tertiäre (bzw. quartäre) Medien handelt. Allerdings spielen hier die Hilfsmittel, wie der Computer oder das Internet, nur als Kriterien zur Differenzierung von Kommunikationsmitteln eine Rolle und werden selbst nicht als Medien angesehen. Dafür schafft Posner mit der Einführung weiterer Medienbegriffe eine gute Basis. Einige der Medienbegriffe sind jedoch sehr abstrakt (beispielsweise die sozialen Medien) und es können auch natürliche Phänomene darunter fallen. So können hier nun mit dem technologischen Medienbegriff auch die Hilfsmittel, wie Computer oder Internet, als Medien Berücksichtigung finden, allerdings können diese sowohl als „Vermittler“, also als Distributionsmedien, als auch als „Mittel“, als Produktions- oder Rezeptionsmedien, auftreten.49
Der Medienbegriff, auf den sich die CMC zumeist bezieht, basiert auf dem technologischen Medienkonzept. Auch die technisch-kommunikationsbezogenen Definitionen und Kategorisierungen des Medienbegriffs nach Holly und Habscheid präsentieren sich als vielversprechend in Bezug auf den Computer, das Internet, die CMC im Allgemeinen und die Facebook Statusmeldungen im Besonderen. Deshalb soll im Folgenden der Medienbegriff für die CMC definiert und abgegrenzt werden. Dafür werden Kriterien festgelegt, deren Gültigkeit im Anschluss exemplarisch für Facebook und die Facebook Statusmeldungen überprüft werden sollen.
2.3.2.1. Die grundlegenden Definitions- und Abgrenzungskriterien
Medien sind sowohl von Menschenhand erschaffene Hilfsmittel, „technische Artefakte“ (Holly 2000, 84), als auch „materiale, vom Menschen hergestellte Apparate“ (Habscheid 2000, 137). Es handelt sich hierbei also nicht um natürliche Phänomene. In Bezug auf die CMC wird unter Hilfsmittel der Computer verstanden. Es handelt sich dabei um ein (mobiles) Endgerät, das sowohl über technologisch-physikalische Eigenschaften (Hardware), als auch über Daten verarbeitende Programme (Software) verfügt (siehe Kapitel ). Computer und all ihre Komponenten sind somit komplexe, vom Mensch erschaffene, technische Hilfsmittel – also Medien.
Medien dienen außerdem der Kommunikation und sind „unweigerlich immer dort und nur dort im Spiel, wo sprachliche Kommunikation stattfindet, ohne dass die elementare Situation des Sprechens bei physisch unmittelbarer Anwesenheit der Gesprächspartner gegeben ist“ (Krefeld 2011a, 269). Für die CMC heißt das, dass der Computer als Distributionsmedium die Kommunikation bei möglicher zeitlicher, nicht aber räumlicher, simultaner Anwesenheit der Gesprächsteilnehmer vermittelt.
Wie schon gesehen, kann der Computer bei drei Arten der Kommunikation eine Rolle spielen (siehe Abbildung 6 in Kapitel ): Der Kommunikation a) Computer-Computer, b) Mensch-Computer und c) Mensch-Mensch vermittelt durch den Computer. Der Computer fungiert bei a) und b) als Instrument oder als Werkzeug, das Befehle ausführt, während seine Funktionen bei Typ c) weitaus komplexer sind. Von Gesprächspartnern, die nicht unbedingt räumlich anwesend sein müssen, kann nur bei Typ c) die Rede sein. Deshalb sollte im Hinblick auf die CMC der Medienbegriff auf die zwischenmenschliche Kommunikation begrenzt werden, da sich bei den anderen Typen die Kommunikation schon in ihren elementaren Komponenten von der CMC unterscheidet.50
In Bezug auf die CMC sind Medien also vom Menschen erschaffene, technische Hilfsmittel, die der zwischenmenschlichen Kommunikation dienen. Der Medienbegriff berücksichtigt somit den Computer (inklusive all seiner Komponenten) als Hilfsmittel, der somit der zwischenmenschlichen Kommunikation dient.
2.3.2.2. Das Zeichensystem der CMC und der digitale Code
Kommunikation erfolgt mittels der Produktion und Verarbeitung von Zeichen aus verschiedenen Zeichensystemen; bei der CMC erfolgt dies sowohl kognitiv als auch durch Medien. Die Kommunikation kann dabei sowohl sprachlich als auch para- oder nichtsprachlich stattfinden. Es können Zeichensysteme verschiedener Art, wie Texte oder Bild- und Tonmaterial, verwendet werden.51 Dabei werden häufig auch verschiedene Zeichentypen gemischt, was als „Multikodalität“ bezeichnet werden kann (vgl. Weidenmann 2001, 415–466).52
Kommunizieren im Sinne der CMC heißt also, dass Zeichen zuerst kognitiv produziert und versprachlicht werden, dann mit Hilfe von Medien produziert, gegebenenfalls modifiziert, gespeichert und daraufhin übertragen werden. Dieser mediale Vorgang kann sehr komplex sein, denn das vom Menschen verwendete Zeichensystem, sei es getippte, also geschriebene, oder gesprochene Sprache muss erst vom Computer kodiert werden, um schließlich von diesem verstanden und weiterverarbeitet zu werden. Diesen Prozess nennt man auch Digitalisierung, welcher sich folgendermaßen verdeutlichen lässt:
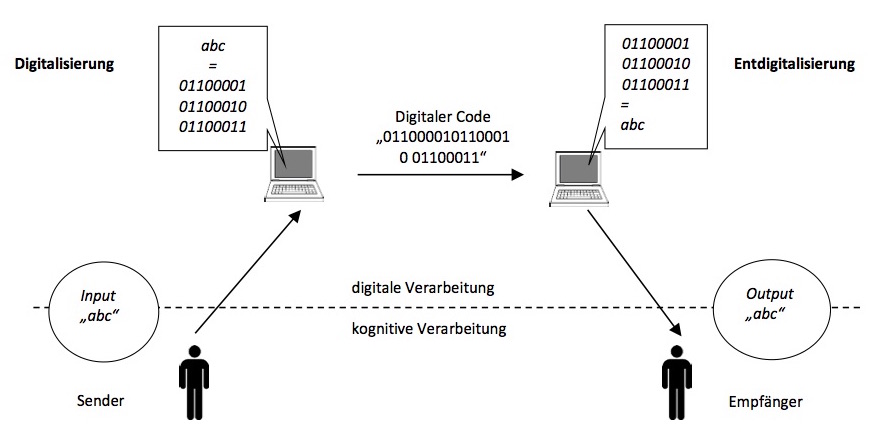
Digitalisierung und Entdigitalisierung in der CMC.
(Lizenz: CC BY SA)
Bei der Digitalisierung werden analoge Informationen, wie sprachliche Produkte, digital kodiert. Das heißt, sie werden meist in einen Zeichensatz übersetzt, der sich als binärer Code (z.B. ASCII) darstellen lässt. Dieser kann vom Computer verarbeitet und somit übermittelt werden. Damit der Rezipient schließlich die Informationen in einer ihm verständlichen Form erhalten und kognitiv verarbeiten kann, ist eine Entdigitalisierung erforderlich, bei der der binäre Kode wieder zurück in ein Zeichensystemm wie beispielsweise der Schrift in alphabetischer Form übersetzt wird.53 Auch wenn die anderen Kommunikationstypen, bei denen der Computer eine Rolle spielt, in Hinblick auf die CMC ausgeklammert wurden, sind bei der Kommunikation des Typs b) (siehe Abbildung 6) die Prozesse der Digitalisierung und Entdigitalisierung erforderlich. Dabei erfolgen diese aber nur innerhalb eines Computers und der Output geht direkt an den Sender zurück. Bei der Kommunikation des Typs a) (siehe Abbildung 6) hingegen sind diese Prozesse nicht vonnöten, da hier nur digitaler Kode als Zeichensystem zur Kommunikation zwischen Computern verwendet wird.
Für die Kommunikation der CMC heißt das folglich, dass der symbolische Austausch zwischen Menschen nur über die Prozesse der Digitalisierung und Entdigitalisierung erfolgen kann. Der digitale Code stellt dabei ein Hilfsmittel dar, also ein Medium nach den bisher erörterten Kriterien: ein technisches, Hilfsmittel, das der zwischenmenschlichen Kommunikation bei physischer und möglicher zeitlicher Abwesenheit der Kommunikationspartner dient.54 Das Medium digitaler Code für sich alleine genommen ist aber relativ nutzlos. Es braucht weitere Hilfsmittel, wie den Computer und die in ihm inhärenten Komponenten, um sprachliches Material umzuwandeln und zu vermitteln. Der Komplexität dieser Kombination von Hilfsmitteln soll der Begriff digitaler Medienkomplex gerecht werden, der im nächsten Abschnitt genauer beschrieben wird.
2.3.2.3. Funktionsbasierte Kategorisierung des digitalen Medienkomplexes
Weder beim Computer, noch beim Internet oder beim digitalen Code handelt es sich um ein Einzelmedium.55 Dem Computer sind mehrere Arten von Medien untergeordnet: das Internet oder der digitale Code sowie einzelne Bestandteile der Hard- und Software lassen sich nur in Verbindung mit anderen Medien nutzen. Dabei kann ein und dieselbe Komponente verschiedene Funktionen erfüllen. Die Zusammenfassung mehrerer Medien auf einem Gerät, wird auch häufig mit dem Begriff Multimedium bezeichnet.56 Wenn verschiedene Einzelmedien zusammenwachsen, wird auch von Medienkonvergenz oder von „media merging“ (Schlobinski & Siever 2005, 3), dessen Resultat ein „Hybridmedium“ (vgl. Beck 2006, 21) ist, gesprochen.
Der Computer, in all seinen Erscheinungsformen und mit all seinen Komponenten, vereint in sich verschiedene Hilfsmittel und kann deshalb als digitaler Medienkomplex bezeichnet werden. Er dient zum einen als „Mittel“ im Sinne eines Sende- und Empfangsgeräts von CMC. Zum anderen ist er Speichermedium, da Informationen direkt auf ihm (oder auf externer Hardware, wie beispielsweise CDs, DVDs oder USB-Sticks) gespeichert werden können. Schließlich ist der Computer auch Produktionsmedium, das Zeichen mittels Hilfsmitteln zur Eingabe (wie der Tastatur oder dem Mikrofon) wiedergibt, und Präsentationsmedium, das der Ausgabe von Informationen (wie Bildschirm oder Lautsprecher) dient.
Die Informationen werden schließlich über das Internet übertragen, weshalb hier auch von einem Übertragungsmedium gesprochen werden kann. Hierbei werden Informationen auf verschiedene Arten (Kabel, Wireless bis hin zu Protokollen der Übertragung (HTTP)) übermittelt. Das Internet ist somit „Vermittler“, aber gleichzeitig auch Speichermedium, das Informationen im Netz, auf Datenbanken oder auf dem Weg dahin speichert.
Das Internet ist damit zum einen eine gigantische Datenbank, zum anderen ein komplexes Kommunikationsnetzwerk, an dessen Endpunkten Computerterminals stehen und an denen Menschen agieren. Das Internet ist somit ein Medium, in dem sich eine transnationale Kommunikationsgemeinschaft konstituiert […]. (Runkehl & Schlobinski & Siever 1998, 27)
Das Internet wird häufig als „das“ technisches Hilfsmittel für die CMC angesehen, zum einen weil es eine technische Infrastruktur darstellt (vgl. Beck 2006, 19). Zum anderen weil es selbst eine technische Plattform ist, die als Extension kognitiver und kommunikativer Fähigkeiten dem Verbreiten von Informationen dient (vgl. Bleicher 2010, 16). Allerdings wird mit dem Internet die Verbindung von Netzwerken verstanden, denen wiederum Computer zugrunde liegen. Das heißt, sowohl das Internet als auch der Computer können somit als Übertragungsmedien bezeichnet werden.
Kommunikation, und somit die Produktion, Rezeption und Übertragung von Zeichen, funktioniert bei der CMC aber nicht nur durch die zu Hilfenahme von Computern und Internet, grundlegend dafür ist der digitale Code (siehe Kapitel ). Dieser Code ist ein technisches Hilfsmittel, das der zwischenmenschlichen Kommunikation dient indem es Zeichensysteme – egal welcher Art – übersetzt und somit selbst ein Medium darstellt.
Allerdings kann der digitale Code nicht alleine als Hilfsmittel dienen, sondern erst in Verbindung mit Hardware und Software können die Prozesse der Digitalisierung und Entdigitalisierung durchgeführt werden. Genauso wenig kann eine Tastatur allein als Produktionsmedium angesehen werden, denn ohne die nötige Hard- und Software des Computers stellt sie kein adäquates Hilfsmittel dar. Die Komponenten des Computers, die für das Funktionieren der Prozesse verantwortlich sind, können folglich als digitalisierende Medien oder Repräsentationsmedien bezeichnet werden. Diese kodieren die übertragene Information – sei es bei der Textproduktion in Textverarbeitungsprogrammen (zum Beispiel mittels dem häufig verwendeten ASCII-Code) oder bei der Eingabe von unformatiertem Text (beispielsweise zur Erstellung von Internetseiten mit Hilfe von HTML). Anschließend transferieren sie den Code wieder in ein Schriftsystem zurück.
Zusammenfassend lässt sich sagen, dass der Computer bei der CMC in seinen Funktionen als Mittel und Vermittler durchaus als Medium angesehen werden kann. Dieses Medium lässt sich aufgrund seiner verschiedenen Komponenten jedoch besser als ein digitaler Medienkomplex fassen, der je nach Funktion als Speicher-, Übertragungs-, Präsentations- und Produktionsmedium dienen kann. Auch die wichtige Rolle des digitalen Codes, selbst als Medium definiert, ist in der Bezeichnung des Computers als digitalisierendes Medium enthalten. Dabei sind die existentiellen Beziehungen der einzelnen medialen Komponenten zueinander sowie die Möglichkeit, dass eine Komponente je nach Funktion(en) mehreren Medienkategorien zugeordnet werden kann, hervorzuheben. Die Einführung des Begriffs des digitalen Medienkomplexes macht es zum einen leichter, Internet und Computer sowie den verwendeten digitalen Code als Medien der CMC zu bezeichnen, zum anderen ist er aber auch elementar für die CMC insofern, dass nicht nur die Hardware miteinbezogen wird, sondern auch die Software, die ebenfalls ein Hilfsmittel der CMC darstellt.
2.3.2.4. Facebook im medialen Diskurs: Beiträge als Kommunikationsmedium
Bisher wurden also die folgenden beiden Merkmale und Kriterien festgehalten, die bei der Abgrenzung und Definition von Medien in Bezug zur CMC helfen sollen: 1) Medien sind vom Menschen erschaffene, technische Hilfsmittel, die der zwischenmenschlichen Kommunikation dienen. Dabei werden Zeichen verschiedener Art durch sie verarbeitet. 2) Die vermittelnde und mittlere Instanz ist bei der CMC nicht nur ein „Computer“. Vielmehr handelt es sich dabei um einen digitalen Medienkomplex, dem sich verschiedene Medientypen unterordnen lassen, die in ihrem Zusammenwirken die Kommunikation ermöglichen.
Auch in Bezug auf Facebook und die Statusmeldungen lässt sich festhalten, dass hier ein digitaler Medienkomplex zu Grunde liegt. Facebook Statusmeldungen als solche als Unterkategorie dieses Komplexes zu definieren, erweist sich jedoch als problematisch. Es lässt sich zwar sagen, dass es sich bei Facebook und somit auch den Facebook Statusmeldungen um vom Menschen erschaffene Hilfsmittel zur zwischenmenschlichen Kommunikation handelt und somit die Hauptkriterien für die Bestimmung eines Medium erfüllt sind. Allerdings ist Facebook selbst weder ein Computer noch ein im digitalen Medienkomplex enthaltenes Medium. Trotzdem lässt sich festhalten, dass ein Funktionieren dieser SNS ohne diese nicht möglich wäre, denn es bedarf der nötigen Hard- und Software sowie der für den Prozess der Digitalisierung und Entdigitalisierung des sprachlichen Codes nötigen Komponenten, die die Produktion, Distribution und Rezeption von sprachlichen Zeichen erst ermöglichen.
Die Facebook Statusmeldungen lassen sich als Kommunikationsmedium von den anderen Medienbegriffen besser abgrenzen.57 Die Kommunikation kann hier als unmittelbare, direkte Funktion dieses Medientypus angesehen werden, während der digitale Medienkomplex nur indirekt dazu beiträgt. Oder anders ausgedrückt: Mit einem Computer, bestehend aus Hard- und Software sowie dem Internet kann noch nicht kommuniziert werden; es bedarf beispielsweise E-Mail Providern, Chaträumen oder eben SNS wie Facebook, damit Kommunikation stattfinden kann.58 Dass die Kommunikation bei Facebook eine wichtige Rolle spielt, lässt sich daran erkennen, dass verschiedene Kommunikationsplattformen in die SNS integriert wurden (Facebook Nachrichten, Chat und Statusmeldungen, siehe Kapitel ).59 Diese erfüllen dabei verschiedene Zwecke und die Grenzen zueinander können durchaus verschwimmen: sie dienen als Speichermedien, da die Kommunikation dort gespeichert wird.60 Sie dienen aber auch als Produktions- und Übertragungsmedien und auf der Seite des Empfängers sind sie Präsentationsmedien, die übertragene Informationen anzeigen.
Das heißt also zum einen, dass es sich auch bei einem Kommunikationsmedium um einen Medienkomplex handelt, der verschiedene Medien miteinschließt, die je nach Funktion unterschiedlich kategorisiert werden können. Zum anderen ist das Kommunikationsmedium in seiner Komplexität immer an einen digitalen Medienkomplex gebunden ohne den es nicht existieren kann.
Mit Hilfe der hier genannten Definitionskriterien, lässt sich ein Medium klar definieren. Festzuhalten ist dabei, dass der hier eingeführte digitale Medienkomplex den gemeinsamen Nenner aller CMC Typen bildet: CMC ist Kommunikation, die durch einen Computer, der einen digitalen Medienkomplex darstellt, vermittelt wird. Mittels des Begriffs des Kommunikationsmediums lassen sich alle Typen der CMC schließlich einordnen. So stellt Facebook eine Plattform dar, auf der verschiedene Kommunikationsmedien angeboten werden, die die zwischenmenschliche Kommunikation ermöglichen.
Nun wurde bisher der Fokus auf die Komponente der „Vermittlung“ hinsichtlich der CMC gerichtet. Das Ergebnis dieser Vermittlung, die Herauskristallisierung von Kommunikationsformen, soll im Folgenden betrachtet werden.
2.3.3. Facebook Statusmeldungen als Kommunikationsform
2.3.3.1. Die technischen Rahmenbedingungen der Medien: Affordanzen und Constraints
Der digitale Medienkomplex und die mit diesem in Verbindung stehenden Kommunikationsmedien stellen der CMC unterschiedliche technische Rahmenbedingungen zur Verfügung. So haben sich viele unterschiedliche computer- und internetbasierte Plattformen und Anwendungen herausgebildet, die ganz verschiedene kommunikative Funktionen erfüllen. Diese Rahmenbedingungen werden auch Affordanzen und Constraints genannt (vgl. Lemke 2002, Barton & Lee 2013, Marx & Weidacher 2014).61 Die Möglichkeiten, die das Medium stellt, um Informationen zu übermitteln oder um zu kommunizieren, sind demnach die positiven Rahmenbedingungen oder auch Affordanzen. Die Einschränkungen, die sich durch die Verwendung eines bestimmten Mediums ergeben, sind die negativen Rahmenbedingungen, die Constraints. Diese Rahmenbedingungen stellen die technische Grundlage dar, auf deren Basis sich Formen der Kommunikation herausbilden können (vgl. Marx & Weidacher 2014, 58). Am Beispiel des Kommunikationsmediums Twitter lässt sich das gut verdeutlichen: Bei den Microblogging-Nachrichten von Twitter kann nur eine begrenzte Anzahl an Zeichen verwendet werden, die die Information auf eine bestimmte Länge limitieren. Diese Zeichen muss der Nutzer über eine Tastatur eingeben, womit der Beitrag auf die Verwendung eines alphanumerischen Zeichensystems eingeschränkt wird. Zusätzlich hat der Sender die Möglichkeit, Emoticons und Querverweise (mittels Hashtags ‚#‘) über die Tastatur zu produzieren, ist aber ansonsten auf die semiotischen Mittel der Sprache angewiesen (vgl. Marx & Weidacher 2014, 56). Das Kommunikationsmedium stellt also Affordanzen und Constraints zur Verfügung, die die Kommunikation leiten.
Diese Affordanzen und Constraints sind aber nicht als immer gleich bleibende Rahmenbedingungen zu betrachten. Sie können sich ändern und werden von ihren Entwicklern immer wieder den Bedürfnissen der Nutzer angepasst. Und auch wenn sie stark die Herausbildung einer bestimmten Kommunikationsform beeinflussen, kann die Art und Weise wie kommuniziert wird Einfluss darauf haben, wie diese Affordanzen von Programmierern weiter entwickelt werden. So hat beispielsweise der häufige Gebrauch von Emoticons, die durch die Kombination der Zeichen „:“, „-“ und „)“ das lachende Smiley „:-)“ ergeben dazu geführt, dass bei Facebook oder Whatsapp beim Schreiben in ein Textfeld nicht nur alphanumerische Zeichen zur Verfügung stehen, sondern auch eine große Auswahl an Emoticons (und Emojis, siehe Kapitel ), die er zu kommunikativen Zwecken einsetzen kann. Es bleibt also festzuhalten, dass die Kommunikation selbst die technischen Rahmenbedingungen ändern kann Allerdings geschieht dies erst, wenn sich ein häufiger Gebrauch von sprachlichen und para- oder nichtsprachlichen Arten der Kommunikation in einer Nutzergemeinschaft konventionalisiert hat.
Bei der Kommunikation entscheidet sich der Sender einer Information nicht nur für den digitalen Medienkomplex des Computers mit all seinen Komponenten, sondern auch für das Kommunikationsmedium und somit die Rahmenbedingungen, die Affordanzen und Constraints, die dieses mit sich bringt. Doch nicht nur diese Medienverbindung bestimmt die Art und Weise der Kommunikation. Die Produzenten selbst entscheiden, welche der gegebenen Möglichkeiten sie nutzen möchten, und tragen damit dazu bei, was für eine Form der Kommunikation sich herausbildet. Wenn sich dabei viele Produzenten bei der Nutzung des Medienkomplexes ähnlich verhalten, können sich mehr oder weniger starre Konventionen ergeben, die als Kommunikationsformen bezeichnet werden.62
2.3.3.2. Kommunikationsformen der CMC
Kommunikationsformen müssen zunächst von den Begriffen Textsorten und kommunikative Gattungen, die beide in der Literatur der Bezeichnung von Typen der CMC dienen, abgegrenzt werden (vgl. Dürscheid 2005, 3). Nach Zieglers (2002, 19) Verständnis konstituiert sich eine Textsorte „aufgrund bestimmter textinterner und textexterner Eigenschaften“. Zu den textinternen Faktoren zählt er die Textstruktur, den Textaufbau und die Zusammensetzung des Textes; zu den textexternen Merkmalen gehören solche, die die Merkmale der diskursiven, kommunikativen und situativen Ebene (dazu gehören Faktoren wie Medium und Kommunikationsbereich) beschreiben (vgl. Ziegler 2002, 19-20). Kommunikationsformen werden somit nur mittels textexterner Kriterien definiert. Bezüglich der Rolle des Mediums (oder des Medienkomplexes) lässt sich sagen, dass dieses ein Merkmal aus der textexternen Beschreibungsebene darstellt, sowohl bei der Textsorte als auch bei den Kommunikationsformen. Auch Dürscheid (2005, 5) folgt diesem Ansatz indem sie Kommunikationsformen als „kommunikative Konstellationen, die über ein technisches Hilfsmittel erst möglich gemacht werden, aber auch solche, die ohne ein Hilfsmittel auskommen“ definiert. Zu den letzteren zählen Gespräche von Angesicht zu Angesicht (face-to-face), bei denen eben kein Hilfsmittel verwendet wird (vgl. Kommunikationsmittel nach Pross, siehe Kapitel ).63
Schließlich lassen sich noch Kommunikationsformen und kommunikative Gattungen unterscheiden. Nach Dürscheid (2005, 9) sind „kommunikative Gattungen […] die in der Kommunikation konstruierten Handlungsmuster, die den Beteiligten eine Orientierung geben.“ Dabei ist die Interaktion, die „nach einem bereits verfestigten Handlungsmuster“ vonstattengeht, eine Voraussetzung (Dürscheid 2005, 11). Hingegen stellen die „Kommunikationsformen […] die Rahmenbedingungen der Interaktion dar. Sie sind durch bestimmte Merkmale gekennzeichnet (Zeichentyp, Kommunikationsrichtung usw.).“ (ebd.). Die sich noch in der Entstehung befindende CMC lässt sich somit aufgrund der fehlenden „verfestigten Handlungsmuster“ nur schlecht als kommunikative Gattung beschreiben (vgl. Androutsopoulos & Schmidt 2001, 6).
In diesem Kontext muss auch der Begriff der Diskurstradition Erwähnung finden, der im Bereich der deutschen Romanistik großen Zuspruch erhält.64
Es handelt sich dabei um Komplexe von Diskursregeln, die auf der Basis der Sprechregeln sowie der Sprachregeln operieren, aber im Unterschied zu ersteren nicht universal, sondern historisch und konventionell sind und im Gegensatz zu letzteren gerade nicht (oder allenfalls zufällig) an Sprachgemeinschaften gebunden sind. Wir erkennen hier die genuine Form der Historizität des Diskurses. (Koch 1988, 341–342)
Das heißt, auch wenn Äußerungen „historisch einmalig“ sind, können sie sich „auf andere individuelle Ereignisse beziehen, diese wiederholen und verändern“ (Kabatek 2011, 92). Diskurstraditionen sind also eine Art Muster von geschriebenen Äußerungen und gesprochenen Texten, die übersprachlich sein können und denen sich „Gattungen (Rätsel, Volkslied, Novelle, Sonett, Gesetzestext, Essay, Trauerrede etc.), Gesprächsformen (höfische Konversation, Beichtgespräch, Wegauskunft, Verkaufsgespräch etc.), Stile (Manierismus; genus humile/mediocre/sublime; trobar clus; dolce stil novo; etc.)“ unterordnen lassen.
Auf Grundlage dieser Abgrenzungen und Definitionen wurde von Androutsopoulos & Schmidt (2001) ein Kriterienkatalog mit fünf Merkmalen zur Bestimmung von Kommunikationsformen vorgeschlagen. Dieser wurde von Dürscheid (vgl. 2005, 7–8) adaptiert und um das Kriterium der räumlichen Dimension ergänzt. Hieraus ergeben sich die folgenden sechs Merkmale zur Bestimmung und Unterscheidung von Kommunikationsformen (ebd.):
- Zeichentyp
- Kommunikationsrichtung
- Anzahl der Kommunikationspartner
- räumliche Dimension
- zeitliche Dimension
- Kommunikationsmedium
Der verwendete Zeichentyp ist ein grundlegendes Merkmal, bei dem zum einen zwischen non-sprachlichen und sprachlichen Zeichen unterschieden wird (siehe auch Kapitel ). Zum anderen kann innerhalb von sprachlichen Zeichen zwischen Laut- oder Schriftzeichen, also zwischen geschriebener und gesprochener Sprache differenziert werden (oder zwischen „Sprech-/ Schriftsprache“ (Androutsopoulos & Schmidt 2001, 5)).65 Die Kommunikationsrichtung gibt Aufschluss darüber, ob die Kommunikation einseitig, also monologisch, oder wechselseitig, also dialogisch verläuft. Ein weiteres Merkmal ist die Anzahl der Kommunikationspartner. Diese kann variieren: Von einer überschaubaren Anzahl an Sendern und/oder Empfängern (beispielsweise in einem persönlichen Gespräch) bis hin zu einer unüberschaubaren und schwer eingrenzbaren Menge. Unter dem Kriterium der räumlichen Dimension stellt sich die Frage, ob die Kommunikationspartner ko-präsent sind, die Kommunikation also face-to-face stattfindet. Bei der zeitlichen Dimension hingegen wird unterschieden, ob Beiträge synchron, also zeitgleich, stattfinden oder asynchron, zeitversetzt, aufeinander folgen (vgl. Dürscheid 2005, 7). Das letzte Merkmal bezieht sich bei Dürscheid auf das verwendete Kommunikationsmedium (im Sinne eines technischen Mediums) und unterscheidet sich somit von dem bei anderen Autoren angeführten Merkmal der Medienkapazität, der „Kapazität des Mediums zur Speicherung bzw. Übertragung von Daten“ (Androutsopoulos & Schmidt 2001, 5). Allerdings ist eine rein quantitative Betrachtung wenig sinnvoll, denn es spielen auch andere Medientypen eine wichtige Rolle bei der Unterscheidung von Kommunikationsformen. Bei Holly (2011, 153) erfolgt dementsprechend eine differenzierte Betrachtung der für die Kommunikation relevanten Speicher-, Übertragungs- und Produktionsmedien.
Wenn sich diese Kriterien standardisiert und etabliert haben, das heißt in einer Sprechergemeinschaft konventionalisiert verwendet werden, kann von Kommunikationsformen gesprochen werden. In Ziegler (2002) wird so überzeugend gezeigt, dass es sich bei der E-Mail um eine Kommunikationsform handelt und in Dürscheid (2005) gelingt dies für die Chat-Kommunikation.
| Chat (Dürscheid 2005, 8) | E-Mail (Ziegler 2002, 25) |
| Zeichentyp: geschriebene Sprache | Zeichentypus: schriftbasiert |
| Kommunikationsrichtung: dialogisch | Kommunikationsrichtung: potentiell monologisch als auch dialogisch |
| Anzahl der Kommunikationspartner: variabel | Anzahl der Kommunikationspartner: zwei oder mehreren Personen |
|
räumliche Dimension: Distanz zeitliche Dimension: quasi-synchron |
Zeitlichkeit: asynchron |
| Kommunikationsmedium: Computer | Medientypus: tertiäres Medium66 |
| Medienkapazität: prinzipiell als äußerst groß einzustufen |
Bei einem Vergleich zeigt sich, dass bei Ziegler die räumliche Dimension keine Beachtung findet. Außerdem werden die Merkmale, die das Medium betreffen, nicht zur Genüge berücksichtigt. Zwar bestimmt der Autor den Medientypus und die Speicherkapazität, allerdings werden andere Aspekte des digitalen Medienkomplexes nicht betrachtet. Auch bei Dürscheid erfolgt die Zuordnung des Kommunikationsmediums, aber es fehlt eine Ausdifferenzierung der einzelnen Komponenten des digitalen Medienkomplexes. So spielen bei einer E-Mail Produktionsmedien wie die Tastatur und der E-Mail Provider eine Rolle. Es wird jedoch ein Distributionsmedium, wie das Internet benötigt. Des Weiteren verlangt es nach Präsentationsmedien, wie dem Bildschirm und einem E-Mail Provider, der gleichzeitig in Verbindung mit entsprechender Hardware als Speichermedium fungiert. Über all dem steht schließlich der digitale Code. Weitere hier verwendete Konzepte wie Synchronität und Zeichentyp sind diskutabel (siehe Kapitel und Kapitel ). Schließlich variieren die Kommunikationsrichtung sowie die Anzahl der Kommunikationspartner; diese unterschiedlichen Konstellationen bestimmen allerdings eher die Kommunikationsgattung als die Kommunikationsform.
Es lässt sich abschließend festhalten, dass alle diese Kriterien zwar einen mehr oder weniger großen Beitrag bei der Herausbildung einer Kommunikationsform spielen, jedoch tragen die verschiedenen Medien und deren Rahmenbedingungen am maßgeblichsten dazu bei. So kann folglich festgestellt werden, dass der in der CMC verwendete digitale Medienkomplex zur Herausbildung konventionalisierter Kommunikationsformen führt. Eine klare Abgrenzung der unterschiedlichen Kommunikationsformen ist aber nicht immer möglich, es kommt auch hier zu Vermischungen. Diese Medienkonvergenz, bei der verschiedene Formen der Kommunikation gemischt werden, bezeichnet Herring (2013, 5) als „convergent media computer-mediated communication (CMCMC)“ und nennt dafür als Beispiel die Vermischung verschiedener textbasierter Kommunikationsformen, wie die Statusmitteilungen und Kommentare bei Facebook. Dieses Phänomen spricht sie aber auch anderen Seiten und Anwendungen des Web 2.0 zu.
2.3.3.3. Die Merkmale der Kommunikationsform Facebook Statusmeldungen
Unter der Verwendung des Kriterienkatalogs von Androutsopoulos & Schmidt (2001) mit den Adaptionen von Dürscheid (2005) lassen sich für die Facebook Statusmeldung folgende Kriterien bestimmen: Bei dem Zeichentyp handelt es sich um geschriebene, getippte Sprache, der die von der Tastatur und dem digitalen Medienkomplex zur Verfügung gestellten Zeichen zugrunde liegen. Allerdings können para- und nichtsprachliche Zeichen verwendet werden, wie z.B. Emoticons. Bilder und Links können ebenso die Statusmeldung ergänzen. Während der Chat ein gutes Beispiel für eine dialogische Kommunikationsrichtung darstellt, ist dies bei den Statusmeldungen nicht so eindeutig. Diese mögen zwar monologisch ausgelegt sein, trotzdem kann darauf mit Kommentaren geantwortet werden und sich so ein Dialog ergeben. Ob dies der Fall ist oder nicht, kann der Produzent nur schlecht beeinflussen, auch wenn davon ausgegangen werden kann, dass viele der Statusmeldungen eine Reaktion bei den Rezipienten auslösen sollen (und sei es nur eine Bewertung mittels der Markierung „gefällt mir“). Ebenso lässt sich die Anzahl der Kommunikationspartnern bei den Facebook Statusmeldungen nur schwer einschätzen und voraussehen. Durch die Definition einer Freundesliste bewegen sich diese zwar in einem bestimmten Rahmen (der durchschnittliche Facebook Nutzer hatte im Jahr 2013 342 Freunde, siehe Kapitel , aber das Verfassen einer Statusmeldung impliziert nicht, dass alle Freunde diese auch lesen oder dass sich diese tatsächlich auch an alle Personen der Freundesliste richtet. Demzufolge ist also auch bei den Statusmeldungen die Anzahl der Kommunikationspartner variabel, bewegt sich aber im Rahmen der Anzahl an Freunden, die der Facebook Nutzer besitzt.67 Nach dem Kriterienkatalog und den hierfür verwendeten Definitionen (vgl. Dürscheid 2005, Androutsopoulos & Schmidt 2001) wären Facebook Statusmeldungen eindeutig asynchron. Allerdings ist dieses Konzept nicht immer eindeutig und bei den technischen Rahmenbedingungen redundant. So konnte schon in Kapitel gezeigt werden, dass nur von asynchron gesprochen werden kann, wenn die Kommunikationspartner offline sind. Im Umkehrschluss kann, bei gleichzeitigem online sein, aber nicht von Synchronität gesprochen werden. Facebook Statusmeldungen wären danach am ehesten quasi- oder semi-synchron.
Die Kriterien, wonach Facebook Statusmeldungen hinsichtlich ihrer Eigenschaften als Kommunikationsmedien definiert werden können, sind wie nach den eben vorgestellten Kriterien unzureichend und müssten hier erweitert werden, wie bereits in Kapitel erörtert wurde. Es lässt sich jedoch festhalten, dass die Bestimmung der Merkmale des Kriterienkatalogs ohne Problem möglich ist, woraus zu schließen ist, dass es sich bei den Facebook Statusmeldungen um eine Kommunikationsform handelt, der ein spezifisches Kommunikationsmedium zugrunde liegt. Zudem können sie als multifunktional betrachtet werden, denn die Kommunikationsform kann verschiedene kommunikative Funktionen erfüllen, beispielsweise Meinungen wiedergeben, Informationen über den emotionalen Status geben oder Diskussionen starten (siehe Kapitel ). Dies zeigt wiederum, wieso dieser Typ der CMC keine Textsorte darstellt, da diese niemals multifunktional ist, sondern eine konkrete kommunikative Funktion erfüllt (vgl. Ziegler 2002, 25).
Die Bestimmung der technisch-medialen Basis ist eindeutig das Hauptkriterium für eine Abgrenzung der verschiedenen Kommunikationsformen der CMC. Das Vorhandensein und der Einsatz eines digitalen Medienkomplexes, der auch den Prozess der Digitalisierung umfasst, ist dabei die Grundvoraussetzung, um eine Kommunikation als CMC zu bezeichnen. Die Bestimmung des Kommunikationsmediums, das nicht nur als Basis dient, sondern direkt zur Kommunikation führt – und deshalb auch für den Nutzer am offensichtlichsten ist – hilft ebenfalls als Kriterium bei der Klassifikation und Bestimmung der Kommunikationsformen innerhalb der CMC. Bei einer genaueren Betrachtung der weiteren Bestimmungskriterien fällt auf, dass es sich auf der einen Seite um kommunikative Rahmenbedingungen handelt, wie der Kommunikationsrichtung, der Anzahl der Kommunikationspartner sowie der räumlichen und zeitlichen Dimension. Auf der anderen Seite rückt der verwendete Zeichentyp in den Fokus. Die Klassifikation der CMC mittels einer adäquaten Bestimmung des Zeichentyps unter Verwendung spezifischer kommunikativer Bedingungen wurde auch für die Verortung der CMC und der dieser unterzuordnenden Kommunikationsformen im Spannungsfeld zwischen Schriftlichkeit und Mündlichkeit diskutiert, welche im nächsten Kapitel thematisiert und erörtert werden soll.
3. Merkmale und Eigenschaften der CMC
3.1. CMC im „Spannungsfeld zwischen Mündlichkeit und Schriftlichkeit“?
Bevor nun auf die linguistischen Merkmale der Facebook Beiträge eingegangen wird, soll zunächst ein weiterer Punkt vorgestellt und diskutiert werden, der eigentlich immer im Zusammenhang mit der CMC genannt wird: Die Frage danach, wie und wo sich diese Kommunikation im Spannungsfeld zwischen Mündlichkeit und Schriftlichkeit einordnen lässt.
Die meisten Autoren sind sich einig, dass bei der CMC weder von „geschriebener“ noch von „mündlicher Sprache“ im klassischen Sinne gesprochen werden kann. Einige gehen stattdessen davon aus, dass es sich bei den Formen der CMC wohl eher um Mischformen von schriftlicher und mündlicher Sprache handelt. So wird bei Hess-Lüttich beispielsweise der “Chat als Zwittermedium” (Hess-Lüttich 2002, Titelzusatz) bezeichnet und Baron (vgl. 1998, 162-165) nimmt bei den E-Mails sogar eine Kreolisierung der beiden Sprachmodalitäten an. Marx & Weidacher (2014, 125) führen dafür den Begriff der „Oraliteralität“ ein, der wie folgt definiert ist:
Hybridisierung von gesprochener und geschriebener Sprache, d.h. in manchen graphisch realisierten Texten im Internet werden Elemente konzeptioneller Mündlichkeit verwendet, unter anderem um kommunikative Nähe zu signalisieren bzw. die jeweilige Äußerung dialogischer und persönlicher wirken zu lassen.(Marx & Weidacher 2014, 125)
Oft wird auch der besondere Umstand, nämlich dass CMC über eine Tastatur geschrieben wird, hervorgehoben und es werden Begriffe wie “italiano digitato” (Gastaldi 2002, Titel) oder “getipptes Gespräch” (Storrer 2000, Titel) verwendet. Bei Letzterem wird auch schon die Tendenz vieler Autoren erkennbar, CMC eher als „gesprochene“ Sprache anzusehen, was beispielsweise für die CMC in Chats zur Folge hat, dass Bezeichnungen, wie “visibile parlare” (Pistolesi 1997, Titel) oder “schriftlich kodifizierter Modus des Sprechens” (Runkehl & Schlobinski & Siever 1998, 100), verwendet werden. Allerdings sind diese Sonderstellungen diskutabel; Hennig (2001, 235) widerspricht einer Verortung der CMC im Allgemeinen und des Chats im Besonderen, da sie es „für wenig sinnvoll halte, dem Phänomen des Chats mittels einer Etikettierung, wie ‚mündliche Schriftlichkeit‘ und ‚schriftliche Mündlichkeit‘ beizukommen“.
Im Folgenden soll vor allem ein Konzept mit den entsprechenden Unterscheidungskriterien zwischen Mündlichkeit und Schriftlichkeit vorgestellt werden, dass sich, von der deutschsprachigen Romanistik ausgehend, in der Linguistik etabliert hat. Dieses von Peter Koch und Wulf Oesterreicher (vgl. 1985) vorgeschlagene Modell der Nähe- und Distanzsprache wurde nämlich mit dem Aufkommen der neuen Technologien einfach auf die CMC übertragen (vgl. Koch & Oesterreicher 2011). Dort aber stößt es an seine Grenzen und viele der zuvor schon deklarierten Kritikpunkte an diesem Modell gewinnen in diesem Kontext noch mehr an Relevanz. Im Folgenden soll dieses Modell im Hinblick auf die CMC diskutiert werden. Dabei soll gezeigt werden, dass eine Einordnung nicht immer möglich und an vielen Stellen auch nicht unbedingt sinnvoll ist.
3.1.1. Kommunikationsformen auf dem Vierfelderschema
3.1.1.1. Das Vierfelderschema nach Koch & Oesterreicher
Die Verwendung der Oppositionen Mündlichkeit und Schriftlichkeit sowie gesprochene und geschriebene Sprache, führten oft zu terminologischen Schwierigkeiten bei der Beschreibung der konkreten sprachlichen Realisierungen (Laute des Gesprochenen vs. geschriebene Texte). So klingen wissenschaftliche Vorträge oder die im Fernsehen gesprochenen Nachrichten häufig wie vorgelesene, zuvor schriftlich fixierte Texte, während ein Notizzettel oder eine Whatsapp-Nachricht manchmal eher nach einer verschriftlichten mündlichen Äußerung klingen. Diesen auffälligen Widersprüchlichkeiten soll die auf Ludwig Söll (1985, 17-25) zurückgehende Differenzierung zwischen Konzeption und Medium entgegenwirken, mit dem Ziel, terminologische Unklarheiten zu beseitigen. Konzeption betrifft den sprachlichen Duktus von Äußerungen (gesprochen und geschrieben sprachlich), also die Ausdrucksweise, die in Äußerungen gewählt wird, während unter Medium die Realisationsform der Äußerungen als entweder phonischer oder graphischer Kode gemeint ist (vgl. Koch & Oesterreicher 2011, 3).68 Daraus ergibt sich ein sogenanntes ‚Vierfelderschema‘ (Koch & Oesterreicher 2011, 3), das verschiedene Kombinationen ermöglicht:

Das Vierfelderschema nach Koch & Oesterreicher (2011, 3).
(Lizenz: CC BY SA)
Während es eine strikte Trennung auf der medialen Seite gibt, also der verwendete Kode sich entweder ausschließlich dem Graphischen oder dem Phonischen zuordnen lässt, ist das Verhältnis auf konzeptioneller Seite eher als Kontinuum zu betrachten (dies wird in Abbildung 10 mit einer gestrichelten Linie dargestellt). An den vier Extrempunkten dieses Schemas lassen sich als konzeptionell gesprochen sowie medial phonisch beispielsweise Unterhaltungen zwischen Freunden einordnen. Konzeptionell geschrieben sowie medial graphisch wären Zeitungsartikel oder wissenschaftliche Aufsätze. Ein Beispiel für eine konzeptionell geschriebene, aber medial phonische Äußerung wäre hingegen ein wissenschaftlicher Vortrag oder eine Nachrichtensendung im Fernsehen und als medial graphisch und konzeptionell gesprochen, ließen sich verschriftlichte Interviews oder Transkriptionen von Gesprächen anführen. Es sei außerdem noch darauf hingewiesen, „dass alle Äußerungsformen, gleich welcher Konzeption, aus der für sie typischen medialen Realisierung in das jeweils andere Medium ‚transferiert‘ werden können“ (Koch & Oesterreicher 2011, 4): Ein Zeitungsartikel kann demnach auch vorgelesen oder eine persönliche Unterhaltung auch verschriftlicht werden.
3.1.1.2. CMC im Vierfelderschema?
Die CMC kann nach einer Betrachtung des Vierfelderschemas als medial graphisch und konzeptionell gesprochen angesehen werden. Als Beispiele werden hier Äußerungen in Chats (Koch & Oesterreicher 2011, 4), aber auch E-Mails (Kilian 2001, 60) genannt, wie Abbildung 11 zeigt.

Kilians (2001, 60) Adaption des ‚Vierfelderschemas‘ nach Koch & Oesterreicher (1985).
(Lizenz: CC BY SA)
So kann nach Koch & Oesterreicher die durch neue technologische Entwicklungen entstandene CMC ihren Platz in diesem Schema finden:
Man könnte nun auf den Gedanken kommen, dass das Schema in Abb. 5 [das Nähe-/Distanzkontinuum], das allein die Medien Phonie und Graphie berücksichtigt, nicht ausreicht, die Komplexität dieser neuesten medialen Entwicklungen zu erfassen. Einer solchen Einschätzung ist jedoch entschieden zu widersprechen. Es muss nämlich klar getrennt werden zwischen ‘Medien’ als physikalischen Manifestationen, die bestimmte sensorische Modalitäten ansprechen (Phonie -> akustisch, Graphie -> visuell), und ‘technischen’ Speicher- und Übertragungsmedien, wie Telephon, Internet etc. […]. (Koch & Oesterreicher 2011, 14)
Koch & Oesterreicher (vgl. 2011, 14) begründen dies mit der klaren Abgrenzung von ‚Medien‘ als Repräsentationsformen sprachlicher Äußerungen von den technischen Übertragungs- und Speichermedien und der Annahme, dass Letztere schlussendlich auf Prinzipien der Ersteren beruhen. Demnach folgt beispielsweise auch der Chat den visuellen Prinzipen der Graphie, egal wie innovativ das technische Medium auch sei. Hier zeigt sich schon einer der größten Kritikpunkte dieses Modells, denn der Medienbegriff nach Koch & Oesterreicher ist alles andere als eindeutig und berücksichtigt nicht zur Genüge die medialen Möglichkeiten der CMC als technisches Speicher- und Übertragungsmedium (vgl. Krefeld 2015, 265). Androutsopoulos (2007, 80) kritisiert ebenfalls diese „Medienvergessenheit“.69 Und auch nach Dürscheid (2003, 3) ist der Begriff des „Mediums“ zu weit gefasst, denn „die Face-to-Face-Kommunikation wäre dann eine Form der Medienkommunikation; sie vollzieht sich – im Sinne von Koch & Oesterreicher – im Medium der gesprochenen Sprache.“ Die Autorin plädiert deshalb für die Verwendung des technischen Medienbegriffs nach Holly (vgl. Holly 1997) (siehe DEFAULT) und schlägt vor, die Problematik mittels der terminologischen Differenzierung zwischen „Medium“ und „Medialität“ zu umgehen und nur den letzten Begriff in Bezug auf die sprachliche Realisierung zu verwenden (vgl. Dürscheid 2003, 3). Diese „Medialität sprachlicher Äußerungen“ legitimiere somit den Gebrauch der Termini Mündlichkeit und Schriftlichkeit (ebd.). Bei anderen Autoren ist aber weiterhin von der Ebene des „Mediums“ die Rede; so auch bei Vorschlägen einer Situierung der verschiedenen Formen der CMC.
Vor dem Hintergrund der Heterogenität der verschiedenen Typen der CMC und der Existenz von Merkmalen, die keinem der vier Bereiche des Vierfelderschemas zuzuordnen sind, schlägt Kattenbusch (2002, 192) eine Änderung des Vierfelderschemas vor. Da die von ihm in Betracht gezogene CMC nicht akustisch abläuft, kann der phonische durch den sogenannten ‚lalischen Kode‘ ersetzt werden.70 Der lalische Kode stellt dabei „ein Hybrid zwischen graphischen und ikonographischen Kode (unter Verwendung von Emoticons, nicht allgemein üblichen Akronymen etc. zur Wiedergabe parasprachlicher und non-sprachlicher Kommunikationselemente)“ (Kattenbusch 2002, 192) dar.
Verortung der CMC zwischen Mündlichkeit und Schriftlichkeit nach Kattenbusch (2002, 192).
(Lizenz: CC BY SA)
Aber auch dieses Modell weist Kritikpunkte auf. Zum einen beschränkt es sich nur auf schriftlich basierte CMC und gesprochene Face-to-Face-Kommunikation. Gesprochene Formen der CMC, wie die Internet-Telefonie, werden nicht berücksichtigt. Die Berücksichtigung des Mediums und der sprachlichen Eigenheiten, die sich bei der Verwendung ergeben, ist zwar positiv hervorzuheben, allerdings stellt sich die Frage, ob eine strikte Trennung zu anderen nicht computervermittelten Kommunikationsformen sinnvoll ist. So lassen sich für die CMC typische Merkmale, wie die Verwendung von Emoticons oder Abkürzungen, auch in anderen Formen der Kommunikation finden (beispielsweise das Smiley auf einem Notizzettel an den Mitbewohner oder ein ausgesprochenes LOL in der Konversation zwischen Jugendlichen in der U-Bahn). Es wird außerdem impliziert, dass sich online Zeitungsartikel und sonstige Formen der online Kommunikation, zu denen auch Veröffentlichungen von wissenschaftlichen Artikeln zählen, von anderen Kommunikationsformen, die offline produziert werden, unterscheiden. Das mag eventuell bei extra für den Internetauftritt einer Zeitung geschriebenen Zeitungsartikeln der Fall sein, ist aber bei beispielsweise wissenschaftlichen Artikeln, die oft erst im Nachhinein online hochgeladen werden, nicht der Fall.
Zusammenfassend lässt sich sagen, dass eine Verortung der CMC auf dem Vierfelderschema problematisch ist. Kattenbuschs Ersetzung des phonischen durch den lalischen Kode ist ebenfalls fragwürdig und macht einen Vergleich von computervermittelten und nicht computervermittelten Kommunikationsformen unmöglich. Allerdings entwickeln Koch & Oesterreicher dieses Modell weiter, weshalb im Folgenden geprüft und diskutiert wird, ob sich die CMC auf dem sogenannten Nähe-/Distanzkontinuum verorten lässt. Zuvor werden die zugrundeliegenden Ideen und Konzepte vorgestellt sowie einige allgemeine Kritikpunkte daran präsentiert, bevor dann eine mögliche Situierung der CMC im Allgemeinen und der Facebook Beiträge im Besonderen diskutiert wird.
3.1.2. Kommunikationsformen auf dem Nähe-/Distanzkontinuum
3.1.2.1. Das Nähe-/Distanzkontinuum nach Koch & Oesterreicher
Während in dem zuvor vorgestellten Vierfelderschema nach Koch & Oesterreicher auf der medialen Seite eine eindeutige Zuordnung möglich ist (ein Kode ist entweder graphisch oder phonisch), gehen Koch & Oesterreicher (2011, 4) bei der konzeptionellen Seite davon aus, dass „das Verhältnis von ‚gesprochen‘ und ‚geschrieben‘ nur als Kontinuum zwischen zwei extremen Ausprägungen der Konzeption begriffen werden kann.“. Ausgehend von Coserius (vgl. 1980) drei Ebenen der Struktur der Sprache entwickeln sie diesen konzeptionellen Aspekt weiter.71 Das Ergebnis ist ein Modell, das universale Charakteristika von Mündlichkeit und Schriftlichkeit, die die Grundlage für die Präsentation und Diskussion einzelsprachlicher Merkmale historischer Sprachen darstellen, berücksichtigt.72 Das Modell stellt ein Kontinuum dar, an dessen Polen die konzeptionell gesprochene Sprache, die Sprache der Nähe, und die konzeptionell geschriebene Sprache, die Sprache der Distanz, verortet werden (vgl. Koch & Oesterreicher 2011, 13). Zur Verortung sprachlicher Äußerungen werden eine Reihe von Parametern auf der Skala zugrunde gelegt: verschiedene außersprachliche Kommunikationsbedingungen und die entsprechenden Versprachlichungsstrategien (ebd).
Unter Kommunikationsbedingungen werden außersprachliche kommunikative Parameter verstanden, welche die sprachlichen Produktionen erfüllen. Die Kommunikationsbedingungen sind (bis auf 6. in Tabelle 9) als graduell zu verstehen und können nach Koch & Oesterreicher (vgl. 2011, 13) wie folgt dargestellt werden:73
| Sprache der Nähe | Sprache der Distanz | |
| 1. | Privatheit | Öffentlichkeit |
| 2. | Vertrautheit | Fremdheit |
| 3. | Emotionalität | keine Emotionalität |
| 4. | Situations- und Handlungseinbindung | Situations- und Handlungsentbindung |
| 5. | Referenzbezug stark abhängig von der Sprecher-origo | Referenzbezug maximal unabhängig von der Sprecher-origo |
| 6. | physische Nähe | physische Distanz |
| 7. | intensive Kooperation | keine Kooperation |
| 8. | Dialogizität | Monologizität |
| 9. | Spontaneität | Reflektiertheit |
| 10. | freie Themenentwicklung | starke Themenfixierung |
| etc. | etc. |
Während die außersprachlichen Kommunikationsbedingungen die Konzeption von Kommunikationsakten steuern, sind die Versprachlichungsstrategien für die Konzeption der Kommunikationsakte verantwortlich (vgl. Koch & Oesterreicher 2011, 11). Auch wenn man dem Namen nach vermuten könnte, es handle sich hier um rein sprachliche Strategien, dürfen jedoch die nichtsprachlichen Kontexte nicht außer Acht gelassen werden. Bei den Versprachlichungsstrategien der Nähe, dem Nähesprechen, und der Distanz, dem Distanzsprechen, sind folgende Arten von Kontexten zu unterscheiden (vgl. Koch & Oesterreicher 2011, 11):
- der situative Kontext
- der individuelle (auf gemeinsamen Erlebnissen und Erfahrungen der Gesprächspartner basierende) und allgemeine (auf sozio-kulturellen und universalen menschlichen basierende) Wissenskontext
- der sprachlich-kommunikative Kontext bzw. Kotext
- und andere parasprachlich-kommunikative Kontexte (z.B. Sprechgeschwindigkeit, Lautstärke und andere intonatorische Phänomene) sowie nichtsprachlich-kommunikative Kontexte (z.B. Mimik, Gestik, Körperhaltung, etc.).
Beim Nähesprechen können eigentlich alle genannten Kontextarten zum Einsatz kommen. Bei einem vertrauten Gespräch werden beispielsweise im Rahmen der Kommunikationssituation die beteiligten Personen, Gegenstände und Sachverhalte wahrgenommen, der Wissensstand der Rezipienten ist zumeist bekannt und kann beachtet werden. Ebenso können para- und nichtsprachliche Kontexte erkannt (der Rezipient kann zum Beispiel an dem Gesichtsausdruck die Stimmung des Produzenten ablesen). Der Kotext spielt zwar auch beim Nähesprechen eine Rolle, kann aber bei sehr großer Nähe in den Hintergrund treten; so kann eine vertraute Person, Wünsche seines Gegenübers auch „von den Augen ablesen“. Beim Distanzsprechen hingegen ist „tendenziell mit Einschränkungen zu rechnen“ (Koch & Oesterreicher 2011, 11). Wenn beispielsweise eine Situations- und Handlungsentbindung oder eine physische Distanz der Gesprächspartner vorliegt, gibt es keinen gemeinsamen Kommunikationsraum und so sind weder ein situativer noch ein para- oder nichtsprachlicher Kommunikationsraum gegeben. Wenn außerdem eine Fremdheit der Kommunikationspartner vorliegt, kann es keinen individuellen, auf gemeinsamen Erlebnissen beruhenden Wissenskontext geben. Das Fehlen dieses Kontexts wird folglich durch den Kotext kompensiert (vgl. Koch & Oesterreicher 2011, 11).
| Sprache der Nähe | Sprache der Distanz | |
| 1. | Präferenz für nichtsprachliche Kontexte und für Gestik, Mimik etc. | Präferenz für sprachliche Kontexte |
| 2. | geringer Planungsaufwand | hoher Planungsaufwand |
| 3. | Vorläufigkeit | Endgültigkeit |
| 4. | Aggregation | Integration |
| etc. | etc. |
Das Nähesprechen zeichnet sich, in Relation zu den Kommunikationsbedingungen und Kontexttypen, durch einen geringen Planungsaufwand beim Formulieren von Äußerungen aus und kann somit als weniger elaboriert betrachtet werden. Außerdem kann bei den Äußerungen der Nähesprache von Vorläufigkeit ausgegangen werden, die außerdem durch eine aggregative Gestaltung gekennzeichnet sind. Nähesprachliche Diskurse werden somit spontaner gestaltet, weisen unvollständige Äußerungen und Abbrüche auf und verfügen damit über eine geringe Informationsdichte (vgl. Koch & Oesterreicher 2011, 11). Das Distanzsprechen hingegen zeichnet sich durch einen höheren Planungsaufwand aus. Die Äußerungen sind geprägt von einer Endgültigkeit und der Integration sprachlicher Einheiten. Damit ist die Informationsdichte sehr hoch, die Äußerungen sind meist komplexer und der Informationsfortschritt schreitet schnell voran (ebd.). In Koch & Oesterreicher (1985, 23) werden zudem auf der Seite der Sprache der Nähe noch das Merkmal der Prozeßhaftigkeit sowie eine geringere Informationsdichte, Kompaktheit, Komplexität und Elaboriertheit genannt – auf der Seite der Sprache der Distanz die entsprechenden Gegenpole.
Je nach dem Grad der Erfüllung dieser Kommunikationsbedingungen und Versprachlichungsstrategien können verschiedene Kommunikationsformen auf dem Kontinuum zwischen Sprache der Nähe und Sprache der Distanz verortet werden. Dafür verwenden Koch & Oesterreicher (vgl. 2011, 8) sogenannte konzeptionelle Reliefs, auf denen für jeden Parameter einer Kommunikationsform festgelegt wird, wo diese auf der jeweiligen Skala zu verorten sei. Das konzeptionelle Relief eines Privatbriefes sieht danach beispielweises folgendermaßen aus:
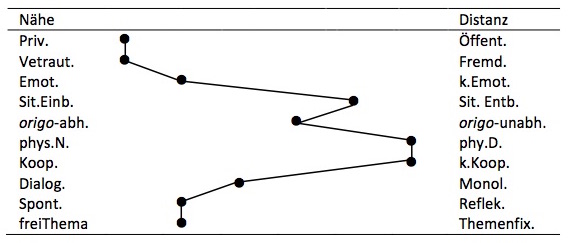
Das konzeptionelle Relief eines Privatbriefes nach Koch & Oesterreicher (2011, 8)74
(Lizenz: CC BY SA)
Daraus ergibt sich dann die Situierung der jeweiligen Kommunikationsformen auf dem Nähe-/Distanzkontinuum. Eine mögliche Einordnung der CMC sei hier auch schon vorweg genommen (diese soll jedoch in Kapitel noch ausführlicher diskutiert werden):
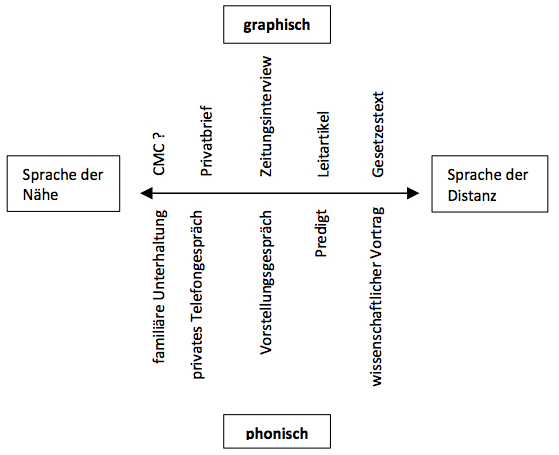
Verschiedene Kommunikationsformen auf dem Nähe/Distanzkontinuum nach Koch & Oesterreicher (2011, 12-13) dargestellt mit dem Vorschlag einer möglichen Situierung der CMC.
(Lizenz: CC BY SA)
Das von Koch & Oesterreicher vorgeschlagene Modell wurde trotz seiner großen Verbreitung auch stark kritisiert, nicht nur hinsichtlich der zugrundeliegenden Theorien, sondern auch wegen der Schwierigkeiten bei dessen Anwendung. Hier sollen zunächst allgemeine Kritikpunkte vorgestellt und diskutiert werden. Bei einer darauf folgenden Betrachtung wird dann gezeigt, ob und wie dieses Modell hinsichtlich der CMC Verwendung finden kann und wie es sich hierbei mit den Kritikpunkten verhält.75
Zuerst seien terminologische Schwierigkeiten genannt, denn das Nähe-/Distanz-Kontinuum wird in der Literatur häufig mit geschriebener bzw. gesprochener Sprache gleichgesetzt (vgl. Berruto 2005, 141). Dabei bezieht sich die gesprochene Sprache aber „nur auf die phonische Seite der Sprache, auf die Lautung“ (Dürscheid 2011, 179), respektive die geschrieben Sprache auf die graphisch-visuelle Realisierung. Mündlichkeit und Schriftlichkeit können hingegen eher mit der Sprache der Nähe und der Sprache der Distanz gleichgesetzt werden. So heißt es bei Dürscheid (2011, 179) zum Thema Mündlichkeit:
Hier unterscheidet man in der Linguistik zwischen konzeptioneller und medialer Mündlichkeit […]. Nur mediale Mündlichkeit bezieht sich auf die phonische Realisierung von Sprache, konzeptionelle Mündlichkeit dagegen meint die in einer Äusserung gewählte Ausdrucksweise. (Dürscheid 2011, 179)
Aber auch die Begriffe Mündlichkeit und Schriftlichkeit implizieren eine bestimmte mündliche oder schriftliche Medialität, weshalb von Koch & Oesterreicher die Begriffe der Nähe- und Distanzsprache eingeführt wurden. Nähe und Distanz können sich allerdings sowohl auf die räumliche als auch die zeitliche Entfernung beziehen, die es zu unterscheiden gilt.76
Ein anderes terminologisches Problem stellt der unklar definierte Begriff der Konzeption dar, denn zunächst wird er als „kommunikative Strategie“ (Koch & Oesterreicher 1985, 17) und später als „sprachlicher Duktus von Äußerungen“ (Koch & Oesterreicher 2011, 3) paraphrasiert (vgl. Loos 2012, 87). Neben der Vagheit des Begriffes ist dieser auch unzureichend von anderen, in der Linguistik geläufigen Konzeptionsbegriffen abgegrenzt.77
Dabei sollte man m. E. nur dann von ‚konzeptioneller Mündlichkeit’ sprechen, wenn […] ein Fall von sekundärer Kommunikation vorliegt (vorgelesene Texte oder transkribierte gesprochene Sprache) oder wenn in primärer Kommunikation die jeweils andere Kommunikationsform „nachgeahmt“ wird. (Hennig 2001, 221)
Des Weiteren führt die Autorin auch an, dass es durchaus vorkommen kann, dass in einer als konzeptionell gesprochen und medial graphisch eingestuften Kommunikationsform gar keine Merkmale des (konzeptionell) Gesprochenen vorkommen (vgl. Hennig 2001, 115-119). Der konzeptionell mündliche bzw. schriftliche Duktus kann also nicht gleichgesetzt werden mit der Sprache der Nähe und Sprache der Distanz – er ergibt sich allerhöchstens daraus.
Schließlich wird der Begriff der Kommunikationsform bei Koch & Oesterreicher nicht immer klar abgegrenzt von der kommunikativen Gattung. Zu den Kommunikationsformen zählen die Autoren beispielsweise die „familiäre Unterhaltung“ und das „private Telefongespräch“, bei denen es sich aber streng genommen eher um kommunikative Gattungen handelt, also „in der Kommunikation konstruierte […] Handlungsmuster, die den Beteiligten eine Orientierung geben“ (Dürscheid 2005, 9) (siehe auch DEFAULT). Auch Loos (vgl. 2012, 90) kritisiert, dass in der praktischen Anwendung anstelle von „Kommunikationsformen“ lediglich „kommunikative Gattungen“ auf dem Kontinuum situiert werden.
Die praktische Einordung dieser Kommunikationsformen auf dem nähe- und distanzsprachlichen Kontinuum führt zu weiteren Kritikpunkten. Dazu zählt auch die mangelnde Operationalisierbarkeit bei der Einordnung. So stellen Koch & Oesterreicher (vgl. 2011, 8-9) zwar mittels konzeptioneller Reliefs graphisch dar, zu welchem Grad die verschiedenen Kommunikationsformen die Kommunikationsbedingungen erfüllen (siehe auch Abbildung 13), aber wie infolgedessen die Situierung auf dem Kontinuum erfolgt, bleibt unklar. Zunächst sei bemängelt, dass nicht alle Parameter graduell sind, denn während es sich bei beispielsweise der „Vertrautheit der Kommunikationspartner“ um ein Kontinuum handelt, kann es entweder eine „physische Nähe“ oder eine „physische Distanz“ geben, also tertium non datur. Zudem werden Kommunikationsformen verortet, die wiederum verschiedenen Handlungsmustern folgen können. Ein Privatbrief kann aus verschiedenen Anlässen geschrieben werden, bei denen die emotionale Beteiligung stark variiert (Reisebericht vs. Beileidsbekundung) und weshalb die Einordnung nicht punktuell erfolgen sollte, sondern die möglichen Spannbreiten mitberücksichtigt werden soll. Die Autoren geben keinen Aufschluss darüber, wie die Positionierung auf dem Kontinuum erfolgt und wie dabei die einzelnen Parameter gewichtet werden. Da häufig die Erfüllung eines Parameters Voraussetzung für einen anderen ist, können diese kaum als gleich gewichtet betrachtet werden.
Auch in Bezug auf die einzelnen Parameter kommt es zu Schwierigkeiten, ebenso wie bei der Relation zwischen Versprachlichungsstrategien und Kommunikationsbedingungen. Viele der Versprachlichungsstrategien könnten auch den Kommunikationsbedingungen zugeordnet werden, das gilt vor allem für die Vorläufigkeit und Prozesshaftigkeit (vgl. Loos 2012, 92).78 Zudem mangelt es an vielen Stellen an logisch-heterogene Bezügen zwischen den Kommunikationsbedingungen und Versprachlichungsstrategien und auch die einzelnen Parameter selbst rücken häufig in den Fokus von Kritikern, ob ihrer Begrifflichkeit oder Anwendbarkeit bei der Situierung einzelner Kommunikationsformen auf dem Kontinuum. Diese sollen im Folgenden nur im Hinblick auf die CMC diskutiert werden.79
Trotz dieser Kritikpunkte hat sich das Nähe-/Distanzkontinuum als nützlich erwiesen, verschiedene Kommunikationsformen zu beschreiben und in Verhältnis mit anderen zu setzen. Mit der Entwicklung neuer Technologien wurde schließlich auch eine Situierung der CMC auf diesem Kontinuum diskutiert, die im Folgenden vorgestellt werden soll.
3.1.3. Verortung der CMC auf dem Nähe-/Distanzkontinuum?
3.1.3.1. Verortung von Chat und E-Mail auf dem Nähe-/Distanzkontinuum
Das Modell nach Koch & Oesterreicher kann „durchaus als gutes Raster zur Einordnung von Textsorten“ (Hennig 2000, 118) dienen und auch andere Autoren verwenden es, um die CMC auf diesem Kontinuum zu positionieren.80 So wurde beispielsweise bei Berruto (2005), ausgehend von den Kommunikationsbedingungen, eine solche Verortung diskutiert. Untersuchungsgegenstand bei Berruto (2005, 138-139) sind dabei Ausschnitte aus vertrauten, stilistisch informellen E-Mail Kommunikationen unter Freunden sowie Mitschnitte von Chat-Kommunikationen und SMS.81 Da aber SMS per se eigentlich nicht als CMC-Typ angesehen werden können, ist ein Vergleich fragwürdig, weshalb sie hier nicht weiter berücksichtigt werden.82 Kattenbusch (2002, 192) untersucht ebenso verschiedene CMC-Typen. Auch wenn bei dem Autor vor allem sprachliche Besonderheiten im Vordergrund stehen, diskutiert er die von ihm untersuchten Typen der CMC (dazu gehören E-Mails, Chat, Mailinglisten, Newsgroup und Online-Printmedien) hinsichtlich ihrer Einordnung zwischen Nähe- und Distanzsprache (vgl. Kattenbusch 2002, 185). Nun könnte angemerkt werden, dass diese Verortungen überholt sind – gerade auch weil SMS hier zumindest bei Berruto noch eine sehr wichtige Rolle spielen – allerdings basieren auch viele neuere Studien auf diesen Situierungen. Zudem sprechen einige der Autoren bei den Merkmalen der CMC von Distanz reduzierenden Charakteristika (vgl. Tavosanis 2011), weshalb diese Situierungen nach Berruto und Kattenbuch hier trotzdem kurz vorgestellt werden sollen.
Berruto (2005) erachtet die Kommunikationsbedingungen nach Koch & Oesterreicher als hilfreich, um auch CMC Typen auf dem nähe-/distanzsprachlichen Kontinuum zu verorten:
Per caratterizzare ulteriormente il nostro settore di varietà di lingua su questa dimensione fra scritto e parlato sarà invece utile riferirsi anche ai parametri in cui Koch […] e poi Koch/Oesterreicher […] articolano l’opposizione fra Sprache der Nähe (tipicamente, il parlato) e Sprache der Distanz (tipicamente, lo scritto) in termini delle condizioni di comunicazione e della codificazione verbale. (Berruto 2005, 141) [Hervorhebungen im Original].
Kattenbusch (vgl. 2002, 186) merkt in seiner Diskussion zur Situierung verschiedener CMC-Typen an, dass je nach Beziehung zwischen Sender und Empfänger sowie in Abhängigkeit der kommunikativen Situation, die Kommunikationsformen der CMC auf verschiedenen, sich erheblich voneinander unterscheidenden Positionen „zwischen konzeptionell schriftlich und konzeptionell mündlich (verschriftete Mündlichkeit)“ verortet werden kann. Der Autor situiert die CMC schließlich, exemplarisch am Chat aufgezeigt, anhand der Kommunikationsbedinungen und Versprachlichungsstrategien auf dem Nähe-/Distanzkontinuum (vgl. Kattenbusch 2002, 193-194).83
In konzeptionellen Reliefs, wie sie auch bei Koch & Oesterreicher (vgl. 2011, 8-9) verwendet werden, lassen sich die Verortungen gut darstellen und zusammenfassen (wie in Abbildung 13). Die beschriebene Einordnung von E-Mail und Chat nach Berruto (vgl. 2005, 141-142) wird punktuell auf dem Relief vorgenommen (in Abbildung 15 und Abbildung 16 mit Hilfe von Punkten und Verbindungslinien dargestellt), die Verteilung der erfüllten Parameter des Chats nach Kattenbusch (vgl. 2002, 194) erfolgt hingegen mittels Zuweisung der möglichen Spannbreiten je nach Erfüllung einzelner Parameter (in Abbildung 16 mit Hilfe von grauen Balken dargestellt).84
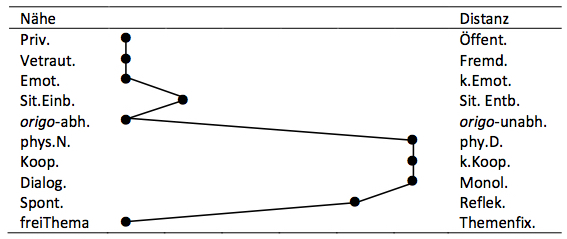
Konzeptionelles Relief der E-Mail nach Berruto (vgl. 2005, 141-142).
(Lizenz: CC BY SA)
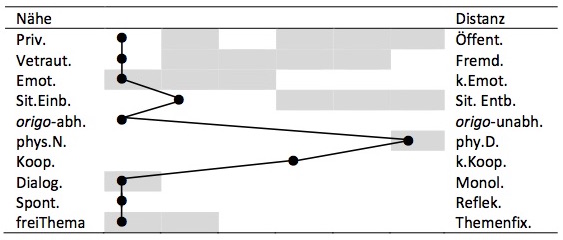
Konzeptionelles Relief des Chats nach Berruto (vgl. 2005, 141-142) und Kattenbusch (vgl. 2002, 194).
(Lizenz: CC BY SA)
Bei beiden konzeptionellen Reliefs nach Berruto wird deutlich, dass sich die Kommunikationsformen hinsichtlich der Mehrheit der Parameter näher an der Sprache der Nähe befinden (siehe Abbildung 15 und Abbildung 16). Der Parameter physische Distanz ist bei der Chat-Kommunikation der einzige Ausreißer, der mit der Sprache der Distanz korreliert. Bei der E-Mail-Kommunikation kommen noch der geringe Grad der Kooperation und das damit verbundene Merkmal der Dialogizität hinzu, die eher der Sprache der Distanz zuzuordnen wären. Auch der Grad der Reflektiertheit entspricht bei der E-Mail Kommunikation weder dem Extrempol der Sprache der Nähe noch dem der Distanz.
Bei Berruto werden allerdings nur Kommunikationsformen in bestimmten situativen Kontexten berücksichtigt, nämlich solche, die einem freundschaftlichen, privaten Austausch aus dem Freizeitbereich darstellen. Es handelt sich also eher um kommunikative Gattungen als um Kommunikationsformen (siehe dazu DEFAULT). Kattenbuschs (vgl. 2002, 193-194) Situierung unterscheidet sich gerade hierbei von Berrutos, da er den Chat weiter definiert und auch öffentliche Multi-User Chats (d.h. Chats mit mehreren Kommunikationsteilnehmern) in seine Beobachtungen mit einschließt. Das zeigt sich bei der Verortung hinsichtlich des Grades der Öffentlichkeit und der Vertrautheit, die sich hier im ganzen Mittelfeld bis hin zum Extrempol der Distanzsprache bewegen können. Außerdem wird eher vor einer Situations- und Handlungsentbindung ausgegangen, da es sich bei einem Chat aus der Sicht des Autors um „zwangloses, inhaltlich meist an der Oberfläche bleibendes Geplauder“ (Kattenbusch 2002, 197) handelt. Der Inhalt dieser Kommunikationen sei dabei „eher anspruchslos“, was schon die Bezeichnung Chat, zu Deutsch ‚Geplauder‘, andeuten (Kattenbusch 2002, 187-188).
Während Berruto die Versprachlichungsstrategien bei seiner Einordnung der CMC auf dem Nähe-/Distanzkontinuum gar nicht berücksichtigt, ergibt sich hier nach Kattenbusch (vgl. 2002, 194) ein homogenes Bild, denn bei allen Formen des Chats lässt sich eine Präferenz für nichtsprachliche Kontexte, ein geringer Planungsaufwand, Vorläufigkeit und Aggregation erkennen, was nach Meinung des Autors der Sprache der Nähe entspricht. Bei den E-Mails ist jedoch von einem größeren Planungsaufwand auszugehen – normalerweise wird eine Struktur mit Anrede, Gruß und ein Betreff verwendet – und auch der Grad der Informationsdichte, Komplexität und Elaboriertheit ist in vielen Fällen sicher größer. Ebenso ist die Präferenz für nichtsprachliche Kontexte fragwürdig.
Bei dem Vergleich dieser beiden Typen der CMC wird schon deutlich, dass es keine einheitliche Einordnung auf dem Nähe-/Distanzkontinuum geben kann. Nicht nur, dass sich die Kommunikationsformen stark voneinander unterscheiden, auch innerhalb einzelner Kommunikationsformen, wie dem Chat, kommt es zu Unterschieden. Ebenso verhält es sich mit den Facebook Statusmeldungen und Posts, wie der folgende Abschnitt zeigt
3.1.3.2. Verortung der Facebook Statusmeldungen
Für die Kommunikationsform der Facebook Beiträge kann ebenso wie für die anderen CMC-Typen (siehe oben) eine Verortung auf einem konzeptionellen Relief mit punktueller Situierung vorgenommen werden (vgl. Franko 2015, 65-67). Allerdings eignet sich auch hier eine Darstellungsform besser, die eine größere Bandbreite an Variation bei der Erfüllung verschiedener Merkmale berücksichtigt (durch Balken dargestellt wie bei Kattenbusch (siehe Abbildung 16)):
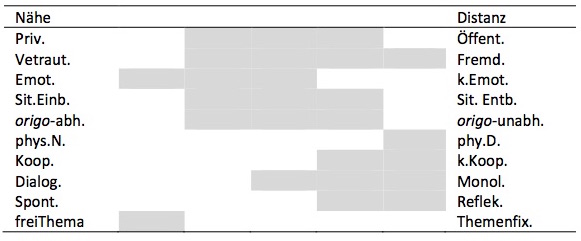
Konzeptionelles Relief der Facebook Statusmeldung.
(Lizenz: CC BY SA)
Der Grad der Öffentlichkeit kann bei den Facebook Beiträgen irgendwo zwischen den Extrempolen Öffentlichkeit und Privatheit angesiedelt werden. Zwar wurden für das gesamte Internet zugängliche Meldungen bei der Untersuchung ausgeklammert, trotzdem können alle Personen, mit denen der Verfasser befreundet ist, die Äußerungen lesen. Sie sind also in dem Sinne privat, dass der Verfasser die Rezipienten (zumindest online) kennt oder eine Verbindung zu ihnen hat. Bei diesem Parameter spielt aber auch die Größe des Publikums eine Rolle und richtet sich nach der Anzahl der Facebook Freunde, die durchaus sehr groß sein kann (im Jahr 2013 hatte nach Wolfram (2013) jeder Facebook Nutzer durchschnittlich 342 Freunde, siehe Kapitel ). Ein weiterer wichtiger Aspekt hierbei ist, dass alle Personen aus der Freundesliste die Statusmeldungen zwar theoretisch lesen können, dies aber nicht tun müssen und wenn sie es tun, nicht immer darauf reagieren. Hier gilt außerdem zwischen Statusmeldungen und Posts zu unterscheiden, denn Erstere sind meist an alle Facebook Freunde gerichtet, während Letztere meist speziell den Nutzer ansprechen, auf dessen Chronik sie gepostet wurden. Der Grad der Vertrautheit der Kommunikationspartner kann als sehr hoch oder aber auch als gar nicht vorhanden eingestuft werden, da die Art der Freundschaften, die auf SNS geknüpft werden, nicht zwangsläufig zu einer Vertrautheit führen oder diese voraussetzen. Was die Emotionalität betrifft, kann man davon ausgehen, dass diese recht hoch ist, was sich auf die Gründe des Nutzers, einen Facebook Beitrag zu verfassen, zurückzuführen ist (dazu zählt beispielsweise die Selbstdarstellung oder das Teilen von Informationen über das eigene emotionale Empfinden, siehe Kapitel ). Die Situations- und Handlungseinbindung sowie der Referenzbezug bei den Facebook Beiträgen unterscheiden sich dahingehend von E-Mails und Chat, dass die Äußerungen nicht immer an Situationen oder Handlungen gebunden sind sowie der Referenzbezug nicht abhängig von der Sprecher-origo sein muss. Wie bei allen Typen der CMC ist zudem auch bei den Facebook Statusmeldungen keine physische Nähe der Kommunikationspartner gegeben. Von Kooperation und Dialogizität kann nur dann ausgegangen werden, wenn die Facebook Freunde die Kommentarfunktion nutzen. Auch wenn von den Produzenten einer Äußerung häufig ein Dialog angestrebt wird, entsteht dieser nur durch die Kooperationsbereitschaft der Facebook Freunde. Es kann bei dieser Kommunikationsform, wie bei den E-Mails, davon ausgegangen werden, dass die Facebook Beiträge nicht spontan verfasst werden. Der Produzent verfolgt die Absicht, sich zu präsentieren, so wie er gerne wahrgenommen werden möchte, und tut dies meist bewusst und mit Bedacht. Schließlich kann zwischen dem Prozess des Schreibens und dem Veröffentlichen einer Statusmeldung der geschriebene Text nochmals gelesen, modifiziert und auch ausgebessert werden, weshalb der Grad der Reflektiertheit als hoch eingestuft wird.
Was die Versprachlichungsstrategien anbelangt entsprechen die Facebook Statusmeldungen aufgrund des hohen Planungsaufwand, und der Endgültigkeit (einmal geschrieben und veröffentlicht, verbleiben die Statusmeldungen auf der Facebook Chronik) eher der Verortung der E-Mails. Allerdings zeigt sich auch hier eine starke Präferenz für nichtsprachliche und parasprachliche Kommunikation in Form von Emoticons, Phoneticons oder Bildern, was eher beim Chat als bei den E-Mails der Fall ist und welche in Kapitel ausführlicher betrachtet und diskutiert werden sollen.
Problematik bei der Verortung der CMC
Auch wenn in den Abschnitten zuvor eine Bestimmung der Kommunikationsbedingungen verschiedener CMC Formen erfolgte, führt der Versuch, die CMC auf dem Nähe-/Distanzkontinuum zu verorten, zu einigen Problemen.Die allgemeinen Kritikpunkte zusammenfassend wurde in Kapitel gezeigt, dass das Modell des Nähe-/Distanzkontinuums, wie auch die als Basis verwendete Trennung zwischen Konzeption und Medium, Mängel aufweisen. Es wurden zum einen terminologische Probleme hinsichtlich der Begriffe der Konzeption und Kommunikationsform aufgeführt und zum anderen gezeigt, dass auch die Differenzierung der einzelnen Parameter und die Relationen zueinander nicht immer eindeutig ist, was letztendlich die Operationalisierbarkeit problematisch macht. Diese Punkte finden sich auch bei der Verortung der CMC auf diesem Kontinuum und bekräftigen diese. Außerdem kommen andere Kritikpunkte erst noch hinzu.
Der Gegenstand der Situierung – ob nun Kommunikationsform oder kommunikative Gattung – ist nicht eindeutig definiert, was auch die verschiedenen Verortungen von Berruto und Kattenbusch zeigen. Während bei Berruto eher kommunikative Gattungen Berücksichtigung finden, werden bei Kattenbusch Kommunikationsformen in verschiedenen situativen Kontexten und mit verschiedenen Kommunikationszielen berücksichtigt. Außerdem zeigt sich bei der Bestimmung der Kommunikationsbedingungen bei den drei verschiedenen Formen der CMC (E-Mail, Chat und Facebook Statusmeldungen), dass innerhalb der CMC differenziert werden muss, da es eine große Variation hinsichtlich einzelner Kommunikationsbedingungen und Versprachlichungsstrategien, und somit der Situierung auf dem Kontinuum gibt.Ebenso stellt die Operationalisierbarkeit der Situierung von Kommunikationsformen der CMC auf dem Kontinuum ein Problem dar (vgl. Androutsopoulos 2007, 80). Zwei Möglichkeiten, wie eine Situierung mittels der Bestimmung von Kommunikationsbedingungen durchgeführt werden kann, wurden dabei demonstriert. Während Berrutos Beschreibung der CMC auf einem konzeptionellen Relief in Anlehnung an die punktuelle Verortung bei Koch & Oesterreicher veranschaulicht wurde, wurde Kattenbuschs Verteilung der CMC mittels einer großflächigeren Darstellung der möglichen Grade beim Erreichen einzelner Kommunikationsbedingungen, veranschaulicht. Letztere hat somit den Vorteil, dass sie auch unterschiedliche Ausprägungen einzelner Kommunikationsformen mitberücksichtigt und wurde deshalb auch für die Bestimmung der Parameter der Facebook Statusmeldungen verwendet. Allerdings ist bei keiner der beiden Möglichkeiten klar, wo diese Kommunikationsformen letztendlich auf dem Kontinuum von Nähe- und Distanzsprache in Vergleich mit anderen Formen der CMC sowie mit nicht computervermittelten Kommunikationsformen, einzuordnen sind.
Einige der außersprachlichen Parameter sind zudem nicht eindeutig im Hinblick auf die CMC. Gerade was die Kommunikationsbedingung Öffentlichkeit/Privatheit angeht, lässt sich diese weder bei Multi User Chats, noch bei Facebook Statusmeldungen bestimmen, da der Produzent nur zu einem gewissen Grad selbst mit entscheiden kann, wer seine veröffentlichten sprachlichen Äußerungen tatsächlich liest.85 Ein weiteres Merkmal, das im Hinblick auf die CMC kritisch zu sehen ist, ist die physische Anwesenheit beziehungsweise Abwesenheit der Kommunikationspartner, denn die CMC wird gerade zur Überwindung raum-zeitlicher Grenzen verwendet (siehe Kapitel ). Aber auch Kattenbuschs Vorschlag, diese Kommunikationsbedingung bezüglich der CMC durch das Merkmal der Synchronität auszutauschen, birgt Gefahren (zur Synchronität siehe Kapitel ). Vielmehr sollte hier mit einbezogen werden, wann und in welcher Art und Weise die Rezipienten auf eine Äußerung der CMC-Formen reagieren. Schließlich verhält sich auch die Kommunikationsbedingung Spontaneität/Reflektiertheit im Zusammenhang mit der CMC deutlich anders als in beispielsweise Face-to-Face-Gesprächen. Noch nicht einmal beim Chat gibt es die Möglichkeiten so spontan auf die Äußerungen des Gesprächspartners zu reagieren – weder Unterbrechungen, noch Überlappungen sind möglich – und die Produktion und das Absenden einer Äußerung verläuft mal mehr oder weniger zeitlich versetzt.
Bei den Versprachlichungsstrategien gibt es ebenso Kritikpunkte hinsichtlich der CMC. Zum einen sei hier das Merkmal der Vorläufigkeit genannt, denn auch wenn Kattenbusch dem Chat einen hohen Grad an Vorläufigkeit zuweist, verflüchtigen sich Texte in der CMC nicht einfach. Der Gesprächsverlauf wird im Chatverlauf gespeichert und kann bei Bedarf von den Gesprächspartnern erneut aufgerufen und gelesen werden. Hier spielt das Medium als Speicher- und Übermittlungsmedium eine wichtige Rolle. Außerdem gibt es bei vielen Formen der CMC eine Präferenz für nichtsprachliche Kontexte und so werden non- und parasprachlichen Kommunikationsmittel auch in der CMC verwendet (siehe Kapitel ).
Schließlich bleiben bei der Relation zwischen den Kommunikationsbedingungen und den Versprachlichungsstrategien hinsichtlich der CMC Unklarheiten. So setzten die Kontexttypen des Nähesprechens physische Anwesenheit voraus, die aber bei den Möglichkeiten der raum-zeitlichen Überwindung der CMC gerade nicht gegeben ist. Und auch die einseitige Beziehung zwischen Text und Kontext – also dass ein Kontext zwar den Text bestimmen kann, aber nicht, dass auch der Text den Kontext bestimmen kann – kann kritisiert werden, denn diese ist beispielsweise bei Massenmedien durchaus vorstellbar.
‚Sprache der Nähe‘ im Internet kann also nur verstanden werden als Sprachgebrauch, der nicht nur eine bereits von der aktuellen Sprechsituation gegebene, vorausgesetzte Nähe reflektiert, sondern diese Nähe eben aktiv herstellt bzw. erzielt. (Androutsopoulos 2007, 80)
Zusammenfassend hängen viele der Kommunikationsbedingungen und Versprachlichungsstrategien mit den Affordanzen und Constraints, die die Formen der CMC mit sich bringen, zusammen. So können einige Merkmale in diesem Zusammenhang gar nicht als Parameter für eine Einordnung auf dem Nähe-/Distanzkontinuum dienen, da hier andere Strategien genutzt werden. Auch bei anderen hängt der Grad des Erfüllens stark mit denen vom Medium und der Kommunikationsform gegebenen Möglichkeiten zusammen, die eine Situierung, die wie die der nicht-computervermittelten Kommunikation erfolgt, in Frage stellt. Dies führt dann auch zu unklaren Relationen zwischen den Parametern und wie sich diese hinsichtlich der CMC gegenseitig beeinflussen.
Ist eine Einordnung überhaupt nötig?
In den vorangehenden Abschnitten wurden einige Kritikpunkte des Vierfelderschemas und des Nähe-/Distanzkontinuums aufgezeigt. Dabei wurden allgemeine Punkte vorgestellt, die hinsichtlich der CMC noch schwerer wiegen. Neben einigen terminologischen Schwierigkeiten und einer mangelnden Operationalisierbarkeit bei der Situierung der einzelnen Kommunikationsformen, führt die Verwendung dieses Modells bei der Situierung der CMC-Typen zu weiter greifenden Problemen. Wie schon im vorangehenden Kapitel erläutert, gilt es den Begriff der Kommunikationsform klar zu definieren, um ihn so von anderen Konzepten wie der kommunikativen Gattung oder der Textsorte abzugrenzen. Es muss deshalb klar sein, ob eine E-Mail nun als Kommunikationsform verortet wird oder ob es bestimmte Gattungen der E-Mail gibt, die einen bestimmten Zweck verfolgen (private vs. geschäftliche Korrespondenz).
Unklarheiten ergeben sich auch bei einer Diskussion der Kommunikationsbedingungen und Versprachlichungsstrategien im Kontext mit den Typen der CMC. Hervorzuheben sei hier der Parameter der physischen Distanz der Kommunikationspartner, der bei der CMC von dem Medialen vorgegeben ist und somit nicht mitberücksichtigt werden sollte. Physische Nähe gibt es hier nicht, weshalb auch die Existenz des darauf aufbauenden Spannungsfelds strittig ist. Das führt auch zu dem – zurecht – am häufigsten kritisierten Punkt, nämlich der fehlenden Berücksichtigung des Mediums.
Des Weiteren führt die Heterogenität innerhalb der CMC dazu, dass sich verschiedene Kommunikationsformen nahezu überall zwischen den beiden Polen des Kontinuums verorten lassen – zwischen und neben den anderen nicht computervermittelten Formen der Kommunikation. Das würde aber zu dem Rückschluss führen, dass diese gar keine genuin eigenständige Art der Kommunikation darstellen. Dem widersprechen aber die in den vorangehenden Kapiteln vorgestellten äußeren Charakteristika der CMC sowie die sprachlichen Merkmale, die im folgenden Kapitel noch thematisiert werden sollen.
Die Frage, die sich nun stellt, ist, ob eine Einordung der Typen der CMC zwischen Mündlichkeit und Schriftlichkeit überhaupt notwendig und sinnvoll ist. Dafür würde sprechen, dass somit die Sprachverwendung als Ganze, unter Berücksichtigung der verwendeten Produktions-, Übertragungs- und Rezeptionsformen in einem Modell dargestellt werden kann. Allerdings sollte dieses Modell bei der CMC vor allem das Medium beziehungsweise den Medienkomplex (siehe Kapitel ) sowie das Kommunikationsmedium in den Fokus rücken. Erst davon ausgehend kann eine Situierung vorgenommen werden. Die Notwendigkeit dieser Situierung sei aber ebenfalls in Frage gestellt, denn auch die sprachlichen Besonderheiten und Merkmale der CMC ergeben sich aus dem verwendeten Medium/Medienkomplex (und daraus resultieren widerum die Affordanzen und Constraints). Dass sich diese spezifischen linguistischen Merkmale auch ohne eine Verortung analysieren und beschreiben lassen, soll das folgende Kapitel zeigen
3.2. Merkmale der CMC in Facebook Statusmeldungen
Nachdem der Fokus in Kapitel auf die Konstituente des Medialen in der CMC gerichtet wurde, soll nun die Kommunikation, die medial vermittelt wird, näher betrachtet werden. Auf Watzlawick (1980, 53) geht dabei das Axiom zurück, „[m]an kann nicht nicht kommunizieren.“[Hervorhebung im Original]. Jeglicher Interaktion von Menschen wird dabei ein Kommunikationsgehalt zugesprochen. Damit ist gemeint, dass wir uns nicht nur über sprachliche Zeichen, also Sprache und Schrift miteinander verständigen, sondern auch die Körpersprache, die Mimik und Gestik, aber auch ein Schweigen übermitteln Informationen verschiedener Art. Das gilt nicht nur für die Face-to-Face-Kommunikation, sondern auch für den virtuellen Raum. Hier spielen – außer bei der Videotelefonie – Mimik, Gestik und Körpersprache keine Rolle. Es muss stattdessen auf andere Kommunikationsmittel zurückgegriffen werden: Zu den wohl bekanntesten zählen sicherlich die Emoticons oder der „gefällt mir“-Button bei Facebook.
Generell versteht man unter Kommunikation im weiteren Sinne die Informationsvermittlung mithilfe von Zeichen; diese kann zwischen Lebewesen erfolgen, aber auch zwischen Mensch und Maschine (siehe Kapitel ). Sprachwissenschaftlich gesehen erfolgt die Kommunikation sowohl mittels sprachlicher, als auch nichtsprachlicher Zeichen (vgl. Bussmann & Gerstner-Link 2002, 346).86 Bei der sprachlichen Kommunikation handelt es sich um die Sprache, den Inhalt, während unter nichtsprachlicher Kommunikation die sprachbegleitenden, nicht sprachlichen Zeichen, wie Körpersprache, Mimik, Gestik oder Blickkontakt, verstanden werden. Begleiten heißt, dass ihnen bei einem Gespräch eine unterstützende, verdeutlichende oder vorbereitende Funktion zukommt, oder dass sie sprachliche Zeichen gar komplett ersetzen (vgl. Linke & Nussbaumer & Portmann 1996, 273). Schließlich kann die nichtsprachliche Kommunikation auch noch weiter unterteilt werden. So werden meist noch parasprachliche Mittel aufgezählt, mit denen Informationen übertragen werden können (vgl. Posner 1986, 272-273).87 Hierzu zählen alle Signale, die bei der Lautsprache durch die Stimme vermittelt werden können, wie Stimmlage, Tonfall, Artikulation, Lautstärke, Sprechtempo und Sprachmelodie, inklusive Sprechpausen und Schweigen. Während der Sprecher die sprachlichen Zeichen meist bewusst wählt, werden nicht- und parasprachliche Merkmale meist unbewusst übermittelt und können zwischen verschiedenen Kulturen und Sprechergemeinschaften stark variieren. Nach Watzlawick & Beaven u.a. (1980, 61) ist die nichtsprachliche oder „analoge Kommunikation“ deshalb eher Indiz für die Glaubwürdigkeit des Gesprächspartners als das sprachlich Geäußerte, die „digitale Kommunikation“.
Die oben genannten Kommunikationsmittel werden vor allem in der Face-to-Face-Kommunikation verwendet. Aber auch in geschriebenen Texten, wie beispielsweise einem Zeitungsartikel, erfolgt Kommunikation auf allen drei genannten Ebenen. Dabei gehören die schriftlich festgehaltenen Texte zur sprachlichen Ebene, während das Parasprachliche durch graphologische Merkmale dargestellt wird. Zu den nichtsprachlichen Elementen zählen bei den geschriebenen Texten die Aufteilung eines Textes, das Layout, zum Beispiel das Hervorheben einzelner Wörtern durch Änderung der Schrift(art), aber auch begleitende visuelle (oder auditive) Elemente.
Auch bei der CMC im Allgemeinen werden Kommunikationsmittel verschiedener Art genutzt, die von den verwendeten Mitteln der gesprochenen oder geschriebenen Sprache, wie gerade exemplarisch für die Face-to-Face-Kommunikation oder den Zeitungsartikel gezeigt, abweichen können. Diese abweichenden Kommunikationsmittel werden als besondere Merkmale der textbasierten CMC oder als semiotische Innovationen oder „semiotische Ausbeutung von Schriftzeichen“ (Kilian 2001, 71) angesehen. Allerdings kann sich deren Verwendung je nach Kommunikationsformen stark unterscheiden. Deren Gebrauch trägt zur Klassifizierung und Abgrenzung von Kommunikationsformen innerhalb der CMC bei.
Diese spezifischen Merkmale der Kommunikation sind häufig Inhalt in sprachbeschreibenden Studien zur textbasierten CMC. Tabelle 9 fasst diese und deren Gebrauch, wie er in den Facebook Statusmeldungen und Posts zu erwarten ist, zusammen.88 Dabei sind die Merkmal gegliedert nach Art des Kommunikationsmittels in nichtsprachlich, parasprachlich und sprachlich, auch wenn an dieser Stelle schon vorweggenommen sei, dass die Grenzen nicht immer klar verlaufen und je nach Autor (und Interpretation) ein Merkmal auch durchaus einem anderen Kommunikationsmitteltyp zugeordnet werden kann.
| Kommunikationsmittel | Beschreibung | Beispiel |
| nichtsprachlich |
Emoticons Verwendung von Groß- und Kleinschreibung zur Hervorhebung Visuelle Elemente |
😉 :'( <3 –<-@ NEIN Bilder und Videos |
| parasprachlich |
Inflektive „Getippte Stimme“ Kurzformen Tippfehler, grammatische und orthographische Unkorrektheiten |
*grins*, <sigh> jaaaaaaaaaaaaaaaa!!!!! haha, ihih, …., hmmm thx, ke, x „Thanx to internet, my spelling sucks!!!“ |
| sprachlich |
Häufige Verwendung von Grußformeln und Phrasen Hohe Frequenz an Vokativen Verwendung von Diskursmarkern, Interjektionen und Modalpartikel (morpho)syntaktische Strukturen zur Hervorhebung Plurilingualismus etc. |
Ciao, che fai? Bussi! Ciao bella! Ecco, dai, scusa. Also, ah Dislokationen; Koordinationen anstelle von Subordinationen; Ellipsen (z.B. Pronomen) regionale Varietäten; Lehngut; Code-Switching |
Diese Merkmale lassen sich nach der Art des Kommunikationsmittels ordnen. Zu dem ersten Bereich der nichtsprachlichen Kommunikationsmittel zählen die textbegleitenden visuellen Darstellungen, wie Emoticons. Dazu gehören auch die Verwendung von anderen visuellen (oder auditiven) Elementen, wie Bilder und Videos. Die Verwendung von anderen Schriftarten sowie Groß- oder Kleinschreibungen, können als nichtsprachliche Informationen hervorgehoben werden. Zu den parasprachlichen Mitteln lassen sich all jene Merkmale zählen, die sich durch das Schreiben, oder besser gesagt das Tippen, auf einer Tastatur ergeben. Dazu zählen nicht nur Merkmale, die sich auf das Zeichensystem, das der sprachlichen Kommunikation dient, beziehen (zum Beispiel verwendete Abkürzungen und Schreib- oder Tippfehler), sondern auch Formen der getippten Prosodie. Bei dem Bereich der sprachlichen Strategien handelt es sich um linguistische Phänomene, die verschiedene Ebenen der Linguistik, wie die (morpho-)syntaktische, lexikalische als auch pragmatische Ebene, betreffen können. Dazu zählt die Verwendung bestimmter Wörter und Ausdrücke, aber auch bestimmter Satzstrukturen und Wortstellungen. Eine große Rolle spielt schließlich auch die Verwendung fremdsprachlichen Materials oder das Wechseln von Sprachen.
Die Verwendung dieser besonderen Merkmale lässt sich vor allem mit zwei Gründen rechtfertigen. Auf der einen Seite sind sie dem Medium beziehungsweise den medialen Affordanzen und Constraints geschuldet. Auf der anderen Seite stellen sie aber auch Strategien dar, die auf konzeptioneller Ebene arbeiten und Distanz reduzierend wirken. Die Verwendung eines Emoticons ist beispielsweise nicht nur darauf zurückzuführen, dass es mittels einer Tastatur erstellt (oder aus einer Liste in einer Anwendung ausgewählt werden kann), sondern sie stellt auch eine Strategie dar, konzeptionell Nähe herzustellen.
Im Folgenden sollen die verschiedenen Merkmale der CMC aus Tabelle 9, die in der Literatur immer wieder thematisiert und hervorgehoben werden, genauer beschrieben werden und deren Existenz in den Facebook Statusmeldungen anhand von Beispielen verifiziert werden.
3.2.1. Nichtsprachliche Merkmale der CMC
3.2.1.1. Emoticons
Unter Emoticons werden textbegleitende Zeichen verstanden, die die Gefühle des Schreibers widerspiegeln sollen.
The term ‘‘emoticons’ ’— a blend of ‘‘emotion’’ and ‘‘icons’’ – refers to graphic signs, such as the smiley face, that often accompany textual computer-mediated communication (CMC). (Dresner & Herring 2010, 249).
Das sogenannte Smiley, das lachende Gesicht, sei hier als das wohl bekannteste Emoticon anzuführen. Es wird meist durch die Kombination von Doppelpunkt und schließender Klammer dargestellt, da es um neunzig Grad gedreht dem lachenden Gesicht eines Menschen ähnelt: :-).89 Emoticons sollen den emotionalen Status des Schreibers widerspiegeln und außersprachliche Informationen, wie sie normalerweise in der Face-to-Face-Kommunikation durch Gesichtsausdruck und Körpersprache vermittelt werden, liefern (vgl. Dresner & Herring 2010, 250).
Im Internet und in der Literatur finden sich verschiedene Vorschläge und Konventionen, welche Symbole mit welchen Emotionen in Verbindung gebracht werden. Allerdings gibt es je nach Quelle unterschiedliche Interpretationen. Facebook unterstützt im Allgemeinen folgende Emoticons:
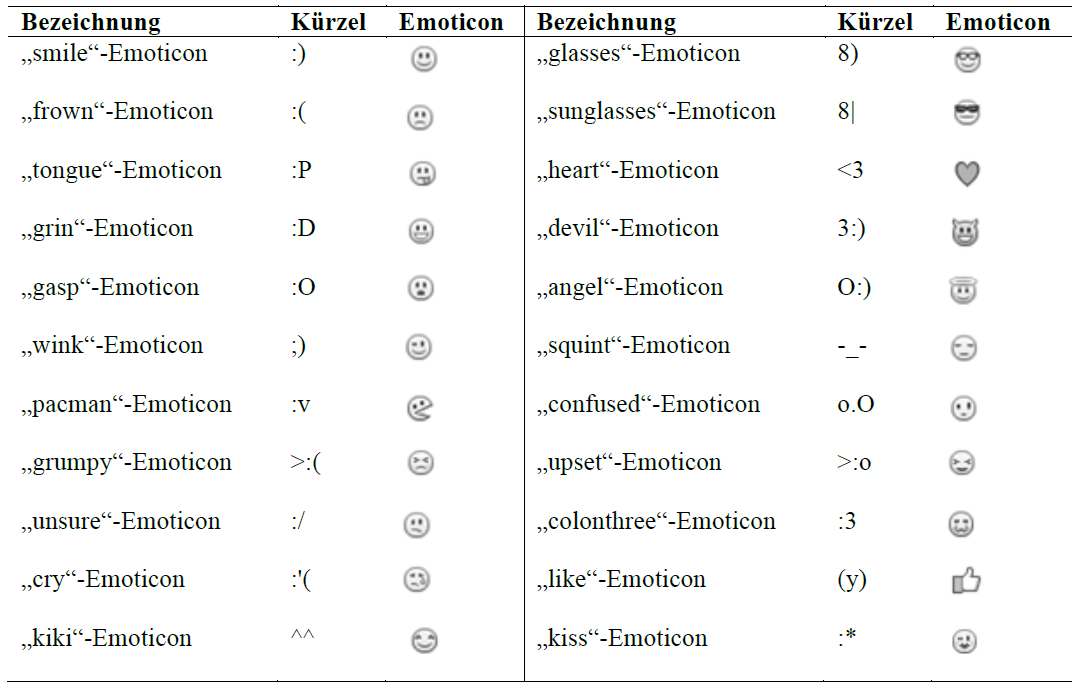
Bei der Vielzahl der Emoticons wird jedoch schnell klar, dass diese nicht immer Emotionen im eigentlichen Sinne widerspiegeln. Das Symbol für einen Teufel, 3:-), und das (Sonnen-)Brille tragende Gesicht, 8-), geben beispielsweise Emotionen nur im übertragenen Sinne wieder (Teufel: ‚Schreiber fühlt sich böse?‘, Sonnenbrille: ‚Schreiber fühlt sich cool oder ist relaxed?‘). Nach Dresner & Herring (vgl. 2010, 263–264) können Emoticons eine von drei verschiedenen Funktionen erfüllen. Sie sind
- Indikatoren für Emotionen, wie sie auch am Gesichtsausdruck abgelesen werden können.
- Indikatoren für nicht emotionale Bedeutungen, die konventioneller Weise an der Mimik erkennbar sind.
- Illokutionsindikatoren, die konventioneller Weise nicht an der Mimik erkennbar sind.
Auf der einen Seite gibt es also Emoticons, die Emotionen ausdrücken, die sich normalerweise auch an der Mimik oder Gestik widerspiegeln. Dazu zählen beispielweise das klassische Smiley sowie das traurige oder das weinende Gesicht, die Gefühle wie Freude oder Trauer ausdrücken und die auch an Gesichtszügen erkennbar sein können. Andere Emoticons kopieren ebenso einen bestimmten Gesichtsausdruck, der aber nicht mit einer emotionalen Gefühlslage in Verbindung gebracht werden kann. Als Beispiel kann hier das zwinkernde Gesicht genannt werden, das einen Witz begleitet. Ebenso verhält es sich mit der herausgestreckten Zunge, die ebenfalls an der Mimik des Sprechers abgelesen werden kann, nicht aber eine Emotion ausdrückt. Dabei handelt es sich um konventionalisierte Mimik und Gestik, die als nichtsprachliche Symbole die Äußerungen begleiten. Auf der anderen Seite gibt es Emoticons, die normalerweise nicht am Gesichtsausdruck abgelesen werden können. Zu dieser Kategorie gehören solche, die beispielsweise dazu verwendet werden, Äußerungen zu entkräften, oder auf Sarkasmus oder Ironie hinzuweisen; dies kann beispielsweise mit einem lachenden oder einem zwinkernden Smiley geschehen. Dresner & Herring (vgl. 2010, 255–259) sprechen den Emoticons in diesen Fällen eine Funktion als Illokutionsindikatoren zu.
Auch in den Facebook Statusmeldungen und Posts werden Emoticons eingesetzt, die vom Nutzer aus der Liste mit Emoticons entweder durch Anklicken oder mit Hilfe von bestimmten Tastenkombinationen (Shortcuts) dem Geschriebenen hinzugefügt werden können (siehe Tabelle 10). Es kommt sogar vor, dass ein Facebook Beitrag nur aus einem einzelnen Emoticon besteht, welches nicht durch einen Text begleitet wird. Hier ist der Zweck häufig das Mitteilen der persönlichen Gefühlslage, wie in Beispiel (3), in dem nur ein trauriges Gesicht wiedergegeben wird.
[FB 1621_1524]
„frown“-Emoticon91
Allerdings finden sich auch Okkurrenzen, in denen Emoticons eine der anderen von Dresner & Herring (vgl. 2010, 263–264) genannten Funktionen erfüllen, wie die Beispiele (4) und (5) zeigen. So wird in (4) zwar mittels dem lachenden und dem Gesicht, das die Zunge hinaus streckt, eine am Gesicht ablesbare Mimik wiedergegeben, die aber nicht unbedingt einer Emotion zuzuordnen ist. Im Falle des Ersteren wird Freundlichkeit signalisiert und im Falle des Letzteren das Gesagte abschwächt. In (5) verdeutlich das Gesicht mit dem zwinkernden Auge, dass es sich hier um einen Witz oder Ironie handelt.
[FB 1301159_205]
Ciao bella „smile“-Emoticon Sei già a Roma?Ti invidio tantissimo…„tongue“-Emoticon un bacio
[FB 1021129_80]
haahaha coppia aperta? hahaaha.. „wink“-Emoticon
Außerdem lässt sich feststellen, dass es auch Statusmeldungen gibt, in denen die Emoticons eine zusätzliche strukturierende Aufgabe übernehmen und somit als eine Art Interpunktion fungieren können, wie vor allem das „smile“-Emoticon in (4) zeigt.
Heutzutage sind auch die in Japan entwickelten zweidimensionalen Piktogramme, die sogenannten Emojis, in der CMC weit verbreitet.92 Neben den erweiterten Möglichkeiten, Emotionen darzustellen, wurden noch weitere Funktionen ergänzt (vgl. Dürscheid & Frick 2014, 173–174, Kelly & Watts 2015). So kann beispielsweise Zustimmung durch das Symbol für klatschende Hände oder einen nach oben gestreckten Daumen ausgedrückt werden. Es können aber auch ganze Wörter oder Phrasen durch Emojis ersetzt oder ergänzt werden, wie ein Beispiel aus dem privaten Whatsapp-Verlauf der Autorin zeigt:
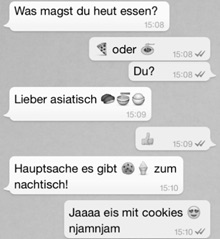
Beispiel für eine Whatsapp Nachricht unter Verwendung von Emojis.
(Lizenz: CC BY SA)
Emojis werden vor allem in Smartphone Applikationen verwendet und auch wenn Facebook Statusmeldungen und Posts über die Tastaturen mobiler Endgeräte verfasst werden können, lassen sich in dem dieser Arbeit zugrunde liegenden Korpus keine Okkurrenzen dafür finden.93
Es lässt sich also festhalten, dass Emoticons als Merkmale für Emotionen das sprachlich Formulierte begleiten und darüber hinaus noch weitere Funktionen erfüllen. Sie sind der nichtsprachlichen Kommunikation zuzuordnen, unterscheiden sich allerdings im Vergleich zu der nichtsprachlichen Gestik eines Sprechers in einer Face-to-Face-Kommunikation dahingehend, dass sie bewusst gewählt (oder getippt) werden, während sich die Gesichtszügen in einem Gespräch meist unbewusst ändern. Sarkasmus und Ironie ergeben sich in einem Gespräch meist aus dem Ko- und Kontext oder aus prosodischen Aspekten, während diese parasprachlichen Merkmale in der CMC durch Emoticons dargestellt werden. Des Weiteren können Emoticons Äußerungen strukturieren oder bestimmte Teile hervorheben. Es gibt aber auch noch anderen Strategien der Emphatisierung, wie der nächste Abschnitt zeigt.
3.2.1.2. Großschreibung zur Hervorhebung
Zu den nichtsprachlichen Kommunikationsmitteln zählen auch das Layout, die Schriftart oder weitere Formatierungsmöglichkeiten des Textes. Allerdings gibt es nicht immer die Möglichkeiten die Typographie, beispielsweise durch Kursivierung oder Änderung der Schriftart, zu ändern. Eine weitere Strategie der Emphatisierung, die sich deshalb in der CMC finden lässt, ist die Versalienschreibung. Auch in Facebook wird diese verwendet und so wird in Beispiel (6) durch die Verwendung von Großbuchstaben das Pronomen MIR betont.
[FB 1921254_1292]
MIR tut es leid, dass ich nicht noch mal oben war!! […]
[FB 1921_761]
back from OKTOBERFEST!!!! einfach super!!!!
Auch in (7) wird OKTOBERFEST durch die Versalienschreibung hervorgehoben und somit auch als anderssprachiges Element in dem Satz markiert. Allerdings dient die Verwendung von Großbuchstaben nicht nur der Hervorhebung oder Betonung, sie kann auch prosodische Merkmale imitieren, wie sich in Kapitel zeigen wird.
3.2.1.3. Visuelle Elemente: Bilder, Videos und Links
Neben dem Layout und der Typographie können auch noch andere visuelle Elemente die Kommunikation begleiten. Je nach Kommunikationsform der CMC können Bilder, Videos und Links eingefügt werden.
Auch die Facebook Beiträge können durch nichtsprachliche Elemente begleitet werden oder sogar nur aus solchen bestehen. Es können hier sowohl Bilder, als auch Videos und Links verwendet werden. Insgesamt bestehen 53% aller Facebook Beiträge des Facebook Korpus nur aus nichtsprachlichen visuellen Elementen und ersetzen so textbasierte Kommunikation (siehe Kapitel ). Des Weiteren begleiten Bilder, Videos und Links 11% aller textbasierten Facebook Beiträge (ebd.). So zeigt das in Abbildung 4 (siehe Kapitel ) verwendete Bild zwei Bierkrüge, die die textbasierte Statusmeldung Prost!!! begleiten. Durch das Bild werden dem Text noch weitere Informationen hinzugefügt, beispielsweise, dass hier zwei Personen miteinander anstoßen, Bier trinken und sich in einem Wirtshaus befinden. Ebenso stellen Links und Videos visuelle und auch auditive Elemente dar, die die Kommunikation begleiten oder sprachliche Texte komplett ersetzen können. Die Wichtigkeit dieser nichtsprachlichen Elemente zeigt sich somit auch in den Facebook Beiträgen.
Aber nicht nur nichtsprachliche Kommunikationsmittel haben sich in der CMC etabliert, auch parasprachliche Zeichen haben hier einen besonderen Stellenwert erhalten.
3.2.2. Parasprachliche Merkmale der CMC
Zu den parasprachlichen Kommunikationsmitteln, die in der CMC verwendet werden, zählen (in geringem Umfang) Inflektive, aber auch die Repräsentationen von stimmlichen Eigenschaften und Lauten. Ebenso kann die Abwesenheit von solchen, die Stille, dazu gerechnet werden. Außerdem können auch graphematische Merkmale, wie die verwendeten Schreibweisen, die das Schriftbild der CMC prägen, zu den parasprachlichen Merkmalen gezählt werden. Deshalb werden in diesem Kapitel auch abkürzende Schreibweisen und Tippfehler vorgestellt, da diese durch ihr schriftliches Erscheinungsbild Abweichungen darstellen – auch wenn diese natürlich auf inhaltlicher Ebene sprachliche Einheiten darstellen.
3.2.2.1. Inflektive
Inflektive sind keine semiotischen Innovationen der CMC, vielmehr handelt es sich dabei um Adaptionen aus der Comicsprache, die in die CMC und vor allem in die Chat-Kommunikation übernommen wurden (vgl. Burger 1980). Dabei werden Verbstämme ohne Flexionsendung verwendet, die zur Markierung meist mit Asterisken oder spitzen Klammern dargestellt werden. Ziel dabei ist die Darstellung von beispielsweise Körpersprache, prosodischen Merkmale, oder anderen die Kommunikation begleitenden außersprachlichen Aktivitäten. Allerdings sind diese meist nur in der deutschen und englischen und kaum in der italienischen CMC zu finden.
[FB 2211129_831]
Rabiosa „smile“-Emoticon *wink* *wink* *wink* *wink* *wink*
[FB 231079_164]
am samstag komm ich!!! *freu freu* ruf dich morgen mal noch wegen weiteren infos an!! „kiss“-Emoticon
In beiden Beispielen stellen die Inflektive die Kommunikation begleitende Gestik oder Mimik dar. Das Blinzeln, das in (8) mit *wink* ausgedrückt ist, soll entkräftend wirken und zeigen, dass das zuvor Geäußerte nicht ernst gemeint ist, während das *freu freu* in (9) die Freude des Schreibers darstellt. Allerdings können hier nur sehr wenige Okkurrenzen insgesamt gefunden werden; andere Formen von parasprachlichen Merkmalen werden bevorzugt.
3.2.2.2. „Getippte Stimme”
In einem Face-to-Face-Gespräch werden den Äußerungen durch stimmliche Merkmale weitere Informationen hinzugefügt; der Sprecher kann durch die Variation von Tonhöhe, Lautstärke, Sprechgeschwindigkeit, Akzentuierung sowie durch das Setzen von Pausen die übermittelte Information strukturieren und bestimmte Aspekte hervorheben. Außerdem kann er seinen Standpunkt oder die Bewertung einer Situation durch diese redebegleitenden stimmlichen Möglichkeiten darstellen. Knas (2009) hebt in ihrer Studie, die unter dem Titel „Read My Voice“ veröffentlicht wurde, im Hinblick auf die CMC die Bedeutung von Stille und (nicht sprachlichen) Geräuschen in den Konversationen hervor. Diese wurde bis dahin zumeist nur für die gesprochene, spontane Kommunikation (sowohl Face-to-Face als auch Telefon, Rundfunk etc.) untersucht.
Stille und Schweigen, definiert als die Abwesenheit von jeglichen Geräuschen, wurde lange Zeit nicht als Bestandteil von Konversationen angesehen. Vielmehr galt sie lange Zeit gar als Zeichen von Unfreundlichkeit oder fehlender Kommunikationsbereitschaft (vgl. Laver 1981, 301). Generell werden dem Gebrauch von Stille unterschiedliche Funktionen zugesprochen, die abhängig von Kultur und Sprechergemeinschaft sind. Pausen strukturieren das Gesagte, dienen aber auch als rhetorische Stilelemente und ein Schweigen an bestimmten Stellen in einem Gespräch vermag mehr auszudrücken als Worte, wie es schon in dem Sprichwort „Reden ist Silber, Schweigen ist Gold“ heißt.
Unter nichtsprachlichen Geräuschen in der Kommunikation versteht man hingegen solche, die der Konversation mit Hilfe der Stimme weitere Informationen hinzufügen. Hierzu zählt man beispielsweise Lachen oder Verzögerungslaute, wie äh oder hm, mit Hilfe derer der Sprecher seine Nachricht wählen und ändern kann (vgl. Allwood 2000, 17). Auch Interjektionen oder andere Pausenfüller werden häufig in Bezug auf spontane mündliche Konversationen untersucht und häufig auch als parasprachliche Kommunikationsmittel angesehen (vgl. Wharton 2003).
In der nicht computervermittelten, textbasierten Kommunikation werden selten lautsprachliche Merkmale, die nichts mit dem Sprachsystem zu tun haben, ebenso wie Laute, die aus nicht sprachlichen Einheiten bestehen, verschriftlicht.94 In der CMC hingegen haben sich verschiedene Strategien, parasprachliche Merkmale darzustellen, etabliert. Das geschieht zu einem Großteil über die Tastatur und somit durch den Gebrauch des alphabetischen und numerischen Zeichensystems sowie nach Knas (vgl. 2009, 2) auch durch die Möglichkeiten der Interpunktion und der Verwendung anderer Symbole, die auf der Tastatur zur Auswahl stehen. Die Strategien, parasprachliche Merkmale mit Hilfe des durch die Tastatur vorgegebenen Zeichensystems in der getippten CMC darzustellen, können nach Knas (ebd.) in drei Kategorien geteilt werden: Stille, Füller und Phoneticons. Diese werden im Folgenden kurz vorgestellt und deren Vorhandensein auf Facebook durch Beispiele belegt.
Stille
Da die Abwesenheit von Geräuschen in der CMC nicht auditiv wahrgenommen werden kann, muss auf visuelle Mittel, die zur Produktion von Informationen Verwendung finden, zurückgegriffen werden. Vor allem die Interpunktion kann hier helfen:
[…] silences are expressed in writing by means of punctuation (mainly by means of ellipses ‘…’) and verbal descriptions. In certain cases, silence is not explicitly expressed in any form, but its occurrence can be inferred based on context or content of the message. (Knas 2009, 2)
In den untersuchten polnischen und englischen SMS-Nachrichten wird von der Autorin eine häufige Verwendung von Ellipsen beobachtet (vgl. Knas 2009, 10).95 Diese können durch die mehrfache Verwendung des Punktes oder des Gedankenstrichs dargestellt werden. Außerdem können Pausen durch sprachliche Phrasen oder durch die Verwendung von Lücken im Text mittels Mehrfachverwendung des Leerzeichens ausgedrückt werden. Stille in dieser speziellen Art der CMC wird dazu verwendet, „loss for words“ auszudrücken, der auf positiven oder negativen Ereignissen, zu denen der Sender seine emotionale Beteiligung zum Ausdruck bringen möchte, beruht (ebd.). Diese Strategien werden auch dazu verwendet, um sozial oder kulturell nicht erwünschte Begriffe zu ersetzen, um zu signalisieren, dass noch eine Antwort erwartet wird oder um feste Phrasen oder idiomatische Ausdrücke abzukürzen.
Auch in den Facebook Statusmeldungen lassen sich verschiedene Strategien finden, Pausen auszudrücken. Vor allem die Verwendung von Punkten lässt sich sehr häufig beobachten:
[FB 102153_351]
ja ich habe einen deutschen freund (unglaublich nett) der eine wg ab september sucht…wenn deine freundin einen sehr sehr sehr netten mitbewohner sucht…bitte sag mir bescheid küsse
[FB 1112_14]
BASTAAAAA odio sto terremoto….es reicht jetzt mit dem sch.. Erdbeben!!!
Nach Auffassung von Knas (vgl. 2009) zur Verschriftlichung von Stille könnten in (10) die Punkte herkömmliche Satzzeichen ersetzen und eine größere Gedanken- oder Sprechpause signalisieren. In (11) hingegen übernehmen die Punkte zum einen eine organisatorische Funktion, zum anderen spiegeln sie auch Höflichkeit wieder, indem der Produzent ein Schimpfwort nicht ganz ausschreibt.
Aber auch der Gebrauch von Gedankenstrichen ist, wenn auch mit weniger Okkurrenzen, in den Statusmeldungen beobachtbar.
[FB 1112_94]
Compliments to all MUMS and DADS – you are doing the best job in the world!
[FB 1301_260]
hat ihren ring im stiefel wiedergefunden „grin“-Emoticon – ha appena ritrovato il suo anello nella scarpa „grin“-Emoticon
Der Gedankenstrich kann dazu dienen, den Fokus auf einen bestimmten Teil der Nachricht zu richten, wie (12) zeigt. Er kann aber wie in (13) auch einen Satz zu strukturieren, wobei die Übersetzung der Äußerung mit einem Gedankenstrich eingeleitet wird.
Es gibt schließlich auch Fälle in denen die Stille sprachlich ausgedrückt wird, wie das Beispiel in (14) zeigt, in dem sich der Autor zusätzlich noch Punkten bedient:
[FB 2211276_1123]
Io non commento… Hihihihihi „wink“-Emoticon
Die hier verwendeten Zeichen sind jedoch anders als die Stille nach Knas zu definieren, wonach die Pausen nicht zwischen zwei Äußerungen liegen, sondern nur innerhalb einer einzigen. Trotzdem lässt sich zusammenfassen, dass die Pausen in den Facebook Beiträgen sowohl eine organisatorische Funktion, als auch eine die Prosodie imitierende Funktion einnehmen. Satzzeichen in geschriebenen Texten übernehmen im Allgemeinen die Funktion, einen Satz zu strukturieren, was im Gesprochenen durch längere Pausen (sowie durch Intonation) geschieht. Die Möglichkeiten der CMC, Stille auszudrücken, stellen somit eine Mischform dar: der Benutzer strukturiert und organisiert seine Äußerungen und Pausen nicht mit den Strategien, womit das üblicherweise in geschriebenen Texten geschieht, sondern verwendet CMC spezifische Mittel, die als Imitation des Gesprochenen angesehen werden können.
Füller
Die Füllwörter nach Knas (2009) stellen eine Unterkategorie der Gesprächswörter dar, die wiederum verschiedene Typen von Interjektionen präsentieren. In der Diskussion zu Interjektionen taucht auch immer wieder die Frage auf, ob es sich hierbei um sprachliches Material handelt oder ob man dabei besser von „nonwords“ oder gar „semiwords“ sprechen sollte (Goffman 1981, 115). Argument für Letztere ist ihre Übereinzelsprachlichkeit, wenn nicht Universalität, da sie eher paralinguistische Funktionen erfüllen. Da ihr Status als parasprachliche und/oder sprachliche Merkmale umstritten ist, und sie in den Studien zur CMC in beiden Bereichen diskutiert werden, werden sie auch hier kurz umrissen und schließlich in Kapitel wieder aufgegriffen.
Füllwörter können theoretisch an jeder Position einer Äußerung auftauchen, stehen meist aber zu Beginn:
[…] fillers replace redundant pauses and mark message-processing, uncertainty, or unwillingness to give up the floor to another participant. They are represented in writing by means of tokens, such as ‘hmm’, which do not carry propositional meaning, but express the sender’s attitude to the message or the ongoing conversational exchange. (Knas 2009, 2) [Hervorhebungen im Original]
Füllwörter können die Einstellung des Verfassers sowie positive oder negative Emotionen widerspiegeln. Die Dopplung der Buchstaben, wie in hmmmm, kann zudem Aufschluss über die Stärke der emotionalen Beteiligung geben (vgl. Knas 2009, 12). Außerdem werden sie oft zur Selbstkorrektur verwendet (ebd.).
[FB 1824_656]
prossimo viaggio … mmmm ci sto ancora pensando
[FB 2310163_83]
hmmm,kagge…weiß auch net!wie lang kann man die denn behalten vorm zurückschicken?was meinst welches passt besser?ach,is des doof…is von dir auch noch was gekommen?weil sonst behalt des,welches eher passt und ich überweis dirs geld auf dein konto plus das internetgeld,dann is des auch erledigt….??grüßle
So zeigen die beiden in Facebook gefundenen Beispiele, dass auch hier diese Strategien Verwendung finden. In (15) signalisiert mmmm eine Gedankenpause, in (16) hingegen stellt hmmm eine negative Bewertung dar (die allerdings hier auch noch mit zusätzlichen sprachlichen Mitteln erklärt wird).
Phoneticons
Unter Phoneticons versteht man die graphematische Repräsentation stimmlicher Merkmale. Sie können auch als der „only naturally type of aural content in text-messages“ (Knas 2009, 12) verstanden werden. Durch Versalienschreibung (die Verwendung von Großbuchstaben) oder Buchstabeniteration wird die Länge von Lauten, die Lautstärke, oder auch eine vom Standard abweichende Aussprache markiert.
[FB 1921170_730]
bello chiaccherare cn te!ci sentiamo quando sarai tornata a Milano..e io nella mia casetta!!!!un mega super grande abbraccio!
[FB 1824128_797]
giornooooooooooooooooooooooooo tesoroooooooooooooooooooooo
In den beiden im Facebook Korpus gefunden Beispielen kann gezeigt werden, dass eine multiple Iteration von Buchstaben den affektiven Status des Produzenten offenbart. Die Verwendung von Großbuchstaben in (17) zeigt auch an, dass es sich hierbei um eine Emphatisierung handelt, die im Gesprochenen wohl mit einer gesteigerten Lautstärke ausgedrückt worden wäre. Interessant dabei ist, dass hier nicht nur Vokale gelängt werden, sondern auch Konsonanten obwohl eine Längung von Konsonanten eher unüblich ist. In diesen Beispielen zeigt sich auch noch eine weitere Möglichkeit, wie Hervorhebung durch Prosodie erfolgen kann, nämlich durch eine Iteration der Interpunktion, wie bei !!!! in (17). Andere Geräusche, die sich auf Aktionen beziehen, die eine Kommunikation begleiten, werden häufig onomatopoetisch dargestellt, wie beispielsweise Lachen (haha oder hihi), Seufzen (ach) oder Essen und Trinken (njamnjam, gulp).96 Auch in den Facebook Beiträgen lassen sich Beispiele dieser Art finden.
[FB 162166_1369]
mmmmmmmmuà!
[FB 2211_79]
stasera: Kässpätzle… mmmmh!!!!
[FB 1021_66]
ahahah fantastico!
[FB 1921422_1102]
haha„smile“-Emoticon Wann kommst du denn wieder?
So wird in (19) das Geben eines Kusses lautmalerisch dargestellt. In (20) imitiert mmmmh ein Geräusch, das Genuss beim Essen ausdrückt. Die Beispiele (21) und (22) stellen Lachen onomatopoetisch dar; interessant hierbei ist, dass das Lachen in einem ansonsten auf Italienisch geschriebenen Text mit einem Vokal beginnt, im Deutschen mit einem stimmlosen glottalen Frikativ, den es im italienischen Konsonantensystem bei der Aussprache nicht gibt.
Die Funktion von Phoneticons ist nach Ansicht von Knas (vgl. Knas 2009, 14) die Imitation von Face-to-Face-Interaktionen. Während Füllwörter und Stille auch in den nicht computervermittelten Kommunikationsformen des Geschriebenen zu finden sind – man denke an Comics oder handschriftliche Briefe – ist die Verwendung von Phoneticons limitiert. Eine Variation zwischen Groß- und Kleinbuchstaben sowie die Verwendung von onomatopoetisch dargestellten Geräuschen ist durchaus vorstellbar (und in Comics auch sehr gebräuchlich), aber häufige Dopplung von Buchstaben oder Interpunktionen zur Imitation von Prosodie sind eine Besonderheit der CMC. Sicher hängt das auch damit zusammen, dass diese recht einfach und ohne großen Aufwand produziert werden können – es reicht meist aus auf der entsprechenden Taste der Tastatur zu bleiben um eine Doppelung des Buchstabens oder Zeichens zu bewirken.
Neben diesen eben beschriebenen Möglichkeiten, Prosodie mit Hilfe von getippten Zeichen darzustellen, gibt es auch noch paralinguistische Merkmale, die die Schreibweisen und das Schriftbild betreffen, dazu gehören abkürzende Schreibweisen, aber auch Tippfehler und grammatische und orthographische Abweichungen, welche im Folgenden vorgestellt werden sollen.
3.2.2.3. Kurzformen und abkürzende Schreibweisen
Es gibt verschiedene Möglichkeiten, beim Schreiben über eine Tastatur abzukürzen. Viele dieser abkürzenden Schreibweisen, bei Antonelli (vgl. 2007, 150–153) Brachy- und Tachygraphie (aus dem griechischen brachys für ‚kurz‘ und tachys für ‚schnell‘) genannt, werden schon lange vor dem Aufkommen und der Verbreitung der textbasierten CMC verwendet. Dies belegen Beispiele aus Texten vom Mittelalter bis in die heutige Zeit, wie Aff.mo für ‚affezzionatissimo‘ im Italienischen zeigt (vgl. Antonelli 2007, 151). Und auch für das Deutsche lassen sich unzählige Beispiele finden, wie die in Briefen verwendeten Abkürzungen z.Hd. ‚zu Händen‘, Hr. ‚Herr‘, Fr. ‚Frau‘ oder MfG ‚Mit freundlichen Grüßen‘. Durch die Einführung von Schreibmaschinen, gefolgt und abgelöst durch den Computer, hat sich der Schreibaufwand im Vergleich zu handgeschriebenen Texten deutlich reduziert. Gleichzeitig ist die Anzahl an verschriftlichten Texten gestiegen. Viele Abkürzungen der CMC sind gesellschaftlich akzeptiert und konventionalisiert. Sie werden, unabhängig von Faktoren wie Alter, Geschlecht, Medium oder dem sprachlichen und außersprachlichen Kontext verwendet; andere sind spezieller und werden häufig nur von einer bestimmten Gruppe oder in einer bestimmten Situation benutzt. Sie sind oft nicht nur zweckdienlich, sondern ihr Gebrauch hat oft spielerische und kreative Züge.
Nach Antonelli (vgl. 2007, 151–153) lassen sich Abkürzungen und Kurzschreibweisen in verschiedene Kategorien einordnen, die im Folgenden kurz erklärt und anhand von Beispielen aus Facebook belegt werden (Tabelle 11 zeigt vorab eine Übersicht).
| Abkürzende Schreibweisen | Italienisch | Deutsch |
| Kürzungen | gent. ‚gentile‘ | so ‚Sonntag‘ |
| Akronyme | tvb ‚ti voglio bene‘ | glg ‚ganz liebe Grüße‘ |
| Reduktion von Digrammen | ke ‚che‘ | |
| Konsonantische Kurformen | nn ‚non‘ | vllt ‚vielleicht‘ |
| Symbolische Schreibweisen | x ‚per‘ | + oder – ‚mehr oder weniger‘ |
| Leetspeak | 6 ‚sei‘ | N8 ‚Nacht‘ |
| Informal spelling | d ‚di‘, t ‚ti‘ | C ‚see‘ |
Unter Kürzungen (oder Substraktionen) sind entweder die sogenannten Kopf- oder Schwanzwörter gemeint. Bei den Kopfwörtern, den Apokopen, wird das Satzende gekürzt, wie beispielsweise bei it. mart. ‚Martedì‘ oder de. Di. ‚Dienstag‘. Bei den Schwanzwörtern, den Aphäresen, hingegen fällt der Wortanfang weg, wie bei it. bus ‚autobus‘. Häufig werden Kürzungen durch einen Punkt markiert, dieser ist aber – vor allem im Falle der CMC – optional geworden.
Diese Kürzungen sind auch in den Facebook Beiträgen zu finden, wie die Beispiele merc ‚Mercoledí‘ in (23) und u ‚und‘ in (24) zeigen, bei denen auch der Punkt zur Kennzeichnung der Abkürzung weggelassen wurde:
[FB 162177_868]
[…] io voglio andarci peró devi vedere per la scuola, vedi se la sera ci sono treni per linz e ti prendi il merc libero.Let me know
[FB 2310126_465]
Amsterdam u Düsseldorf „heart“-Emoticon
Bei Akronymen werden nur die Anfangsbuchstaben eines Wortes oder einer (idiomatischen) Phrase wiedergegeben. Bussmann (vgl. 2008, 1) unterscheidet zwischen Akronymen, die ausbuchstabiert und mit Endbetonung ausgesprochen werden, wie in DM ‚deutsche Mark‘, und Akronymen, deren Buchstaben silbischen Wert annehmen und die mit Anfangsbetonung ausgesprochen werden, wie Hiwi ‚Hilfswissenschaftler‘. Es gibt zudem Akronyme, deren Initialen phonetisch zu einem Wort zusammengefügt werden, wie in AIDS ‚acquired immune deficiency syndrome‘. Schließlich gibt es auch noch Mischformen aus Initial- und Silbenbildung, wie in BAföG ‚Bundesausbildungsförderungsgesetz‘ (ebd.). Auch in der CMC werden Akronyme aller Art verwendet. Im Italienischen wäre tvb ‚ti voglio bene‘ als Beispiel zu nennen, im Englischen wären asap ‚as soon as possible‘ und im Deutschen glg ‚ganz liebe Grüße‘ prototypische Beispiele dafür.97 Auch in den Facebook Beiträgen lassen sich Akronyme finden, wie lol ‚laughing out loud‘ in (25), tvb ‚ti voglio bene‘ in (26) und hdl ‚hab dich lieb‘ in (27) zeigen.
[FB 1301116_79]
hahahah ja ich weiß was du meinst….wollt auch schon was sagen „tongue“-Emoticon lol
[FB 1621287_1241]
..che bello sentirti oggi..tvb…
[FB 1211_81]
danke mau hdl
Die Reduktion von Di- oder gar Trigrammen sowie die symbolischen und konsonantischen Schreibweisen werden ebenfalls zu den abkürzenden Schreibweisen gezählt. In der Facebook Statusmeldung in (28) wird ein Zitat aus einem Werk von Neruda wiedergegeben bei dem verschiedene Wörter durch abkürzende Schreibweisen ersetzt sind.
(#2808)
È vietato piangere senza imparare nn sorridere ai problemi nn lottare x ciò ke vuoi abbandonare tt x paura dll vita e dei suoi compromessi sentire la mancanza d qlcn senza rallegrarsi dimenticare i suoi okki,la sua risata solo xké le vostre strade nn si incrociano+ dimenticare il tuo passato e pagarlo cn il tuo presente nn tentare di capire le xsn nn sapere ke ognuno ha il suo cammino e la sua gioia (Neruda).98
Unter Reduktion von Digrammen versteht man die Ersetzung von mehreren orthographisch realisierten Buchstaben, die aber in der Aussprache nur einem Laut entsprechen, durch einen einzelnen Buchstaben. Im Italienischen erfolgt solch eine Reduktion von Digrammen häufig, wenn <ch> als [k] realisiert wird, wie in ke ‘che’ oder okki ‘occhi’ (siehe Beispiel (28)).99
In dem Beispiel lassen sich auch Okkurrenzen von konsonantischen Schreibweisen feststellen, wie in nn ‘non’, tt ‘tutto’dll ‘della’ und qlcn ‘qualcuno’. Dabei werden die Vokale weggelassen und nur die Konsonanten ausgeschrieben. Denkbar wären auch vokalische Schreibweisen, die aber deutlich seltener zu finden sind. Von symbolischen Schreibweisen spricht man, wenn Wörter durch numerische oder arithmetische Zeichen ersetzt werden. In (28) ist das bei + ‘più’ oder x ‘per’ der Fall. In beiden Fällen werden mathematische Operatoren (hier sind es die Symbole für Addition und Multiplikation) verwendet. Im Italienischen kommt es auch häufig zu einer Kombination von verschiedenen verkürzenden Schreibweisen, wie bei xké ‚perché‘ oder xsn ‚persone‘ in (28).
Des Weiteren wird häufig auch der sogenannte Leetspeak zu den abkürzenden Schreibweisen gezählt. Dabei werden Buchstaben durch ähnlich aussehende Zahlen ersetzt, wie beispielsweise in 1337 ‚leet‘ (vgl. Marx & Weidacher 2014, 101). Aber auch das Ersetzen von Buchstaben oder Silben, die Zahlen lautlich gleichen, kann zu dieser Art der abkürzenden Schreibweisen gezählt werden. Ein Beispiel aus dem Italienischen wäre 6 ‚sei‘ und im Deutschen sowie Englischen n8 ‚nacht‘/‘night‘. Auch in Facebook Beiträgen lassen sich Okkurrenzen für den Leetspeak finden, wie das folgende Beispiel zeigt:
[FB 1921512_1334]
Amore 6 tornata?? I m waiting for u
Schließlich wird unter „informal spelling“ (Antonelli 2007, 152) oder auch „grafia compitale letterale“ (Berruto 2005, 144) das Ersetzen eines Wortes (oder einer Silbe) durch den entsprechenden Konsonanten, so wie er im Alphabet bezeichnet wird, verstanden. Ein Beispiel wäre im Italienischen d ‚di‘ und im Englischen c und u wie in c u ‚see you‘. Diese werden vor allem in den englischsprachigen Facebook Beiträgen verwendet, wie u ‚you‘ in (29) zeigt.
Es können somit alle oben eingeführten abkürzenden Schreibweisen in den Facebook Beiträgen belegt werden. In den ersten Jahren des Computers und Internets wurden Abkürzungen und Akronyme vor allem dazu verwendet Zeit und Kosten bei der Datenübertragung zu sparen. Allerdings spielt dieser Aspekt heutzutage durch die erhöhten Kapazitäten bei Datengröße und Übertragungszeit kaum noch eine Rolle. Auch die zeitliche Ersparnis bei der Produktion lässt sich kaum als Argument dafür anführen, da diese Ersparnis in Zeiten des Schreibens auf Tastaturen kaum ins Gewicht fällt. Akronyme dienen zum einen dazu, im Netz eine gewisse Gruppenidentität unter den Nutzern zu schaffen (vgl. Storrer 2000, 169), aber sie sind auch ein Ausdruck von kreativer und spielerischer Verwendung der Sprache, wie vor allem das Beispiel (28) gezeigt hat.
Es lässt sich in den Facebook Beiträgen allerdings eine Präferenz verschiedener Typen von abkürzenden Schreibweisen in den hier beschriebenen Sprachen Deutsch, Italienisch und Englisch feststellen. So lassen sich für das Deutsche nur schwer Beispiele der informal spelling finden; c ‚Zeh‘ wäre hier eine Möglichkeit, für die aber keine Okkurrenzen gefunden werden konnten. Des Weiteren kann die Reduktion von Digrammen vor allem als ein besonderes Merkmal der italienischen Sprache angesehen werden. Begründet werden kann das vor allem durch die morphologischen und phonetischen Besonderheiten der Sprachen.
Es kann also beobachtet werden, dass abkürzende Schreibweisen bewusst gewählt und eingesetzt werden. Andere Merkmale, deren Gebrauch ungeplant vorkommt, werden im Folgenden diskutiert.
3.2.2.4. Tippfehler, grammatikalische Unkorrektheiten
„Thanx to internet, my spelling sucks!!!“ und „Facebook killed my grammar“ (Lee 2011, 110) sind zwei gute Beispiele, die die Behauptung untermalen, dass in der CMC Rechtschreib- und Grammatikfehler keine Seltenheit sind. Dabei gilt es zu unterscheiden zwischen Tippfehlern, wie Buchstabenverdrehern, die auf das Schreiben mit Hilfe der Tastatur zurückzuführen sind, und echten Orthographie- und Grammatikfehlern. Als Grund für beide wird meist die Schnelligkeit und Flüchtigkeit mit der Nachrichten der CMC verfasst werden, genannt. So heißt es bei Storrer „[d]as erhöhte Aufkommen an schriftlicher Textproduktion wird vielfach dadurch kompensiert, daß [sic!] weniger Zeit in die sprachlichen Formulierungen und deren Kontrolle investiert wird.“ (Storrer 2000, 168). Schuld an den Fehlern sei somit nicht die mangelnde Kompetenz der Produzenten, sondern die Geschwindigkeit der Performanz. Allerdings lassen sich auch bei Kommunikationsformen, die geplant verfasst werden und somit auch meist einer erneuten Kontrolle des Geschriebenen unterliegen, sowohl Tippfehler, als auch grammatische und orthographische Unkorrektheiten feststellen. Am häufigsten sind dabei Buchstabenverdreher, wie uaf ‚auf‘ und bion ‚buon‘ in den Beispielen (30) und (31) zeigen:
[FB 1621_68]
Ich mag es uaf dem Boden […]
[FB 1021213_113]
[…] Bion Natale???
In diesem Kontext sollte auch erwähnt werden, dass meist komplett auf Majuskel verzichtet wird – auch zu Satzbeginn und auch in Sprachen wie dem Deutschen, in dem die Großschreibung bestimmte Wortarten markiert und visuell hervorhebt. Als Gründe für den Verzicht auf die Großschreibung können wieder Zeit- und Arbeitsersparnis genannt werden – schließlich muss dafür die Shift-Taste in Kombination mit der Buchstabentaste gedrückt werden. Diese durchgängige Minuskelschreibung hat sich mittlerweile in vielen Formen der CMC etabliert und ist auch in Facebook Beiträgen zu finden, wie (32) zeigt, wo bis auf das K in Küsse sowohl Satz initiale Wörter, als auch Nomen kleingeschrieben sind.
[FB 102153_304]
hallo!!!!!!kommst du morgen für die prüfung?????????das ist um 4.00 in dem normalen raum.Küsse
Zu den Tippfehlern lässt sich auch die fehlerhafte oder spärliche Verwendung von diakritischen Zeichen zählen. Allerdings ist diese meist darauf zurückzuführen, dass diese Zeichen häufig nicht auf der verwendeten Tastatur produziert werden können. So unterscheiden sich die deutsche und die italienische Tastatur dahingehend, dass darauf entweder nur die diakritischen Zeichen der einen oder der anderen Sprache angeboten werden.
[FB 1021_70]
neue Farbe fuer mein Zimmer!
Ein Umschalten von einer Tastaturversion auf eine andere oder die Darstellung von Diakritika über Tastenkombinationen setzt einen gewissen Zeit- und Arbeitsaufwand voraus, weshalb häufig darauf verzichtet wird. Allerdings lässt sich aber auch beobachten, dass es manchmal zu einer fehlerhaften Verwendung kommt, wie das Beispiel in (34) zeigt, in dem der Produzent einen Gravis anstelle eines Akuts in perchè ‚perché‘ verwendet. Auch die Darstellung mit Hilfe von anderen Zeichen, wie dem Apostroph, ist häufig zu beobachten, wie e´ ‚è‘ in (35) demonstriert.
[FB 1021221_142]
Ciao albi,domani non ci sono per la partita perchè tornerò da Torino verso le 20.00…grazie lo stess alla prox!
[FB 102130_11]
Ho visto l´annuncio.. e´ semplicemente geniale!!!! mi vien voglia di imparare l´italiano! „grin“-Emoticon
Auf alle Fälle sollte unterschieden werden, wann es sich um Fehler – egal welcher Sorte – oder geplante und gewollte Zeichenkonventionen handelt. Außerdem sollte differenziert werden, ob beispielweise abweichende Schreibweisen auf mangelnde Kompetenz oder die Contraints, die die verwendeten Medien mit sich bringen, zurückzuführen sind. Schließlich dienen diese Schreibweisen häufig auch der Emphatisierung oder stellen einen innovativen Gebrauch der Sprache dar. So wird im Italienischen die Ersetzung von <c> durch <k> , wenn es sich dabei um den Laut [k] handelt, häufig von Internetnutzern als mangelnde orthographische Kompetenz kritisiert, obwohl sie in den meisten Fällen bewusst von den Nutzern eingesetzt wird und so eher einen speziellen Gebrauch der Sprache in den CMC reflektiert.
Es konnte hier also an den Belegen aus den Facebook Beiträgen gezeigt werden, dass nicht nur nichtsprachliche Kommunikationsmittel in der CMC eingesetzt werden, sondern auch parasprachliche, wie beispielsweise Inflektive und Phoneticons. Aber auch Schreibweisen, die in ihrer Gestalt und Erscheinung das Schriftbild der CMC prägen, wie Abkürzungen und Tippfehler, wurden hier vorgestellt. Es lassen sich schließlich auch auf sprachlicher Ebene Merkmale finden, die als typisch für die CMC erachtet werden, und im nächsten Abschnitt umrissen werden sollen.
3.2.3. Sprachliche Merkmale der CMC
Es gibt eine Vielzahl an sprachlichen Merkmalen, die als typisch für die CMC erachtet werden. Hier soll im Folgenden nur eine Auswahl von den Besonderheiten wiedergegeben werden, die in den Facebook Beiträgen besonders hervorstechen und darin häufig Verwendung finden.
3.2.3.1. Grußformeln, Vokative und Gesprächspartikel
In der CMC ist die Frequenz von Grußformeln, Vokativen und Gesprächspartikeln sehr groß (vgl. Antonelli 2007, 148, Berruto 2005, 150, Storrer 2007, 52). Diese werden dabei häufig als Merkmale der gesprochenen Sprache, „tratti tipici del parlato“ (Berruto 2005, 150), hervorgehoben.
Zu den Grußformeln zählt man Phraseologismen, die eine Kommunikation initiieren oder beenden und die in Form von Begrüßungs- oder auch Abschiedsformeln daherkommen. Dazu zählen beispielsweise im Deutschen hallo, wie geht’s oder tschüss und im Italienischen ciao, che fai? oder dove sei?. Unter Vokativen sollen hier Anrede- und Anrufformen verstanden werden, die die Form eines Nomens (oder einer Nominalphrase) haben und häufig Spitznamen oder Hypokoristika, also Kosenamen, darstellen.100 Diese treten auch häufig in Kombination mit Grußformeln auf, wie beispielsweise in de. hallo Schatz oder it. ciao bella.
Auch in den Facebook Beiträgen lassen sich sehr viele Okkurrenzen für Grußformeln und Vokative finden. Diese treten oft kombiniert auf, wie hey suesse in Beispiel (36) und ciao bella in Beispiel (37) zeigen. Allerdings sind Begrüßungsformeln deutlich frequenter als Abschiedsformeln.
[FB 111264_132]
hey suesse! habe doch keinen laptop und damit kein internet, […]
[FB 2310148_232]
ciao bella!sitzt best. grad im pub, gell?[…]
Es kann auch noch bemerkt werden, dass Grußformeln öfter in Facebook Posts als in Facebook Statusmeldungen auftreten, da hier meist ein bestimmter Facebook Nutzer gemeint ist und damit direkt angesprochen wird. In den Letzteren sind Anreden und Begrüßungen, die sich an mehrere Personen oder eine bestimmte Personengruppe richten, frequent, wie Beispiel (38) zeigt.
[FB 1211_172]
Hallo allerseits…Ciao a tutti..
Neben einer Vielzahl an Vokativen und Grußformeln lassen sich auch Gesprächswörter in der CMC beobachten, wie gell in Beispiel (37) zeigt. Unter Diskursmarkern oder Gesprächswörtern versteht man sprachliche Ausdrücke, die den Diskurs strukturieren. Diese sind zum einen „satzzusammenhang-unabhängig“ und gleichzeitig „satzwertig“ bzw. „satzassoziiert“ (Henne 1978, 46). Dazu gehören Gliederungspartikel, zum Beispiel nicht, gell, ja, die das Gespräch gliedern und gleichzeitig Zustimmung einfordern (vgl. Henne 1978, 45), Rückmeldungspartikel (en. back channel), wie genau, hm, richtig, mit denen der Angesprochene seine Gesprächsbereitschaft signalisiert (ebd.) sowie Interjektionen, wie oh, ach, hopsa, die sich nicht in den grammatischen Zusammenhang eines Satzes einordnen lassen (vgl. Henne 1978, 44). Manchmal werden auch Modalpartikel zu der Klasse der Gesprächswörter gezählt (vgl. Abraham 1991).
Gesprächswörter dienen als Pausenfüller oder Affirmative, sie geben Hörersignale wieder, drücken Wünsche oder Verwünschungen aus. Zudem können sie eine expressive Funktion innehaben, also Freude oder Schmerz ausdrücken. Zudem können sie eine appellative Funktion haben, leiten also Drohungen ein, dienen der Kontaktaufnahme („phatische Funktion“) und können Laute verschiedener Art imitieren (‚schallnachahmende Funktion“) (Burger 1980, 62).
Gesprächswörter werden auch in der CMC verwendet. Berruto (2005, 150) unterteilt diese in solche, die als Pausenfüller dienen, wie ehm, bah, no, und in Affirmative, wie sì, certo, vabbè. Außerdem zählt er noch Hörersignale, wie ecco, cioé sowie Unterbrechungen oder phatische Ausdrücke, wie eh, sai, dazu.101
In den Facebook Beiträgen lassen sich ebenfalls Gesprächspartikel aller Art finden – nicht nur im Italienischen, wie ehm in Beispiel (39), ecco in (40) und vabbé in (41), auch im Deutschen, wie gell in (37) und ach, wow, naja und hehe in (42).
[FB 192115_25]
…ehm..io!!!
[FB 1621198_762]
Ecco adesso ti scrivo qui…„smile“-Emoticon
[FB 2001_180]
vabbé — dico niente
[FB 2101116_60]
ach habs gerade gesehen.. wow da musst du dich aber ranhalten… naja es gibt ja noch las vegas hehe
Schlussfolgernd lässt sich festhalten, dass Gesprächswörter, Vokative und Grußformeln in den Facebook Beiträgen häufig und regelmäßig verwendet werden.
3.2.3.2. (Morpho-)syntaktische Strukturen zur Hervorhebung
Es gibt einige (morpho-)syntaktische Besonderheiten, die typischerweise bei der Beschreibung der CMC genannt werden. Für das Italienische nennt Antonelli (vgl. 2007, 12–13) beispielsweise die Verwendung von gli anstelle von ‚a lei‘ oder ‚a loro‘, fehlende Konjunktivformen oder Dislokationen. Berruto (vgl. 2005, 148) spricht zudem von einer „generale frammentazione sintattica“, zu der er Topikalisierungen, Dislokationen nach rechts und nach links, Ellipsen, und eine Häufung von Nominalphrasen nennt; außerdem werden komplexe Tempusformen und Subordinationen deutlich seltener verwendet. Für das Deutsche kann hier zum einen das Weglassen von Pronomen genannt werden (vgl. Marx & Weidacher 2014, 104), aber auch Assimilationen, wie in hast dus ‘hast du es’, kannste ‘kannst du’, bei denen eine lautliche Anpassung durch Tilgung mit gleichzeitiger Morphemverschmelzung erfolgt (vgl. Marx & Weidacher 2014, 113).
In den Facebook Statusmeldungen finden sich auch Beispiele für oben genannte morphosyntaktische Besonderheiten. Für das Italienische lassen sich zusätzlich noch einige Okkurrenzen für den Gebrauch des c’èpresentativo nennen, wie er in Beispiel (43) verwendet wird.
[FB 1211130_1023]
ciao ciccina, c’e una cugina che vuole la tua amicizia
Ein häufiges Fehlen von Konjunktivformen lässt sich allerdings nicht verifizieren. Zwar gibt es auch Fälle, in denen anstelle der Konjunktivform die Indikativform verwendet wird, aber diese sind eher Ausnahmen (siehe (44)).
[FB 210166_26]
Ciao Lea come stai????Spero che ti sei ripresa da febbre e dolori!!!!!„wink“-Emoticon KISS
Fehlende Pronomen werden dafür in den deutschsprachigen Beiträgen sehr häufig verwendet, wie die Beispiele (45) und (46) demonstrieren, bei denen jeweils das Pronomen ich weggelassen wurde.102
[FB 1211_782]
bin stolz auf meine beiden schätze
[FB 2101116_121]
Hab gerade eure letzten Kekse aufgegessen
Sicherlich ließen sich hier noch viele weitere Beispiele und Besonderheiten in den Facebook Beiträgen finden, die allerdings eine genauere Betrachtung und Beschreibung erfordern würden. Auch auf der Ebene der Morphologie lassen sich hier, gerade bei der Wortbildung, weitere Besonderheiten feststellen, die aber häufig auf die Verwendung fremdsprachlicher Elemente zurückzuführen sind.
3.2.3.3. Plurilingualismus
Ein häufig genanntes Charakteristikum der CMC ist der dort vorherrschende Pluri- oder Multilingualismus. Dieser kann sich zum einen auf die innere Mehrsprachigkeit, also den Reichtum an verschiedenen Varietäten, die ein Sprecher einer Sprache verwenden kann, beziehen (vgl. Tracy 2014, 18). Dabei werden grammatische und lexikalische Elemente aus einer sprachlichen Varietät in eine andere eingefügt (Matrixvarietät, siehe Krefeld (2016)). Das betrifft fast alle Ebenen des Diasystems.103 Dabei sticht jedoch besonders die diatopische Dimension hervor, bei der Elemente aus verschiedenen regionalen und dialektalen Sprachvarietäten übernommen werden (vgl. Berruto 2005, 152–153). Krefeld (2016, 1) führt hierzu den Begriff der Matrixvarietät ein und merkt diesbezüglich an, dass „esclusivamente lo standard e il dialetto sono idiomi che possono fungere da ‘varietà matrice’ del discorso, nelle quali spiccano eventualmente varianti marcate.”104
In den Facebook Statusmeldungen lässt sich ebenso die Verwendung von Dialekten beobachten. Sowohl im Italienischen als auch im Deutschen werden Beiträge in regionalen Varietäten veröffentlicht, wie das Beispiel aus dem Sizilianischen in (47) und das Beispiel (48) aus dem Schwäbischen zeigen.
(1126)
‚Nna picciuttedda ca ti voli beni, sulu ’n Sicilia tu la poi truvari; lu cori d’amurusi peni idda sultantu sapi cunsulari 105
[FB 1211_282]
Für älle wo’s läsa kennad…:Do poschtet ewel ebbe..
Neben den verwendeten Varietäten einer Sprache, lassen sich außerdem häufig fremdsprachliche Elemente in der CMC finden. Dabei spielt vor allem das Englische eine wichtige Rolle (vgl. Antonelli 2007, 13–18, Berruto 2005, 152). Aufgrund der Dominanz der USA in Wirtschaft, Forschung und Entwicklung, Mode und Musik, aber auch in der Politik, hat sich die angloamerikanische Sprache auf der ganzen Welt verbreitet (vgl. Schlobinski & Siever 2005, 3).106 Das Englische wird häufig durch die Schriftsprache verbreitet, beispielsweise durch die Presse und andere Printmedien, aber auch durch die Werbung fließt fremdsprachliches Material mit in die Sprache ein.107 Seit ihrer Erfindung und Verbreitung tragen schließlich auch der Computer und das Internet zur Verbreitung des Englischen bei, was sich auch in der CMC widerspiegelt (vgl. Gianni 1994 und Fanfani 2003 für das Italienische und Schlobinski & Siever 2005 für das Deutsche). Die sogenannten Anglizismen (darunter werden Britizismen und Amerikanismen, also sowohl Einflüsse aus dem britischen als auch dem amerikanischen Englisch, zusammengefasst) treten auf verschiedenen linguistischen Ebenen auf; am Häufigsten sind dabei wohl lexikalische Entlehnungen. Diese können aber ebenso auf der morphologischen, graphematischen oder syntaktischen Ebene stattfinden. Der Grad der Integration in die entlehnende Sprache variiert dabei.
Die Definitionen von Lehngut gehen zumeist auf den deutschen Sprachwissenschaftler Betz (1959) zurück. Er unterscheidet dabei verschiedene Arten von fremdem Material.
Ein solcher Begriff, ein solches Wort kann auf dreifache Weise übernommen werden: entweder wird das fremde Wort übernommen, dabei in seiner fremden Lautgestalt bewahrt (Subjekt, Palais) bzw. lautlich der eigenen Sprache angepaßt (Kirche, Pfalz), oder es wird mit dem Material der eigenen Sprache nachgebildet (Gewissen, Barmherzigkeit, Umwelt), oder es wird nur die Bedeutung des fremden Wortes für ein Wort der eigenen Sprache entlehnt (Gott, Geist, Seele, Gnade). (Betz 1959, 128)
Die drei daraus resultierenden Begriffe Lehnwort, Lehnbildung und Lehnbedeutung unterteilt Betz in inneres Lehngut (Lehnwort) sowie äußeres Lehngut (Lehnbildung und Lehnbedeutung). Das innere Lehngut oder die „lexikalischen Entlehnung“ (Blasco Ferrer 1994, 55) können unterteilt werden in Fremdwörter, also Wörter bei denen die „fremde Lautgestalt bewahrt“ wird, und Lehnwörter im eigentlichen Sinne, bei denen die Lautgestalt angepasst wird (vgl. Betz 1959, 128). Auch Blasco Ferrer (1994, 56) greift augenscheinlich diese Klassifikation auf und unterscheidet bei Lehnwörter zwischen forestierismo ‚Fremdwort‘ und prestito ‚Lehnwort (im engeren Sinn). Auch hier erfolgt die Zuweisung basierend auf dem Grad der (lautlichen und morphologischen) Assimilation.
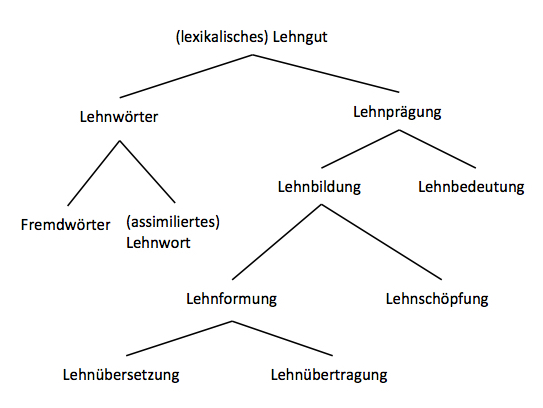
Fremdsprachliche Entlehnungen nach Betz (1959, 128)und nach Blasco Ferrer (1994, 56).
(Lizenz: CC BY SA)
Auch in der CMC finden sich Lehnwörter, sowohl im Deutschen als auch im Italienischen. Nach Zimmer (1997, 60) lassen sich dabei nur bestimmte aus dem Englischen übernommene Verben in die Morphosyntax des Deutschen integrieren:
[…] testen, tunen, clonen, outen bewegen sich fast auf Anhieb frei in der deutschen Syntax, wohl weil sie zufällig fast den Regeln der Morphembildung und der Laut-Buchstaben-Beziehung entsprechen und auch der Aussprache keine nennenswerten Schwierigkeiten bereiten.(Zimmer 1997, 60)
Bei anderen Verben sei das nicht so einfach oder sogar unmöglich, wie es beispielsweise bei to sightsee und to layout der Fall ist: „Sie sightseete? sightsaw? sightsah?“ sowie „Wer hat das gelayouted? gelayoutet? outgelayed? outgelayt? outlayed?“ (Zimmer 1997, 60).108 Das Konjugationsproblem lasse sich nun nicht durch Abwarten lösen, „indem man den englischen Verben nur genug Zeit läßt, sich in unserer Sprache häuslich einzurichten. Das Verb, das sich nicht gleich einrichtet, richtet sich nie ein.“(Zimmer 1997, 61). Aber auch für das Italienische kann man dieses Phänomen beobachten. Zwar führen englische Wörter oder Phrasen häufig zu einer Verwendung von Lehnbildungen, wie die Beispiele it. finestra en. ‚windows‘ und it. cartella en. ‚directory‘ zeigen (Antonelli 2007, 21). Aber auch hier können englischstämmige Wörter morphologisch angepasst und somit in das Italienische integriert werden, wie it. scannerizzare en.‚to scan‘ oder it. cliccare en. ‚to clic‘ demonstrieren.
In Zimmer (1997, 86–104) findet sich schließlich eine Liste der „[h]undert Computerbegriffe in zehn europäischen Sprachen“, die zeigt, dass sowohl im Deutschen als auch im Italienischen in vielen Fällen unassimilierte Wörter und durch Lehnschöpfung, Lehnübersetzung und Orthographie assimilierte Wörter, wie beim engl. computer de. ‚Computer, Rechner‘, it. ‚computer, calcolatore, elaboratore‘, koexistieren (vgl. Zimmer 1997, 86).109 Die Auszählung und der Vergleich von assimilierten und nicht-assimilierten Wörtern lassen den Schluss zu, dass der Computerjargon im Deutsch und Italienischen stark anglisiert ist (ebd.).110
Auch in den Facebook Beiträgen gibt es eine große Vielzahl an Lehngut; das meiste aus dem Englischen, aber auch aus anderen Sprachen. Um welchen der oben beschriebenen Typen es sich dabei handelt, muss für jede Okkurrenz entschieden werden. So enthält Beispiel (49) ein assimiliertes Lehnwort: chillst (aus dem Englischen ‚to chill‘ mit der deutschen Verbindung –st). In Beispiel (50) stellt In den Wolfsmund eine Lehnübersetzung des Italienischen ‚in bocca al lupo‘ (de. ‚viel Glück‘) dar.
[FB 221129_51]
HEy Süße! Ich komm aus dem Skiurlaub und du chillst schon fast in der Sonne! […]
[FB 231084_58]
In den Wolfsmund cara!!! ich denk an dich! Küßchen
Schließlich lassen sich in der CMC häufig auch Sprachmischungen finden, in denen nicht nur einzelne Wörter aus einer anderen Sprache in einen ansonsten monolingualen Beitrag eingefügt werden, sondern tatsächlich sprachliche Elemente in einem einzelnen Beitrag gemischt werden. Dieses Phänomen, das sogenannte Code-Switching, soll in Kapitel ausführlicher diskutiert und erläutert werden, und findet hier nur der Vollständigkeit halber Erwähnung.
3.2.4. Merkmale der CMC als Merkmale der Mündlichkeit?
Wie die vorangehenden Unterkapitel zeigen, lässt sich die Existenz von verschiedene Merkmalen, die als typisch für die CMC gelten, auch in den Facebook Beiträgen belegen. Es wurde dabei auch immer wieder darauf verwiesen, dass einige dieser Merkmale „die gesprochene Sprache imitieren“, es sich dabei um Merkmale handelt, die aus dem „Gesprochenen übernommen“ wurden. Das lässt den Schluss zu, dass die CMC am Pol der Nähesprache zu verorten sei, als konzeptionell gesprochen, wie in Kapitel diskutiert. Dafür spricht, dass in der CMC häufig Merkmale der Dialogizität, wie Gesprächswörter, Inflektive und Grußformeln auftauchen. Auch die Verwendung von graphematischen Mitteln, um solche nichtsprachlichen und parasprachlichen Mittel zum Ausdruck von Emotionen zu substituieren, die in einer Face-to-Face-Kommunikation an Mimik und stimmlichen Eigenschaften der Sprecher abgelesen werden können, spricht für eine Verortung der CMC im Bereich der Nähesprache. Zudem können Tippfehler als Zeichen für Spontaneität oder geringen Planungsaufwand gewertet werden und die Tatsache, dass Koordinationen den Subordinationen vorgezogen werden, spricht für eine geringere Komplexität. Diese Schlussfolgerungen wiederum können als Merkmale der Nähesprache gewertet werden.
Allerdings gibt es hier dann doch einen großen Unterschied. Nämlich den, dass diese Merkmale bewusst und geplant eingesetzt werden (manchmal sogar die Tippfehler) und nicht wie beispielsweise bei der Face-to-Face-Kommunikation, im Unterbewusstsein entstehen. Dabei ist hervorzuheben, dass die Verwendung vieler der genannten Merkmale auf die gegebenen Affordanzen und Constraints des Medienkomplexes sowie des Kommunikationsmediums zurückzuführen sind, ihre Verwendung also durch diese erst ermöglicht wird. Dieser mediale Aspekt wird aber in dem Modell des Nähe-/Distanzkontinuums gar nicht berücksichtigt (siehe Kapitel ). Häufig ist der Gebrauch dieser CMC spezifischen Merkmale auf eine kreative und spielerische Sprachverwendung zurückzuführen, was wiederum für hohen Planungsaufwand und Komplexität spricht – die ihrerseits als Merkmale der Distanzsprache gelten.
Schließlich ist auch eine Transferenz zwischen dem medial graphischen und phonischen ausgeschlossen, denn obwohl sich die CMC wohl Ersterem zuordnen ließe, können Beiträge kaum oder nur unter Hinnahme eines inhaltlichen Verlusts ins medial phonische übertragen, also vorgelesen, werden. So könnte bei der Versalienschreibung oder der Verwendung von Phoneticons zwar die Stimme erhoben werden (genauso wie bei Emoticons während des Vorlesens die entsprechende Mimik dazu gemacht werden könnte), aber wie gerade gesehen, sind die Funktionen viel komplexer. Die Verwendung von Buchstabeniteration und Versalienschreibung bedeutet nicht zwangsläufig, dass hier eine Anhebung der Lautstärke oder die Längung eines Lautes gemeint ist; oftmals dient dies nur der Emphase oder drückt eine emotionale Beteiligung aus. Und auch bei den Emoticons wurde gezeigt, dass zwar einige Emoticons Mimik widerspiegeln sollen, aber sie erfüllen durchaus noch andere Funktionen und tragen Bedeutungen, die eben nicht so einfach durch sprachliche oder nichtsprachliche Mittel imitiert werden können, da so der Facettenreichtum dieses verwendeten Merkmals dabei verloren gehen würde.
Zusammenfassend kann gesagt werden, dass auch die Facebook Nutzer bewusst Strategien verwenden, die ihnen durch die vom Computer gegebenen Möglichkeiten zur Verfügung gestellt werden, um ihre textbasierten Beiträge mit non- und parasprachlichen Kommunikationsmitteln anzureichern. In den Facebook Beiträgen zeigt sich dabei, dass bei den parasprachlichen Merkmalen kaum Inflektive gefunden werden können, dafür verschiedene Mittel Prosodie um auszudrücken, wobei vor allem Phoneticons häufig anzutreffen sind. Aber auch die Anzahl der abkürzenden Schreibweisen ist recht hoch. Während die Phoneticons häufig das Sprachliche begleiten und eine qualifizierende oder emphatisierende Funktion haben, können die abkürzenden Schreibweisen durchaus mit einer Zeitersparnis bei der Produktion begründet werden. Allerdings kann dieser Grund hier nur eine untergeordnete Rolle spielen, denn wie schon bei den nichtsprachlichen Kommunikationsmitteln gesehen und wie auch die Ausgestaltung von prosodischen Merkmalen zeigt, sind diese geplant und die Merkmale der CMC werden bewusst eingesetzt. Des Weiteren konnte bei den Emoticons gezeigt werden, dass diese auch in den Facebook Beiträgen frequent sind und Funktionen verschiedener Art erfüllen können – vom Ausdruck des emotionalen Status der Nutzer bis hin zu einer strukturierenden und emphatisierenden Funktion. Zudem wurde auch eine häufige Verwendung von Grußformeln, Vokativen und Gesprächswörter in den Facebook Beiträgen beobachtet, ebenso wie spezielle morpho-syntaktischen Strukturen und eine kreative Verwendung von fremdsprachlichen Elementen. Im nächsten Kapitel soll schließlich das Phänomen des Code-Switchings besprochen sowie Studien, die dieses in Hinblick auf die CMC untersucht haben, vorgestellt werden.
4. Code-Switching in der CMC
Seit vielen Jahrzehnten ist das Phänomen des Sprachwechsels ein fester Bestandteil der Mehrsprachigkeitsforschung. Generell versteht man darunter das Wechseln von einer Sprache zu einer anderen bei bi- oder plurilingualen Sprechern.111 Sprachwechsel galten lange Zeit als Zeichen für eine mangelnde sprachliche Kompetenz der Sprecher, und auch heute noch sind Begriffe wie Spanglish, Portuñol oder Denglisch negativ konnotiert. Den Sprechern werden dabei mangelnde Grammatikkenntnisse oder lexikalische Lücken in einer der beiden (oder gar beiden) Sprachen unterstellt. Ein Grund dafür ist, dass der Grammatikbegriff von vielen Sprechern als präskriptiv aufgefasst wird und Sprachwechsel somit eine Verletzung dieser Grammatik darstellen, vor allem bei typologisch sehr unterschiedlichen Sprachen (vgl. Bullock & Toribio 2009a, 1-4). Heute ist man sich weitgehend einig, dass Sprecher nicht nur wegen zu geringer Kompetenz in einer der Sprachen zu ihrer anderen wechseln (wie es beim Language Shifting der Fall ist, siehe Kapitel ), sondern dass dahinter spezielle Kompetenzen oder Strategien bi- oder plurilingualer Sprecher stehen. Die Frage, wieso Sprecher von einer Sprache in eine andere wechseln, beantwortet Montes-Alcalà (2007, 169) schlicht und einfach mit der Aussage “because they can”.
Die Geschichte der CS-Forschung lässt sich in verschiedene Etappen einteilen: Ausgehend von einem soziolinguistischen Ansatz, über die Fomulierung von grammatischen Restriktionen, bis hin zu einer Berücksichtiung sozialer und pragmatischer Aspekte, wurde schon ein langer Weg zurückgelegt. Zu Beginn der Erforschung von Sprachwechselphänomenen standen vor allem die sozialen und pragmatischen Funktionen des Sprachwechsels im Vordergrund (vgl. Blom & Gumperz 1972, Gumperz & Hymes 1972, McClure 1981, Valdés Fallis 1976). Die Forscher waren sich jedoch schnell Einigkeit, dass es strukturelle Beschränkungen geben muss, was sie anfangs zunächst mit Hilfe von Akzeptabilitätsurteilen von Sprechern untermauerten (vgl. Gumperz 1977, Timm 1975). Die daraus abgeleiteten strukturellen Regeln und Restriktionen konnten aber nicht als universell angesehen werden, da sie sehr stark von der untersuchten bilingualen Sprechergemeinschaft abhängen (vgl. Pfaff 1979). Es wurden später weitere auf strukturellen Regularitäten basierende Modelle und Beschränkungen vorgeschlagen, die mit Daten spontaner Sprache belegt wurden und die nicht zuletzt dank der Popularität der Aufsätze von Pfaff (1979), Poplack (1980) und Sankoff & Poplack (1981) die Forschung in diesem Bereich vorantrieben. Diesen strukturellen Beschränkungen liegen prinzipiell zwei Ansätze zu Grunde: Bei dem ersten und am häufigsten vertretenen Ansatz wird davon ausgegangen, dass der Sprachwechsel von einer dritten Grammatik gesteuert wird. Nach dem zweiten Ansatz sind nur zwei Grammatiken daran beteiligt.112 Nach dem ersten Ansatz können Sprachwechsel nur durch die Interaktion mit den Grammatiken der anderen beteiligten Sprachen erfolgen. Valdés beschreibt dies mit einer Metapher:113
By alternating between their languages, bilinguals are able to use their total speech repertoire, which includes many levels and style modes of speaking in two languages. It is helpful to imagine that when bilinguals code-switch, they are in fact using a twelve-string guitar, rather than limiting themselves to two six-string instruments. (Valdés Fallis 1988, 126)
Zu den Autoren, die von solch einem Ansatz ausgehen, gehören unter anderem Poplack (1980), Sciullo, Muysken & Singh (1986) oder Myers-Scotton (1993). Seit den 90er Jahren wird hingegen oft angenommen, dass es keine spezifischen Regeln oder Beschränkungen für Sprachwechsel gibt, sondern dass hier dieselben Regeln, die auch für die anderen beteiligten Sprachen gelten, vorherrschen. Zu den Autoren, die diesen zweiten Ansatz vertreten, zählen unter anderem Belazi & Rubin & Toribio (1994). Trotz der Bemühungen, universell gültige Restriktionen für CS aufzustellen, zeigte sich, dass diese meist nur für ein bestimmtes Sprachenpaar oder gar einen bestimmten Sprecher hielten.
Bei den Arbeiten dieser Art werden oft die kommunikativen und diskursrelevanten Funktionen, die ein Wechsel mit sich bringt, außen vor gelassen. Auch Auer (1984, 1–2) merkt an, dass “code-switching is not merely a matter of linguistic well-formedness – it also has communicative content left unexplained by the analysis of syntactic surface constraints” und plädiert dabei für eine interaktionelle Perspektive bei der Analyse der Bedeutung einzelner Sprachwechsel. Es folgten in den letzten Jahren weitere Ansätze um das Phänomen zu beschreiben, beispielsweise ausgehend von einem psycholinguistischen (vgl. Kutas & Moreno 2009, Wei 2009) oder konstruktionsgrammatischen Ansatz (vgl. Wasserscheidt 2014, 2016).
Trotz oder gerade wegen der verschiedenen Forschungsansätze gibt es die meisten Kontroversen schon im Vorfeld der Untersuchungen, nämlich bei der Frage nach der Verwendung des richtigen Fachterminus und dessen Abgrenzung zu anderen Phänomenen aus der Sprachkontaktforschung. Ausgehend von dem verwendeten Ansatz, definiert so jeder Autor für sich, was er unter Code-Switching, Sprachwechsel, etc. versteht. Deshalb muss auch hier zuallererst eine geeignete Definition für Code-Switching (CS) erarbeitet werden. Dafür werden zunächst die Begriffe Code-Switching und Sprachwechsel synonym als Oberbegriffe verwendet, um nach einer Einführung und kurzen Diskussion anderer in diesem Zusammenhang verwendeter Begriffe eine geeignete Interpretation zu präsentieren.
Bei der Beschreibung von Sprachwechseln in der CMC eignet sich vor allem eine soziolinguistische und pragmatische Herangehensweise, um so die Besonderheiten dieser Kommunikationsform hervorzuheben. Dafür sollen zunächst verschiedene strukturelle Typisierungen, nach denen CS untergliedert werden kann, vorgestellt werden. Diese bilden die Grundlage für eine spätere Datenanalyse. Im Anschluss daran sollen Funktionen verschiedener Art, die im Hinblick auf CS von verschiedenen Autoren vorgeschlagen wurden, und die sich mittlerweile innerhalb der Sprachkontaktforschung etabliert haben, präsentiert werden. Es wird darauffolgend der aktuelle Stand der Forschung hinsichtlich von CS in der CMC dargestellt und die wichtigsten Erkenntnisse und Ergebnisse zusammengefasst. Davon ausgehend werden die Fragestellungen und Hypothesen für die vorliegende Arbeit abgeleitet und vorgestellt.
4.1. Begriffsklärung und Definition
Code-Switching, Code-Mixing, Language-Switching, Style-Shifting, Language-Shifting, Code-Shifting: im Zusammenhang mit dem Sprachwechsel kommt es zu einem regelrechten „Begriffs-Switching“.114
Sometimes the problem is that researchers use different terminology for data that are in essence the same, but in other cases researchers appear to be investigating different phenomena alltogether […]. (Treffers-Daller 2009, 58)
Es ergeben sich also zwei Probleme: Ein und dasselbe Phänomen wird mit verschiedenen Termini beschrieben und ein, und derselbe Begriff wird für völlig verschiedene und häufig auch kontroverse Phänomene verwendet.115 Außerdem ist es schwer, die große Bandbreite an phonologischen, morphologischen, syntaktischen und semantischen Elementen, die von einer Sprache in die andere übertragen werden können, mit einem Begriff zu erfassen. Daraus folgt, dass je nach linguistischer Betrachtungsweise in der gängigen Literatur verschiedene Begriffe für diese geswitchten Elemente vorgeschlagen werden (vgl. Treffers-Daller 2009, 59).
Zunächst soll deshalb geklärt werden, was Code in dem Begriff Code-Switching bezeichnet und im Anschluss daran, was unter Switching verstanden wird, um ein umfassendes Bild der gängigen Forschungsliteratur und der verwendeten Termini zu erhalten.116 Dies führt schließlich zu der Definition des Begriffs, der dieser Arbeit zugrunde gelegt werden soll.
4.1.1. Language, Code und Style
Häufig wird der Begriff CS dazu verwendet, nicht nur das Wechseln von Sprachen, sondern auch von Sprachvarietäten miteinzubeziehen. Code (oder auch ‚Kode‘) bedeutet hier dabei zum einen ‚Sprache‘ im Sinne einer ausgebauten Schriftsprache, und zum anderen auch ‚Varietät‘ (im Sinne von Dialekten) (vgl. Riehl 2004, 19–20).117 Auch Alvarez-Cáccamo (1998, 34) bemerkt, dass “[p]ractically all research on ‘code-switching’ has been based on the identification of ‘code’ and ‘linguistic variety’ as interchangeable notions”.
Ein Code ist in der Regel ein in sich selbstständiges und geschlossenes Set von Merkmalen, das gegenüber einem anderen Set bedeutungsunterscheidend ist. Das kann ein nach außen hin unterschiedlich wirkendes Merkmalsset sein, wie es bei Sprachen der Fall ist, es kann sich dabei aber auch um eines handeln, das von den Kommunikationsteilnehmern selbst als eigenständiger Code wahrgenommen wird (vgl. , Androutsopoulos & Hinnenkamp 2001). Es kann zwischen Sprachen gewechselt werden, beispielweise vom Italienischen ins Deutsche und umgekehrt (vgl. Cantone 2005, Krefeld 2004, Müller & Gil Arnaus & Eichler & Geveler & Hager & Jansen & Patuto & Repetto & Schmeißer 2015). Es kann sich beim CS aber auch um den Wechsel zwischen Dialekt(en) und Standard handeln, beispielsweise das Wechseln zwischen Schweizer Dialekten und dem Schweizerstandarddeutschen (vgl. Siebenhaar 2005, 2006) oder dem Wechseln zwischen dem Marokkanischen Arabisch und seinen Dialekten (vgl. Ackermann 2007). Der Wechsel kann nicht nur zwischen diatopischen Varietäten stattfinden, sondern auch auf allen anderen Ebenen des Diasystems; also auch auf der Ebene der Diaphasik und der Diastratik. Diese letzten beiden Typen sind dabei strenggenommen keine Phänomene bilingualen Sprechens, sondern betreffen die Äußerungen monolingualer Sprecher.118 In der Forschungsliteratur hat sich dafür der Begriff Style Shifting etabliert, um den Wechsel monolingualer Sprecher zwischen verschiedenen Sprachvarietäten zu beschreiben (vgl. Müller & Gil Arnaus & Eichler & Geveler & Hager & Jansen & Patuto & Repetto & Schmeißer 2015, 14).
In der Literatur wird dennoch häufig explizit auf einen Wechsel zwischen Languages anstelle von Codes verwiesen, wie die Begriffe Language Switching und Language Shifting zeigen. Ersteren Begriff findet man in Studien zur Sprachwahl aus der Psycholinguistik. Hierbei werden Kontrolle, Struktur und Zugang zum bilingualen Lexikon der Sprecher untersucht (vgl. Gullberg & Indefrey & Muysken 2009, 21). Der zweite Begriff meint meist den Wechsel, der aufgrund von Kompetenzlücken der Sprecher in einer der Sprachen erfolgt und der zwischen Minoritätensprachen und der ansonsten verwendeten Umgebungssprache stattfindet (vgl. Fishman 2004). Oft wird für diesen Wechsel auch der Begriff des Code-Shiftings bevorzugt, wie etwa in Studien zu bilingualen spanisch-englisch Sprechern in den USA (vgl. Gardner-Chloros 1987, 71).
Dieser Arbeit liegt im Folgenden der Begriff Code-Switching (CS) zugrunde. Darunter werden Wechsel zwischen zwei oder auch mehreren (Einzel-)Sprachen verstanden. Da diese Sprachen als sprachliche Kommunikationsmittel der CMC verwendet werden, und als solche besondere Merkmale enthalten (siehe Kapitel ), wird hier der Begriff Code präferiert.
Allerdings variiert nicht nur der Begriff, der den Gegenstand des Wechsels bezeichnet, auch wie der Wechsel an sich von statten geht, wird mit unterschiedlichen Termini ausgedrückt und soll im Folgenden thematisiert werden.
4.1.2. Switching, Shifting und Mixing
Die aus dem Englischen stammenden Termini Switching, Shifting und Mixing haben eine ähnliche Bedeutung. Unter to switch ‘wechseln’ versteht man eher einen abrupten Wechsel, meist aktiv hervorgerufen, während to shift ‘verändern‘, auf einen durch Bewegung hervorgerufenen (langsameren) Vorgang verweist. Schließlich bedeutet to mix ‚mischen/vermengen‘.
Language Shifting (oder auch Code Shifting) tritt, wie oben schon gesehen, in soziolinguistisch motivierten Situationen auf, in denen ein Sprecher in einer Sprache kommunizieren muss, in der er geringe(re) Kompetenz besitzt. Die dominante Sprache (hier die Sprache, die besser beherrscht wird) bestimmt die syntaktische Struktur, und lexikalische Lücken werden mit sprachlichem Material daraus geschlossen (vgl. Gardner-Chloros 1987, 85). Häufig sind diese Shiftings durch Häsitationen und Pausen vor den Wechseln gekennzeichnet (vgl. Gardner-Chloros 1987, 77).
Mixing suggeriert, dass hierbei Sprachen (oder Sprachvarietäten) miteinander vermengt werden. Mit Code-Mixing wird deshalb häufig satzinternes CS (sogenanntes intra-sententiales CS, siehe Kapitel ) bezeichnet (vgl. Sciullo & Muysken & Singh 1986, , Riehl 2004). Meisel 1994, 414 hingegen verwendet den Begriff Code-Mixing allgemein für alle Fälle, in denen “[…] features of two languages are juxtaposed, within a clause or across clause boundaries, irrespective of the etiology of these phenomena.” Auch Krefeld (vgl. 2004, 91) plädiert für die Verwendung des Begriffs Code-Mixing bei funktional kaum oder nicht einsichtigen Wechseln. Solche nicht-funktionale Wechsel sind meist psycholinguistisch motiviert und werden oft durch sogenannte Trigger-Words ‚Auslösewörter‘ hervorgerufen. Dabei kann es sich beispielsweise um Eigennamen, lexikalische Übernahmen oder bilinguale Homophone handeln (vgl. Riehl 2004, 65–66). Diese Code-Mixings stehen bei den oben genannten Autoren in Kontrast zum Code-Switching, der Fähigkeit des bilingualen Sprechers, die Sprache nach äußeren Faktoren und situationsbedingtem Kontext zu wählen. Diese zuletzt genannten Wechsel sind somit funktional motiviert (vgl. Meisel 1994, Berruto 1995, Krefeld 2004).
Oft spielt auch der Grad der Integration grammatischer Regeln aller beteiligten Sprachen eine Rolle bei der Verwendung der Termini Code-Switching und Code-Mixing. Während beim Code-Mixing davon ausgegangen wird, dass die grammatischen Regeln einer Sprache in die der anderen integriert werden, muss dies beim Code-Switching nicht der Fall sein. Demzufolge kommt es an Satzgrenzen zu Code-Switching, während Code-Mixing auch innerhalb eines Satzes (oder innerhalb von Wörtern) erfolgt (vgl. Bokamba 1989, 278). Bei anderen Autoren wiederum versteht man unter Code-Mixing die Wechsel, bei denen die normalerweise für das Code-Switching geltenden Beschränkungen verletzt werden (vgl. Meisel 1994, 414).
Sprachwechsel sollen in der vorliegenden Arbeit sowohl nach strukturellen als auch nach kommunikationsfunktionalen Kriterien untersucht werden, weshalb hier der Begriff des Switchings passender erscheint. Das heißt, Code-Switching wird als als das Wechseln zwischen zwei oder mehreren Sprachen verstanden, wobei sich der Begriff sich für die vorliegende Arbeit nur auf die Sprachwechsel innerhalb einer einzigen Facebook Statusmeldung oder eines einzigen Facebook Posts beschränkt.119
4.1.3. Code-Switching in der CMC
Die Idee, CS für die CMC zu untersuchen ist dabei nicht neu. So können der Aussage „so little work has been carried out on CS in the internet“ (Dorleijn & Nortier 2009, 135) mittlerweile schon einige Studien und Arbeiten entgegengesetzt werden. Dabei werden verschiedene Ansätze aus der klassischen CS Forschung aufgegriffen und auf die CMC angewandt. Im Folgenden sollen nur die Studien Erwähnung finden, die nach einem strukturellen Ansatz verschiedene CS Typen untersuchen oder die kommunikativen Funktionen der Sprachwechsel thematisieren (für die Ersteren siehe Kapitel , für die Letzteren Kapitel ).
Innerhalb dieser Studien werden verschiedene Sprachpaarungen analysiert. Vor allem Paarungen, bei denen Englisch eine der beiden Sprachen, zwischen denen gewechselt wird, darstellt, sind häufig zu finden: CS zwischen Spanisch und Englisch (vgl. Cárdenas-Claros & Isharyanti 2009, Goldbarg 2009, Lanz Vallejo 2011, Montes-Alcalá 2005, 2007), zwischen Englisch und Griechisch (vgl. Georgakopoulous 1997), zwischen Englisch und Indonesisch (vgl. Cárdenas-Claros & Isharyanti 2009, Hidayat 2012), zwischen Englisch und Malaysisch (vgl.Shafie & Nayan 2013, Syazwani Halim & Maros 2014), zwischen Englisch und Punjabi (vgl. Paolillo 1996, 2011) und schließlich zwischen Englisch und jamaikanischem Kreol (vgl. Hinrichs 2006). Aber es gibt auch einige Untersuchungen zu anderen Sprachenpaaren, wie Niederländisch und Türkisch (vgl. Dorleijn & Nortier 2009), Italienisch und Russisch (vgl. Goletiani 2010), marrokanischem Arabisch und Französisch (vgl. Ackermann 2007) sowie Deutsch und Griechisch oder Deutsch und Türkisch (vgl. Androutsopoulos & Hinnenkamp 2001, Androutsopoulos 2006). Allerdings spielt auch in diesen Studien das Englische eine wichtige Rolle, da auch hier ein großer Einfluss der englischen Sprache erkennbar ist.120 Untersuchungen zu CS zwischen Deutsch und Italienisch liegen zurzeit und nach dem Kenntnisstand der Autorin dieser Arbeit nicht vor.
Es ist zu beobachten, dass sich die meisten Autoren bei ihren Untersuchungen auf eine bestimmte Kommunikationsform beschränken und die CMC somit nicht mehr als eine homogene Form der Kommunikation betrachtet wird – im Vergleich zu früheren Untersuchungen der CMC (siehe Kapitel ). So werden zum einen E-Mails auf CS untersucht (vgl. Georgakopoulous 1997, Goldbarg 2009, Hinrichs 2006, Montes-Alcalá 2005). Aber auch Blog- und Forumsbeiträge oder Beiträge auf Webseiten (vgl.Androutsopoulos 2006, Dorleijn & Nortier 2009, Goletiani 2010, Montes-Alcalá 2007, Paolillo 2011) und Tweets auf Twitter (vgl. Lanz Vallejo 2011) werden betrachtet. Vor allem CS in Chats ist jedoch in den letzten Jahren in den Fokus der CMC Forschung gerückt (vgl. Ackermann 2007, Cárdenas-Claros & Isharyanti 2009, Scheuplein 2010).
Schließlich gibt es auch einige kurze und meist sehr oberflächliche Studien, deren Inhalt CS in Facebook ist. Die untersuchten Sprachpaarungen sind dabei Indonesisch und Englisch (vgl. Hidayat 2012), Malaysisch und Englisch (vgl. Shafie & Nayan 2013, Syazwani Halim & Maros 2014) sowie Englisch mit verschiedenen anderen Sprachen (vgl. Sukyadi & Wirza & Hasiani 2012). Dabei bilden auf der einen Seite Facebook comments die Basis der Untersuchung, wobei nicht klar wird, ob es sich dabei um Facebook Statusmeldung oder Posts oder um die eigentlichen Kommentare zu den Beiträgen handelt (vgl. Hidayat 2012). Auf der anderen Seite werden entweder nur Facebook Statusmeldungen (vgl. Syazwani Halim & Maros 2014) oder auch Facebook Beiträge inklusive der Kommentare untersucht (vgl. Shafie & Nayan 2013, Sukyadi & Wirza & Hasiani 2012). Bei keiner dieser Studien wird jedoch der Untersuchungsgegenstand der Facebook Beiträge genauer beschrieben oder von anderen Kommunikationsmöglichkeiten auf Facebook abgegrenzt. In dieser Arbeit wurde deshalb eine systematische Beschreibung des Untersuchungsgegenstands der Facebook Beiträge vorausgeschickt, um diese Lücke zu schließen.
Es muss allerdings hier angemerkt werden, dass ein Vergleich der Ergebnisse dieser hier präsentierten Studien, verschiedene Kommunikationsformen der CMC berücksichtigt und somit die Ergebnisse nur bedingt vergleichbar sind. Trotzdem werden alle im Kontext der CMC und der dort vorhandenen Affordanzen und Constraints behandelt (siehe Kapitel ), weshalb diese auch hier als Grundlage für eine genauere Betrachtung des CS in der CMC dienen können.
Im Folgenden werden die wichtigsten Ergebnisse und Schlüsse, die aus diesen Untersuchungen zum CS in der CMC gezogen werden können, vorgestellt. Zunächst erfolgt eine Betrachtung des CS nach einem strukturellen Ansatz, also wie CS hinsichtlich seiner Form in verschiedene Typen untergliedert werden kann. Anschließend folgt eine Übersicht der Forschung nach einem sozio-pragmatischen Gesichtspunkt. Bei beiden Ansätzen werden zunächst die entsprechenden Ansätze aus der klassischen Forschungsliteratur des CS vorgestellt und im Anschluss daran Studien, die diese hinsichtlich der CMC untersuchen, präsentiert. Abschließend sollen aus den Erkenntnissen die Hypothesen und die Fragestellungen für die vorliegende Arbeit abgeleitet werden.
4.2. Typisierung des Code-Switchings
Code-Switching, also das Wechseln zwischen zwei oder mehreren Sprachen innerhalb eines Facebook Beitrags, kann verschiedene Formen annehmen. Während manchmal nur ein Wort von der Sprache A in einen ansonsten auf Sprache B verfassten Beitrag eingefügt wird, werden in anderen Fällen Phrasen, Konstituenten oder ganze Sätze in einer anderen Sprache wiedergegeben. Um CS in den Facebook Beiträgen bestimmen zu können, soll eine geeignete Typisierung diskutiert werden. Dabei werden zwei strukturelle Kategorisierungen vorgeschlagen, um daraus eine für diese Arbeit anwendbare Untergliederung für CS zu finden.
4.2.1. Inter- und intra-sententiales CS
CS wird nach Poplack (1980, 583) als “the alternation of two languages within a single discourse, sentence or constituent” definiert, und schon die Überschrift des Artikels, aus dem diese Definition stammt, stellt ein Beispiel für einen Sprachwechsel dar:
(Poplack 1980, Titel) [Hervorhebungen und Glossierung im Original].
Sometimes I’ll start a sentence in Spanish [sic!] Y TERMINO EN ESPAÑOL.121
Unter CS versteht man also einen Wechsel, der sowohl auf Diskurs-, oder Satzebene, aber auch zwischen dessen untergeordneten Teilen stattfinden kann. Das heißt, CS kann auf verschiedenen Ebenen stattfinden, und diese Wechsel werden häufig auch getrennt voneinander betrachtet. In der allgemeinen Forschungsliteratur gibt es einen Konsens darüber, dass vor allem zwei Typen von CS unterschieden werden können: inter- und intra-sententiales CS.122
Unter inter-sententialem CS versteht man „switches from one language to the other between sentences“ (Myers-Scotton 1993, 4) und intra-sententiales CS hingegen “occurs within the same sentence or sentence fragment” (ebd.).123 Inter-sententiales CS bezeichnet also das Switchen an der Satzgrenze, wie das Beispiel (52) zeigt, und intra-sententiales CS den Sprachwechsel innerhalb eines Satzes, wie in Beispiel (53).
(Myers-Scotton 1995, 41) [Hervorhebungen und Glossierung im Original].
That’s too much. Sina pesa.
That’s too much. I don’t have [much] money.
(Poplack 1980, 589) [Hervorhebungen und Glossierung im Original].
Why make Carol SENTARSE ATRAS PA’ QUE (sit in the back so) everybody has to move PA’ QUE SE SALGA (for her to get out)?
Der Wechsel in (53) findet zudem innerhalb einer Äußerung statt. Satz- und Äußerungsgrenzen fallen oft, aber nicht immer zusammen, weshalb manchmal auch zwischen inter-sentential und inter-utterance Code-Switching unterschieden wird (vgl. Müller & Gil Arnaus & Eichler & Geveler & Hager & Jansen & Patuto & Repetto & Schmeißer 2015, 15). Der letztere Terminus wird allerdings selten verwendet. Darüber hinaus wird in einigen Fällen auch ausgehend vom Sprechakt bestimmt, ob es sich um inter-sententiales und intra-sententionales CS handelt. So kann nach Berruto (1995, 261) nur von intra-sententialem Code-Switching gesprochen werden, wenn der Wechsel innerhalb eines Sprachaktes und innerhalb eines Satzes stattfindet.
[…] quando il passaggio avviene all’interno di un singolo atto linguistico e una singola frase, e consiste nella formulazione di uno o più costituenti della frase in una lingua diversa da quella in cui la frase è stata iniziata talché il risultato è una frase i cui costituenti appartengono a diversi sistemi linguistici. (Berruto 1995, 261) 124
Es lässt sich schießlich festhalten, dass die Bandbreite an Variation von intra-sententialem CS sehr groß ist. Dabei kann es sich um einzelne lexikalische Elemente oder kurze Phrasen handeln, aber auch um ganze Konstituenten, wie bei Berruto. Dieser Switching-Typ wird deshalb häufig noch weiter untergliedert.
4.2.2. Tag-, Einzel-Wort- und wortinternes Switching
Poplack (1980, 589) führt neben dem inter- und dem intra-sententialen CS noch die Unterkategorien Tag-Switching und Einzel-Nomen-Switching ein, die sich teilweise dem intra-sententialen CS unterordnen lassen.
(Poplack 1980, 589) [Hervorhebungen und Glossierung im Original]
Vendía arroz (He sold rice) ‘N SHIT.
(Poplack 1980, 589) [Hervorhebungen und Glossierung im Original]
Salían en sus carros y en sus (They would go out in their cars and in their) SNOWMOBILES.
Unter Tag-Switching versteht man, wenn nur ein einzelnes Gesprächswort oder formelhafte Ausdrücke, sogenannte Tags, in einen ansonsten monolingualen Satz in einer anderen Sprache eingefügt werden, wie `N SHIT in Beispiel (54).125 Bei diesen Tags kann es sich um Refrainfragen, wie en. isn’t it? oder de. gell?, handeln, aber auch um Interjektionen jeder Art wie it. ecco oder de. achja. Häufig wird dieser Typ des Switchens als emblematisches Code-Switching bezeichnet, das eigentlich überall im Satz vorkommen kann, ohne dadurch irgendwelche grammatischen Regeln zu verletzen (vgl. Poplack 1980, 589). Auch wenn dieser Typ häufig innerhalb der Satzgrenzen verwendet wird, gibt es hierbei keine Beteiligung der grammatischen Struktur, weshalb dieser Typ häufig auch dem inter- oder gar dem extra-sententialen CS zugeordnet wird (vgl. Poplack 1980, 602).
Unter Einzel-Nomen-Switching (oder Single-Noun-Switching) versteht man Ein-Wort-Switching, bei dem ein Nomen aus einer Sprache A in einen ansonsten in Sprache B verfassten Satz eingefügt wird wie SNOWMOBILES in Beispiel (55). Nomen stellen die wohl am häufigsten geswitchten Elemente dar und können fast überall im Satz eingefügt werden. Eigentlich können alle Wortarten als Ein-Wort-Switches vorkommen, jedoch sind Switches mit anderen Wortarten deutlich seltener. Deshalb wird bei vielen Autoren nur das Switchen eines Nomens als eigene Unterkategorie aufgeführt – die anderen Ein-Wort-Switches werden dann zum intra-sententialen CS gezählt (vgl. Poplack 1980, 603)). Diese Einzel-Nomen-Switches sind jedoch häufig problematisch, da eine Abgrenzung zu Lehnwörtern nicht immer eindeutig ist (siehe Kapitel ).
Manchmal werden zudem noch die sogenannten Intra-Wort-Switches oder wortinternen Switches aufgeführt, die die Wechsel innerhalb der Wortgrenzen bezeichnen (vgl. Myers-Scotton 1989, 337).
(Myers-Scotton 1989, 337) [Hervorhebungen und Glossierung im Original]
CARPET ni matatizo. lnabidi u-li-SHIP. huwezi kulipeleka kwenye ndege kwa sababu ya urefu wake. . . Sisi tunayotaka kununua ni ki-CLOTH.
A carpet is problems. You have to ship it. You can’t carry it on the plane because of its length . . . What we want to buy is cloth.
Meist werden Beispiele aus agglutinierenden Sprachen genannt, wie bei Myers-Scotton (vgl. 1989, 338)), wo in eine ansonsten auf Swahili gesprochene Äußerung englische Nomen eingefügt werden, wie CARPET, SHIP und CLOTH in Beispiel (56). Diesen werden teilweise Affixe aus dem Swahili angehängt wie bei u-li-SHIP und ki-CLOTH. Für andere Sprachenpaare, bei denen die Basissprache (Matrixsprache bei Myers-Scotton126) keine Agglutinierende ist, korreliert dieser Typ der wortinternen Switches mit dem Konzept von morphologisch assimilierten Lehnwörtern, wie Kapitel zeigen wird.
Schließlich werden anhand der verschiedenen CS Typen Voraussagen über die Kompetenz der Sprecher getroffen (vgl. Poplack 1980, 589–590). So schätzt Poplack das intra-sententiale CS als komplexer ein, da das geswitchte Element (oder die geswitchten Elemente) mit den zugrundeliegenden syntaktischen Strukturen der beiden beteiligten Sprachen übereinstimmen muss. Aber auch das inter-sententiale CS erfordert sehr gute Kompetenzen in allen beteiligten Sprachen, da es mit der Produktion ganzer Sätze einhergeht (vgl. Bullock & Toribio 2009a, 3). Die Tag- und Einzel-Nomen-Switches erfordern letztendlich die niedrigste Kompetenz. Das heißt also, dass davon ausgegangen werden kann, dass wenn ein Sprecher intra-sententiales CS verwendet, es sehr wahrscheinlich ist, dass dieser auch die anderen Typen benutzt.
Neben dem Einzel-Nomen- und dem wortinternen Switching gibt es noch weitere Typen von intra-sententialem CS. Die Typisierung nach Muysken, die im Folgenden vorgestellt wird, schließt nicht nur die eben Erwähnten ein, sondern ermöglicht es, (fast) alle Arten von CS innerhalb der Satzgrenzen zu kategorisieren.
4.2.3. Insertion, Alternation und kongruente Lexikalisierung
Muysken (2000) verwendet den Begriff Code-Mixing um alle Fälle, in denen grammatische Eigenschaften und lexikalische Elemente zweier verschiedener Sprachen in einem Satz auftreten, zu bezeichnen.127 Die Annahme, die Muysken zugrunde legt, ist, dass beide Grammatiken und Lexika der beteiligten Sprachen bei der Produktion eines gemeinsamen Satzes involviert sind (vgl. Muysken 2000, 70). Der Autor definiert drei verschiedene Unterkategorien, die er als Prozesse bezeichnet: Insertion, Alternation und kongruente Lexikalisierung.
• insertion of material (lexical items or entire constituents) from one language into a structure from the other language
• alternation between structures from languages
• congruent lexicalization of material from different lexical inventories into a shared grammatical structure (Muysken 2000, 3)
Bei der Insertion handelt es sich um die Integration von Sprachmaterial, beispielsweise die Einbettung einer italienischen NP in eine deutsche VP, aber auch die Einbettung von vorzugsweise einzelnen Inhaltswörtern, wie beispielsweise eines Nomens (vgl. Muysken 2000, 95). Auch Beispiel (57) zeigt eine Insertion, bei der der temporale Ausdruck pa dos días eindeutig in Bezug zu dem Verb anduve steht (vgl. Muysken 1995, 180).
(Pfaff 1979, 296, zit. Muysken 1995, 180) [Hervorhebungen und Glossierung nach Muysken].
Yo anduve in a state of shock pa dos días.
I walked in a state of shock for two days.
Bei der Alternation handelt es sich um einen „true switch from one language to the other“ (Muysken 2000, 5), bei dem sowohl die grammatischen als auch lexikalische Strukturen beteiligt sind. Der Satz aus (51) ist ein Beispiel dafür. Alternation kann dabei sowohl inter- als auch intra-sentential vorkommen, auch wenn Muysken in seinen Untersuchungen nur auf intra-sententiales Code-Mixing eingeht.
Die kongruente Lexikalisierung kann schließlich als eine Kombination von Alternation und Insertion betrachtet werden. Dabei teilen sich zwei Sprachen eine grammatische Struktur, die mit lexikalischen Elementen beider Sprachen gefüllt wird (vgl. Muysken 1997, 362).
(Pfaff 1979, 310, (zit.nach Muysken 1997, 362)) [Hervorhebungen und Glossierung nach Muysken].
Bueno, in other words, el flight [que sale de Chicago around three o’clock]
Good, in other words, the flight that leaves Chicago around three o’clock.
Hierbei kommt es zu einem „rapid back and forth switching of loose elements in a structure mostly shared by two languages“ (Muysken 2007, 322). Dieses Phänomen ist dabei vor allem bei Sprachwechseln zwischen Standardsprache und Dialekt(en) oder nah verwandten Sprachen anzutreffen.
Der Grad der Integration von Sprachmaterial einer Sprache in die andere nimmt von der Insertion, über die Alternation, bis hin zur kongruenten Lexikalisierung immer weiter ab. Deshalb wird davon ausgegangen, dass für die Insertion die geringste Sprachkompetenz nötig ist, gefolgt von der Alternation und der kongruenten Lexikalisierung (vgl. Cárdenas-Claros & Isharyanti 2009, 77).
Diese Typisierung ist jedoch oft nicht eindeutig, da zum einen die Insertion – gerade wenn es sich bei der Einbettung um Nomen handelt – der Entlehnung sehr ähnelt (siehe Kapitel ). Zum anderen gibt es bei der Alternation eine große Bandbreite an Switches, die sich teilweise sehr voneinander unterscheiden; so werden auch eingefügte Interjektionen und Diskursmarker zur Alternation gezählt, das heißt auch das Tag-Switching würde zu dieser Kategorie gehören.128 Schließlich ist bei der kongruenten Lexikalisierung eine gemeinsame grammatische Struktur von Nöten, weshalb diese meist nur zwischen verwandten Sprachen oder auch Sprachvarietäten (z.B. Standard und Dialekt) stattfindet. Es kann zudem kritisiert werden, dass dieser letzte Typ als eine Art Sammelkategorie für alle Sprachwechsel, die sich weder der Insertion noch der Alternation zuweisen lassen, darstellt. Außerdem wird diesem Typ eine gleichzeitige Aktivierung von Lexikon und Grammatik zugesprochen. Dies als Abgrenzungskriterium zu der Insertion und Alternation zu verwenden, ist kritisch zu sehen, da auch bei den anderen Typen eine Aktivierung der sprachlichen Regeln erfolgen muss. Eine Unterscheidung und klare Abgrenzung der einzelnen Typen ist schlussendlich nicht immer möglich, vielmehr sollten sie als graduell betrachtet werden (vgl. Muysken 2000, 9).
4.2.4. Abgrenzung zur Entlehnung
In der Sprachkontaktforschung werden neben CS viele Phänomene untersucht, wie beispielsweise die Entlehnung oder auch der Transfer. Dabei sind die Grenzen nicht immer klar umrissen und eine eindeutige Zuordnung zu einem Phänomen ist nicht immer möglich. Am Schwierigsten ist wohl die Unterscheidung zwischen Code-Switching und Entlehnung (en. borrowing).129 Deshalb werden hier kurz die wichtigsten Unterscheidungsmerkmale zwischen CS und Entlehung wiedergegeben, um eine spätere Zuweisung rechtfertigen zu können.
Gardner-Chloros (1987, 102) fasst zusammen: “a loan is a code-switch with a full-time job”. Das bedeutet zum einen, dass die Unterscheidung zwischen Entlehnung und CS keine absolute ist und dass der Übergang fließend sein kann; so können im CS verwendete Wörter zu fest etablierten Lehnwörtern werden (vgl. Romaine 1995, 124). Bei einer Entlehnung werden sprachliche Elemente aus einer Gebersprache, in eine andere Nehmersprache eingefügt.130 Entlehnungen sind dabei meist kürzer, denn sie betreffen nur einzelne Wörter (also Lehnwörter) oder kurze Phrasen. Sie sind im Normalfall in die Nehmersprache integriert und dienen häufig dazu, semantische Lücken zu schließen (vgl. Gardner-Chloros 1987, 102). Nach Grosjean (vgl. 1982, 308) kommt es dabei zu einer morphologischen Adaption, während dies beim Code-Switching nicht der Fall ist. Das verdeutlicht der Autor mit einem Beispiel:
Thus, a French-English bilingual can say:
„a m’étonnerait qu’on ait code-switched autant que ça.“
or
„Ca m’ étonnerait qu’on ait CODE-SWITCHÉ autant que ça.“
(Grosjean 1982, 308) [Hervorhebungen im Original]
Während es sich bei der ersten Äußerung um CS handelt, erfolgt bei der zweiten eine morphologische Anpassung, weshalb hier von einer Entlehnung gesprochen wird. Allerdings ist die Unterscheidung zwischen morphologisch assimilierten Lehnwort und CS nicht immer eindeutig. Es könnte sich bei einem einmaligen Vorkommen von code-switché ohne lautliche Anpassung des Englischen an das Französische ebenso um ein CS auf Wortebene (wortinternes Switching, siehe Kapitel ) handeln.
Des Weiteren wird davon ausgegangen, dass beim CS alle Elemente ihre Eigenschaften beibehalten, was bei der Entlehnung nicht der Fall ist (vgl. González Vilbazo 2005, 25-26). Bei manchen Nomen weicht beispielsweise das Genus eines Nomens der Gebersprache von dem der Nehmersprache ab, wie bei it. il treno (Maskulinum) und de. die Bahn (Femininum). Wenn das deutsche Nomen dann in eine italienische Äußerung eingefügt wird und dabei das Genus des Artikels mit dem der Nehmersprache übereinstimmt, würde man von Entlehnung sprechen (siehe Beispiel (59)), wenn das Genus des Artikels aus der Gebersprache mit übernommen wird, dann von CS (siehe Beispiel (60)).
[FB_1921_1034]131
[..] sullo strassenbahn!!
[FB 1621_2577]
[…] nella ubahn […]
Dieses Unterscheidungskriterium funktioniert allerdings nur, wenn sich die Sprachen hinsichtlich bestimmter Kriterien unterscheiden. So wäre bei Nomen, bei denen sich die Genera in dem betrachten Sprachpaar nicht unterscheiden, eine solche Differenzierung nicht möglich (wie bei it. la donna, de. die Frau, beides Femininum). Aber auch wenn sich Sprachen hinsichtlich bestimmter Merkmale zu sehr unterscheiden, ist dieses Kriterium unbrauchbar wie beispielsweise beim Genus im Englischen im Vergleich zum Deutschen.
Neben der morphologischen Integration wird häufig auch noch die lautliche Integration genannt. So ist für Grosjean (1995) eine phonetisch-phonologische Integration entscheidend, und nur bei einer Aussprache der Wörter in der Nehmersprache kann von Entlehnung gesprochen werden.132 Wenn diese Wörter allerdings wie in der Gebersprache ausgesprochen werden, findet CS statt. Diese Unterscheidung kann aber nur bei gesprochenen Äußerungen überprüft werden und ist deshalb für die Zwecke dieser Arbeit unbrauchbar.
Ein weiteres vorgeschlagenes Kriterium ist die Frequenz. Wenn ein Lexem häufig in einer anderen Sprache und von mehreren Sprechern dieser verwendet wird, das heißt sozial konventionalisiert ist, ist es eher als Lehnwort zu betrachten, als ein Lexem, das einmalig und nur von einer Einzelperson benutzt wird. Auch Poplack & Sankoff & Miller (1988) gehen auf die Ähnlichkeit zwischen Ein-Wort-CS und Lehnwörtern ein:
We can of course distinguish between those that occur only once in our corpus (’nonce‘ borrowings) and those used by many speakers (widespread loans), but a priori we cannot take for granted that this purely operational distinction correlates either with the degree of linguistic assimilation of the word or with its history of attestation as a loanword in the language. (Poplack & Sankoff & Miller 1988, 50) [Hervorhebungen im Original].
Ein-Wort-Switches, die nur einmalig (in einem Korpus) auftauchen, werden von den Autoren als Nonce-Borrowing bezeichnet, um diese zu Lehnwörtern, die häufiger im Korpus Verwendung finden, abzugrenzen.133 Allerdings kann die Grenze zwischen Lehnwörtern und Nonce-Borrowing je nach Frequenz des Vorkommens und deren Status in der Sprache und im mentalen Lexikon der Sprecher verschwimmen. Das heißt, die Fragen, wie häufig ein Wort vorkommen muss, um als Lehnwort angesehen zu werden oder wie weit es in die Nehmersprache assimiliert sein muss, um einen bestimmten Status in der Sprache zu erlangen, werden hier nicht beantwortet. Auch Myers-Scotton (vgl. Myers-Scotton 1993, 181-182) merkt an, dass die Einführung eines neuen Terminus nicht ausreicht, das Phänomen von einmalig vorkommenden Ein-Wort-Switches zu erklären und es von dem des Lehnwortes abzugrenzen.134
Zusammenfassend lässt sich festhalten, dass es verschiedene Kriterien gibt, Entlehnung von CS zu unterscheiden. Dazu zählt zum einen der Grad der morphologischen und lautlichen Integration; ebenso kann die Frequenz hierfür zu Rate gezogen werden.135 Schließlich spielt auch noch die Gebersprache des entsprechenden Lexems eine Rolle. Gerade die sogenannten Anglizismen, wobei es sich um einzelne Wörter oder feste Phrasen aus dem Englischen handelt, lassen sich häufig zu der Gruppe der Lehnwörter zählen (vgl. Androutsopoulos & Hinnenkamp 2001, 12). Vor allem bei diesen ist deshalb nicht nur die Frequenz im Korpus relevant, sondern auch der Status, den sie in der entsprechenden Nehmersprache einnehmen.136
Für die Zwecke dieser Arbeit sollen nur Wechselphänomene untersucht werden, bei denen zwischen Sprachen gewechselt wird. Dabei ist vor allem die Unterscheidung zwischen Entlehnung und CS wichtig, wobei hier von einem Kontinuum ausgegangen wird. Lehnwörter werden sowohl nach ihrer morphologischen Integration, als auch nach ihrer Frequenz (im Korpus) und ihrem Status in der Nehmersprache vom CS abgegrenzt werden. Für jedes Vorkommen von Einzel-Nomen-Switches und vor allem wortinternen Switches muss deshalb entschieden, wo diese auf dem Kontinuum zu verorten sind und ob diese überhaupt eindeutig zuordnenbar sind. Das wird auch davon abhängen, um welche Sprachenpaare es sich handelt, welche der Sprachen also die Geber- und welche die Nehmersprache darstellt.
4.2.5. Strukturelle Typisierung von CS in der CMC
Auch in Studien zum CS in der CMC werden die Sprachwechsel nach einem strukturellen Ansatz kategorisiert. Androutsopoulos (2006) stellt bei seinen Untersuchungen von Forenbeiträgen auf Ethnoportalen fest, dass es mehr inter-sententiales als intra-sententiales CS gibt (bei ihm als „Sprachwechsel“ und „Sprachmischung“ bezeichnet).137 Der Autor findet innerhalb des intra-sententialen CS vor allem viele Insertionen, bei denen beispielsweise Grußformeln, Anreden, Glückwünsche etc. aus der Sprache der Migranten in ansonsten auf Deutsch verfasste Beiträge eingefügt werden. Außerdem kann der Autor feststellen, dass keine klare Beziehung zwischen Thema und Sprachwechsel erkennbar ist (vgl. Androutsopoulos 2006, 194).
Auch Cárdenas-Claros & Isharyanti (vgl. 2009, 74) finden mehr inter-sententiales als intra-senteniales CS (fast doppelt so viel).138 Bei der Klassifikation des intra-sententialen CS nach Insertion, Alternation und kongruenter Lexikalisierung stellen die Autoren schließlich eine große Anzahl an Insertionen fest. Die Vorkommnisse von Alternation und und kongruenter Lexikalisierung sind deutlich seltener zu finden (vgl. Cárdenas-Claros & Isharyanti 2009, 76). Die Autoren merken an, dass fast alle Alternationen dabei aus Tag-Switchings (darunter yeah, yes, si) bestehen und begründen die hohe Anzahl an Insertionen damit, dass hierfür am wenigsten Sprachkompetenz von Nöten sei. Getriggert wird CS vor allem, wenn es zu Intimitäten und persönlichen Gefühlen kommt (vgl. Cárdenas-Claros & Isharyanti 2009, 77).
Dorleijn & Nortier (2009, 135-140) stellen fest, dass vor allem bei „texts that resemble oral conversation“ (Dorleijn & Nortier 2009, 138-140) sowohl intra- als auch inter-sententiales CS verwendet wird, ohne jedoch eine Verteilung oder Angabe über die Anzahl der Okkurrenzen zu nennen.139 Es wird angenommen, dass bei einem informativen Gebrauch häufig der CS Typ der Insertion verwendet wird (bei ihren Untersuchungen stellt dabei meist das Niederländische die Basissprache dar). Witze und Erzählungen sind meist monolingual, können aber erklärende Kommentare und Hinweise in der anderen Sprache enthalten.
Eine Studie, bei der das intra-sententiale CS überwiegt, wurde von Goletiani (2010) vorgestellt. Innerhalb der Gruppe des intra-sententialen CS wird zudem noch zwischen zentralen und peripherischen Switches unterschieden, die sich mit Insertion und Alternation gleichsetzen lassen. Ersterer Typ überwiegt dabei innerhalb der Gruppe des intra-sententialen CS.
Schließlich werden auch in zwei der Studien, die Facebook als Untersuchungsbasis haben, strukturelle Typen von CS bestimmt. Bei Hidayat (2012) konnte in den insgesamt 39 Okkurrenzen für CS in den Beiträgen, die von 20 indonesischen Studierenden verfasst wurden, eine Präferenz für inter-sententiales CS ausgemacht werden (59%), gefolgt von intra-sententialem CS (33%) und Tag-Switching (8%). In einer anderen Studie stellen deren Autoren (vgl. Sukyadi & Wirza & Hasiani 2012, 4) in 688 Beiträgen mit CS fest, dass sich hier – im Gegensatz zur Studie von Hidayat – eine geringfügig höhere Anzahl an Belegen für intra-sententiales CS finden lässt (42,9%) als für inter-sententiales CS (40%). Die Tag-Switchtes (17 %) werden näher bestimmt, aber keine weiteren Unterkategorien zum intra-sententialen CS ausgemacht.
Zusammenfassend lässt sich festhalten, dass in den meisten Studien zur CMC der Typ des inter-sententialen CS überwiegt – außer bei den Studien von Sukyadi, wo sie nur geringfügig größer ist, und von Goletiani, was dort auf eine recht weit gefasste Interpretation der Definition des CS Typs zurückzuführen ist (vgl. Goletiani 2010, 93).140 Es wird außerdem eine hohe Anzahl an Insertionen festgestellt, wobei die hierzu gerechneten Sprachwechsel sich durchaus voneinander unterscheiden. Während Androutsopoulos (2006) vor allem Grußformeln und Anreden findet, haben die Insertionen nach Dorleijn & Noriter (2009) eher informativen Charakter und bei Cárdenas-Claros & Isharyanti (2009) werden sie vor allem mit geringer Sprachkompetenz begründet. Insgesamt werden kaum Gründe für die Präferenz eines bestimmten CS Typs genannt, und wenn, dann folgen sie einem psycholinguistischen Ansatz, wonach eine „Sprachmischung […] eine spontane Sprechweise, die bei der Planung schriftlicher Forenbeiträge automatisch unterdrückt wird“ (Androutsopoulos 2006, 180), ist. Der Grad der Planung bei dem hierfür zugrundeliegenden Untersuchungsgegenstand, den Forenbeiträgen, ist tatsächlich als relativ hoch anzusehen. Auch bei CMC Typen, die sehr viel spontaner und weniger geplant verfasst werden, wird der Typ des inter-sententialen CS bevorzugt, wie beispielsweise bei den Chatnachrichten. Dies verdeutlicht die Studie nach Cárdenas-Claros & Isharyanti (2009).
Für die vorliegende Arbeit soll ebenfalls zwischen inter-sententialem und intra-sententialem CS unterschieden werden. Es wird erwartet, dass der Typ des inter-sententialen CS überwiegt, da zum einen Facebook Beiträge nicht spontan entstehen, sondern geplant verfasst werden. Zum anderen liegt das an der Verwendung struktureller Typen, die dafür eingesetzt werden, um die kommunikativen Funktionen des CS zu erfüllen (siehe Kapitel ). Es wird davon ausgegangen, dass auch Beiträge mit intra-sententialem CS vorkommen. Diese sollen untergliedert werden in Alternation und Insertion.141 Dabei wird das Tag-Switching zur Alternation gezählt, wohingegen sowohl Einzel-Wort-Switches, vor allem Einzel-Nomen-Switches, aber auch wortinterne Switches zu der Insertion gezählt werden.
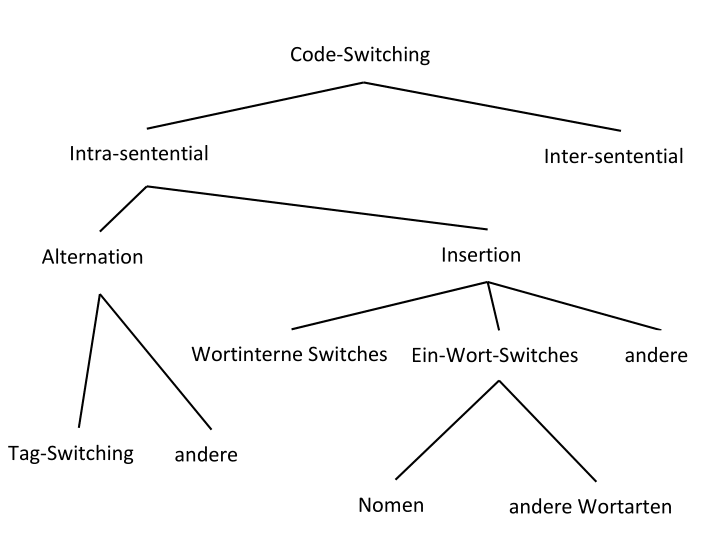
Strukturelle Typisierung für die Klassifizierung der CS in Facebook Beiträgen.
(Lizenz: CC BY SA)
Weiterhin wird erwartet, dass Tag-Switching aufgrund des hohen Grads der Geplantheit und Komplexität, die den Facebook Beiträgen zugrunde liegen, nicht so häufig vorkommt. Dafür werden sicherlich viele Einzel-Nomen-Switches sowie wortinterne Switches verwendet. Diese müssen dabei genauer betrachtet werden, denn man kann davon ausgehen, dass viele davon eher der Entlehnung als dem CS zugeordnet werden können. Gerade bei den aus dem Englischen stammenden Wörtern wird dies der Fall sein. Einzel-Wort-Switches wird es schließlich eher selten geben, und auch die verbleibenden Alternationen und Insertionen werden seltener vorkommen.
Es wird davon ausgegangen, dass die Verwendung von bestimmten strukturellen CS Typen mit deren kommunikativen Funktionen zusammenhängt. Diese werden deshalb im Laufe des nächsten Kapitels vorgestellt und in Hinblick auf die CMC diskutiert.
4.3. Sozio-pragmatische Funktionen von Code-Switching
Die Anfänge der CS Forschung lagen vor allem in der Soziolinguistik. CS wurde dabei auf der Basis seiner kommunikativen Funktionen begründet.
Einer der Vorreiter war John Gumperz (vgl. Blom & Gumperz 1972, Gumperz & Hymes 1972, 1982). Aber auch andere Forscher stellten fest, dass es viele Gründe und Motivationen für CS gibt, die sich sowohl auf den Kontext, als auch auf die Situation oder die Persönlichkeit des Produzenten zurückführen lassen (vgl. Hoffmann 1991, 115).
Nach Gumperz (vgl. 1982, 187) handelt es sich beim CS um eine Kontextualisierungsstrategie (en. contextualization cue), mit der der Sprecher dem Hörer vermitteln kann, wie seine Äußerung verstanden werden soll. CS wird danach häufig für organisatorische Zwecke eingesetzt (vgl. Auer 1988, 210). Der Sprachwechsel wirkt dabei als Verstärkung auf sprachliche, aber auch para- und nichtsprachliche Mittel oder ersetzt diese. CS eröffnet dem bilingualen Sprecher aber auch über organisatorische Zwecke hinausgehende Funktionen.
Dabei sei gleich vorweggenommen, dass sich die meisten Studien, die CS auf sozio-pragmatische Funktionen hin untersuchen, auf Daten der gesprochenen Sprache stützen. Gumperz (vgl. 1982, 59) belegt seine konversationellen Funktionen (siehe Kapitel ) beispielsweise mit Beispielen aus der natürlichen Sprache von Sprechern bilingualer Gemeinschaften (darunter die Sprachenpaare Spanisch und Englisch, Hindi und Englisch sowie Slowenisch und Deutsch). Auch Hoffmann (vgl. 1991, 111-112) und McClure (vgl. 1981, 72-73) stützen ihre Erkenntnisse und Untersuchungen auf Beispiele verschiedener Sprachenpaare des Gesprochenen.
Im Kontext der CMC erlebt dieser sozio-pragmatische Ansatz eine Renaissance, denn gerade hier stechen – je nach betrachteter Kommunikationsform – bestimmte in der klassischen CS-Forschung verwendete Funktionen hervor. Weitere Funktionen müssen im Rahmen der CMC wiederum ergänzt werden. Im Folgenden sollen deshalb verschiedene Kategorisierungen der Funktionen aus der klassischen CS-Forschung vorgestellt werden, die auch im Rahmen der CMC verwendet werden können (siehe dafür auch Kapitel ).
4.3.1. Situationsbedingtes Code-Switching
Gumperz (vgl. Blom & Gumperz 1972, 2000, Gumperz 1977, 1982) unterscheidet zunächst zwischen zwei Arten von Sprachmischungen: nämlich dem situationsbedingten (situational) und dem metaphorischen (metaphorical) bzw. konversationellen (conversational) CS.142 Bei Ersterem wird davon ausgegangen, dass “the notion of situational switching assumes a direct relationship between language and the social situation” (Blom & Gumperz 2000, 126). Situationsbedingtes CS findet statt, wenn Sprecher (oder Gesprächsteilnehmer) in verschiedenen sozialen Sprechsituationen verschiedene Sprachen oder Sprachvarietäten verwenden. Blom & Gumperz (ebd.) vergleichen hierbei eine lokale Sprachvarietät mit der Standardvarietät Norwegens. Diese Sprechsituationen sind gekennzeichnet vom Schauplatz oder dem Rahmen (beispielsweise zu Hause, im Klassenzimmer, auf dem Amt, etc.), von den beteiligten Sprechern (wie Lehrer, Freunde, Vorgesetzte, etc.) und der Beziehung, die zwischen Sprecher und den am Gespräch beteiligten Personen besteht (vgl. Blom & Gumperz 2000, 126). Auch Myers-Scotton (vgl. 1995, 52) geht bei diesem Typ von externer Motivation aus, zählt aber auch noch das Gesprächsthema zu einem der Gründe, aus denen geswitcht wird. Allerdings wird diese Art des CS von vielen Autoren nicht als solches betrachtet, da hier der oben dargelegten Definition folgend kein CS stattfindet. Vielmehr geht es hier um die Verwendung verschiedener Sprachen in unterschiedlichen Situationen. Deshalb wird auch hier der Begriff des situationsbedingten Sprachwechsels bevorzugt.
Dieser situationsbedingte Sprachwechsel kann auch bei den Facebook Beiträgen erwartet werden: Eine Statusmeldung wird auf Italienisch verfasst und die nächste auf Deutsch. Allerdings sind die externen Faktoren, die die Wahl der Sprache beeinflussen, sehr vielseitig. So könnte beispielsweise die aktuelle Umgebungssprache die Sprachwahl steuern. Die Sprache kann aber auch danach gewählt werden, welche Facebook Freunde damit angesprochen werden sollen. Ob hier überhaupt eine Klassifizierung von externen Kriterien möglich ist, soll Kapitel zeigen.
Es gibt des Weiteren auch Situationen, in denen die Sprecher sich nicht nur auf eine Sprache oder Varietät ihres linguistischen Repertoires beschränken. Das ist vor allem in zweisprachigen Sprechergemeinschaften der Fall, kann aber auch in der CMC beobachtet werden. Gumperz spricht hier von konversationellem CS, das im Folgenden beschrieben werden soll.
4.3.2. Konversationelles Code-Switching
Manchmal lässt CS nicht auf eine Änderung der Situation schließen; stattdessen werden durch den Sprachwechsel verschiedene kommunikative Effekte erzielt. Blom und Gumperz (2000, 127) nennen diesen Sprachwechsel metaphorisches oder konversationelles CS.143 Da dabei kein ersichtlicher Wechsel des Themas oder des außersprachlichen Kontexts stattfindet, ist dieser Typ sehr komplex. Myers-Scotton (vgl. 1995, 52) geht davon auf, dass hier vor allem die innere Motivation der Sprecher widergespiegelt wird; so lässt CS beispielsweise darauf schließen, wie die Interaktionspartner zu einem bestimmten Thema stehen. Die Wechsel des konversationellen CS können zudem – im Gegensatz zum situationsbedingten CS – sowohl inter- als auch intra-sentential stattfinden.
Konversationelle Funktionen von CS nach Gumperz
Zu den konversationellen Funktionen von CS zählt Gumperz (vgl. 1982, 75-82) die Folgenden:
- Zitate: CS markiert direkte Zitate und indirekte Rede.
- Spezifizierung des Adressaten: CS wird verwendet, um einen oder mehrere bestimmte Adressaten anzusprechen.
- Interjektionen: CS markiert eine Interjektion, einen Ausruf oder andere Satzfüller.
- Reiteration: der Inhalt wird in einer anderen Sprache wiedergegeben, entweder als direkte oder als inhaltliche (gegebenenfalls etwas modifizierte) Übersetzung. Sie dient der Erklärung, Betonung oder Hervorhebung einer Äußerung (oder eines Teils davon).
- Qualifikation der Nachricht: CS wird verwendet, um die Hauptnachricht zu markieren. Dies kann beispielsweise durch eine Erklärung, eine Bewertung oder eine Spezifikation dieser erfolgen.
- Personalisierung vs. Objektivierung: CS kann anzeigen, welcher Teil einer Rede eine persönliche Meinung darstellt und wo es sich um generelles Wissen handelt. Beispielsweise kann der Teil, bei dem eine persönliche Beteiligung vorliegt, in der einen Sprache ausgedrückt werden, während die objektive Sichtweise in einer anderen Sprache formuliert wird.
Es handelt sich aber eigentlich nicht bei all diesen genannten Typen um Funktionen und Motivationen, die dem konversationellen CS zugrunde gelegt werden können. So kann CS zwar aus dem Einfügen einer Interjektion (dieser Typ entspricht dabei dem Tag-Switching nach Poplack, siehe Kapitel ) oder einer Wiederholung in einer anderen Sprache bestehen. Diese stellen jedoch eher Strategien dar, die der tatsächlichen kommunikativen Funktion vorgeschaltet sind. Die von Gumperz (ebd.) angeführten Funktionen können schließlich auch keinen Anspruch auf Vollständigkeit erheben – wie der Autor selbst anmerkt – und so werden diese Funktionen bald von anderen Autoren, die CS mit verschiedenen sozio-pragmatischen Funktionen begründen, ergänzt.
McClure (1981, 80-85) merkt beispielsweise an, dass Betonung und Erklärung die eigentlichen Funktionen von CS darstellen, die nicht nur durch Reiteration (wie bei Gumperz), sondern auch durch den Sprachwechsel an sich erreicht werden. Gumperz‘ Qualifikation der Nachricht wird zudem als Ausarbeitung (en. elaboration) bezeichnet (McClure 1981, 80). Die Liste der konversationellen Funktionen wird des Weiteren um die Funktionen der Fokussierung, Erregung von Aufmerksamkeit oder Ablenkung sowie dem Themenwechsel ergänzt (ebd.).
Auch bei Hoffmann (1991, 115-116) werden im Großen und Ganzen die Funktionen nach Gumperz angegeben. Allerdings werden auch hier noch weitere Funktionen hinzugefügt: die lexikalische Notwendigkeit (wenn es ein Lexem in der anderen Sprache nicht gibt oder der Sprecher es nicht kennt) sowie der Wunsch, mögliche Konnotationen, die einem sprachlichen Element in einer Sprache anhaften könnten, zu vermeiden.
Auch in den Facebook Beiträgen kann erwartet werden, dass es zum einen konversationelles CS gibt, und dass zum anderen prinzipiell alle vorgeschlagenen Funktionen vorkommen können. Allerdings sollen diese getrennt betrachtet werden: nach den eigentlichen sozio-pragmatischen Funktionen und den Strategien, wie diese Funktionen erreicht werden können. Ein Modell in die Richtung zeigt die Einordnung der Funktionen in das Kommunikationsmodell nach Jakobson, das im Folgenden vorgestellt wird.
Die Funktionen von CS im Kommunikationsmodell
Appel & Muysken (1987, 119-120) fassen diese eben genannten Funktionen mit Hilfe von Jakobsons Kommunikationsmodell der sprachlichen Mitteilung zusammen (vgl. Jakobson 1960, 357). Danach werden Switches aus lexikalischer Notwendigkeit als referentielle Funktion klassifiziert. Eine direktive Funktion erfüllen wiederum Switches, mit denen andere Sprecher oder Sprechergruppen direkt angesprochen oder aber von einem Gespräch ausgeschlossen werden. Die Verwendung von CS, um eine gemischtsprachige Identität auszudrücken, zählen die Autoren zur expressiven Funktion. Sie verweisen damit auch auf die von Poplack gezogenen Schlüsse zu der Einstellung zum CS der von der Autorin untersuchten bilingualen Sprechergemeinschaft (vgl. Poplack 1980, 594-595).144 Außerdem wird CS dazu verwendet „to indicate a change in tone“ (Appel & Muysken 1987, 119). Dies wird von der phatischen Funktion erfüllt. Dazu zählen zudem sowohl die Emphatisierung, als auch die Gumperz‘sche Qualifikation einer Nachricht und die Personalisierung/Objektivierung. Die metalinguistische Funktion von CS dient dazu, direkt oder indirekt Bezug auf die involvierten Sprachen zu nehmen. Der Gebrauch zweier Codes dient hiernach dazu, anderen mit den eigenen linguistischen Fähigkeiten zu imponieren. Die letzte Funktion stellt schließlich die poetische Funktion dar, nach der die Sprecher CS in Witzen und Wortspielen verwenden.
Diese Aufteilung ist für die vorliegende Analyse von CS in Facebook Beiträgen nicht zielführend, es können hieraus jedoch einige Funktionen übernommen werden. So sind die wichtigsten Erkenntnisse aus diesem Modell die unter den letzten beiden Funktionen genannten Strategien. So wird gerade bei der CMC eine poetische Funktion erwartet, bei der CS in Witzen und Wortspielen zum Einsatz kommt. Des Weiteren spielt speziell im Falle der Facebook Beiträge die Selbstpräsentation eine wichtige Rolle. So kann auch die Verwendung von CS als ein Teil dieser Eigendarstellung angesehen werden, die dazu dient, anderen mit den eigenen Sprachkenntnissen zu imponieren.
Schließlich gibt es aber noch eine weitere Ursache für CS, auf die auch schon die direktive Funktion nach Appel & Muysken (ebd.) hinweist, die aber in den Facebook Beiträgen von besonderer Bedeutung ist und der deshalb der nächste Abschnitt gewidmet wird.
4.3.3. CS und Identität
Wie gemischtsprachige Äußerungen verstanden werden, wird zudem noch von einem weiteren Faktor bestimmt, nämlich der Richtung des Wechsels, der nach Gumperz eindeutig eine semantische Bedeutung trägt (vgl. Gumperz 1982, 93). In einer bilingualen Interaktion fungiert demnach eine der Sprachen als We-Code und die andere als They–Code. Mit We-Code wird dabei die Minderheitensprache, die für die eigene ethnische Gruppe steht und meist im privaten Bereich verwendet wird, bezeichnet. Der They-Code stellt die Mehrheitssprache, die die Minderheit umgibt, dar. Myers-Scotton (vgl. 1995, 54) merkt dazu an, dass der Status der Sprachen als We- oder They-Code dabei nicht statisch ist, sondern sich ändern kann. Der We-Code wird somit als Sprache zwischen Insidern verwendet und der They-Code als Sprache zum Austausch zwischen verschiedenen Sprachgruppen. Es gibt weitere Studien, die ebenfalls davon ausgehen, dass soziale Implikationen mit den Sprachen verbunden werden und CS sich diese als Strategie zu Eigen macht.145 So wird CS häufig dazu verwendet, um eine Gruppenidentität auszudrücken oder Solidarität zu zeigen (vgl. Hoffmann 1991, 116). Allerdings wird diese These nicht von allen gestützt, und so schreibt McClure (1981, 81),, „[w]e have not found this to be the case in our data“ was aber laut der Autorin auch auf das Forschungsdesign ihrer Studie zurückzuführen ist.146
Gerade bei einer SNS wie Facebook, bei der schon durch den Aufbau eines Netzwerkes und dem Hinzufügen von Freunden Gemeinschaften entstehen, ist die Identität sehr wichtig. Durch die Verwendung einer bestimmten Sprache spricht der Nutzer eine bestimmte Gruppe von Facebook Freunden an. Durch die Verwendung von CS begrenzt er diese schließlich auf entweder andere bilinguale Nutzer oder weitet diese – je nach Art des CS – auf alle Facebook Freunde aus. Auch in anderen Formen der CMC spielt die Identität eine Rolle und CS wird zur Wahrung oder Erschaffung dieser verwendet, wie das nächste Unterkapitel zeigt.
4.3.4. Gründe für und kommunikativen Funktionen von CS in der CMC
Es gibt einige Untersuchungen aus der CMC, die belegen, dass sich Beispiele für CS in der CMC finden lassen, die sich den auf Gumperz beruhenden konversationellen Funktionen zuordnen lassen. Im Folgenden soll dafür jedoch der Terminus kommunikative Funktion bevorzugt werden.
Montes-Alcalá (vgl. Montes-Alcalá 2007, 167-169) kommt nach der Analyse ihrer Daten zu einem ähnlichen Ergebnis wie die Autoren von Studien zum gesprochenen CS und auch die gefundenen Funktionen ähneln diesen: Der größte Teil der Sprachwechsel erfolgt aus lexikalischer Notwendigkeit, wobei die geswitchten Wörter häufig Verwandtschafts- und Familienbezeichnungen sind. Danach folgen Sprachwechsel zu emphatischen Zwecken und eine Gruppe, die als freies CS bezeichnet wird. Unter Letztere fallen alle Sprachwechsel, die sich keiner der anderen eindeutig zuordnen lassen oder eine Kombination derer darstellen; die Autorin vermutet hier eine stilistische Funktion (vgl. Montes-Alcalá 2007, 169). Die Sprache wird auch in den Blog Beiträgen zur Erklärung oder Erläuterung eines Sachverhalts gewechselt oder einzelne Tags werden aus einer anderen Sprache in eine ansonsten monolinguale Äußerung eingefügt. Sprachwechsel, die (direkte oder indirekte) Zitate einleiten, sind im Gegensatz zum Gesprochenen selten zu finden, ebenso wie durch ein bestimmtes Wort oder einen Ausdruck hervorgerufene getriggerte Wechsel.
Die Funktionen von CS sind auch nach Androutsopoulos & Hinnenkamp (vgl. 2001, 32-33) vergleichbar mit der direkten Interaktion in der Face-to-Face-Kommunikation. Sprachwechsel dienen dazu, Zusammengehörigkeit zu signalisieren. Sie markieren Distanzierung und Annäherung, aber auch Zustimmung oder Ablehnung. Es können dabei verschiedene Funktionen des Sprachwechsels (hier mit intra-sententialem CS gleichgesetzt) identifiziert werden (vgl. Androutsopoulos 2006, 185-190): die formelhafte Verwendung der Herkunftssprache, die zur Stärkung des We-Code führt, Wiederholungen zur Hervorhebung, Redeerwähnungen (Zitat nach Gumperz), Adressierung von bestimmten Personen(gruppen) und Kommentierung einer Äußerung. Ergänzt werden zudem die Funktionen von CS als Scherzkommunikation und zu Zwecken der Performance. Unter Scherzkommunikation versteht der Autor, dass eine Äußerung durch CS als Scherz markiert wird. Zu Performance wird eine „formbetonte, auf ein Publikum zugeschnittene Darbietung“ (Androutsopoulos 2006, 189) gezählt.
Andere Autoren sehen in der Performance ebenfalls eine weitere kommunikative Funktion von CS. So vermutet Georgakopoulous (vgl. 1997, 159), dass CS der Selbstpräsentation und der Anpassung an den Adressaten dient, sowohl in formellen, beruflichen als auch in informellen, intimen Konversationen. Lanz Vallejo (vgl. 2011, 64) stellt zudem fest, dass CS mit dem Ziel verwendet wird, sich selbst positiv zu präsentieren.147 Es wird ergänzt, dass CS zumeist eine sehr kreative Form des Sprachgebrauchs darstellt, sowohl auf lexikalischer, morphologischer, als auch auf syntaktischer Ebene. Die Wechsel können dabei eine humoristische, spielerische oder ironische Funktion erfüllen.
Auch bei Goldbarg (2009) werden die kommunikativen Funktionen untersucht. Die Autorin stellt fest, dass Spanisch in englisch-spanischen E-Mails häufig dazu verwendet wird, eine Aussage intimer oder freundlicher wirken zu lassen oder um das Humoristische zu unterstreichen. Switches, egal welcher Richtung, dienen dabei der Hervorhebung bestimmter Teile einer Nachricht. Aber auch die Themen können Sprachwechsel triggern, wobei spanische Elemente in einen ansonsten auf Englisch verfassten Text eingefügt werden, wenn es um persönliche und intime Themen geht, während Englisch in spanischen E-Mails häufig für technische Termini verwendet wird. Das führt die Autorin darauf zurück, dass Spanisch in den untersuchten E-Mails der Identifikation mit einer Gruppe dient. Bei anderen Studien konnte allerdings gezeigt werden, dass es nicht die Themen sind, die die Verwendung einer Sprache oder Sprachwechsel triggern (vgl. Androutsopoulos 2006, Hinrichs 2006). Es wird davon ausgegangen, dass der Gebrauch mehrerer oder bestimmter Sprachen häufig zu Zwecken der Identifikation mit einer Gruppe verwendet werden. Schon bei Paolillo (1996) wird Punjabi in Usenet Foren zur Identifikation mit der Sprechergruppe verwendet, während Englisch dort eine Prestige-Sprache darstellt, die vor allem wegen ihrer Vorherrschaft als Sprache des Internets verwendet wird. Auch Ackermann (2007) zeigt, dass ein gleicher Kode zur Identifikation dient, während ein anderer Kode zu einer Abgrenzung führt. Ackermann (vgl. 2007, 130) benennt in Folge dieser Beobachtung drei Funktionen von CS: vom Interaktionstypus abhängiges CS (Konsens oder Konflikt), CS als Hinweis für die Art der Interaktion (intim oder distanziert, formell oder informell148) oder durch formale Elemente getriggertes CS. Dabei konnte der Autor zeigen, dass CS häufig eine beabsichtigte Provokation darstellt, manchmal aber auch dazu dient, um humorvolle, ironische Kontexte herzustellen.
Nach Hidayats (2012) Untersuchungen von CS in Facebook Beiträgen gehören zu den am häufigsten mittels Fragebögen festgestellten kommunikativen Funktionen die lexikalische Notwendigkeit (45%) oder „talking about a particular topic“ (40%). Vereinzelt werden zu den Funktionen auch noch Zitate, Erklärungen und Gruppenidentität gezählt (je 5%). Allerdings ist die Anzahl der untersuchten Code-Switches sehr gering und die Methode, nach der die kommunikativen Funktionen erhoben wurde, birgt Gefahren.149 Auch bei Sukyadi & Wirza & Hasiani (vgl. 2012) wird vor allem die lexikalische Notwendigkeit und das Wahren einer Gruppenidenität hervorgehoben, wobei es auch hier keine genauen Angaben zu Anzahl und Vorkommen der Funktionen gibt.
In zwei Studien, die Facebook Beiträge von bilingualen malaysisch-englischen Studenten untersuchen, werden ebenfalls kommunikative Funktionen untersucht. In einer der beiden werden Beiträge mit CS auf deren kommunikative Funktionen in Anlehnung an Gumperz Klassifikation geprüft (vgl. Syazwani Halim & Maros 2014). Die Autoren finden in den 439 untersuchten Beiträgen Beispiele für jede der vorgeschlagenen Funktionen, fügen aber auch noch ökonomische Gründe als eine weitere Funktion hinzu. Das heißt, dass die jeweils andere Sprache auch in Fällen verwendet wird, in denen Wörter oder Phrasen kürzer sind oder um Ambiguitäten zu vermeiden (vgl. Syazwani Halim & Maros 2014, 132). Es werden auch hier keine genauen Angaben dazu gemacht, welche kommunikativen Funktionen wie oft vorkommen. In der zweiten Untersuchung wird die Sprachverteilung in 5000 Beiträgen untersucht, wobei 568 Beiträge mit CS gefunden werden (vgl. Shafie & Nayan 2013). Hierbei steht die primäre funktionelle Orientierung aller Beiträge und Kommentare im Vordergrund, das heißt die Autoren untersuchen, inwieweit die Funktionen, die Thurlow & Brown (2003) für das Schreiben von SMS Nachrichten nennen, in den Facebook Beiträgen gefunden werden können. Dabei stellen die Autoren fest, dass vor allem das Teilen von Informationen sowie das Aufrechterhalten von Freundschaften im Vordergrund stehen (vgl. Shafie & Nayan 2013, 194-196). Allerdings unterscheiden sich die primären Funktionen von SMS und Facebook Beiträgen, und es wäre zu erwarten gewesen, dass in Bezug zu den Facebook Statusmeldungen noch weitere Funktionen identifizierbar gewesen wären (siehe Kapitel ).
Zusammenfassend lässt sich festhalten, dass in den Studien zum CS in verschiedenen CMC Typen die kommunikativen Funktionen, die zu einem großen Teil auf denen von Gumperz und Hoffmann beruhen, bestätigt werden konnten. Es werden aber auch weitere Funktionen benannt, wie die humoristische und spielerische Verwendung von CS, die auf die sprachliche Kreativität der Verfasser bei der CMC zurückzuführen sind. Aber auch die Selbstpräsentation oder Performance spielen bei der Verwendung von CS in der CMC eine wichtige Rolle. Schließlich kann noch festgehalten werden, dass eine alternierende Verwendung von Sprachen eine Gruppenidentität fördert oder erschafft. Bei all diesen zusätzlichen Funktionen sollte allerdings beachtet werden, dass diese sehr vom Typ der CMC abhängen. Während ein spielerischer, kreativer Sprachgebrauch in allen CMC Typen erwartet werden kann, ist die Selbstpräsentation oder -darstellung vor allem bei Twitter, Blogbeiträgen oder eben Facebook eine wichtige kommunikative Funktion.
Schlussendlich bleibt anzumerken, dass in den meisten der eben vorgestellten Studien der Hauptkritikpunkt an Gumperz‘ Klassifizierung einfach mit übernommen wird. So fehlt auch hier oft eine Trennung zwischen den kommunikativen Funktionen und den Strategien, die dazu verwendet werden, diese Funktionen zu erfüllen. Wie oben gesehen, werden Wiederholungen auch für die CMC als Funktionen angeführt, die aber in erster Linie Strategien darstellen. Außerdem werden die primären Funktionen der CMC-Typen zu wenig beachtet, denn auch diese können letztendlich die kommunikativen Funktionen von CS in der CMC voraussagen. Abschließend sei festzuhalten, dass in keiner der Studien eine Korrelation zwischen den strukturellen Typen und den kommunikativen Funktionen untersucht wird. Hier soll aber davon ausgegangen werden, dass gerade diese strukturellen
(Unter-)Typen als Strategien für die Erfüllung von kommunikativen Funktionen verwendet werden.
Bei der Ermittlung der kommunikativen Funktionen des CS in den Facebook Beiträgen soll von den primären Funktionen dieser Form der CMC (siehe Kapitel ) ausgegangen werden. Dazu zählen das Berichten von personenbezogenen Informationen, das Teilen von Meinungen und Interessensbekundungen und eine humoristische, spielerische Verwendung. Als SNS dient Facebook des Weiteren der Netzwerkpflege und dem Austausch mit anderen Facebook Freunden (siehe Kapitel ). Aus diesen eben genannten allgemeinen Funktionen der Facebook Beiträge lassen sich auch Funktionen für das CS ableiten: So kann CS Meinung oder Interessensbekundung ausdrücken. Oder es dient der Selbstpräsentation, indem es den anderen Nutzern zeigt, dass der Nutzer mehrere Sprachen beherrscht oder sich als besonders weltgewandt betrachtet. Außerdem erfüllt CS eine Social-Networking-Funktion: CS dient dem Wahren oder Schaffen eine Gruppenidentität, indem nur bestimmte Facebook Freunde angesprochen werden oder die Verwendung mehrerer Sprachen eine Äußerung allen Facebook Freunden zugänglich macht. Schließlich dient Facebook auch dem Zeitvertreib, und in den Facebook Beiträgen werden häufig lustige, scherzhafte oder ironische Äußerungen gepostet. So kann auch CS benutzt werden, diese Funktion zu erfüllen, indem es besonders kreativ eingesetzt wird. Die Funktionen der Emphatisierung sowie CS aus Diskurs strukturierenden Gründen werden ebenfalls in den Facebook Beiträgen erwartet. Ob das Switchen aus lexikalischen Gründen hier Verwendung findet, soll schließlich ebenfalls überprüft werden.150 Um diese Funktionen zu erreichen, können verschiedene Strategien angewandt werden. Diese ergeben sich dabei aus den verwendeten strukturellen CS Typen, wie in der Auswertung gezeigt werden soll.
4.4. Hypothesen und Fragestellungen zum CS in CMC
Aus den dargestellten Ergebnissen und deren Diskussion lassen sich die Fragestellung und die Hyptohese, die dieser Arbeit zugrunde liegen, ableiten. Das Ziel dabei ist es, CS in Facebook Beiträgen zu untersuchen. Dabei soll die Frage beantwortet werden, wie und aus welchen kommunikativen Gründen deutsch-italienische Nutzer CS in Facebook Beiträgen verwenden.
In den vorangehenden Kapiteln konnte zum einen gezeigt werden, dass es sich bei den Facebook Beiträgen um einen Untersuchungsgegenstand handelt, der einer linguistischen Untersuchung wert ist, und zum anderen, dass es hier besondere Merkmale gibt, wobei CS als eines davon genauer betrachtet wird. Die Grundvoraussetzung dabei ist, dass in Facebook Beiträgen verschiedene Sprachen verwendet werden. Dabei wird in den Beiträgen der bilingualer Nutzer, die im Rahmen der vorliegenden Arbeit untersucht werden,
- sowohl zwischen Beiträgen, die komplett auf Italienisch oder Deutsch verfasst sind, gewechselt,
- als auch innerhalb eines einzigen Beitrags (= CS).
Davon ausgehend sollen die folgenden Hypothesen verifiziert werden:
- Es gibt einen Zusammenhang zwischen den Sprachen, die auf Beitragsebene verwendet werden und den Sprachen beim CS innerhalb einzelner Beiträge.
- Es lässt sich kein Zusammenhang zwischen externen Faktoren, wie dem Thema des Beitrags, und der verwendeten Sprache bzw. dem Sprachwechsel feststellen.
Dabei soll den Fragen nachgegangen werden, wie die Sprachen in den Beiträgen verteilt sind, ob bei bestimmten Nutzern eine der Sprachen überwiegt und ob davon ausgehend auch Vorhersagen zu den Sprachen des CS gemacht werden können.
Des Weiteren soll CS wie oben definiert in den Facebook Beiträgen betrachtet werden. Dafür werden die Facebook Beiträge, die mehr als eine Sprache enthalten, analysiert. Es werden zunächst die strukturellen Typen des CS quantitativ ausgewertet und anschließend die Funktionen, die damit erfüllt werden können, untersucht. Es wird erwartet, dass es mehr inter- als intra-sententiales CS gibt, da Facebook Beiträge geplant verfasst werden und CS deshalb selten spontan durch psycholinguistische Faktoren getriggert wird. Wenn CS vorkommt, wird es bewusst eingesetzt, um bestimmte kommunikative Funktionen zu erfüllen. Das führt zu den nächsten Hypothesen:
- In Facebook Beiträgen wird inter-sententiales CS bevorzugt.
Es wird erwartet, dass sich verschiedene Strategien von CS identifizieren lassen, mit denen bestimmte kommunikative Funktionen erreicht werden sollen. Auf Grundlage des Untersuchungsgegenstands und dessen primären kommunikativen Funktionen, ist eine Präferenz für bestimmte Funktionen erkennbar
- „Social-Networking“ und Selbstdarstellung sind die Hauptfunktionen bei der Verwendung von CS in Facebook Beiträgen.
Dabei wird auch der Frage nachgegangen, mit welchen Strategien diese Funktionen erreicht werden und ob sich hinsichtlich der Beitragsart und der Nutzer Präferenzen für bestimmte Strategien und somit deren kommunikativen Funktionen erkennen lassen.
Die eben vorgestellten Hypothesen und Fragestellungen sollen auf der Grundlage einer Datenanalyse beantwortet werden. Dafür wurden Daten gesammelt und in einem Korpus gespeichert und aufbereitet. Die Methode der Datensammlung, der Aufbereitung und die Korpusannotation werden im folgenden Kapitel präsentiert.
5. Das Facebook Korpus: Datensammlung und Methoden
Linguistische Korpora als Grundlage für die empirische Forschung sind aus der Sprachwissenschaft nicht mehr weg zu denken und auch für die Auswertungden der vorliegenden Arbeit wird ein Korpus verwendet. In diesem Kapitel soll deshalb die Methode der Datensammlung für das Korpus beschrieben werden. In einem ersten Schritt werden Vorüberlegungen angestellt und die Kriterien der Datensammlung erläutert, danach wird das Korpusdesign, also die Planung des Korpusaufbaus, präsentiert. Im Anschluss wird darauf eingegangen, wie die Rohdaten gesammelt und aufbereitet werden. Vorbereitend muss allerdings entschieden werden, welche Art von Korpus erstellt wird und welche methodische Rolle das Korpus in dieser Forschungsarbeit einnimmt. Dafür darf ein kurzer Überblick nicht fehlen, was im Allgemeinen unter einem linguistischen Korpus verstanden wird und welche Rolle Korpora und die Korpuslinguistik in der Sprachwissenschaft spielen.
Bereits in den 1940er Jahren entstehen die ersten linguistischen Korpora.151 Dabei handelt es sich zunächst um Karteikasten ähnliche Sammlungen sprachlicher Materialien von kleinem Umfang, die vor allem für die Lexikographie relevant sind (vgl. Spina 2001, 19). Einer der nachweislich Ersten, der sich den Computer und die damit verbundenen Technologien zunutze macht, ist der Jesuitenpater Roberto Busa aus Italien, der 1946 den Gründer von IBM, Thomas J. Watson, überzeugt, die Werke von Thomas von Aquin mit Hilfe von IBM Technologien zu digitalisieren und so mit Hilfe eines Computers analysierbar zu machen (vgl. McEnery & Hardie 2012, 20, Spina 2001, 20).152 Nachdem die empirische Arbeit mit Korpora in der Sprachwissenschaft zunächst durch den Generativismus153 gebremst wird, entstehen mit dem Aufkommen neuer technologischer Mittel Ende der 1960er Jahre die ersten großen, systematischen und computergestützten Korpora, wie beispielsweise das Brown Corpus oder das Lancaster-Oslo & Bergen Corpus (vgl. Spina 2001, 22–29).
It was not the linguistic climate but the technological one that stimulated the development of corpora. The computer was on the horizon, and although the first computers were extremely difficult to work with, their great potential was correctly assessed from an early date. (Tognini-Bonelli & Sinclair 2006, 207)
Seitdem hat sich die linguistische Forschung mit Hilfe von Korpora weiter entwickelt und aus der Korpuslinguistik als „Werkzeugkasten“ ist eine eigenständige Methodologie enstanden (vgl. Perkuhn & Keibel & Kupietz 2012, 19). So stellt Tognini-Bonelli (, 1) fest, dass die Korpuslinguistik „goes well beyond this purely methodical role“ und mittlerweile eine eigene Disziplin darstellt.
Ein linguistisches Korpus wird dabei meist als “a collection of (1) machine-readable (2) authentic texts (including transcripts of spoken data) which is (3) sampled to be (4) representative of a particular language or language variety” (McEnery & Xiao & Tono 2006, 5) definiert. Je nach Forschungsfrage und Interessensgebiet haben sich dabei verschiedene Korpustypen etabliert. Während generelle Korpora oder Referenzkorpora einer allgemeinen Sprachbeschreibung dienen und deswegen alle sprachlichen Varietäten einer Sprache in einem bestimmten Zeitabschnitt enthalten, repräsentieren spezialisierte Korpora hingegen eine bestimmte Untergruppe der Sprache, wobei es sich beispielsweise um die Repräsentation einer bestimmten sprachlichen Varietät handeln kann. Oder das Korpus repräsentiert nur die Sprache bestimmter Sprecher(gruppen) oder Texte einer bestimmten Textsorte.154 Auch das Internet wurde in zweierlei Hinsicht interessant für die Korpuslinguistik. Zum einen kann das WWW selbst mithilfe von Suchmaschinen (wie z.B. google, yahoo, etc.) als Korpus verwendet werden, zum anderen können aus den Inhalten des Internets Referenzkorpora erstellt werden (wie beispielsweise die Korpora des Projekts WaCky ‚Web as Corpus kool ynitiative’ (vgl. Baroni & Bernardini & Ferraresi & Zanchetta 2009).
Des Weiteren haben sich zwei Methoden in der Korpuslinguistik etabliert: der korpusbasierte und der korpusgestützte Ansatz (vgl. Lemnitzer & Zinsmeister 2010, 18–19).155 Bei der ersteren Methode stellt das Korpus die einzige Quelle für Sprachtheorien und Sprachhypothesen dar. Aussagen und Regularitäten über die Sprache werden daraus abgeleitet und im Anschluss daran können sie durch weitere Beobachtungen bestätigt, modifiziert oder verworfen werden. Nach einem korpusgestützten Ansatz verifizieren oder falsifizieren die Korpusdaten linguistische Theorien oder Hypothesen.
Bei dem für diese Arbeit erstellten Korpus handelt es sich um ein spezialisiertes Korpus, das die Kommunikationsformen Facebook Statusmeldungen und Posts von Nutzern enthält, die sowohl auf Italienisch als auch auf Deutsch schreiben. Es stellt also kein Referenzkorpus dar und kann somit auch nicht dem Anspruch gerecht werden, allgemeine Aussagen über das Italienische, das Deutsche oder eben die CMC zu treffen. Es enthält außerdem textbasierte Elemente aus mehreren Sprachen und ist somit multilingual.
Die Forschungsarbeit ist als korpusgestützt zu betrachten, da im Vorfeld Fragestellungen und Hypothesen aufgestellt werden, die anschließend mit den Korpusdaten verifiziert und belegt werden. Allerdings können bei der Datenauswertung Beobachtungen gemacht werden oder es fallen Besonderheiten ins Auge, die danach als Basis für weiterführende Studien dienen können.
Bei der Korpuserstellung werden verschiedene Schritte durchlaufen. Zunächst wird ein Korpusdesign entworfen. Bei der darauffolgenden Datensammlung und -strukturierung geht es vornehmlich um die technische Aufbereitung der Daten – wie also aus „Rohdaten“ (Perkuhn & Keibel & Kupietz 2012, 54) ein Korpus wird. Den Primärdaten werden schließlich Metadaten verschiedener Art hinzugefügt. Zuletzt erfolgt die Korpusannotation, wobei den sprachlichen Daten linguistische Informationen, die auf einer Analyse und Interpretation dieser Daten beruhen, hinzugefügt werden. In den folgenden Unterkapiteln sollen zunächst einige Vorüberlegungen zur Korpusplanung angestellt werden und Kriterien, nach denen die Datensammlung erfolgen soll, werden definiert. Danach folgen die einzelnen Schritte der eigentlichen Datensammlung sowie eine Übersicht über die Korpusdaten. Den Abschluss dieses Kapitels stellt die Methode der linguistischen Annotation, die für diese Arbeit entwickelt und verwendet wurde, dar.
5.1. Vorüberlegungen und Kriterien zur Datenauswahl
Bei der Korpusplanung spielen vor allem die Art und das Format der Primär- und Metadaten und deren Herkunft eine Rolle. Aber auch Kriterien, welche die Datensammlung eingrenzen, müssen ausgearbeitet werden. An erster Stelle müssen aber Vorüberlegungen zum Datenschutz angestellt werden.
5.1.1. Datenschutztechnische Vorüberlegungen
Primärdaten sind nicht frei von Rechten Dritter. Während bei Audio- und Videodateien auf die informationelle Selbstbestimmung und die Persönlichkeitsrechte der Probanden geachtet werden muss, gelten bei Textdaten die Urheberrechte der Autoren und die Leistungsschutzrechte von Verlagen. Bei der Erstellung und Verbreitung von Korpora kann es so zu einer Kollision von Grundrechten kommen, denn auf der einen Seite steht die Freiheit der Wissenschaft und auf der anderen Seite das Recht auf Privateigentum bzw. die Persönlichkeitsrechte.
Relevant für Textkorpora ist das Urheberrechtsgesetz (UrhG), das in Deutschland gültig ist. Es gilt automatisch für jedes Werk, das eine Schöpfungshöhe erreicht und ist bis 70 Jahre nach Tod des Urhebers wirksam. Werke müssen dabei eine mit den Sinnen „wahrnehmbare Formgestaltung“ besitzen und es muss sich um eine „persönliche geistige Schöpfung“ handeln (§2, Geschützte Werke, UrhG). Dieses Kriterium schließt einerseits Zufallsentstehungen, Fundstücke und von Tieren produzierte Werke aus. Außerdem verlangt es eine dem Schöpfer zuzurechnende Individualität des Werkes ab.
Geschützte Werke nach § 2 (UrhG):
(1) Zu den geschützten Werken der Literatur, Wissenschaft und Kunst gehören insbesondere:
- Sprachwerke, wie Schriftwerke, Reden und Computerprogramme;
- Werke der Musik;
- pantomimische Werke einschließlich der Werke der Tanzkunst;
- Werke der bildenden Künste einschließlich der Werke der Baukunst und der angewandten Kunst und Entwürfe solcher Werke;
- Lichtbildwerke einschließlich der Werke, die ähnlich wie Lichtbildwerke geschaffen werden;
- Filmwerke einschließlich der Werke, die ähnlich wie Filmwerke geschaffen werden;
- Darstellungen wissenschaftlicher oder technischer Art, wie Zeichnungen, Pläne, Karten, Skizzen, Tabellen und plastische Darstellungen.
(2) Werke im Sinne dieses Gesetzes sind nur persönliche geistige Schöpfungen.
(§2; UrhG)
Danach kann allein schon die Datensammlung für ein Korpus unter Umständen rechtswidrig sein. Probleme kann es aber vor allem dann geben, wenn ein Korpus öffentlich zugänglich gemacht werden soll – auch wenn dies ausschließlich akademischen Zwecken dient. So steht in § 52a (UrhG) über die öffentliche Zugänglichmachung für Unterricht und Forschung:
(1) Zulässig ist,
- veröffentlichte kleine Teile eines Werkes, Werke geringen Umfangs sowie einzelne Beiträge aus Zeitungen oder Zeitschriften zur Veranschaulichung im Unterricht an Schulen, Hochschulen, nichtgewerblichen Einrichtungen der Aus- und Weiterbildung sowie an Einrichtungen der Berufsbildung ausschließlich für den bestimmt abgegrenzten Kreis von Unterrichtsteilnehmern oder
- veröffentlichte Teile eines Werkes, Werke geringen Umfangs sowie einzelne Beiträge aus Zeitungen oder Zeitschriften ausschließlich für einen bestimmt abgegrenzten Kreis von Personen für deren eigene wissenschaftliche Forschung öffentlich zugänglich zu machen, soweit dies zu dem jeweiligen Zweck geboten und zur Verfolgung nicht kommerzieller Zwecke gerechtfertigt ist.
(2) Die öffentliche Zugänglichmachung eines für den Unterrichtsgebrauch an Schulen bestimmten Werkes ist stets nur mit Einwilligung des Berechtigten zulässig. Die öffentliche Zugänglichmachung eines Filmwerkes ist vor Ablauf von zwei Jahren nach Beginn der üblichen regulären Auswertung in Filmtheatern im Geltungsbereich dieses Gesetzes stets nur mit Einwilligung des Berechtigten zulässig.
(3) Zulässig sind in den Fällen des Absatzes 1 auch die zur öffentlichen Zugänglichmachung erforderlichen Vervielfältigungen.
(4) Für die öffentliche Zugänglichmachung nach Absatz 1 ist eine angemessene Vergütung zu zahlen. Der Anspruch kann nur durch eine Verwertungsgesellschaft geltend gemacht werden.
(§ 52a; UrhG)
Es gibt demnach durchaus Wege zu einem legalen Korpus. So können Texte verwendet werden, die grundsätzlich nicht urheberrechtlich geschützt sind (z.B. Gesetzestexte) oder bei denen die Urheberrechte abgelaufen sind. Außerdem kann ein Korpus aus Einheiten, bei denen die Schöpfungshöhe nicht erreicht wird (z.B. zufällig aneinander gereihte Sätze, einzelne Beiträge) erstellt werden, das nur nicht kommerziellen Zwecken dient.
Für ein Korpus aus Facebook Daten ergeben sich noch weitere Probleme. Lange Zeit galt das Recht an auf Facebook veröffentlichten Inhalten als Grauzone und es kursierten Gerüchte, dass man mit dem Teilen von Bildern, Textbeiträgen und anderen Inhalten jegliche Rechte daran an Facebook überträgt. In einer „Erklärung der Rechte und Pflichten“ ( 2016a) heißt es allerdings
Dir gehören alle Inhalte und Informationen, die du auf Facebook postest. Zudem kannst du mithilfe deiner Einstellungen für Privatsphäre und Appskontrollieren [sic!], wie diese geteilt werden. Außerdem gilt:
1. Für Inhalte, die durch Rechte am geistigen Eigentum geschützt sind, wie Fotos und Videos (IP-Inhalte), erteilst du uns ausdrücklich nachfolgende Genehmigung, vorbehaltlich deiner Einstellungen für Privatsphäre und Apps: Du gewährst uns eine nicht-exklusive, übertragbare, unterlizenzierbare, gebührenfreie, weltweite Lizenz für die Nutzung jedweder IP-Inhalte, die du auf bzw. im Zusammenhang mit Facebook postest (IP-Lizenz). Diese IP-Lizenz endet, wenn du deine IP-Inhalte oder dein Konto löschst; es sei denn, deine Inhalte wurden mit anderen geteilt und diese haben die Inhalte nicht gelöscht. […]
4. Wenn du die Einstellung „Öffentlich“ bei der Veröffentlichung von Inhalten oder Informationen verwendest, können alle Personen, einschließlich solcher, die Facebook nicht nutzen, auf diese Informationen zugreifen, sie verwenden und sie mit dir (d. h. mit deinem Namen und Profilbild) assoziieren. […]
Das heißt, die Urheberrechte bleiben bei den Facebook Nutzern und Facebook erhält, bei Accounts, die nicht „öffentlich“ verwendet werden, lediglich die Lizenz diese Inhalte (beispielsweise für Werbezwecke) nutzen und anzeigen zu dürfen.156
Für die Erstellung eines Facebook Korpus heißt das, dass nur die geistigen Eigentümer der Inhalte im Sinne des Urheberrechtgesetztes – die Facebook Nutzer – um Erlaubnis gefragt werden müssen, um die Daten zu extrahieren, zu analysieren und schließlich zu veröffentlichen. Des Weiteren kann eine Verletzung des UrhG vermieden werden, indem die Schöpfungshöhe nicht erreicht wird. So werden beispielsweise nur einzelne textbasierte Inhalte extrahiert und nicht die Facebook Chronik als Ganzes. Eine weitere Vorsichtsmaßnahme stellt die Anonymisierung der Facebook Nutzer und ihrer persönlichen Daten dar. Schlussendlich sollen nicht alle im Korpus enthaltenen Tabellen veröffentlicht werden, sondern nur die für diese Forschungsarbeit relevanten Teile, die außerdem auf ein Publikum mit rein wissenschaftlichem Interesse, das zudem für eine Konsultation eine Lizenz beantragen muss, beschränkt werden.
Nachdem also die datenschutzrechtlichen Fragen geklärt sind sowie eine Lösung zur Erstellung eines legalen Facebook Korpus gefunden ist, sollen nun von den Nutzern abhängige Kriterien geklärt werden, die die Datensammlung einschränken.
5.1.2. Eingrenzung auf private Facebook Nutzer
Die Anzahl der Facebook Nutzer ist in den letzten Jahren rasant gestiegen und das Netzwerk hat sich zu einer Plattform entwickelt, die nicht mehr nur Studenten, sondern mittlerweile allen Bevölkerungsgruppen und -schichten zugänglich ist (siehe DEFAULT). In den Einstellungen eines Accounts kann jeder Nutzer selbst entscheiden, für wen seine Facebook Chronik und somit sein persönliches Profil und die geposteten Statusmeldungen und Posts einsehbar sind. Er kann entscheiden, ob sie von allen Facebook Nutzern („öffentlich“) oder nur von Facebook Freunden gelesen werden können (siehe DEFAULT). Mittlerweile können Accounts sogar auf bestimmte Untergruppen beschränkt werden.157 Die meisten privaten Facebook Nutzer machen ihre Profile zur Wahrung ihrer Privatsphäre nicht öffentlich zugänglich, sondern erlauben nur ihren Facebook Freunde eine Einsicht.
Bei den Facebook Nutzern handelt es sich aber nicht nur um Privatpersonen. 50 Millionen kleine und mittelständische Unternehmen sind mittlerweile auf Facebook vertreten (vgl. Hutter 2015). Ebenso haben berühmte Personen aus Politik, Kunst, Sport oder anderen Bereichen der Öffentlichkeit oft neben ihren privaten Accounts auch noch öffentliche Profile, die in vielen Fällen von sogenannten Social Media Managern verwaltet werden (ebd.). Zwar gibt es bei Facebook seit 2007 die Möglichkeit, Facebook Seiten (en. Facebook Pages) zu erstellen, aber häufig werden auch öffentliche Profile dafür verwendet, die nicht nur als Chronik einer Einzelperson, sondern – genauso wie die Facebook Seiten – häufig von mehreren Personen nach den Standards und Vorgaben des Seiten- oder Profiladministrators gestaltet werden.158 Öffentliche Seiten und Profile können zudem von jedem Internetnutzer – egal ob selbst Nutzer von Facebook oder nicht – aufgerufen werden (siehe DEFAULT).
In der vorliegenden Arbeit stehen die Facebook Statusmeldungen von Chroniken von Privatpersonen im Fokus. Die Chroniken der Facebook Nutzer werden von den Nutzern selbst gestaltet und verwaltet; es kann also davon ausgegangen werden, dass die Statusmeldungen immer nur von ein und derselben Person verfasst werden. Außerdem sind die Facebook Chroniken von Privatpersonen meist nur für Facebook Freunde einsehbar – abhängig von den individuellen Einstellungen – und Interaktionen jeglicher Art (Facebook Posts und Kommentare) finden nur mit Personen, die dem Nutzer bekannt sind, statt.
5.1.3. Nutzerspezifische Kriterien für die Datenauswahl
Für das Facebook Korpus sollen die Daten einer möglichst homogenen Gruppe von Facebook Nutzern extrahiert werden. Hierfür werden die autobiographischen Daten, die die Nutzer in ihren Accountinformationen veröffentlichen, gesammelt und mit den Daten typischer Facebook Nutzer verglichen.
Facebook war anfangs noch Studenten vorbehalten, öffnete sich aber rasch anderen Altersgruppen. Es wird trotzdem davon ausgegangen, dass diese Plattform hauptsächlich von Personen der „Generation 2.0“ genutzt wird.159 Wie in Abbildung 21 exemplarisch für Deutschland gezeigt wird, lässt sich so bei einem Vergleich der Anzahl der Nutzer von 2011 und 2014 feststellen, dass es insgesamt in allen Altersklassen einen Anstieg gab:
Facebook Nutzer in Deutschland nach Altersgruppen in den Jahren 2011 und 2014 (in Millionen) ( 2016).
(Lizenz: CC BY SA)
Auch wenn es vor allem in den Nutzergruppen ab 35 Jahren zwischen 2011 und 2014 einen Anstieg gab, dominieren trotzdem nach wie vor die jüngeren Nutzer unter 35 Jahren die SNS Facebook: in 2011 sind mit 10 Millionen 73% aller Facebook Nutzer jünger als 35 Jahre, in 2014 sind es mit 17,4 Millionen 64 % aller Nutzer.160
Bei der Verteilung nach biologischem Geschlecht wird deutlich, dass es im Jahre 2010 bei der Verwendung von Facebook bei männlichen und weiblichen Nutzern kaum Unterschiede gibt, wie Abbildung 22 zeigt. Bis zum Jahre 2014, in dem es schließlich über eine Millionen mehr männliche als weibliche Nutzer gibt, entsteht hier eine Kluft bei der Verteilung der Facebook Nutzer nach männlichem und weiblichem Geschlecht.
Anzahl der aktiven Nutzer von Facebook in Deutschland in den Jahren 2010 bis 2014 nach Geschlecht (in Millionen) ( 2016).
(Lizenz: CC BY SA)
Das könnte nun damit gerechtfertigt werden, dass das männliche Geschlecht, das oftmals für technisch versierter gehalten wird, häufiger das Internet nutzt und deswegen auch häufiger bei Facebook registriert ist. Tatsächlich überwiegen aber in der Gesamtheit aller aktiven Internetnutzer die weiblichen mit 71% Registrierungen bei Facebook im Jahr 2013, während es bei den männlichen nur 61% waren (vgl. 2016).
Facebook verbreitet sich nach seiner weltweiten Öffnung rasant und löst vielerorts kleinere, auf eine bestimmte Region oder ein bestimmtes Land begrenzte SNS ab (oder führte zu einem Einbruch der Mitgliederzahlen, siehe DEFAULT). Mittlerweile ist Facebook fast auf der ganzen Welt vertreten (siehe Abbildung 24). Im Jahr 2013 verwenden in Nord-und Lateinamerika, im Mittleren Osten sowie in Westeuropa über die Hälfte aller Personen, denen Internet zur Verfügung steht und die dieses auch regelmäßig benutzen, mindestens einmal im Monat Facebook. Wie schon in Kapitel dargestellt, benutzen dabei in Deutschland 43% aller Internetnutzer monatlich die SNS Facebook, in Italien sind es sogar 71% (vgl. Hutter 2015). In Osteuropa nutzt nur knapp die Hälfte und im Asien-Pazifik-Raum gerade einmal ein Viertel aller Internetnutzer Facebook. Das liegt nicht etwa daran, dass die Internetnutzer hier weniger an SNS interessiert sind, sondern daran, dass es hier alternative Plattformen gibt und der Wunsch, sich auch über die Landesgrenzen hinaus mit Nutzern auf der ganzen Welt zu vernetzen, nicht so stark ausgeprägt oder gar nicht vorhanden ist.161
Anteil der Internetnutzer, die in 2013 Facebook mindestens einmal monatlich nutzen nach Weltregionen (vgl. 2016).
(Lizenz: CC BY SA)
Die Nutzer des Facebook Korpus sollen einen guten Mittelwert der Facebook Nutzer darstellen. Dabei wird erwartet, dass die Nutzer im Schnitt ebenfalls der Generation 2.0 angehören, also unter 35 Jahre alt sind. Außerdem wird erwartet, dass sich sowohl männliche als auch weibliche Nutzer mit dem Account vernetzen. Allerdings wird es keine Voraussetzung sein, dass die Nutzer für das Projekt entweder aus Deutschland oder aus Italien stammen oder dort wohnen, da Facebook weltweit als virtueller Raum verfügbar ist und in verschiedenen Sprachen verwendet werden kann. Eine Eingrenzung kann deshalb nicht auf einer geographischen Ebene stattfinden, sondern sollte sich auf die Verwendung von Sprache(n) beziehen.
5.1.4. Sprachliche Eingrenzung der Datenextraktion
Die zu untersuchenden Facebook Statusmeldungen und Posts sollen von Nutzern stammen, die sowohl auf Italienisch, als auch auf Deutsch schreiben. Das setzt voraus, dass die Nutzer beide Sprachen beherrschen und führt damit zu der Frage, ob diese Facebook Nutzer somit als bilinguale Sprecher des Deutschen und Italienischen bezeichnet werden können. Es gilt also zum einen zu klären, was genau unter Mehrsprachigkeit im Allgemeinen und bei den Facebook Nutzern im Besonderen verstanden wird. Zum anderen muss überlegt werden, wie Mehrsprachigkeit als Kriterium für die Eingrenzung der Nutzeraccounts zur Datensammlung für das Facebook Korpus angewandt werden soll.
Eine terminologisch eindeutige Definition des Begriffs der Mehrsprachigkeit ist nicht möglich, denn„[a]us sprachwissenschaftlicher Sicht ist der Versuch, Ein-, Zwei- oder Mehrsprachigkeit kategorisch voneinander abzugrenzen, zum Scheitern verurteilt.“ (Tracy 2014, 18). Generell kann mit Mehrsprachigkeit oder Bilingualismus – oft, aber nicht immer synonym verwendet – der tatsächliche Sprachgebrauch, die Sprachkompetenz der Sprecher sowie der Sprachsituation in einer ganzen Nation oder Gesellschaft gemeint sein (vgl. Clyne 1997, 301).162
Zu Sprachsituation würde in Bezug auf die CMC und die Facebook Statusmeldungen die Sprachsituation im Internet zählen. Unter Mehrsprachigkeit im Internet versteht man dabei zum einen auch den Landesgrenzen überwindenden, globalen kommunikativen Austausch. Zum anderen zählt dazu auch die Verwendung mehrerer Sprachen in der CMC innerhalb eines Landes (vgl. Danet & Herring 2007, 3-6). So gibt es in Ländern, wie Deutschland und Italien, nur eine einzige offizielle Amtssprache, im Netz werden aber neben dieser noch viele andere Sprachen verwendet.163 Bei diesen Sprachen kann es sich sowohl um Regional- oder Minderheitensprachen handeln, als auch um die Sprachen von Migranten. Im deutschen Internet können beispielsweise verschiedene Ethnoportale ausgemacht werden, in denen Nutzer mit Migrationshintergrund neben Deutsch, auch noch ihre Erstsprache(n) verwenden (vgl. Androutsopoulos 2006). Eine Definition der Mehrsprachigkeit im Internet nach der sprachlichen Situation und Verwendung von Sprachen in der CMC ist allerdings sehr weit gefasst und nicht zielführend für die Fragestellungen, die dieser Arbeit zugrunde liegen. Vielmehr geht es dabei um die Beiträge deutsch-italienischer Facebook Nutzer, weshalb eine Definition auf diese bezogen sein sollte und entweder die sprachliche Kompetenz oder den tatsächlichen Sprachgebrauch bestimmen soll.
Wann eine Sprache beherrscht wird, lässt sich an verschiedenen Faktoren messen (vgl. Zurer Pearson 2009, 380-384): Als Kriterien werden hier zum einen die sprachlichen Kompetenzen und Fähigkeiten der Sprecher angeführt. Zum anderen kann auch der außersprachliche Kontext, in dem eine Sprache erworben wird (z.B. Migration, familiäres Umfeld, etc.), eine Rolle spielen. Auch der Zeitpunkt des Erwerbs einer Sprache wird häufig als ein wichtiges Kriterium angeführt; entscheidend dabei ist das Alter und die Reihenfolge bzw. Gleichzeitigkeit des Spracherwerbs (vgl. ebd.). Schließlich kann auch noch die Beziehung der beteiligten Sprachen untereinander eine Rolle spielen.164
Definitionen, die Bilingualismus anhand des Sprachgebrauchs und der –kompetenz bestimmen, können durchaus stark variieren. Nach einer engen Definition spricht man nur bei dem doppelten Erstspracherwerb von Bilingualismus. Dabei werden zwei Sprachen als Erstsprachen – gemeinhin als Muttersprachen bezeichnet – in einem natürlichen Umfeld (also nicht gesteuert und institutionalisiert) erworben, meist schon in frühestem Kindesalter (vgl. Romaine 1995, 165-166). Nach einer etwas weiteren Definition kann dazu auch der spätere Erwerb einer Zweit- oder Fremdsprache gezählt werden. Bei Grosjean (vgl. 2008, 10) heißt es „Bilingualism is the regular use of two or more languages (or dialects), and bilinguals are those people who use two or more languages (or dialects) in their everyday lives”. Auch nach Myers-Scotton (vgl. 2006, 65) ist jeder Sprecher, der in mehr als einer Sprache zumindest alltägliche Gespräche führen kann, bilingual.165
Für die Bestimmung des „Online Bilingualismus“ soll ebenfalls eine weite Definition angesetzt werden, nach der jeder Facebook Nutzer, der mehr als eine Sprache in der CMC verwendet, als bilingual angesehen wird. Dabei muss aber ein gewisses Maß an Sprachkompetenz erkennbar sein und es muss sich bei dem Material aus anderen Sprachen nicht nur um einzelne Okkurrenzen handeln. Was die Kompetenz betrifft, können Aussagen nur auf Grundlage der Performanz auf morphologischer und syntaktischer Ebene getroffen werden – phonologische Integration ist bei textbasierter CMC nicht erkennbar, sondern allein die Verwendung grammatischer Strukturen und die Variation im Wortschatz sind Indikatoren, die auf die Kompetenz schließen lassen. Die Verwendung der Sprachen muss zudem in einem gewissen Maße stattfinden, soll heißen, dass hier nicht nur einzelne Token aus einer anderen Sprache stammen dürfen (hierbei spricht man dann eher von Lehngut/Fremdwort/Nonce-Borrowing, siehe DEFAULT), sondern dass die Sprachen regelmäßig benutzt werden, wenn auch nicht unbedingt in gleichem Umfang.166 Außerdem können noch Informationen zu Sprachbiografien und des außersprachlichen Kontextes der Nutzer, die häufig in den Facebook Accounts angegeben werden, den Status der Bilingualität verifizieren. Es ist dabei wichtig, die „Online Bilingualität“ von der „Bilingualität im Real Life“, also in der Realität außerhalb des virtuellen Raums, abzugrenzen. Auf SNS ist die Selbstdarstellung der Facebook Nutzer ein wichtiges Merkmal und durch das Verwenden mehrerer Sprachen stellt sich der Nutzer bewusst als bilingual dar – auch wenn er vielleicht außerhalb des virtuellen Raumes des Internets nur eine Sprache verwendet.
Zusammenfassend heißt das, dass für die Analyse nur die Statusmeldungen und Posts von bilingualen Facebook Nutzern untersucht werden sollen, die sowohl auf Deutsch als auch auf Italienisch (und eventuell ebenso auf anderen Sprachen) schreiben. Ausschlaggebend für die Berücksichtigung eines Facebook Accounts für die Datenextraktion ist die tatsächliche und hinreichende Verwendung beider Sprachen in den textbasierten Statusmeldungen und Posts. Die sprachbiografischen und außersprachlichen Informationen zu den Nutzern unterstützen die Auswahl der Nutzer-Accounts.
5.1.5. Zeitliche Eingrenzung bei der Datenextraktion
Die Facebook Statusmeldungen und Posts sollen auch zeitlich nach dem Datum ihrer Veröffentlichung gefiltert und sortiert werden, denn wie in 2.1.1. zu erkennen, gibt es immer wieder Entwicklungen und Neuerungen bei Facebook. So sollen die Beiträge ab 2009 extrahiert werden, da es Facebook erst seit 2008 auf Italienisch und Deutsch gibt und es sich deshalb auch erst ab diesem Zeitpunkt in Europa verbreitet hat. Davor gab es zudem viele konkurrierende SNS, sowohl in Italien als auch in Deutschland, die erst nach der europäischen Öffnung Facebooks und der Einführung verschiedener Sprachversionen langsam an Bedeutung (und somit an Größe aktiver Mitgliederzahlen) verloren. Deshalb kann davon ausgegangen werden, dass erst ab 2009 regelmäßig Statusmeldungen und Posts von den Nutzern veröffentlicht wurden. Außerdem wurden Ende 2008/ Anfang 2009 wichtige Funktionen eingeführt, wie der Facebook Chat und der „gefällt mir“-Button (siehe Tabelle 1), die die kommunikativen Anwendungen maßgeblich prägten.
Den Endpunkt der zu extrahierenden Daten stellt das Jahr 2013 dar. In diesem Jahr änderte sich das Aussehen der Statusmeldungen oder Posts durch Neuerungen. Dazu gehörten beispielsweise die Einführung einer Liste mit Emotionen und Aktivitäten, aus denen der Nutzer wählen kann sowie die Einführung einer Version für Mobiltelefone und die Übernahme einer Anwendung, die dem Teilen von Fotos dient (Instagram). Schließlich stellt das Jahr 2013 auch hinsichtlich des Arbeitsplans des Promotionsprojekts einen guten Endpunkt der Datensammlung für das Facebook Korpus dar.
Nachdem nun die von den Nutzern abhängigen Faktoren vorgestellt wurden, die die Sammlung von Daten auf die für das Korpus und die zugrundeliegenden Forschungsfragen einschränkt, sollen jetzt die Bestandteile der Primärdaten, die extrahiert werden sollen, betrachtet werden.
Zusammenfassend lässt sich festhalten, dass zur Wahrung der Legalität, nur textbasierte Beiträge extrahiert werden können, die zudem nur zu nicht-kommerziellen Zwecken öffentlich zugänglich gemacht werden können – außerdem bedarf es noch einer Zustimmung der Autoren (siehe DEFAULT). Facebook Statusmeldungen und Posts werden des Weiteren nur von den Chroniken privater Nutzer extrahiert, die als typische Facebook Nutzer angesehen werden können. Sie treten zudem als online bilinguale Benutzer des Deutschen und Italienischen auf und verwenden diese Sprachen auch zu einem hinreichenden Maß. Außerdem wird die Sammlung auf veröffentlichte Beiträge zwischen den Jahren 2009 und 2013 begrenzt, da hier davon ausgegangen werden kann, dass die Daten hinsichtlich ihrer (kommunikativen) Funktionen homogen sind.
5.2. Elemente der Datenextraktion
Ziel ist es, Facebook Beiträge, von Nutzern, die sowohl auf Deutsch als auch auf Italienisch schreiben, zu untersuchen. Dabei geht es also um die verwendete(n) Sprache(n), weshalb die sprachlichen Elemente sowohl aus den Facebook Statusmeldungen als auch den Posts die Primärdaten des Korpus darstellen. Eine Reihe von weiteren Informationen begleiten allerdings die veröffentlichten Texte und können Aussagen verschiedener Art zu den Texten und zu den Verfassern dieser machen. Im Folgenden werden deshalb die Metadaten, die zur Korpuserstellung erhoben und gesammelt werden, vorgestellt und es wird kurz erläutert, warum diese relevant sind.
5.2.1. Autobiographische Informationen der Facebook Nutzer
Neben den Primärdaten, also den Facebook Statusmeldungen und den Posts sowie den Kommentaren, können weitere Informationen für die Auswertung relevant sein. Dafür sollen auch Informationen zu den Nutzern, deren Daten im Korpus gesammelt werden, im Korpus gespeichert werden.
Zum Erstellen eines Facebook Accounts werden das Geburtsdatum und eine gültige E-Mail Adresse benötigt. Den Namen, den der Nutzer bei Facebook tragen möchte, wählt er selbst. Wie bereits in Kapitel dargestellt, ist ein Charakteristikum der SNS das Anlegen eines Profils, auf dem der Nutzer Informationen über sich selbst teilt und so eine Vernetzung mit Facebook Freunden begünstigt. Es gibt allerdings keine Instanz, welche die Richtigkeit der Angaben überprüft; die Facebook Mitglieder erschaffen sich eine Identität, mit der sie sich innerhalb des Netzwerks selbst repräsentieren. Diese kann sich zuweilen von der Identität des Nutzers in der Realität – also außerhalb der virtuellen Welt – unterscheiden, deshalb ist es wichtig zu berücksichtigen, dass es sich hier immer um eine Selbstdarstellung der Nutzer handelt.
In den Account-Informationen, die das Profil der SNS Facebook darstellen, können autobiographische Daten veröffentlicht und somit mit anderen Nutzern geteilt werden. Dazu gehören Heimatstadt, der aktuelle Wohnort, das Geburtsdatum (mit oder ohne Angabe des Geburtsjahres) und das biologische Geschlecht. Zudem können Kontaktdaten in Form von virtuellen und reellen Adressen (beispielsweise E-Mail oder Wohnanschrift) angegeben werden.
Ausbildungs- und Arbeitsstätten (bzw. -orte) können hier ebenfalls eingetragen und gespeichert werden, ebenso wie persönliche Vorlieben und Interessen in Form von einer Übersicht über „gefällt mir“-Angaben des Nutzers oder Mitgliedschaft in Gruppen (beispielsweise für Vereine, Sportmannschaften, Sänger, Bands, Filme, etc.). Lebensereignisse (beispielsweise Hochzeit, Umzug, Abschluss, Geburt eines Kindes) können geteilt und eigene Sprachkenntnisse vermerkt werden. Auf der Facebook Chronik eines Nutzers wird des Weiteren auch eine Übersicht der Freunde angezeigt sowie selbst hochgeladene Fotos oder Videos sowie Fotos oder Videos, auf denen der Nutzer markiert wurde, und besuchte Orte.
Mit Hilfe dieser Daten kann bei der Auswertung überprüft werden, ob die Daten von typischen Facebook Nutzern verfasst wurden und ob Herkunft, Wohnort und angegebene Sprachkenntnisse tatsächlich etwas über die verwendeten Sprachen aussagen können. Für die Datenauswertung interessant sind folglich der Nutzername (der allerdings anonymisiert wird), das Geburtsdatum und Geschlecht sowie Angaben, die über die Sprachbiografie und die Sprachkenntnisse der Nutzer Aufschluss geben. Dazu gehören der Heimatort, der aktuelle Wohnort, Informationen zu Ausbildung (mit Ort und Land) und Sprachkenntnisse.
5.2.2. Bestandteile von Facebook Statusmeldungen und Posts
Neben den autobiographischen Daten und Informationen zu den Facebook Nutzern, sollen neben den Primärdaten auch deren Bestandteile, die die Primärdaten charakterisieren, gesammelt werden. Der in Kapitel vorgestellte Aufbau und die einzelnen möglichen Bestandteile der von den Chroniken kopierten Statusmeldungen und Posts lassen sich schematisch wie folgt darstellen:

Schematische Darstellung des Aufbaus einer Facebook Statusmeldung.
(Lizenz: CC BY SA)
Eine Facebook Statusmeldung und ein Post unterscheiden sich nur dahingehend, dass bei Letzterem neben dem Namen des Verfassers auch noch der Nutzername des Facebook Freundes, an dessen Facebook Chronik die Nachricht gepostet wurde, erscheint (siehe auch Abbildung 2 in Kapitel ). Die Elemente, die für die spätere Datenauswertung relevant sind und deshalb als Bestandteile des Korpus von den Facebook Accounts extrahiert werden, sollen im Folgenden kurz vorgestellt werden. Dazu gehören:
- Nutzername
- Datum der Statusmeldung
- Typ der Statusmeldung: textbasierter Beitrag, (textbasierter) Link, (textbasiertes) Foto, (textbasiertes) Video
- Text der Statusmeldung/ des Posts, insofern es sich um einen textbasierten Beitrag handelt
- Likes
- Kommentare (mit Datum, Nutzernamen, Text, Likes)
Nutzernamen
Bei allen veröffentlichten Facebook Beiträgen wird der Nutzername angezeigt. Er gibt auch Aufschluss darüber, ob es sich um eine Statusmeldung oder einen Post handelt, denn wenn der Name des Nutzers mit dem der Chronik, auf der der Beitrag gepostet wird, übereinstimmt, handelt es sich um eine Facebook Statusmeldungen. Wenn der Name einem anderen Nutzer gehört, dann handelt es sich um einen Post. Deshalb sind die Nutzernamen ein wichtiger Bestandteil, müssen aber aus datenschutzrechtlichen Gründen anonymisiert werden (siehe DEFAULT).
Datum
Statusmeldungen und Posts sowie die Kommentare sind mit einem Zeitstempel versehen und werden umgekehrt chronologisch auf der Facebook Chronik angezeigt. Sie sind wichtig, um die Datensammlung auf den eingegrenzten Zeitraum von 2009 bis 2013 einzuschränken (siehe 5.1.5) und können bei der Auswertung in Hinblick auf die Entwicklung der textbasierten Beiträge wichtige Hinweise geben.
Typisierung von Facebook Statusmeldungen und Posts
In der schematischen Darstellung in Abbildung 24 wird ein Bild oder Foto mit einem Text kombiniert, generell müssen Beiträge aber nicht textbasiert sein. Bilder, Videos oder Links können auch ohne Text oder Beschreibung geteilt werden, genauso wie ein Beitrag rein sprachlich gestaltet sein kann. Folgenden Typen von Facebook Statusmeldungen und Posts können also unterschieden werden:
- textbasiert (TXT)167: Der Beitrag ist sprachlich gestaltet, kann aber mit parasprachlichen Elementen, wie Emoticons oder Phoneticons (siehe Kapitel ), angereichert werden. Außerdem können Facebook Freunde durch Hyperlinks darin markiert werden. Dies kann innerhalb des Texts erfolgen – beim Schreiben des Namens des Freundes erscheint eine Auswahl, aus der dieser gewählt werden kann – aber auch außerhalb durch eine Markierung (siehe -mit Username in Abbildung 24). Es kann nun auch eine Ortsmarkierung vorgenommen werden, sowohl im Text als auch außerhalb (siehe hier: Ort in Abbildung 24). Für das Korpus und die anschließende Datenanalyse interessieren allerdings nur Namens- und Ortsmarkierungen, die im Text enthalten sind.
- Foto (PIC): Fotos und Bilder verschiedener Formate und Größen können bei Facebook hochgeladen und auf der eigenen Chronik oder der eines Freundes geteilt werden. Auch hier können auf dem Bild sowohl der Ort als auch Facebook Freunde (teilweise direkt durch Anklicken der Gesichter) markiert werden. Eine automatische Gesichtserkennung sorgte 2011 in Europa für Unmut und wurde nach Protesten von Datenschutzrechtlern 2012 wieder abgeschafft (vgl. 2012).
- Link (LINK): Jede beliebige URL kann veröffentlich werden. Es erscheinen zum einen die Internetadresse sowie ein Ausschnitt der Internetseite, oft in Kombination mit einer Beschreibung dieser.
- Video (VID): Auch selbstaufgenommene Videos können veröffentlicht werden. Diese werden (wie Fotos) hochgeladen. Allerdings wird zum Hochladen häufig die Plattform com genutzt und anschließend nur der Link auf der Chronik (oder der eines Freundes) geteilt.
Die letzten drei Typen treten auch als Kombination mit einem Text, der der näheren Beschreibung oder der Erklärung von veröffentlichten Links, Fotos oder Videos dient, auf. Zu unterscheiden sind dabei:
- textbasierte Statusmeldung mit Foto (TXTPIC)
- textbasierte Statusmeldung mit Link (TXTLINK)
- textbasierte Statusmeldung mit Video (TXTVID)
Die Bestimmung des Typs ist insofern relevant, da die textbasierten Beiträge gefiltert werden können um danach im Korpus gespeichert zu werden. Zudem geben sie einen Aufschluss darüber, ob und in wie weit Facebook Nutzer sich nichtsprachlicher Kommunikation, wie Fotos, Videos oder Links bedienen. Es kann damit gezeigt werden, wie hoch die Anzahl der textbasierten Statusmeldungen überhaupt ist und welche Kommunikationsmöglichkeiten von den Nutzern bevorzugt werden.
Likes
Sowohl die Statusmeldung und die Posts, als auch die Kommentare können „gelikt“ werden.168 Das bedeutet, der Nutzer klickt mit der Maus den gefällt mir-Button (en. Like-Button), der 2009 von Facebook eingeführt wurde. Dieser Button wird von dem Piktogramm des nach oben gestreckten Daumens dargestellt:

„Gefällt-mir“-Button von Facebook ( ).
(Lizenz: CC BY SA)
Mit dem Anklicken dieses Symbols, das bei allen veröffentlichten Beiträgen erscheint, äußert der Nutzer seine Zustimmung und sein Wohlwollen.169 Im Jahr 2010 klickte jeder Nutzer durchschnittlich neun Mal im Monat auf dieses Symbol (vgl. 2010), 2012 waren es bei den deutschen Nutzern im Schnitt 60 Likes im Monat (vgl. 2012). Interessant ist auch, dass es nur einen Like– aber keinen Dislike-Button gibt. Das begründen die Facebook Gründer damit, dass sie negativen Emotionen wie Missgunst, Hass, Neid und Eifersucht keinen Platz bieten wollen (vgl. 2016).170
Likes drücken nichtsprachlich Zustimmung oder Wohlwollen der Facebook Freunde aus. Dies kann gleichgesetzt werden mit Mimik oder Gesten aus der Face-to-Face Kommunikation, wie einem anerkennenden Kopfnicken oder eben dem hochgestreckten Daumen als Symbol für Zustimmung. Sie ersetzen oder ergänzen textbasierte Kommentare und sollen deshalb mit ins Korpus übernommen werden.
Kommentare
Facebook Statusmeldungen und Posts können zudem kommentiert werden. Die Anzahl der Kommentare ist nicht beschränkt, aber in der Chronik werden nur bis zu vier Kommentare automatisch angezeigt. Diese stammen von Facebook Freunden, aber auch von dem Facebook Nutzer selbst. Kommentare sind immer textbasiert, können aber auch verlinkte Namen und URLs enthalten. Die Verwendung von Emoticons ist ebenfalls möglich. Die Kommentare beziehen sich auf den Inhalt der Statusmeldung oder der Posts und können Zustimmung oder Ablehnung ausdrücken; es können sich daraus aber auch Dialoge entwickeln.
Die Kommentare sind insofern relevant für das Korpus, da sie teilweise Reaktionen der Facebook Freunde zur Sprachverwendung enthalten. An den Kommentaren lassen sich also nicht nur Bewertungen, sondern auch Reaktionen auf die verwendete(n) Sprache(n) des Verfassers der Facebook Statusmeldung oder des Posts erkennen, wie Beispiel 61 zeigt.
[FB 2211_458]
2211: YEAH..und so wurde Super-Maradona und der weltbeste Fussballer von ihrem Arroganz-Thron gestoßen.. e fu così che l’arroganza di Maradona ed il migliore calciatore del mondo caddono dal trono..
221133: grazie per la traduzione! stavo già per usare il google translate!! „wink“-Emoticon
Beim Sammeln der Kommentare werden auch die dazugehörenden Informationen, wie Nutzernamen des Verfassers, Datum und Anzahl der Likes zu dem Kommentar gesammelt. Allerdings sollen die Kommentare nicht Gegenstand der Datenauswertung sein, da es sich hierbei um eine andere Kommunikationsform handelt. So sind diese immer textorientiert, stellen eine Antwort oder einen Bezug zum Facebook Beitrag dar und adressieren meist den Verfasser des Beitrags direkt. Sie unterscheiden sich hinsichtlich der kommunikativen Funktionen stark von der Kommunikationsform Facebook Statusmeldungen und Posts. Trotzdem werden sie für zukünftige Studien mit ins Korpus aufgenommen, für die vorliegende Arbeit werden sie jedoch nicht weiter bereinigt, annotiert und analysiert.
Für die Datensammlung relevant sind neben den Primärdaten, also dem Text aus Facebook Statusmeldungen und Beiträgen, auch die Metadaten. Dazu gehören die weiteren Bestandteile der Beiträge, die Informationen zu den Beiträgen liefern sowie die (autobiographischen) Informationen zu den Nutzern. Das nächste Kapitel soll zeigen, wie die verschiedenen Bestandteile als Daten extrahiert werden können und daraus schließlich ein spezialisiertes linguistisches Korpus entsteht.
5.3. Datensammlung
Um die Daten zu sammeln, muss erst der Zugriff auf die Daten ermöglicht werden, um sie dann zu speichern. Im Anschluss daran müssen sie bereinigt und bearbeitet werden, um schließlich in einer Datenbank, die der Darstellung des Korpus dient, zusammengeführt zu werden. Die einzelnen Schritte sollen im Folgenden vorgestellt und erklärt werden.
5.3.1. Erstellung eines Facebook Accounts
Um die Statusmeldungen und Posts von privaten Facebook Nutzern zu sichten und schließlich von den jeweiligen Facebook Chroniken extrahieren zu können, muss eine Vernetzung mit diesen Nutzern erfolgen. Dafür werden Nutzer auf Facebook befreundet, denn nur so kann bei privaten Accounts auf alle Informationen zugegriffen und die Facebook Chroniken eingesehen werden.
Vernetzen auf Facebook oder der Facebook Freund
Die Termini Freund im Deutschen und amico im Italienischen sind aus dem englischen friend übersetzt und bezeichnen bei Facebook die Kontakte, mit denen sich der Nutzer vernetzt. Im Jahr 2010 hatte jeder Nutzer im Schnitt 130 Freunde auf Facebook (vgl. 2010) und im Jahr 2013 342 Freunde (vgl. Wolfram 2013). Schon die Anzahl dieser Freunde zeigt, dass diesen „virtuellen“ Facebook Freunden nicht dasselbe Konzept eines „realen“ Freundes zugrunde liegt.
Facebook ist ein soziales Netzwerk, das Menschen mit ihren Freunden, Arbeitskollegen, Kommilitonen und anderen Mitmenschen verbindet. Nutzer verwenden Facebook, um mit ihren Freunden in Verbindung zu bleiben, eine unbegrenzte Anzahl an Fotos hochzuladen, Links und Videos zu posten sowie mehr über die Personen zu erfahren, die sie kennenlernen. ( 2014)
Facebook è una piattaforma sociale che ti consente di connetterti con i tuoi amici e con chiunque lavori, studi e viva vicino a te. Puoi usare Facebook per rimanere in contatto con i tuoi amici, caricare tutte le foto che vuoi, pubblicare link e video o per saperne di più sulle persone che incontri. ( 2014)
Nach dieser Beschreibung kann sich ein Nutzer über Facebook mit Freunden, Arbeitskollegen, Kommilitonen und flüchtigen Bekanntschaften, die er beispielweise im Urlaub, bei der Arbeit, im Verein oder beim Sport kennenlernt, vernetzten; genauso wie mit seinen Familienmitgliedern. All diese Kontakte werden unter dem Oberbegriff Freund in der Freundesliste gespeichert.
Die Bezeichnung „Freund“ auf Facebook trifft damit nicht ganz die Bedeutung, die dem Terminus im Deutschen zugesprochen wird. So heißt es im Duden (Duden 2016), ein Freund bzw. eine Freundin sei eine „männliche/weibliche Person, die einer anderen in Freundschaft verbunden ist, ihr nahesteht“ oder auch eine „männliche/weibliche Person, mit der eine Frau oder ein Mann befreundet ist [und mit der sie oder er zusammenlebt]“. Danach bezeichnet ein Freund/eine Freundin im Deutschen eher eine vertraute Person, die einem nahesteht oder mit der man gar eine Partnerschaft pflegt. Und auch im Italienischen bedeutet amico bzw. amica laut dem Zingarelli (Zanichelli 2004, 82) zum einen „Amante“ oder „chi ha particolare interesse o sente particolare attrazione per qlco.” und zum anderen „Chi è legato da sentimenti di amicizia“, wobei amicizia die Bedeutung “Affetto vivo e reciproco tra due o più persone” hat. Es ist also auch hier die Rede von einer durch wechselseitige Zuneigung gekennzeichneten Beziehung oder von einer partnerschaftlichen Beziehung von Personen. Somit stimmen im Deutschen und im Italienischen die verschiedenen Bedeutungen von Freund überein. Anders im Englischen,
Dass nun auf Facebook jeder Kontakt als „Freund“ bezeichnet wird, lässt sich zunächst mit der Übersetzung des englischen „friend“ in der deutschen Version von Facebook begründen und der damit einhergehenden Übernahme der englischen Lesart (im Sinne von ‚Bekannter‘). (Brommer & Dürscheid 2013, 33) [Hervorhebungen im Original].
Man kann hier also von einer Bedeutungserweiterung des Begriffs sprechen: die Bedeutungen ‚nahestehende, vertraute Person‘ und ‚Partner‘ werden um die Bedeutung ‚allgemeiner sozialer Kontakt‘ ergänzt (vgl. Brommer & Dürscheid 2013, 33).
Bei den Facebook Freunden handelt es sich demnach um Kontakte, mit denen der Nutzer sich auf Facebook verbunden hat und die eventuell dort auf einer virtuellen Ebene dem deutschen (oder italienischen) Konzept eines Freundes entsprechen können. Allerdings ist diese hier geschlossene Freundschaft nicht auf die Realität und die dort herrschenden Beziehungen übertragbar. Das hat für die vorliegende Arbeit den Vorteil, dass sich Nutzer häufig mit ihnen unbekannten Accounts vernetzen und so wurde der Account „Projekt Code-Switching“ erstellt, dessen einziger Zweck die Datensammlung von den Chroniken von befreundeten Nutzern, die die entsprechenden Kriterien erfüllen, darstellt.171
Der Facebook Account „Projekt Code-Switching“
Schon der Name des Accounts – „Projekt Code-Switching“ – soll den Nutzern den Hinweis geben, dass es sich hierbei um ein Forschungsprojekt handelt. In der Beschreibung des Accounts werden die Nutzer über den Zweck und das Ziel des Forschungsprojekts informiert und dazu aufgefordert, sich nur mit dem Projekt zu befreunden, wenn sie einer Datenextraktion zustimmen.
Ciao an alle tedesco-italienisch parlanti!!
Questo sito è un progetto su cui sto lavorando nell’ambito del mio dottorato presso l’università di Monaco. La mia ricerca si occupa del fenomeno del code-switching, cioè il cambio tra due (o più) lingue, in particolare tra l’italiano e il tedesco nei messaggi di bacheca su Facebook.
Aver accettato la richiesta di amicizia, mi avete dato il consenso di estrarre i vostri messaggi di bacheca ed analizzarli. Ovviamente verranno tutti anonimizzati.
Scrivetemi se volete saperne di più o se avete qualche consiglio o dubbio.
Vi ringrazio per il vostro aiuto!!!
Diese Seite ist ein Projekt an dem ich gerade im Rahmen meiner Doktorarbeit an der Universität München arbeite. Meine Forschung setzt sich mit dem Phänomen des Code-Switchings, also dem Wechsel zwischen zwei (oder mehreren) Sprachen, auseinander und betrifft vor allem das Deutsche und das Italienische in Facebook Pinnwandeinträgen.
Durch das Akzeptieren meiner Freundschaftseinladung habt ihr mir die Zustimmung erteilt, eure Pinnwandeinträge zu extrahieren und zu analysieren. Diese werden natürlich zu diesem Zwecke anonymisiert!
Schreibt mir, wenn ihr mehr dazu wissen möchtet oder wenn ihr Vorschläge oder Beanstandungen habt.
Ich danke euch vielmals für eure Hilfe!
(Aus der Accountinfo, Stand 15.09.2012)
In den Informationen der Profilseite werden zusätzlich Kontaktdaten mitgeteilt, damit sich die Facebook Nutzer bei eventuellen Nachfragen oder Vorschlägen an die Autorin wenden können. Davon machen drei Nutzer Gebrauch. Zum einen wollten sie sicher gehen, dass ihnen keine Werbung (Spam) zugesendet wird. Zum anderen baten sie aus Interesse am Forschungsprojekt darum, im Anschluss über die Ergebnisse informiert zu werden. Mit diesem Account werden keine Statusmeldungen verfasst oder Nachrichten aus dem Account gesendet, um vor den Nutzern so wenig wie möglich in Erscheinung zu treten, sondern eher als „stiller Beobachter“ Daten zu extrahieren. Da die meisten Nutzer in den Jahren 2012 und 2013 als Facebook Freunde bestätigt werden, sind die meisten Statusmeldungen und Posts schon geschrieben und auf den Chroniken veröffentlicht. Durch die Zurückhaltung des Accounts und das fehlende In-Erscheinung-Treten im Newsfeed (d.h. den Benachrichtigungen über aktuelle Aktivitäten von Facebook Freunden) fühlen sich die Nutzer unbeobachtet. Das führt dazu, dass die Nutzer ihre Beiträge nicht aufgrund ihres Wissens um eine Datenextraktion mit Fokus auf Sprachwechsel und Sprachverwendung modifizieren.172
Die Akquise der Facebook Freunde findet zum einen innerhalb des Netzwerkes der Autorin statt, aber auch über Facebook Gruppen für italienisch-deutsche Sprachtandems und über Aushänge an der Ludwig-Maximilians-Universität sowie an einigen italienischen Universitäten.173 Nachdem der Freundschaftsantrag auf beiden Seiten bestätigt ist, kann auf die Facebook Chroniken der Nutzer mitsamt Statusmeldungen und Posts zugegriffen werden.
5.3.2. Extraktion der Primär- und Metadaten
Die Sammlung der autobiographischen Daten zu den Nutzern erfolgt über die Accountinformationen der Nutzer. Die dort veröffentlichten Informationen zu Namen, Geburtstag, Geschlecht sowie Sprachkenntnisse und Ausbildung(en) werden in einer Tabelle gespeichert.
Für die Datensammlung existieren verschiedene Methoden. Einige davon wurden getestet, um festzustellen, welche sich am besten eignet. Als erste Möglichkeit wurde die von Barilà (2012) entwickelte Facebook Anwendung I told you , in Betracht gezogen. Mit Hilfe dieser konnten in Facebook die Statusmeldungen von befreundeten Accounts automatisch gesammelt werden. Diese war allerdings fehlerhaft, beispielsweise funktioniert die Kodierung von Sonderzeichen und Emoticons nur eingeschränkt. Außerdem wurden Kommentare und Posts sowie die Anzahl der Likes bei der Datenextraktion nicht berücksichtigt. Nach einer Facebook Aktualisierung im Jahr 2013 wurde die Anwendung schließlich aus Facebook entfernt, da sie mit der neuen Version nicht mehr kompatibel war. Eine zweite mögliche Methode stellte ein mit php geschriebenes Programm der Autorin dar, das anhand des HTML-Codes einer Facebook Chronik die einzelnen Statusmeldungen herausfilterte. Die laufenden Aktualisierungen von Facebook und dementsprechend auch des HTML Codes erwiesen sich allerdings als problematisch. Eine Zusammenführung alter und neuer Codes sowie eine laufende Anpassung innerhalb des Programms stellten große Hindernisse dar.
Als effizientesten (und wohl auch simpelsten) Weg, um die Statusmitteilungen zu extrahieren, stellte sich schließlich das Kopieren der Statusmeldungen und Posts von den einzelnen Facebook Chroniken heraus. Aber auch hier mussten anfangs einige Schwierigkeiten überwunden werden, da ein vollständiges Kopieren nicht mit jedem Internetbrowser möglich ist. So wurden beispielsweise nur bei Opera und Chrome überhaupt Kommentare (limitiert auf vier Kommentare pro Statusmeldung) angezeigt und nur bei der Verwendung des letzteren Internetbrowsers werden auch Emoticons – egal nach welcher Kodierung – beim Kopieren übernommen. Die Statusmeldungen und Posts der einzelnen Facebook Freunde werden jahresweise von den Chroniken der einzelnen mit dem Forschungsaccount vernetzten Nutzer kopiert. Da Facebook zunächst in der Chronik nur die Highlights anzeigt, also Statusmeldungen und Posts, die aufgrund der Anzahl an Kommentaren und „gefällt mir“-Bewertungen als besonders wichtig erachtet werden, muss nach Auswahl eines bestimmten Jahres auch darauf geachtet werden, tatsächlich alle Beiträge zu kopieren (es gibt hier zwei Ansichten, die ausgewählt werden können: alle Beiträge oder Highlights).
Alle Inhalte, die auf der Chronik in den entsprechenden Jahren veröffentlicht sind, wurden anschließend als Textdateien (im .txt-Format) gespeichert, um sie auf das Hochladen in die Datenbank vorzubereiten.
5.3.3. Bereinigung und Strukturierung der Rohdaten
Wie in Abbildung 5 dargestellt, werden in der Facebook Chronik nicht nur Statusmeldungen und Posts angezeigt, sondern auch eine Vielzahl an anderen Elementen, die beim Kopieren ebenfalls übernommen werden. Da aber nur die im vorangehenden Kapitel vorgestellten Elemente für die Datenanalyse relevant sind und somit in das Facebook Korpus übernommen werden, müssen die in Textdateien kopierten Daten bereinigt werden. Diese Datenbereinigung erfolgt halbautomatisiert mit Hilfe von Regulären Ausdrücken (en. regular expressions oder abgekürzt RegEx) und mit Hilfe eines Textverarbeitungsprogramms, das erweiterte Ersetzungsfunktionen zulässt.174 Platzhalter, Werbung, aber auch irrelevante Informationen (wie beispielsweise „Ist seit …mit…befreundet“) wurden entfernt. Bei den nicht textbasierten Typen der Facebook Statusmeldungen und Posts wurden zudem alle nichtsprachlichen Elemente durch die entsprechenden Kürzel ersetzt, also beispielsweise Fotos durch das Kürzel „PIC“ (siehe Typisierung von Facebook Beiträgen in DEFAULT). Auch die restlichen Typen der Statusmeldungen konnten aufgrund von Informationen zu den hochgeladenen Dateien, wie Fotos, Videos oder Links, automatisch ergänzt werden.
Zurück bleiben schließlich die zu extrahierenden Elemente, die mit Hilfe der Regulären Ausdrücke in das für den Import in eine Datenbank passende, durch Semikolons getrennte, Format gebracht werden. Die Elemente einzelner Statusmeldungen werden hierfür nach folgendem Schema aufbereitet:
status_writer; date; type; text; likes; comment_1; comment_text_1; comment_date_1; comment_like_1; comment_2; comment_text_2; comment_date_2; comment_like_2; comment_3; comment_text_3; comment_date_3; comment_like_3; comment_4; comment_text_4; comment_date_4; comment_like_4;
Unter status_writer wird der Nutzername des Verfassers der Statusmeldung oder des Posts vermerkt. Im Falle einer Statusmeldung ist es der eigene Name des Facebook Nutzers, von dessen Chronik Daten extrahiert wurden. Im Falle eines Posts ist es der Name des befreundeten Nutzers, der einen Beitrag an der Chronik hinterlassen hat. Es folgt das Datum (date) an dem der Beitrag veröffentlicht wurde sowie das Kürzel für den entsprechenden Typ der Statusmeldung oder des Posts (type). Unter text folgt dann der tatsächliche textbasierte Beitrag sowie die Anzahl der „gefällt mir“-Angaben (likes). Insofern vorhanden, können bis zu vier Kommentare gesammelt werden; dazu wurden für jeden Kommentar der Nutzername des Kommentators (z.B. comment_1), der eigentliche Text des Kommentars (z-B. comment_text_1), das Datum der Veröffentlichung (z.B. comment_date_1) und die Anzahl der Likes (z.B. comment_like_1) übernommen. An einem Beispiel verdeutlicht, können die einzelnen Einträge (mit Zeilenumbruch voneinander getrennt aus) nach der Strukturierung wie folgt aussehen:
Nutzername;2009-12-28;TXT;studying for PV Praktikum;1;Kommentatorname_1;good work! (is PV photovoltaic?);2009-12-29;0;Nutzername; genau „wink“-Emoticon;2009-12-29;0;
Wie in (62) am Beispiel von „wink“-Emoticon zu sehen, werden auch die Texte aus den Facebook Statusmeldungen und Posts bearbeitet. Gerade bei den Emoticons fehlt häufig eine einheitliche Kodierung, denn es gibt verschiedene Möglichkeiten, diese zu erstellen, die wiederum zu unterschiedlichen Kodierungen führen. Zum einen kann der Nutzer von Facebook unterstützte Emoticons aus einer Liste auswählen, zum anderen kann er direkt beim Schreiben ein Tastenkürzel verwenden (siehe die Spalten Emoticon und Kürzel in Tabelle 10). Die Nutzer verwenden aber auch häufig von den Vorgaben Facebooks abweichende Tastenkürzel und Symbole; so ergeben sowohl die Tastenkombinationen „:)“ als auch „(:“ das Emoticon „J“. Dies funktioniert auch mit der Tastenkombination „:-)“, nicht aber mit „(-:“ (diese Tastenkombination funktioniert dafür bei anderen Arten der CMC, beispielsweise in bestimmten Chaträumen). Zudem weicht die Kodierung von Emoticons in den Statusmeldungen und Posts teilweise von der in den Kommentaren ab. Viele der Emoticons werden außerdem erst nach 2009 in Facebook übernommen, das heißt es gab auch im Laufe der Jahre Änderungen in der Kodierung.
Um eine Suche zu erleichtern und Emoticons im Korpus einheitlich darzustellen, werden die verwendeten Bezeichnungen, egal ob Tastenkürzel oder die unterschiedlichen Facebook Bezeichnungen, in den textbasierten Primärdaten einheitlich gekennzeichnet. Tabelle 10 in Kapitel zeigt die für das Korpus gewählten Bezeichnungen sowie die von Facebook vorgegebenen Kürzel, die schließlich zur Anzeige des entsprechenden Emoticons führen. So steht beispielsweise „smile“-Emoticon für das J-Symbol, das entweder aus einer Liste ausgewählt wird oder mit einem Tastenkürzel während des Schreibens zur automatischen Anzeige dieses Symbols führt. In den textbasierten Beiträgen finden sich auch noch weitere, in der CMC übliche Tastenkürzel, die teilweise – aber nicht immer – zur Darstellung der Emoticons führen und die dennoch vereinheitlicht werden und denen entsprechende Bezeichnungen hinzugefügt wurden.
Neben den Unterschieden in der Kodierung von Emoticons ergeben sich noch weitere Schwierigkeiten bei der Kodierung der beiden zu untersuchenden Sprachen, denn es werden beispielsweise verschiedene Diakritika verwendet, die unterschiedlich kodiert sein können. Im Deutschen zählen die Umlaute ä, ö und ü sowie das Eszett ß zu den diakritischen Zeichen; das Italienische verwendet Gravis und Akut in Kombination mit Vokalen, wie in à, è, é, ì, í, ò, ó, ù und ú. Da eine Zeichenkodierung mit ASCII nicht unproblematisch ist und es bei der Datenübertragung zu einer unvollständigen Darstellung von Zeichen kommen kann, werden die Daten als Unicode-kodifizierte Textdateien gespeichert. Dabei wird das 8-Bit UCS Transformation Format (=utf-8), das wohl gängigste Kodierungsformat für Unicode-Zeichen, verwendet. Diese Kodierung hat den Vorteil, dass es für (fast) alle Zeichen einen Zeichensatz gibt und so die Speicherung und Verarbeitung von Datensätzen vereinfacht.
Des Weiteren haben sich innerhalb der CMC und so auch in den Facebook Statusmeldungen verschiedene Schreibkonventionen etabliert, die bei der Datenbereinigung und Datenverarbeitung zu Problemen führen.175 Dazu zählen
- durchgängige Minuskelschreibung
- abkürzende Schreibweisen
- Iteration von Buchstaben und Interpunktion
- Füllwörter, Interjektionen
- Versalienschreibung zur Emphatisierung
- Inflektive
- Phoneticons
Das Schreiben mit der Tastatur führt darüber hinaus noch zu Tippfehlern und Buchstaben- oder Zahlendrehern. Es gibt eine Häufung von Rechtschreibfehlern und einer falschen oder spärlichen Verwendung diakritischer Zeichen. Für die Datenspeicherung und –übertragung sind diese Punkte allerdings unproblematisch, denn wenn die Kodierung im utf-8 Format erfolgt, können alle verwendeten alphanumerischen Symbole sowie Interpunktionen und weitere auf der Tastatur produzierbare Sonderzeichen gespeichert und in das Korpus übertragen werden. Durch das Ignorieren von Groß- und Kleinschreibung (en. case insensitive) bei der Datenspeicherung und beim Übertragen der Daten in das Korpus waren von der durchgängigen Kleinschreibung sowie der Versalienschreibung, also der ausschließlichen Verwendung von Großbuchstaben, ebenfalls keine Schwierigkeiten zu erwarten. Allerdings sollten diese Besonderheiten für die Annotation im Blick behalten werden.
Nachdem die Textdateien strukturiert, bereinigt und mit der richtigen Kodierung versehen wurden, werden sie anschließend als .csv-Dateien gespeichert und können in einem nächsten Schritt in eine elektronische Datenbank übertragen werden, die die technische Grundlage des Korpus darstellt.
5.3.4. Aufbau der Datenbank und Import
Die für das Korpus verwendete Datenbank wird mit Hilfe einer MySQL-basierten Webanwendung verwaltet.176 Diese bietet den Vorteil, dass mittels MySQL-Befehlen die Daten schnell und einfach bearbeitet und komplexe Suchabfragen durchgeführt werden können. Nachdem die aufbereiteten und bereinigten Statusmeldungen und Posts der Facebook Chroniken aller Nutzer in die Datenbank importiert sind, folgt die Anonymisierung der Namen der Nutzer sowie all deren Facebook Freunde, die mittels Facebook Posts oder Kommentaren in Erscheinung getreten sind. Dazu werden aus den Tabellen die Namen der Nutzer und der Kommentatoren ermittelt und durch fortlaufende IDs ersetzt.
Die ID für Facebook Nutzer setzt sich wie folgt zusammen: Die ersten beiden Ziffern der ID des Facebook Nutzers werden fortlaufend im zweistelligen Zahlenbereich vergeben, die dritte Ziffer bezieht sich auf das Heimatland und die vierte auf das Land, in dem der Nutzer zu dem Zeitpunkt der Datenextraktion wohnt. Dabei steht 1 für Deutschland, 2 für Italien und 4 für andere Länder, 0 wird vergeben, wenn es in den Profilinformationen des Nutzers keine Angaben zu Heimatstadt und aktuellem Wohnort gibt. Die Nutzer ID 2211 beispielweise bezieht sich auf die Daten des Facebook Nutzers, der an zwölfter Stelle (da zur Wahrung der Vierstelligkeit erst bei 10 begonnen wird) in die Datenbank aufgenommen wurde und der sowohl in Deutschland aufgewachsen ist, als auch aktuell dort wohnt.177 Bei den Kommentatoren sowie den Nutzern, die Facebook Posts schreiben, handelt es sich um Freunde des Nutzers. Deshalb wird zum einen die Nutzer-ID übernommen und zum anderen wird diese dann mit der Zahl, die sich bei der Nummerierung der Kommentatoren in alphabetischer Reihenfolge ergibt, kombiniert. Die Nutzer-ID 221112 bedeutet somit, dass es sich bei dem Nutzer um den zwölften Facebook Freund (in alphabetischer Reihenfolge) des Nutzers 2211 handelt. Die zur Anonymisierung der Nutzer und Kommentatoren verwendeten IDs werden schließlich zur Sicherung und Dokumentation in der Datenbank gespeichert, aber zur Wahrung des Datenschutzes nicht damit verknüpft.
Jedem einzelnen Facebook Beitrag und jedem Kommentar wird in den verschiedenen Tabellen automatisch eine fortlaufende ID gegeben, die somit jeder Zeile einer Tabelle den Status der Einzigartigkeit (unique nach MySQL Syntax) zuweist und notwendig für die weitere Bearbeitung ist. Damit später auch Tabellen angelegt werden können, welche Facebook Beiträge aller Nutzer sammeln, werden schließlich die Nutzer-IDs mit den IDs der Statusmeldungen kombiniert. Beispielsweise bedeutet 2211_12, dass es sich hier um die zwölfte Statusmeldung des Nutzers 2211 handelt, und 2211_12_2 bedeutet, dass es sich hier um den Kommentar mit der ID 2, der die Statusmeldung mit der ID 12 des Nutzers 2211 kommentiert. In den Beispielen aus dem Facebook Korpus, wie sie teilweise schon in den vorangehenden Kapiteln (vor allem in DEFAULT) verwendet wurden, wird die ID verwendet, um Korpusbelege eindeutig zu kennzeichen. Belege aus dem Korpus werden demnach wie folgt kenntlich gemacht:
[FB 1021_26]
fantastic
[FB 22114_705]
Happy Birthday
So bedeutet FB 1021_26 in (63), dass es sich hier um die 26. Statusmeldung von Nutzer 1021 handelt und FB 22114_705 in (64), dass es sich hier um den 705. Post des 4. Freundes von Nutzer 2211 handelt. Es sei auch noch anzumerken, dass aufgrund der Tippfehler, die in den Facebook Beiträgen häufig vorkommen und durchaus auch bewusst eingesetzt werden können (siehe DEFAULT), diese in den Beispielen nur in Ausnahmen markiert wurden. Ansonsten werden die Belege genauso wie im Korpus gespeichert, wiedergegeben.
Schließlich können aus den einzelnen Nutzer-spezifischen Tabellen weitere Tabellen erstellt werden, die nur die Statusmeldungen und Posts oder nur die Kommentare der einzelnen Nutzer enthalten. Der Aufbau der Datenbank vor der Korpusannotation lässt sich am Beispiel des Facebook Nutzers 1021 darstellen:
Aufbau der Datenbank des phpMyAdmin basierten Facebook Korpus am Beispiel der Tabellen für Nutzer 1021.
(Lizenz: CC BY SA)
Unter facebook werden die vier Datenbanken facebook_analyse, facebook_cs, facebook_nutzer und facebook_pinnwand gebündelt dargestellt. Während der Inhalt der ersten beiden Datenbanken erst in Kapitel bzw. DEFAULT vorgestellt wird, sollen hier die Inhalte der letzten beiden Datenbanken kurz beschrieben werden:
facebook_nutzer
Hier wird für jeden Nutzer eine Tabelle angelegt, in der die Anonymisierung der Nutzer und Kommentatoren mittels entsprechender IDs dokumentiert ist. Der Tabellenname, zum Beispiel 2211_user_anonym, lässt erkennen, um welchen Nutzer es sich handelt. Da in dieser Tabelle die auf Facebook verwendeten Namen gespeichert sind, die eventuell auch Aufschluss über die Identität der Person geben können, werden diese Tabellen verschlüsselt.
In die Tabelle nutzer_metadaten werden alle Informationen, die Bestandteile der zuvor angelegten Tabelle sind (siehe DEFAULT), gespeichert: Dazu gehören die User_ID und – insofern angegeben – das aus der Heimatstadt und dem aktuellen Wohnort hergeleitete Heimatland und aktuelle Land, angegebene Sprachkenntnisse, das Geburtsjahr und Geschlecht sowie Informationen zur Ausbildung.178
facebook_pinnwand
In dieser Datenbank werden, nach Nutzern sortiert, alle bereinigten und strukturierten Beiträge der Facebook Chroniken gespeichert. Tabellen, wie beispielsweise 1021, enthalten alle extrahierten Daten. Daraus wurden für eine weitere Bearbeitung der Daten neue Tabellen kreiert. Während somit Tabellen mit dem Zusatz status (wie zum Beispiel in 1021_status) nur die tatsächlichen textbasierten Statusmeldungen und Posts enthalten (inklusive Nutzer-ID, eigentlichem Text und Beitrags-ID) werden in den Tabellen mit dem Zusatz comment (wie zum Beispiel in 1021_comment) nur die Kommentare gespeichert. Alle diese Tabellen sind miteinander verknüpft, sodass eine eindeutige Zuordnung einzelner Beiträge mit den Kommentaren und der vollständigen Dokumentation der Facebook Chronik möglich ist.
Aus den so gespeicherten Daten können schon Informationen verschiedener Art, wie beispielsweise Informationen zu den Nutzern, die Anzahl der veröffentlichten Beiträge, Anzahl und Typ der Beiträge herausgelesen werden, die im Folgenden wiedergegeben werden sollen.
5.4. Übersicht der Facebook Daten
Das folgende Unterkapitel dient dem Überblick über die Daten, die im Rahmen der vorliegenden Untersuchung erhoben wurden. Inhalt werden dabei auf der einen Seite die gesammelten nutzerspezifischen Daten sein; dazu gehören Angaben zur Nutzerauswahl, Verteilung nach Alter, Geschlecht, Heimatland und aktueller Wohnsitz sowie Sprachkenntnisse und Anzahl von Freunden.179 Auf der anderen Seite sollen beitragsspezifische Informationen, wie die Verteilung nach Beitragstyp, nach Statusmeldungen und Posts sowie die Anzahl an Token und das Type-Token Verhältnis, vorgestellt werden.
5.4.1. Übersicht der (autobiographischen) Daten der Facebook Nutzer
Nutzerauswahl
Nach dem Versand und Erhalt von Freundschaftsanfragen, wurden zunächst alle Nutzer hinzugefügt und danach nach den Kriterien aus 5.1 gefiltert. Die autobiographischen und persönlichen Informationen der Nutzer aus den 51 befreundeten Accounts wurden entnommen, um einen ersten Überblick zu bekommen, welche Accounts relevant sein könnten. Teilweise wurde schon bei der Datenextraktion klar, dass einige Nutzeraccounts nicht für das Korpus verwendet werden können, da die Chroniken keine Beiträge enthalten, dem Facebook Account „Projekt Code-Switching“ keine Berechtigung zur Einsicht ihrer Chronik erteilt wurde oder die Freundschaft bereits wieder gekündigt worden war. Bei anderen Nutzeraccounts stellte sich erst bei der Datenbereinigung oder bei der Annotation heraus, dass die Nutzer nur in einer Sprache kommunizieren (abgesehen von einzelnen Okkurrenzen in einer anderen Sprache) oder das verwendete Sprachenpaar nicht Italienisch und Deutsch, sondern eine andere Sprachenkombination darstellt. Somit waren die Kriterien der Bestimmung des Bilingualismus, nämlich die hinreichende Verwendung des Deutschen und Italienischen, nicht gegeben (siehe Kapitel ).
| Nutzerauswahl | Grund | Anz. | |
| Ausgewählt | 14 | ||
| Abgelehnt | 37 | ||
| davon | |||
| Freundschaft gekündigt | 5 | ||
| Keine Beiträge | 4 | ||
| andere Sprachenkombinationen | Italienisch-Chinesisch | 1 | |
| Italienisch-Französisch | 1 | ||
| Spanisch-Italienisch | 3 | ||
| Sprachverwendung | nur Deutsch | 4 | |
| nur Englisch | 1 | ||
| nur Italienisch | 17 | ||
| nur Schweizerdeutsch | 1 | ||
| Gesamt | 51 | ||
Schließlich wurden die Daten von 14 Facebook Nutzern sowohl extrahiert als auch weiter aufbereitet und im Korpus gespeichert.
Die autobiographischen Informationen sind nichtsdestotrotz von allen Facebook Nutzern, die sich mit dem Account befreundet haben, vorhanden. Sie sollen hier präsentiert werden, da sie verdeutlichen, dass die befreundeten Nutzer tatsächlich einem Querschnitt durch die Menge der typischen Facebook Nutzer entsprechen.
Alter
Knapp die Hälfte der Facebook Nutzer verzichten darauf, ihr Alter anzugeben. Bei der restlichen Hälfte sind bis auf zwei Nutzer bei Abschluss der Datensammlung in 2013 jünger als 35 Jahre, bei den für die Datensammlung ausgewählten Nutzern liegt keiner über diesem Alter. Es kann auch davon ausgegangen werden, dass die Nutzer, die keine Angaben in ihren Accountinformationen veröffentlicht haben, ebenfalls aus dieser Altersgruppe stammen.180 Das deckt sich mit den statistischen Angaben aus Kapitel , nach denen die Mehrheit aller Nutzer aus dieser Altersgruppe stammt.
| alle Nutzer | ausgewählte Nutzer | |||
| Anz. | % | Anz. | % | |
| 1968 | 1 | 2 | 0 | 0 |
| 1974 | 1 | 2 | 0 | 0 |
| 1979 | 2 | 4 | 0 | 0 |
| 1981 | 1 | 2 | 0 | 0 |
| 1982 | 3 | 6 | 0 | 0 |
| 1983 | 2 | 4 | 1 | 7 |
| 1984 | 4 | 8 | 3 | 21 |
| 1985 | 2 | 4 | 1 | 7 |
| 1986 | 4 | 8 | 3 | 21 |
| 1987 | 1 | 2 | 0 | 0 |
| 1988 | 2 | 4 | 0 | 0 |
| 1994 | 2 | 4 | 0 | 0 |
| nn | 26 | 51 | 6 | 43 |
| Gesamt | 51 | 100 | 14 | 100 |
Geschlecht
Auch beim Geschlecht haben viele Nutzer keine Angaben gemacht. Allerdings sind das mit 37% aller Facebook Nutzer deutlich weniger Nutzer, die auf Angaben verzichten, als es beim Alter waren (51% machen hier keine Angaben, siehe Tabelle 13). Es kann vermutet werden, dass hier in den meisten Fällen der Facebook Name schon Aufschluss über das biologische Geschlecht gibt und die Daten deshalb nicht als allzu sensibel angesehen werden. Anders wie in der Statistik zu den Facebook Nutzern gesehen, überwiegen bei den für die Datensammlung in Betracht gezogenen Nutzern, die weiblichen Nutzer. So sind 39% laut eigenen Angaben weiblich und 24% männlich. Bei den letztendlich ausgewählten sind sogar 57% weiblich und 21% männlich. Das könnte zu der Annahme führen, dass weibliche Nutzer eher dazu neigen, sich mit unbekannten Accounts zu vernetzen. Dies kann zum einen an einer erhöhten Hilfsbereitschaft liegen, aber auch an der Strategie der Nutzerakquise.
| alle Nutzer | ausgewählte Nutzer | |||
| Anz. | % | Anz. | % | |
| männl. | 12 | 24 | 3 | 21 |
| weibl. | 20 | 39 | 8 | 57 |
| nn | 19 | 37 | 3 | 21 |
| Gesamt | 51 | 100 | 14 | 100 |
Herkunft und Wohnort
Im Vergleich zu den anderen Angaben, geben viele der Facebook Nutzer Auskunft zu ihrem Heimatort und zu ihrem dem aktuellen Wohnort. Diese wurden nach Ländern sortiert. Die Übersicht in Tabelle 15 zeigt, dass nur 29% aller befreundeten Facebook Nutzer keine Angaben zum Heimatland machen und 18% geben nicht das aktuelle Land, in dem sie leben, an. In den Informationen ihres Accounts geben 45% aller Nutzer als Heimatland einen Ort in Italien und 16% einen in Deutschland an, während der aktuelle Wohnort bei 49% in Deutschland und bei 24 % in Italien liegt. Diese Zahlen legen die Vermutung nahe, dass es sich bei vielen der teilnehmenden Nutzer um Personen handelt, die in Italien geboren wurden und später nach Deutschland gekommen sind. Auch bei den für die Datensammlung ausgewählten Nutzern lebt der Großteil zum Zeitpunkt der Datenerfassung in Deutschland (79%), während das Heimatland in fast gleichem Maße Deutschland oder Italien ist.
| Heimatland | aktuelles Land | |||||||
| alle Nutzer | ausgewählte Nutzer | alle Nutzer | ausgewählte Nutzer | |||||
| Anz. | % | Anz. | % | Anz. | % | Anz. | % | |
| de | 8 | 16 | 5 | 36 | 25 | 49 | 11 | 79 |
| it | 23 | 45 | 4 | 29 | 12 | 24 | 1 | 7 |
| ot | 5 | 10 | 0 | 0 | 5 | 10 | 1 | 7 |
| nn | 15 | 29 | 5 | 36 | 9 | 18 | 1 | 7 |
| Gesamt | 51 | 100 | 14 | 100 | 51 | 100 | 14 | 100 |
Leider lässt sich bei Facebook nicht nachvollziehen, zu welchem Zeitpunkt das aktuelle Land tatsächlich „aktuell“ war. Es kann durchaus sein, dass der eigentliche Wohnsitz des Facebook Nutzers zwischen 2009 und 2013, also den Jahren aus denen die Facebook Statusmeldungen und Posts extrahiert wurden, wechselte. Interessant ist auch, dass bei Facebook nur das Heimatland ausgewählt werden kann, nicht aber das Herkunftsland, obwohl die Konzepte „Heimat“ und „Herkunft“ durchaus unterschiedlich definiert werden können.
Sprachen
22 von den betrachteten 51 Facebook Nutzern (das entspricht 43%) machen in den Informationen ihres Accounts Angaben zu den von ihnen beherrschten Sprachen; bei den für die Datenbank ausgewählten Nutzern sind dies 6 von 14 (d.h. ebenfalls 43%). Das Nennen von mehreren Sprachen ist dabei der Standard, nur ein Nutzer (4441) nannte als einzige Sprache Dialetti italiani meridionali estremi.181 Facebook bietet den Nutzern zwar eine Vielzahl an möglichen Sprachen und Dialekten zur Auswahl an, jedoch besteht keine Möglichkeit, den Grad der Kompetenz zu bestimmen. Tabelle 16 zeigt eine Übersicht aller der von den Nutzern genannten Sprachen (für eine Übersicht nach Nutzer ID, siehe Anhang 1).
Wie nicht anders zu erwarten, sind Deutsch und Italienisch die Spitzenreiter. Aber auch Sprachen, die normalerweise in einem institutionellen Kontext erlernt werden, wie das Englische und das Französische, werden genannt. Interessant ist dabei, dass auch Dialekte genannt werden, was einen Aufschluss über das allgemeine Sprecherbewusstsein und das Bewusstsein über den eigenen (Online) Bilingualismus der Facebook Nutzer geben kann. Die gewählten Sprachen zeigen auch, wie sich einzelne Sprecher auf der SNS Facebook präsentieren möchten. Dabei verweisen möglicherweise nicht alle gewählten Sprachen auf das Beherrschen der Sprache, sondern können eventuell auch als Ausdruck von Humor verstanden werden (z.B. bei Portuñol oder Nepalese Sign Language).
| Sprache | Varietät/Spezifikation | ||
| alle Nutzer | ausgewählte Nutzer | ||
| Anz. | Anz. | ||
| Altgriechische Sprache | 1 | 0 | |
| Arabisch | 1 | 1 | |
| Chinesisch | 2 | 1 | |
| Deutsch | 16 | 5 | |
| Kölsch | 1 | 0 | |
| Schwäbische Dialekte | 1 | 1 | |
| Englisch | 14 | 5 | |
| English | 6 | 1 | |
| Kanadisches Englisch | 1 | 0 | |
| Französisch | 10 | 3 | |
| Français | 2 | 1 | |
| French | 2 | 1 | |
| Gotisch | 1 | 0 | |
| Italienisch | 17 | 5 | |
| Dialetti italiani meridionali estremi | 1 | 0 | |
| Dialetto Pugliese | 1 | 0 | |
| Dialetto toscano | 1 | 0 | |
| Neapolitanisch | 1 | 0 | |
| Sardisch | 1 | 0 | |
| Kurdisch | 1 | 0 | |
| Latein | 1 | 0 | |
| Nepalese Sign Language |
1 | 0 | |
| Portuñol | 1 | 0 | |
| Russisch | 1 | 1 | |
| Spanisch | 7 | 3 | |
| Spanisch in Äquatorialguinea | 1 | 0 | |
| Thailändisch | 1 | 0 | |
| Türkische Gebärdensprache | 1 | 0 | |
| Gesamt | 95 | 28 |
Facebook Freunde der Nutzer
Bei den für diese Arbeit untersuchten Nutzerprofilen können nur bei 9 Nutzern die Freundeslisten eingesehen werden. Die durchschnittliche Anzahl der Facebook Freunde liegt bei diesen Nutzerprofilen bei 575 Freunden. Bei der Datensammlung wurden zudem die Nutzernamen aller Freunde, die in irgendeiner Form – sei es durch Facebook Kommentare oder Facebook Posts – mit den Nutzern kommuniziert haben, gesammelt. Diese gehören somit zu den aktiven Freunden, mit denen der Nutzer mehr oder weniger regelmäßig Kontakt hat. Der Durschnitt dieser ist mit 195 Freunden weitaus kleiner, variiert aber zwischen 523 und 46.
| Freunde insgesamt | aktive Freunde | |
| Anz. | Anz. | |
| 1021 | 490 | 232 |
| 1112 | 448 | 156 |
| 1211 | nn | 140 |
| 1301 | 523 | 203 |
| 1411 | 407 | 69 |
| 1501 | nn | 46 |
| 1621 | nn | 307 |
| 1701 | 489 | 197 |
| 1824 | nn | 151 |
| 1921 | 1.352 | 523 |
| 2001 | 453 | 96 |
| 2101 | 462 | 119 |
| 2211 | nn | 318 |
| 2310 | 553 | 174 |
| Gesamt | 5.177 | 2.731 |
| Durschnitt/Nutzer | 575 | 195 |
Die durchschnittliche Anzahl aller Facebook Freunde liegt somit über dem von Wolfram (2013) genannten Durchschnitt, der im Jahr 2013 bei 342 lag. Diese hohe Anzahl an Freunden könnte man darauf zurückführen, dass diese Nutzer neben dem Forschungsaccount auch noch weitere ihnen unbekannte Accounts in ihre Freundeslisten aufgenommen haben. Andererseits lässt das auch die Vermutung zu, dass die Anzahl der Freunde mit der guten Vernetzung zusammenhängt. Somit kann bei den ausgewählten Nutzern eine große Kommunikationsbereitschaft erwartet werden, was auch die Anzahl an Statusmeldungen und Posts an der Chronik der Facebook Nutzer, die im nächsten Kapitel präsentiert wird, zeigt.
5.4.2. Übersicht der gesammelten Facebook Beiträge
Von den 14 Facebook Accounts wurden alle Beiträge der Chroniken extrahiert. Insgesamt konnten so 17.317 Statusmeldungen und Posts mit 4.480 Kommentaren in die Datenbank übertragen werden. Diese stellen die Grundlage des Facebook Korpus dar. Im Folgenden soll präsentiert werden, wie sich diese Daten zusammensetzen.
Verteilung nach Typ und Jahr der Veröffentlichung
Die 17.316 extrahierten Beiträge enthalten nicht alle sprachliche Beiträge, sondern können verschiedenen Beitragstypen zugeordnet werden (siehe DEFAULT). Zwar ist mit 36% die Anzahl der nur aus Text bestehenden Statusmeldungen und Posts am Höchsten, direkt darauf folgen aber 29%, die nur aus einem Link, und 23%, die nur aus einem Bild bestehen. Einen kleineren Anteil machen die Beiträge aus, die aus einer Kombination von Bild oder Link und einem begleitenden Text bestehen. Videos (auch in Kombination mit Text) sind recht selten.
Die Anzahl der Beiträge auf den Facebook Chroniken nimmt zwischen dem Jahr 2009, in dem insgesamt 2.822 Beiträge, und dem Jahr 2013, in dem 4.577 verfasst wurden, stetig zu. Bei einer Betrachtung der unterschiedlichen Beitragstypen lässt sich feststellen, dass in den Jahren 2009 bis 2011 die textbasierten Beiträge deutlich überwiegen und weit mehr als die Hälfte aller Statusmeldungen und Posts ausmachen: So sind im Jahr 2009 beispielsweise 61% aller in diesem Jahr veröffentlichten Beiträge textbasiert. Allerdings nimmt die Anzahl der nicht textbasierten Beiträgen im Laufe der Zeit zu. Während im Jahr 2009 nur knapp 5% der Beiträge aus einem geposteten Bild bestanden, waren es im Jahr 2013 schon 38%. Folglich ist auch der Anstieg textbasierter Beiträge, die zusammen mit Bildern, Videos und Links veröffentlicht werden, nicht verwunderlich.
| 2009 | 2010 | 2011 | 2012 | 2013 | Gesamt | |||||||
| Anz. | % | Anz. | % | Anz. | % | Anz. | % | Anz. | % | Anz. | % | |
| TXT | 1.715 | 61 | 1.634 | 55 | 1.510 | 43 | 864 | 25 | 462 | 10 | 6.185 | 36 |
| TXT-PIC | 20 | 1 | 59 | 2 | 121 | 3 | 330 | 10 | 514 | 11 | 1.044 | 6 |
| TXT-LINK | 155 | 5 | 169 | 6 | 192 | 5 | 187 | 5 | 179 | 4 | 882 | 5 |
| TXT-VID | 14 | 0 | 8 | 0 | 2 | 0 | 5 | 0 | 10 | 0 | 39 | 0 |
| PIC | 148 | 5 | 348 | 12 | 591 | 17 | 1.169 | 34 | 1.757 | 38 | 4.013 | 23 |
| LINK | 749 | 27 | 756 | 25 | 1.101 | 31 | 850 | 25 | 1.624 | 35 | 5.080 | 29 |
| VID | 21 | 1 | 8 | 0 | 5 | 0 | 8 | 0 | 31 | 1 | 73 | 0 |
| Gesamt | 2.822 | 100 | 2.982 | 100 | 3.522 | 100 | 3.413 | 100 | 4.577 | 100 | 17.316 | 100 |
Im Lauf der Zeit gibt es einen dementsprechend großen Anstieg der nicht textbasierten Beiträge, während die Anzahl an Beiträge, die nur aus einem Text bestehen nach 2011 deutlich abfällt, wie die Abbildung 27 grafisch verdeutlicht. Dies hängt zum einen mit dem Wechsel von der Facebook Pinnwand zur Facebook Chronik zusammen, die in diesem Jahr vollzogen wurde (siehe DEFAULT), aber auch die Tendenz der Nutzer, in den CMC vermehrt para- und nichtsprachliche Arten der Kommunikation zu verwenden, kann hier erkannt werden.
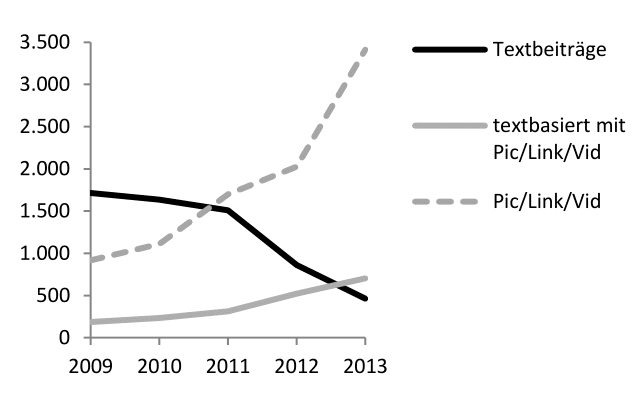
Entwicklung der Anzahl der Beiträge nach Typ zwischen 2009 und 2013 (Anzahl).
(Lizenz: CC BY SA)
Verteilung der Beiträge nach Facebook Nutzer
Ausgehend von der Gesamtanzahl von 17.316 Beiträgen, hat jeder Facebook Nutzer zwischen 2009 und 2013 durchschnittlich 1.237 Beiträge auf seiner Chronik gespeichert. Allerdings variiert die Anzahl der Beiträge nach Nutzer stark. Während die Nutzer mit den IDs 1621 und 1701 auf über 3.000 Beiträge kommen, sind es bei 1921 und 1824 mit respektive 2.352 und 2.052 Beiträgen schon deutlich weniger. Schlusslichter bilden die Nutzer 1411 und 1501 mit nur 174 und 105 Beiträgen.
Neben den Unterschieden in der Anzahl der veröffentlichten Beiträge lässt sich auch erkennen, dass das Verhältnis zwischen den verschiedenen Typen der Beiträge, die hier zusammenfassend als textbasierte und nicht textbasierte Beiträgen dargestellt werden, von Nutzer zu Nutzer unterschiedlich sein kann. Vor allem der Nutzer mit der größten Anzahl an veröffentlichten Beiträgen, Nutzer 1701, hat mit 6% einen verhältnismäßig niedrigen Prozentsatz an textbasierten Beiträgen auf seiner Chronik. Das Verhältnis der nicht-textbasierten zu den textbasierten Beiträgen der meisten anderen Nutzer bewegt sich zwischen 2:1 oder 1:2. Den größten Anteil textbasierter Beiträge haben mit 80% die Nutzer 1112 und 2211, wobei vor allem Letzterer auch insgesamt über eine nicht allzu kleine Menge an Beiträgen verfügt.
| VID/LINK/PIC | textbasiert (mit VID/LINK/PIC) | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| 1021 | 241 | 30 | 567 | 70 | 808 | 100 |
| 1112 | 135 | 20 | 549 | 80 | 684 | 100 |
| 1211 | 753 | 71 | 306 | 29 | 1.059 | 100 |
| 1301 | 191 | 29 | 458 | 71 | 649 | 100 |
| 1411 | 106 | 61 | 68 | 39 | 174 | 100 |
| 1501 | 50 | 48 | 55 | 52 | 105 | 100 |
| 1621 | 1.666 | 48 | 1.824 | 52 | 3.490 | 100 |
| 1701 | 3.319 | 94 | 198 | 6 | 3.517 | 100 |
| 1824 | 1.534 | 75 | 518 | 25 | 2.052 | 100 |
| 1921 | 627 | 27 | 1.725 | 73 | 2.352 | 100 |
| 2001 | 64 | 32 | 135 | 68 | 199 | 100 |
| 2101 | 149 | 31 | 329 | 69 | 478 | 100 |
| 2211 | 247 | 20 | 994 | 80 | 1.241 | 100 |
| 2310 | 85 | 17 | 424 | 83 | 509 | 100 |
| Gesamt | 9.167 | 53 | 8.150 | 47 | 17.317 | 100 |
Es besteht somit kein Zusammenhang zwischen der Anzahl der geposteten Beiträge und dem Typ des Beitrags, zusammenfassend als textbasiert und nicht textbasiert dargestellt. Es muss aber vermerkt werden, dass die Anzahl der auf der Chronik veröffentlichten Beiträge stark variieren kann und zwischen 105 und 3.517 Beiträgen liegt, und dass einzelne Nutzer, wie Nutzer 1701 mit seinen 3.319 nicht textbasierten Beiträgen, einen großen Anteil an dem insgesamt für das Korpus ermittelten Verhältnis an textbasierten und nicht textbasierten Beiträgen haben (sieh Tabelle 19).
Unterteilung der Beiträge in Statusmeldungen und Posts
Wie in Kapitel bereits dargestellt, lassen sich die an den Chroniken geposteten Beiträge in Facebook Statusmeldungen und Facebook Posts unterteilen. Bei den 17.317 Beiträgen, die von den Facebook Chroniken extrahiert wurden, handelt es sich dabei bei 12.361 (also 71% aller Beiträge) um Statusmeldungen, also um vom Nutzer selbst verfasste Beiträge, während die restlichen 4.956 (also 29% der Beiträge) von befreundeten Nutzern veröffentlichte Posts darstellen. Interessant dabei ist, dass die Anzahl der nicht textbasierten Beiträge bei den Posts recht gering ist und es sich so bei 83% der Posts um textbasierte Beiträge handelt. Bei den Statusmeldungen ist die Anzahl der nicht textbasierten Beiträge höher. Hier handelt es sich bei 67% der geposteten Statusmeldungen um Bilder, Videos oder Links.182
| textbasiert | nicht textbasiert | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| Statusmeldungen | 4.045 | 33 | 8.316 | 67 | 12.361 | 100 |
| Posts | 4.105 | 83 | 851 | 17 | 4.956 | 100 |
| Gesamt | 8.150 | 47 | 9.167 | 53 | 17.317 | 100 |
Es lässt sich hier sehr deutlich die kommunikative Funktion von Facebook Statusmeldungen und Posts ablesen. Die vielen textbasierten Posts lassen Vermutungen zur verwendeten Sprache zu, nämlich dass beispielsweise häufig der Nutzer direkt angesprochen wird und sich andere der Dialogizität geschuldeten Merkmale finden lassen (siehe DEFAULT).
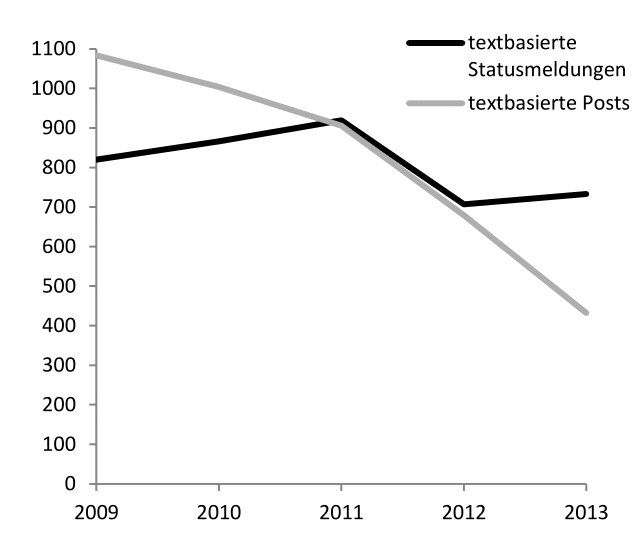
Anzahl textbasierter Statusmeldungen und Posts zwischen 2009 und 2013 (Anzahl der Beiträge).
(Lizenz: CC BY SA)
Bei der Betrachtung der Anzahl aller textbasierten Beiträge zwischen 2009 und 2013 fällt auf, dass die Anzahl der Posts stark zurückgeht, von 1.084 im Jahr 2009 auf 432 in 2013. Bei den textbasierten Statusmeldungen ist zunächst ein Anstieg zu beobachten (von 820 in 2009 auf 906 in 2006). Die Änderungen der Facebook Chronik und der damit verbundenen neu eingeführten Funktionen, die das Teilen von Bildern und Videos erleichtern (siehe Tabelle 1), führt zu einem leichten Rückgang der Anzahl der Statusmeldungen. Diese steigen aber bis 2013 von 679 (in 2012) auf 733 an. Für die Datenauswertung bedeutet dies, dass die Anzahl der vom Nutzer selbst verfassten Beiträge nur leicht zurückgeht, aber mehr oder weniger konstant bleibt. Allerdings nehmen im Laufe der Jahre die an den Nutzer gerichteten Nachrichten, also die Posts, ab. Das führt zu der Vermutung, dass damit auch die Merkmale der Dialogizität in der verwendeten Sprache abnehmen könnten.
Allerdings kann Interaktion bei Facebook auch noch außerhalb der Statusmeldungen und Posts stattfinden, nämlich mittels Kommentaren und Likes, deren allgemeine Verteilung im Folgenden kurz präsentiert werden soll.
Kommentare zu Facebook Beiträgen
Insgesamt werden 6.242 der 17.341 Facebook Beiträge kommentiert. Das heißt, dass ungefähr jeder dritte Beitrag kommentiert wird, wie das Verhältnis der Anzahl der kommentierten Beiträge und der Gesamtanzahl der Beiträge diesen Typs in Tabelle 21 zeigt. Damit liegt die Anzahl der kommentierten Beiträge unter der von Tavosanis (vgl. 2011, 209-210), in dessen Korpus es bei 48% aller Beiträge Kommentare gibt (allerdings ist das Korpus des Autors mit 1.855 Beiträgen deutlich kleiner).
Es werden vor allem textbasierte Beiträge kommentiert; ungefähr jede zweite Statusmeldung und jeder zweite Post enthalten Kommentare. Bei den nicht textbasierten Statusmeldungen ist das Verhältnis mit 0,17 Kommentaren pro Beitrag am geringsten. Dass Posts im Allgemeinen mit 0,49 Kommentaren häufiger als Statusmeldungen, wovon jede nur 0,31 Kommentare erhält, kommentiert werden, lässt den Schluss zu, dass diese hier meist an den Nutzer eines Accounts gerichtet sind und dieser dementsprechend darauf antwortet.
Die Anzahl der Kommentare und die Tatsache, dass die Beiträge überhaupt kommentiert werden, zeigen, dass Facebook Nutzer interaktiv sind und sich auch regelmäßig mit ihren Facebook Freunden austauschen. Auch die Anzahl der Likes kann Aufschluss darüber geben, wie interaktiv Nutzer sich auf Facebook verhalten.
Anzahl der Likes
Likes drücken im Gegensatz zu den Facebook Kommentaren nichtsprachlich Zustimmung aus und stellen somit ebefalls eine Art der Kommunikation dar (siehe DEFAULT).
| textbasiert | nicht textbasiert | Gesamt | ||||
| Anz. | Verhältnis Likes /Beiträge | Anz. | Verhältnis Likes /Beiträge | Anz. | Verhältnis Likes /Beiträge | |
| Statusmeldungen | 12.646 | 3,13 | 11.531 | 1,39 | 24.177 | 1,96 |
| Posts | 5.286 | 1,29 | 2.551 | 3,00 | 7.837 | 1,58 |
| Gesamt | 17.932 | 2,20 | 14.082 | 1,54 | 32.014 | 1,85 |
Bei den 17.341 Facebook Beiträgen wird insgesamt 32.014 Mal der „gefällt-mir“-Button angeklickt. Das heißt, dass jeder Beitrag 1,85 Likes erhält. Dabei erhalten die textbasierten Statusmeldungen mit im Schnitt 3,13 Likes im Verhältnis zu den anderen Beiträgen die größte Zustimmung, gefolgt von nicht textbasierten Posts. Schlusslicht bilden die textbasierten Posts, die nur etwas mehr als einen Like pro Beitrag erhalten.
Das zeigt, dass die Like Funktion von den Facebook Nutzern genutzt wird und so Beiträge häufig auch nichtsprachlich mit Hilfe von Likes kommentiert werden. Im Vergleich mit der Anzahl der kommentierten Beiträge kann man sehen, dass vor allem die vom Nutzer selbst verfassten, textbasierten Statusmeldungen am häufigsten sowohl kommentiert als auch gelikt werden, diese somit einen hohen Stellenwert einnehmen und am meisten Beachtung finden.
Anzahl der Token und Types im Facebook Korpus
Nachdem nun die Verteilung der Korpusdaten nach Beitragstyp, Jahr und Nutzer sowie die entsprechenden Möglichkeiten zur Interaktion, die in Verbindung mit den Beiträgen stehen, vorgestellt wurden, soll nun auch ein Blick in die Primärdaten erfolgen. Dafür soll die Verteilung der Token sowie der Types in den textbasierten Facebook Statusmeldungen und Posts vorgestellt werden und mittels einer Frequenzliste ein kurzer Überblick über deren Inhalte gegeben werden.
Die Ermittlung der Anzahl der Token erfolgt mittels einer MySQL Abfrage, mit der alle durch Leerzeichen voneinander getrennten Elemente gezählt werden. Insgesamt können so in allen Facebook Beiträgen 109.078 Token ermittelt werden. Das ergibt eine durchschnittliche Länge von 13 Token pro Beitrag. Da die Nutzer unterschiedlich viele Beiträge gepostet haben, könnte ebenso die Längen dieser erheblich variieren. Tabelle 23 zeigt, dass dies tatsächlich der Fall ist.
| textbasierte Beiträge | Token | Verhältnis | |
| Anz. | Anz. | Token/Beitrag | |
| 1021 | 567 | 7.540 | 13 |
| 1112 | 549 | 5.864 | 11 |
| 1211 | 306 | 6.865 | 22 |
| 1301 | 458 | 9.435 | 21 |
| 1411 | 68 | 727 | 11 |
| 1501 | 55 | 937 | 17 |
| 1621 | 1.824 | 23.408 | 13 |
| 1701 | 198 | 2.458 | 12 |
| 1824 | 518 | 4.756 | 9 |
| 1921 | 1.725 | 22.937 | 13 |
| 2001 | 135 | 1.063 | 8 |
| 2101 | 329 | 3.578 | 11 |
| 2211 | 994 | 13.482 | 14 |
| 2310 | 424 | 6.028 | 14 |
| Gesamt | 8.150 | 109.078 | 13 |
So sind die Beiträge auf der Chronik des Nutzers 1211 durchschnittlich mit 22 Token pro Beitrag am längsten, während die Beiträge von Nutzer 2001 und 1824 mit nur 8 und 9 Token pro Beitrag deutlich kürzer sind. Die meisten Beiträge der anderen Nutzer bewegen sich allerdings um den Mittelwert von 13 Token pro Beitrag und auch bei Tavosanis (vgl. 2011, 209) liegt die durchschnittliche Anzahl an Wörtern eines Facebook Posts mit 11,27 in einem ähnlichen Bereich, weshalb der Autor den Beiträgen auch einen synthetischen Charakter zuspricht. Eine Korrelation zwischen der Anzahl der textbasierten Beiträge einzelner Nutzer und der durchschnittlichen Tokenlänge lässt sich dabei nicht beobachten.
Mit AntConc184, einem Konkordanz-Programm für die Korpusanalyse, kann außerdem die Anzahl von Word Token und Word Types bestimmt werden. In allen textbasierten Beiträgen, Statusmeldungen und Posts (ohne Kommentare) gibt es 115.814 Token und 18.373 Types. Die Abweichung zu der oben ermittelten Anzahl an Token im Facebook Korpus kommt zustande, da die Token bei AntConc nach einem anderen Schema getrennt werden. So werden durch Bindestriche getrennte Komposita (z.B. wink-Emoticon) als zwei Token gezählt, während der MySQL Befehl die Elemente nur nach Leerzeichen trennt.
Mit Hilfe von AntConc kann auch das Type-Token-Verhältnis (en. type-token-ratio) ermittelt werden, das 0,159 beträgt. Bei dem Korpus itWac (vgl. Baroni & Bernardini & Ferraresi & Zanchetta 2009, 9), das ebenso CMC Daten – genauer gesagt, Daten von italienischen Webseiten verschiedener Art – enthält, liegt dieses Verhältnis bei 0,0023 Types pro Token. Bei der deutschen Version dieses Korpus, dem deWac (ebd.), ist das Type-Token-Verhältnis 0,0073. Das heißt, dass es im Facebook Korpus im Verhältnis zu den Token, mehr verschiedene Types gibt als in den anderen Korpora.
Interessant dabei ist auch die Frequenzliste der am Häufigsten gefundenen Token, (siehe Tabelle 24 für die ersten 120 Token aus dieser Frequenzliste). Diese wird von emoticon angeführt, welchem auf dem vierten Platz smile, auf dem zehnten Platz heart und auf dem 18. Platz wink folgen. Bei diesen, während der Datenbereinigung für die Bezeichnung von Emoticons gewählten Begriffen (in der Tabelle durch Kursivschreibung hervorgehoben), handelt es sich genau genommen nicht um Token, sondern eher um Pseudo-Token. Sie sind eine Art Platzhalter für die bei Facebook als Piktogramme dargestellten Emoticons. Das lässt nichtsdestotrotz den Schluss zu, dass Emoticons in den Facebook Beiträgen einen hohen Stellenwert einnehmen.
Die Frequenzliste wird wie erwartet von italienischen und deutschen Funktionswörtern, wie Artikeln, Präpositionen, Pronomen, angeführt. Die ersten Autosemantika, die in dieser Rangtabelle auftauchen, lassen schon auf kommunikative Funktionen der Beiträge sowie deren Inhalte schließen: bene auf Platz 48, bella auf Platz 62, buon auf Platz 80 sowie bacio und auguri auf den Plätzen 88 und 90.185 Unter den einhundert am häufigsten verwendeten Token tauchen ebenfalls englische Token auf: the auf Platz 39, you auf Platz 66 (sowie wahrscheinlich das als Kurzschreibweise für you gewählte u auf Platz 86) und and auf Platz 99.
| Rang | Anz. | Token | Rang | Anz. | Token | Rang | Anz. | Token |
| 1 | 3757 | emoticon | 41 | 297 | al | 81 | 190 | ha |
| 2 | 1800 | a | 42 | 296 | wie | 82 | 187 | nicht |
| 3 | 1558 | e | 43 | 295 | das | 83 | 185 | für |
| 4 | 1467 | smile | 44 | 290 | dir | 84 | 182 | domani |
| 5 | 1409 | in | 45 | 287 | te | 85 | 178 | alle |
| 6 | 1316 | di | 46 | 281 | sei | 86 | 177 | u |
| 7 | 1201 | che | 47 | 279 | grin | 87 | 176 | va |
| 8 | 1008 | un | 48 | 265 | bene | 88 | 175 | bacio |
| 9 | 1002 | la | 49 | 261 | ist | 89 | 175 | bin |
| 10 | 975 | heart | 50 | 249 | mal | 90 | 171 | auguri |
| 11 | 881 | il | 51 | 244 | to | 91 | 171 | dann |
| 12 | 877 | ich | 52 | 242 | tutto | 92 | 170 | ne |
| 13 | 813 | und | 53 | 240 | es | 93 | 170 | quando |
| 14 | 717 | non | 54 | 235 | anche | 94 | 169 | della |
| 15 | 683 | per | 55 | 234 | zu | 95 | 169 | o |
| 16 | 613 | i | 56 | 228 | grazie | 96 | 168 | am |
| 17 | 612 | è | 57 | 224 | dich | 97 | 167 | sempre |
| 18 | 609 | wink | 58 | 221 | wir | 98 | 166 | ja |
| 19 | 571 | ma | 59 | 220 | del | 99 | 165 | and |
| 20 | 544 | mi | 60 | 219 | auf | 100 | 163 | alles |
| 21 | 506 | da | 61 | 216 | auch | 101 | 163 | schon |
| 22 | 495 | ti | 62 | 216 | bella | 102 | 161 | s |
| 23 | 478 | come | 63 | 215 | was | 103 | 154 | casa |
| 24 | 460 | du | 64 | 213 | mia | 104 | 154 | lo |
| 25 | 456 | ciao | 65 | 213 | noch | 105 | 152 | wenn |
| 26 | 441 | die | 66 | 211 | you | 106 | 151 | nach |
| 27 | 424 | l | 67 | 208 | tutti | 107 | 149 | ora |
| 28 | 422 | si | 68 | 206 | wieder | 108 | 148 | gli |
| 29 | 383 | ci | 69 | 204 | me | 109 | 147 | hai |
| 30 | 376 | con | 70 | 202 | frown | 110 | 146 | bist |
| 31 | 353 | sono | 71 | 198 | mich | 111 | 145 | den |
| 32 | 342 | le | 72 | 197 | alla | 112 | 143 | morgen |
| 33 | 339 | una | 73 | 195 | an | 113 | 142 | hey |
| 34 | 337 | ho | 74 | 195 | stai | 114 | 141 | dass |
| 35 | 335 | io | 75 | 195 | tu | 115 | 141 | im |
| 36 | 323 | der | 76 | 194 | is | 116 | 141 | nn |
| 37 | 323 | se | 77 | 193 | aber | 117 | 139 | no |
| 38 | 314 | so | 78 | 192 | ein | 118 | 138 | hab |
| 39 | 308 | the | 79 | 192 | mir | 119 | 138 | von |
| 40 | 305 | mit | 80 | 190 | buon | 120 | 137 | più |
Es kann erwartet werden, dass sowohl das Deutsche als auch das Italienische in den Facebook Beiträgen verwendet wird, mit einem etwas höheren Anteil an italienischem Sprachmaterial. Aber auch die englische Sprache wird in den Beiträgen verwendet.
Die hier präsentierte Übersicht, lässt Aussagen zu den Facebook Nutzern zu. Vom Alter ausgehend, stellen diese einen typischen Facebook Nutzer dar. Nach den Angaben zu Heimatort und dem aktuellem Wohnsitz zu urteilen, könnte es sich bei der Mehrheit der Nutzer um aus Italien stammende Personen handeln, die irgendwann im Laufe ihres Lebens nach Deutschland gekommen sind. Für eine genauere Bestimmung fehlen Angaben dazu, wann eine Person von einem Land in ein anderes gezogen ist und auch die Dauer des Aufenthalts kann nicht angegeben werden. Allerdings ist Facebook als ein virtueller Raum anzusehen und so spielen Herkunft und Wohnort nur eine untergeordnete Rolle. Dafür geben die in der Accountinformation angegebenen Sprachkenntnisse einen Aufschluss über die Online Bilingualität der Facebook Nutzer und deren Bewusstsein darüber. Schließlich lässt die große Anzahl an Facebook Freunden vermuten, dass mit diesen auch mittels Facebook Statusmeldungen und Posts kommuniziert wird.
Der zweite Teil der Übersicht zeigt, dass es einen stetigen Anstieg an nicht- und parasprachlicher Kommunikation in den Facebook Beiträgen gibt. Darauf deutet zum einen die stetig wachsende Anzahl an nicht textbasierter Statusmeldungen. Zum anderen sind aber auch die verwendeten Emoticons, die die Frequenzliste der im Korpus verwendeten Types anführen, ein Indiz dafür. Trotzdem überwiegen zwischen 2009 und 2013 die textbasierten Beiträge, wobei es insgesamt mehr Statusmeldungen als Posts gibt. Das spricht für die kommunikative Selbstdarstellungsfunktion in den Beiträgen. Wie bereits in Kapitel beschrieben, wird bei einem Großteil der Statusmeldungen auf nicht- oder parasprachliche Kommunikation zurückgegriffen, während die Posts meist textbasiert sind. Das wiederum lässt erwarten, dass es hier häufiger zu Merkmalen der Dialogizität kommt, die sich in der oder den verwendeten Sprachen widerspiegeln. Um diese Sprachen zu ermitteln und anschließend auf die sprachlichen und kommunikativen Merkmale der Facebook Beiträge einzugehen, müssen die Primärdaten annotiert werden. Das Vorgehen bei der Korpusannotation und die verwendete Methode sollen daher Inhalt des folgenden Kapitels sein.
5.5. Korpusannotation
Unter Korpusannotation versteht man das Hinzufügen von linguistischen Informationen, also „Werten“, die auf sprachwissenschaftlichen Interpretationen beruhen, zu einem elektronischen Korpus. Nach Leech (1997, 2) ist die Korpusannotation „a crucial contribution to the benefit a corpus brings, since it enriches the corpus as a source of linguistic information for future research and development“. Korpusannotation ist dabei auf allen linguistischen Ebenen möglich und kann in diversen Formen erfolgen, je nach Fragestellungen und Forschungsinteresse. Folgende Annotationsebenen sind denkbar (vgl. Lemnitzer & Zinsmeister 2010, 64; McEnery & Xiao & Tono 2006, 33-41):
| Ebene | Annotation |
| Phonologisch | Silbenstruktur, prosodische Merkmale |
| Morphologisch | Flexionsmorphologie, Affixe, Grundformen |
| Morphosyntax | Wortarten (POS = Part-Of-Speech Tagging) |
| Syntax | Konstituenten, Dependenzen |
| Semantik | Eigennamen, Lesarten (Word Senses), thematische Rahmen (Frames) |
| Pragmatik | Informationsstruktur, Koreferenz, Diskursstruktur |
Desweitere sind stilistische Annotationen, Error tagging und Problem-orientierte Annotationen denkbar (vgl. McEnery & Xiao & Tono 2006, 41-43), aber auch eine Annotation nach der verwendete Sprache sollte in diese Liste der Annotationsebenen aufgenommen werden.
Dabei gibt es drei Möglichkeiten der Annotation: automatisch, computergestützt (semi-automatisch) und manuell. Während bei der ersten Möglichkeit Programme (wie beispielsweise der TreeTagger, siehe DEFAULT) die Annotation automatisch durchführen, ist bei der computergestützten Analyse eine manuelle Nachbearbeitung notwendig. Bei der manuellen Methode werden die Annotationen einzeln per Hand hinzugefügt. Jede dieser Möglichkeiten bietet dabei Vor- und Nachteile. Bei der automatischen Annotation ist im Vorfeld ein großer Arbeitsaufwand notwendig, vor allem wenn das Computerprogramm, das die Annotation durchführen soll, selbst entworfen und geschrieben wird. Ein reduzierter Aufwand besteht aber auch, wenn entsprechende bereits existierende Annotationsprogramme installiert und erlernt werden müssen. Die Zeitersparnis ist bei dieser Art der Annotation ein großer Vorteil, allerdings ist kaum ein Programm fehlerfrei, weshalb meist eine manuelle Nachbearbeitung notwendig ist. Die manuelle Annotation hingegen ist die zeitaufwendigste und auch hier kann es zu Fehlern kommen.186 Schließlich bleibt noch die computergestützte Methode der Annotation, bei der ebenfalls zeitersparend annotiert wird und durch eine manuelle Bearbeitung die Fehlerquote reduziert wird, auch wenn sie keinen Anspruch darauf erheben kann, zu einhundert Prozent fehlerfrei zu sein.
Schließlich sollte auch noch die Art der Annotation festgelegt werden. Es wird generell zwischen eingebetteter (en. embedded) und nicht-eingebetteter (en. standalone) Annotation unterschieden. Eingebettete Korpusannotation bedeutet, dass die Informationen direkt in den Text integriert werden. Bei der nicht-eingebetteten Methode werden die linguistischen Annotationen in separaten Dokumenten gespeichert, die dann über beispielsweise Hypertext die entsprechenden Verlinkungen zum Originaltext enthalten. Die letztere Methode ist wohl die am Häufigsten verwendete und wird auch in den Richtlinien der Text Encoding Initiative (TEI) vorgeschlagen.187 Die Vorteile dieser Annotationsart sind, dass sie viele, sich überlappende Annotationshierarchien erlauben, alternative Annotationsschemata auf dieselben Daten angewandt werden können. Außerdem können neue Annotationen hinzugefügt oder Bestehende geändert werden, ohne dass es andere Ebenen betrifft (vgl. McEnery & Xiao & Tono 2006, 44).
Für das Facebook Korpus wurde eine computergestützte, nicht-eingebettete Methode der Annotation gewählt. Die Annotationen werden in der Datenbank in entsprechenden Tabellen gespeichert. Die Annotationen sollen dazu beitragen, die Sprache der Beiträge und schließlich einzelner Token zu bestimmen. Dadurch können auch Sprachwechsel und Code-Switchings identifiziert werden, um schließlich Aussagen darüber zu machen, welchem Typ diese zuzuordnen sind und welche Elemente geswitcht werden (siehe Kapitel ). Zum anderen erfolgt die Annotation auf morphosyntaktischer Ebene, bei der einzelne Wortarten und Lemmata bestimmt werden.
Die größte Herausforderung bei der Annotation stellt die Sprachzuweisung dar. Bei jeder Facebook Statusmeldung und jedem Post soll die entsprechende darin verwendete(n) Sprache(n) gekennzeichnet werden, um später die Statusmeldungen, in denen Code-Switching erfolgt, untersuchen zu können. Beim Testen verschiedener Möglichkeiten können sowohl Vor- als auch Nachteile verglichen werden. Es sei vorweggenommen, dass keine zufriedenstellende Lösung unter Verwendung eines einzelnen automatisierten Programmes gefunden werden konnte, sondern dass die benutzte Vorgehensweise eine Kombination aus automatischen Zuweisungen und einer umfassenden manuellen Kontrolle mit entsprechenden Verbesserungen darstellt. Im Folgenden wird deshalb zunächst die lexikonbasierte Bestimmung der Sprache vorgestellt, gefolgt von der Präsentation eines Annotationsprogramms mit dessen Hilfe die Korpusdaten morphosyntaktisch getaggt werden können. Im Anschluss daran wird die daraus resultierende kombinierte Annotationsmethode vorgestellt. Die Bestimmung der Code-Switching Typen erfolgt aus dem Auslesen der Daten und ist Inhalt von Kapitel , genauso wie die Bestimmung der kommunikativen Funktion, der eine ausführliche Interpretation der Daten vorausgehen wird.
5.5.1. Lexikonbasierte Sprachzuweisung
Die erste getestete Möglichkeit der Sprachzuweisung ist die Zuweisung der Sprache mit Hilfe eines Abgleichs der einzelnen Token mit entsprechenden Einträgen aus deutschen, italienischen und englischen Lexika.188 Dafür werden in der Datenbank drei Tabellen angelegt, deren Inhalt Wortlisten des Deutschen, Italienischen und Englischen darstellen.
| Sprache | Anzahl Token | Herkunft der Daten |
| Deutsch | ca. 201.000 Token | Kombination aus den Daten der Top 10.000 Wortschatzliste der Uni Leipzig () und Liste mit 198.706 Wörter nach alter Rechtschreibung, nur Nomen ( ) |
| Italienisch | ca. 250.000 Token | DIZIONARIO ITALIANO A cura di Luigi M. Bianchi Toronto, Canada Prima Edizione (Riveduta) Maggio 1994 |
| Englisch | ca. 58.000 Token | Mieliestronk’s list of more than 58 000 English words ( ) |
In einem nächsten Schritt werden alle gesammelten Beiträge tokenisiert, das heißt, jedem Token wird eine Zeile in der Datenbank zugewiesen.189 Daraufhin wird für jede der Sprachen eine Spalte angelegt, die mit 1 markiert wird, wenn das entsprechende Token eines Facebook Beitrags auch in einem der Lexika vorkommt, und mit 0, wenn nicht. Diese Operation kann mit Hilfe von MySQL-Befehlen direkt in der Datenbank vorgenommen werden. Eine Tabelle dieser Art sieht wie die in Beispiel (65) aus.
| Token | deutsch | italienisch | englisch |
| Freund | 1 | 0 | 0 |
Daraufhin können mit einem weiteren Befehl die einzelnen Token einer Statusmeldung oder eines Posts wieder zusammengefügt werden, und man erkennt, ob in einem Beitrag Token aus mehreren Sprachen vorkommen, also Code-Switching (siehe Kapitel ) stattfindet.
Allerdings birgt diese Methode einige Probleme. Auf der einen Seite gibt es viele Token, die in keiner der drei Sprachtabellen vorkommen. Beim Herausfiltern dieser nicht zugewiesenen Token stellt sich heraus, dass die Anzahl dieser sehr hoch ist, da in den Lexika häufig nur die Grundformen, nicht aber alle flektierten Formen gespeichert sind. Zudem sind die spezifischen Schreibweisen der CMC nicht in den Sprachlexika enthalten und müssen manuell hinzugefügt werden. Das betrifft beispielsweise die Verwendung von Abkürzungen und Akronymen, die beliebig häufige Wiederholung von Buchstaben oder Satzzeichen, aber auch die Verwendung von Interjektionen und anderen Füllwörtern sowie Tippfehler.
| Token | deutsch | italienisch | englisch |
| in | 1 | 1 | 1 |
Auf der anderen Seite gibt es viele Token, die in mehreren der drei verwendeten Sprachen vorkommen können (wie Beispiel (76) zeigt). Bei diesen kann die Sprachbestimmung nur unter Beachtung der Frequenz und des sprachlichen Kontexts, in dem diese stehen, erfolgen. Auch dies kann hier nur in manueller Aufarbeitung erfolgen, weshalb eine andere Methode der Sprachzuweisung bevorzugt wird.
5.5.2. Morphosyntaktische Annotation mit dem TreeTagger
Das Programm TreeTagger – a language independent part-of-speech tagger ist eine Anwendung zum Annotieren von Texten und wurde im Rahmen des TC Projekts des Instituts für Computerlinguistik der Universität Stuttgart von Helmut Schmid entwickelt (Schmid o.J.). Mit Hilfe dieses Programms können in Sprachen, wie Deutsch, Englisch, Französisch, Italienisch oder Spanisch, den einzelnen Token Wortarten und Lemmata hinzugefügt werden. Dafür werden die Textdateien zuerst tokenisiert und in einzelne Token geteilt. Anschließend folgt das Part-of-Speech-Tagging (POS), das Hinzufügen von Wortarten mit Hilfe von Tags.190 Für die Tokenisierung und das anschließende POS-Tagging können schon erstellte Parameterdateien verwendet werden, die von der Webseite des TreeTaggers heruntergeladen werden müssen (vgl. Schmid o.J.). Eine mit Hilfe des TreeTaggers annotierte Textdatei in italienischer Sprache sieht schließlich folgendermaßen aus:
| Token | POS-Tag | Lemma |
| Poco | ADV | poco |
| dopo | PRE | dopo |
| Stephen | NPR | Stephen |
| Hawking | NOM | Hawking |
| ha | VER:pres | avere |
| rincarato | VER:pper | rincarare |
| la | DET:def | il |
| dose | NOM | dose |
| . | SENT | . |
In der ersten Spalte werden zunächst die einzelnen Token angezeigt, anschließend der Tag für die entsprechende Wortart. Die Beschreibung der POS-Tags der einzelnen Sprachen ist in sogenannten Tagsets dokumentiert (Schmid o.J.). So steht NOM im Italienischen für Nomen (vgl. Stein o.J.); im Deutschen hingegen wird das Nomen mit NN bezeichnet (vgl. Schiller & Teufel & Stöckert 1995). In der letzten Spalte wird die lemmatisierte Form des Tokens dargestellt.
Allerdings funktioniert das Programm nur für einzelne Sprachen und nicht für gemischtsprachige Textdateien. Es gibt bestenfalls die Möglichkeit, Fremdsprachliches mit entsprechenden Tags zu kennzeichnen, beispielsweise FM im deutschen Tagset (vgl. Schiller & Teufel & Stöckert 1995). Das Programm kann entweder für die eine oder für die andere Sprache verwendet werden, aber nicht für Beiträge, in denen mehrere Sprachen vorkommen. Die Annotation zum Beispiel nur für das Italienische vorzunehmen, um danach alle als fremdsprachlich markierte Token erneut – diesmal mit dem Tagset für das Deutsche – zu annotieren, würde die statistische Grundlage, auf der das Programm beruht, verfälschen.
Das Programm ist demnach sehr hilfreich beim Taggen in einer einzelnen Sprache und erkennt (fast) alle flektierten Formen und häufig sogar Tippfehler und alternative Schreibweisen. Allerdings können die vorhandenen Parameterdateien nicht gemischtsprachige Texte annotieren, weshalb das Programm zwar einen guten Ansatz darstellt, aber für die Zwecke der Korpusannotation von Facebook Beiträgen, die Code-Switching enthalten, noch modifiziert werden muss.
5.5.3. Kombinierte Methode – Sprachzuweisung mit POS-Tagging
Die für die Annotation des Facebook Korpus erarbeitete und angewandte Methode, lässt sich in vier Schritte gliedern:
- Sprachzuweisung auf Beitragsebene
- Tokenisierung über MySQL-Output
- Sprachzuweisung und gleichzeitiges POS-Tagging mit dem TreeTagger
- Manuelle Kontrolle, Überarbeitung und Korrektur
Die einzelnen Schritte sollen im Folgenden vorgestellt werden.
5.5.3.1. Sprachzuweisung auf Beitragsebene
Zunächst erfolgt eine manuelle Sprachzuweisung auf Beitragsebene, die später mithilfe des TreeTaggers verifiziert werden kann. Dafür werden zunächst alle textbasierten Beiträge in der Datenbank gefiltert und nach Nutzern sortiert. Im Anschluss wird jedem Beitrag, insofern möglich, manuell eine Sprache zugewiesen. Die Zuweisung für die Sprachen Deutsch (de), Italienisch (it) und Englisch (en) ist dabei ohne Probleme möglich.191 Wenn ein Beitrag in einer anderen als der genannten Sprachen geschrieben wird, wird dieser mit ot (für ‚andere Sprache‘) markiert und wenn mehrere Sprachen in einem Beitrag verwendet werden, egal in welcher Sprachkombination, wird dieser mit mx (für ‚gemischtsprachiger Beitrag‘) markiert. Folgende Tags werden demzufolge verwendet:
| Bezeichnung | Sprache |
| de | Deutsch |
| it | Italienisch |
| en | Englisch |
| ot | andere Sprache |
| mx | mehr als eine Sprache |
| nn | Sprachzuweisung nicht möglich |
Bei einigen Statusmeldungen ist eine sprachliche Zuordnung nicht möglich, wie die Beispiele (67), (68) und (69) zeigen. Darunter fallen Beiträge, die nur eine Interjektion, wie Beispiel (67), eine graphische Darstellung von prosodischen Merkmalen, wie in (68), oder Emoticons, wie in (69) sowie Verlinkungen, Namen, Zahlen und Symbole enthalten. Solche Beiträge werden mit dem Tag nn markiert.
[FB 1021_28]
woooww!
[FB 1021_695]
ahaha
[FB 1021_715]
„smile“-Emoticon
Zudem existieren einige Besonderheiten, die beim Taggen berücksichtigt werden müssen. Eigennamen für Personen, Schauspieler, Sänger, Filme, für die es keine deutsche oder italienische Entsprechung gibt, können keiner konkreten Sprache zugeordnet werden. Sie bekommen den Tag nn). So wurde beispielsweise der Statusmeldung in (70) die Sprache Deutsch zugewiesen, da es sich bei Inglorious Basterds und Final Destination um Filme handelt, deren Titel im Deutschen nicht übersetzt wurden.
[FB 1021_715]
Ich hoffe dass ´Inglorious Basterds´ gut war! Final Destination war ziemlich lustig, aber auch grausam. […]
Wenn jedoch Entsprechungen für Eigennamen in anderen Sprachen vorhanden sind, wird der Tag der entsprechenden Sprache zugewiesen. Beispielsweise gibt es häufig für deutsche Länder- und Städtenamen, wie Berlin oder Italien, italienische Entsprechungen, ‚Berlino‘ und ‚Italia‘, die normalerweise auch in den italienischen Beiträgen verwendet werden, wie das Beispiel in (71) zeigt. In Beispiel (72) wird hingegen der Ortsname auf Deutsch in einem ansonsten auf Italienisch verfassten Post verwendet, weshalb hier von einer Verwendung mehrerer Sprachen ausgegangen wird. Bei Städtenamen, für die es in der jeweils anderen Sprache keine Entsprechung gibt, wie bei Oldenburg in (73), kann hingegen kein Sprachwechsel angenommen werden.
[FB 1021_215]
ma ciaoooo!!!allora come si sta a Berlino??nostalgia di casa……?bacione
[FB 1021_690]
Mbè come procede ad Hamburg???
[FB 1021_740]
Oggi ho scoperto che un tesista del mio gruppo ad Oldenburg ti conosce: tal [NAME]!!!
Einige Statusmeldungen werden als Sprachwechsel gekennzeichnet, obwohl davon ausgegangen werden kann, dass es sich bei dem fremdsprachlichen Material um (assimiliertes) Lehngut handelt. Diese sollen aber später noch genauer untersucht werden, wie beispielsweise die Beiträge (74) und (75). Sie werden deshalb mit dem Tag mx versehen (wobei (75) sowieso wegen der Interjektion mann als Sprachmischung gekennzeichnet worden wäre).
[FB 1021_44]
giorno di divino relax..
[FB 1021_491]
ok, io dimentico la luce accesa quando torno stordita dai partys e non faccio la raccolta differenziata.. ma tu ieri sera hai lasciato la finestra del bagno aperta!!! mann..
Nach dem Schritt der Sprachzuweisung auf Beitragsebene können die textbasierten Beiträge nach Sprachen gefiltert werden. Diese werden als Tabellen in der Datenbank gespeichert; so werden in der Datenbank facebook_cs die textbasierten Beiträge in den Tabellen txt_it, txt_de, txt_en, txt_mx, txt_nn nach Sprachtypen sortiert gespeichert (Aufbau der Datenbank siehe Kapitel ). Des Weiteren wird die Tabelle txt_alle angelegt, in der alle textbasierten Beiträge inklusive Sprachtags gespeichert werden.192
5.5.3.2. Tokenisierung über MySQL-Output
Nach der Sprachzuweisung auf Beitragsebene wird die Tabelle txt_mx, die nur textbasierte, gemischtsprachige Beiträge enthält, aus der Datenbank exportiert. Dieser Output, der sowohl die ID der Facebook Beiträge als auch den Text enthält, wird dazu verwendet, diese zu tokenisieren. Dafür werden die Daten mit Hilfe von Regulären Ausdrücken in einem Textverarbeitungsprogramm modifiziert.193 Dabei werden die sprachlichen Elemente nach Leerzeichen getrennt, aber auch Satzzeichen, Symbole, Zahlen, etc. werden als separate Token markiert und in einzelne Zeilen gespeichert. Damit später noch eine eindeutige Zuweisung der Token zu einem Beitrag erfolgen kann, wird jedem Token eines Beitrags die entsprechende Beitrags-ID zugeordnet.194 Schließlich wird jedem Token auch noch eine Token-ID hinzugefügt.
| Token_ID | Status_ID | Token |
| 1 | 130118_2 | certo |
| 2 | 130118_2 | ! |
| 3 | 130118_2 | „ |
| 4 | 130118_2 | smile |
| 5 | 130118_2 | “ |
| 6 | 130118_2 | – |
| 7 | 130118_2 | Emoticon |
| 8 | 130118_2 | wo |
| 9 | 130118_2 | treffen |
| 10 | 130118_2 | wir |
| 11 | 130118_2 | uns |
| 12 | 130118_2 | ? |
Wie in Tabelle 29 zu sehen, wird sowohl einzelnen durch Leerzeichen getrennten Token eine extra Spalte zugewiesen, wie auch Satzzeichen, Zahlen und Symbolen jeder Art. Es wird dabei ersichtlich, dass Emoticons, wie das „smile“-Emoticon, in fünf Token geteilt werden. Dies muss erst einmal so übernommen werden, um hieraus resultierende Schwierigkeiten auszuschließen. Allerdings darf diese Tatsache später beim Tagging sowie bei der Datenauswertung nicht außer Acht gelassen werden.
Schließlich werden aus den so bearbeiteten und tokenisierten Dateien Texdokumente (.txt) erstellt, damit sie in einem nächsten Schritt vom TreeTagger weiterverarbeitet werden können.
5.5.3.3. Sprachzuweisung und gleichzeitiges POS-Tagging mit dem TreeTagger
Neben dem TreeTagger gibt es auch noch die Möglichkeit, selbst auf der Grundlage eines Lexikons eine Parameterdatei zu erstellen, um damit Texte in Sprachen, in denen noch keine (oder fehlerhafte) Parameterdateien vorhanden ist, taggen zu können. Das Programm TrainTreeTagger (Schmid o.J.) kann mit Hilfe eines selbst erstellten und mit eigenen Tags versehenen Lexikons sowie eines manuell getaggten Trainingskorpus eine solche Parameterdatei erstellt werden. Diese Parameterdatei wird dabei nach derselben statistischen Methode wie die bereits existierenden Parameterdateien erstellt. Auf Grundlage dieser kann dann eine Annotation von Textdateien stattfinden.
Ziel für die hier verwendete Annotationsmethode ist die Erstellung einer solchen Parameterdatei, mit der gemischtsprachige Text getaggt werden können und die den Namen „Sprachzuweisung“ trägt. Grundlage bildet dafür ein Lexikon, das aus den Sprachtabellen aus Tabelle 26 besteht. Die einzelnen Lexikoneinträge sollen dabei sowohl die verschiedenen POS-Tags, als auch gleichzeitig Tags für die jeweiligen Sprachen, aus denen diese stammen, enthalten.
Dafür müssen im Vorfeld die Tags für das POS-Tagging festgelegt werden, denn jeder der bereits existierenden Parameterdateien zum Tagging von verschiedenen Sprachen liegt ein anderes Tagset zugrunde.195 Deshalb werden zunächst die Tags der verschiedenen Tagsets der einzelnen Sprachen vereinheitlicht. Die Tags und die Bezeichnung werden im Tagset Mix gespeichert: NOM steht hier beispielsweise für Nomen, VE für Verben und ADJ für Adjektiv (siehe Tabelle 30):
| POS-Tag | Wortart | Beispiele |
| ADJ | Adjektiv | gut, buono, wonderful |
| ADV | Adverb | jetzt, bene |
| CON | Konjunktion | und, e |
| DET | Determinierer | die, il, the, ein, una |
| FM | Fremdsprachliches | beijinhos, hasta |
| INT | Interjektion | na, juchuh, ciao, yeah, hmm |
| NE | Eigenname | Berlin, Anna, Italia, Facebook |
| NOM | Nomen | Abend, aereo, city |
| NUM | Numerale | fünf, secondo, 23 |
| PON | Satzinterne Zeichen und Symbole | ,, :, -, „“, Emoticon, &, @ |
| PRE | Präposition | nach, da, in, to |
| PREDET | Präposition mit Determinierer | am, della, nel |
| PRO | Pronomen | ich, mio, you |
| SENT | Satzfinale Interpunktion | ., !, ? |
| VE | Verb | gehst, è, studying, fatto |
Unterkategorisierungen, wie sie im Tagging der einzelnen Sprachen vorgenommen wurden, werden hier zum größten Teil aufgehoben: So werden beispielsweise mit ADJ alle Arten von Adjektiven bezeichnet, die im deutschen Tagging in attributive, adverbiale oder prädikative Adjektive untergliedert sind, und mit VE alle Verben (das Tagging für das Deutsche unterscheidet hier 12, das Italienische 13 verschiedene Verbformen).
Schließlich muss das Lexikon erstellt werden, das eine Kombination der drei Sprachlexika des Deutschen, Italienischen und Englischen darstellt, und Lexikon_mix genannt werden soll. Dafür wird jedes der drei Sprachlexika einzeln mit dem TreeTagger unter der Verwendung der Parameterdatei der jeweiligen Sprache getaggt. Anschließend wird der Output kontrolliert. Im Anschluss daran werden die zugewiesenen Tags durch die vereinheitlichten Tags aus dem Tagset Mix ersetzt. Zudem wird jedem Token je nach Sprache auch noch ein sprachspezifisches Kürzel hinzugefügt. Beispielsweise wird im getaggten italienischen Lexikon der POS-Tag mit dem Sprach-Tag kombiniert und so steht it_NOM etwa für ein italienisches Nomen. Für das Deutsche wird den POS-Tags das Kürzel de vorangestellt und für das Englische en. Die drei so bearbeiteten Lexika des Italienischen, Deutschen und Englischen werden in einem Lexikon (Lexikon_mix) zusammengeführt und gespeichert. Schließlich werden noch satzfinale Interpunktionen (SENT), wie Punkt, Ausrufezeichen und Fragezeichen, Symbole und satzinterne Zeichen (PON), wie Komma, Doppelpunkt, Anführungszeichen, Klammern, Asterisken sowie Zahlen (NUM) hinzugefügt. Diese bekommen allerdings keine sprachspezifischen Kürzel.
Der Nachteil des TreeTagger ist allerdings, dass einem Token nicht mehrere Tags hinzugefügt werden können und so auch im Lexikon die Token nicht mit mehreren Sprachtags versehen werden können (wie es zum Beispiel bei der Präposition in, die in allen drei Sprachen vorkommen kann, der Fall wäre). Deshalb müssen Dubletten anhand des Kriteriums der Frequenz entfernt werden: wenn das Token in also beispielsweise im Deutschen häufiger als im Italienischen verwendet wird, wird es nur als Deutsch getaggt.
Um den TrainTreeTagger schließlich auf der Basis des von Dubletten befreiten Lexikons (Lexikon_mix_ohnedubletten) verwenden zu können und so die Parameterdatei sprachen.par zu erstellen, muss dieser auf einem manuell getaggten Trainingkorpus trainiert werden. Dafür wird zunächst eine Auswahl an tokenisierten Korpusdaten von Hand mit den entsprechenden Tags (inklusive Sprachtags) versehen.196 Unter Sprachzuweisung kann die so erstellte Parameterdatei auf dem TreeTagger (siehe Abbildung 30) verwendet werden und den Token der Beiträge werden damit die Tags Sprache, Wortart (POS) und Lemma hinzugefügt.
TreeTagger mit Windows Interface und ausgewählter Parameterdatei „Sprachzuweisung“.
(Lizenz: CC BY SA)
5.5.3.4. Manuelle Kontrolle, Überarbeitung und Korrektur
Ein mit dem TreeTagger und der Parameterdatei der Sprachzuweisung generierter Output eines Facebook Beitrags wird im Anschluss manuell überprüft, damit er wie das Beispiel in Tabelle 31 aussieht.
| Token_ID | Status_ID | Token | Sprache | POS | Lemma |
| 1504 | 102179_359 | ciao | it | INT | ciao |
| 1505 | 102179_359 | albi | NE | personenname | |
| 1506 | 102179_359 | ! | SENT | ! | |
| 1507 | 102179_359 | ho | it | VE | avere |
| 1508 | 102179_359 | letto | it | VE | leggere |
| 1509 | 102179_359 | ke | it | CON | che |
| 1510 | 102179_359 | 6 | it | VE | essere |
| 1511 | 102179_359 | tornato | it | VE | tornare |
| 1512 | 102179_359 | in | it | PRE | in |
| 1513 | 102179_359 | Italy | en | NE | Geographischer Name |
| 1514 | 102179_359 | ! | SENT | ! | |
| 1515 | 102179_359 | km | it | CON | come |
| 1516 | 102179_359 | è | it | VE | essere |
| 1517 | 102179_359 | andata | it | ADJ | andato |
| 1518 | 102179_359 | a | it | PRE | a |
| 1519 | 102179_359 | berlin | de | NE | Geographischer Name |
| 1520 | 102179_359 | ? | SENT | ? |
Spezifische Schreibweisen der CMC, wie ke ‚che’ und 6 ‚sei‘, werden nicht erkannt und müssen manuell ergänzt werden. Auch bei Token, die in allen drei Sprachen vorkommen, gilt es zu entscheiden, welcher Sprachtag hier der Richtige ist (entscheidend ist dabei meist der Kontext). Schließlich werden die so annotierten Daten in der Datenbank facebook_cs gespeichert und in der Tabelle mix_token zusammengeführt. Die Datenbank facebook_cs umfasst schließlich folgende Tabellen:
Übersicht der Tabellen der Datenbank facebook_cs.
(Lizenz: CC BY SA)
Zusammenfassend lässt sich festhalten, dass die Korpusannotation nur durch eine kombinierte Methode zufriedenstellende Ergebnisse liefert. Dabei werden die für eine Sprachzuweisung vorgesehenen sprachspezifischen Lexika mit einem POS-Tagging Programm kombiniert. Der Aufwand, die Parameterdatei „Sprachzuweisung“ mit dem Traintreetagger zu erstellen, diese zu modifizieren, zu trainieren und auf ihre Funktionalität zu testen, ist relativ groß. Der Vorteil, dass mit dieser Methode die Sprachzuweisung und das POS-Tagging gleichzeitig vorgenommen werden kann, liegt jedoch klar auf der Hand. Mit Hilfe von MySQL Abfragen kann schließlich herausgefunden werden, wie viele Token es in den einzelnen Sprachen gibt, um welche Art des Sprachwechsels es sich handelt und welche Teile eines Satzes (und Wortarten) von solchen Wechseln betroffen sind. Diese Ergebnisse sollen im folgenden Kapitel ausführlich beschrieben werden.
6. Code-Switching in Facebook Beiträgen: Auswertungen
In diesem Kapitel soll die Auswertung der Daten des Facebook Korpus erfolgen. Um der Frage nachzugehen, wie und in aus welchen Gründen CS verwendet wird, wird zunächst ein Überblick über die Verwendung von Sprachen im kompletten Korpus gegeben. Im Anschluss daran folgt die Betrachtung der Sprachen in den gemischtsprachigen Beiträgen. Im zweiten Teil der Auswertung erfolgt eine Übersicht nach CS Typen. Von den einzelnen strukturellen Typen und CS Strategien ausgehend werden daraufhin die kommunikativen Funktionen präsentiert und analysiert. Den beiden Teilen dieses Kapitels schließt sich eine Übersicht der Ergebnisse sowie eine Diskussion dieser an.
6.1. Sprachverteilung und –verwendung im Facebook Korpus
Die Grundannahme der vorliegenden Arbeit ist, dass in Facebook Beiträgen verschiedene Sprachen verwendet werden. Dieser Plurilingualismus stellt eines der besonderen Merkmale der CMC dar (siehe Kapitel ). Unter der Prämisse, dass die Verwendung mehrerer Sprachen bestimmten Zwecken dient, soll hier gezeigt werden, dass die zweisprachigen Facebook Nutzer die Sprachen sowohl zwischen einsprachigen Beiträgen wechseln, als auch innerhalb eines einzigen Beitrags. Die Ersteren sind situationsbedingte Sprachwechsel, die Letzteren werden als CS im Sinne dieser Arbeit definiert. Dafür wird in den entsprechenden Unterkapiteln zunächst die Verteilung der Sprachen im gesamten Korpus bestimmt. Anschließend wird der Fokus auf die Verteilung der Sprachen in den gemischtsprachigen Beiträgen gelegt. Es folgt eine kurze Diskussion über die Rolle, die gemischtsprachige Beiträge innerhalb Facebooks und des Korpus spielen.
6.1.1. Verteilung der Sprachen in den Facebook Beiträgen
Die Facebook Beiträge wurden nach Sprachen annotiert (siehe Kapitel ). Eine Korpusabfrage, die die Sprachen auf Beitragsebene ermittelt, zeigt, dass mit 3.888 Facebook Beiträgen knapp die Hälfte aller Facebook Beiträge komplett auf Italienisch verfasst sind. Des Weiteren gibt es insgesamt 1.623 deutsche Beiträge (das entspricht 20% aller Beiträge) und 668 englische Beiträge (das entspricht 8% aller Beiträge). 168 Beiträge (2% aller Beiträge) wurden in anderen Sprachen (Kategorie andere), wie beispielsweise Spanisch, Portugiesisch, Französisch oder auch Polnisch, verfasst. Zu der Gruppe der 434 unbekannten Beiträge (5% aller Beiträge) gehören solche, die nur Emoticons, Personennamen oder Elemente enthalten, die keiner Sprache zugeordnet werden können. Beiträge, die mehr als eine Sprache enthalten und somit nach der Definition aus Kapitel als CS zu werten sind, fallen unter die Kategorie Mix. Diese zählt 1.369 Beiträge und stellt mit 17% aller Beiträge die drittgrößte Kategorie dar.
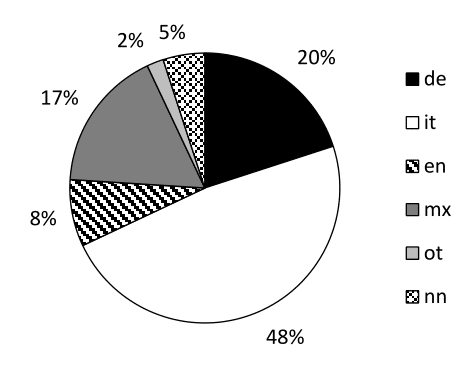
Verteilung der Sprachen auf Beitragsebene.
(Lizenz: CC BY SA)
An der Sprachverteilung in Abbildung 31 ist zu erkennen, dass es neben dem CS in gemischtsprachigen Beiträgen auch viele situationsbedingte Sprachwechsel gibt. Die Sprachwahl erfolgt dabei nach externen Faktoren. Dazu zählen der Rahmen des Beitrags, die beteiligten Facebook Nutzer, die Beziehung zwischen Nutzern und Adressaten sowie das Gesprächsthema (siehe Kapitel ). Deshalb soll im Folgenden überprüft werden, ob es einen Zusammenhang zwischen der verwendeten Sprache beziehungsweise der Sprachwechsel und den externen Faktoren gibt. Dafür wird die Sprachverteilung nach Art des Beitrags (Statusmeldung oder Post), Verfasser des Beitrags (Nutzer und Facebook Freunde) sowie Thema des Beitrags betrachtet.
6.1.1.1. Übersicht nach Art des Beitrags
Tabelle 32 zeigt die Verteilung der Sprachen in den Facebook Statusmeldungen und Posts:
| Statusmeldungen | Posts | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| de | 810 | 20 | 813 | 20 | 1.623 | 20 |
| it | 1.865 | 46 | 2.023 | 49 | 3.888 | 48 |
| en | 420 | 10 | 248 | 6 | 668 | 8 |
| mx | 667 | 16 | 702 | 17 | 1.369 | 17 |
| ot | 84 | 2 | 84 | 2 | 168 | 2 |
| nn | 199 | 5 | 235 | 6 | 434 | 5 |
| Gesamt | 4.045 | 100 | 4.105 | 100 | 8.150 | 100 |
Sowohl in Facebook Statusmeldungen als auch in Facebook Posts gibt es gemischtsprachige Beiträge. Die Verteilung der Sprachen in den Facebook Statusmeldungen ist dabei mit der in den Posts fast identisch. Die auf Italienisch verfassten Beiträge überwiegen mit 46% in den Statusmeldungen und mit 49% bei den Posts. 20% der Beiträge sind auf Deutsch verfasst – sowohl in den Statusmeldungen als auch den Posts. Die Beiträge auf Englisch machen 10% aller Statusmeldungen und 6% aller Posts aus, während die Beiträge in anderen Sprachen 2% erreichen. Auch der Anteil der gemischtsprachigen Beiträge ist mit 16% bei den Statusmeldungen und 17% bei den Posts ähnlich groß.
Das heißt, dass es keinen Zusammenhang zwischen der Art des Beitrags – Facebook Statusmeldung oder Post – und der oder den verwendeten Sprache/n gibt. Die zugrundeliegende Annahme, dass mehrere Sprachen verwendet werden und dass es gemischtsprachige Beiträge gibt, wird hiermit bestätigt.
6.1.1.2. Übersicht nach dem Verhältnis Token/Beitrag
Es könnte nun gemutmaßt werden, dass zwar die Anzahl der italienischen Beiträge größer ist, dass dies aber nicht auch für die Anzahl der italienischen Token, die in diesen Beiträgen enthalten sind, gelten muss.
| Beiträge | Token | Verhältnis | |||
| Anz. | % | Anz. | % | Token/Beitrag | |
| de | 1.623 | 20 | 23.687 | 22 | 14,59 |
| it | 3.888 | 48 | 48.554 | 45 | 12,49 |
| en | 668 | 8 | 7.304 | 7 | 10,93 |
| mix | 1.369 | 17 | 26.472 | 24 | 19,34 |
| ot | 168 | 2 | 2.112 | 2 | 12,57 |
| nn | 434 | 5 | 949 | 1 | 2,19 |
| Gesamt | 8.150 | 100 | 109.078 | 100 | 13,38 |
Wie schon in Kapitel gesehen, umfassen alle Facebook Statusmeldungen und Posts insgesamt 109.078 Token. Von all diesen Token werden 45% in italienischen und 22% in deutschen Beiträgen verwendet. Weitere 7% lassen sich englischen Beiträgen und 2% weiteren Sprachen zuordnen. Damit ist die Verteilung der Sprachen der Token ähnlich der der Beiträge.
Das berechnete Verhältnis Token pro Beitrag zeigt, dass die auf Deutsch verfassten Beiträge tendenziell um zwei Token länger sind als die Italienischen. Noch kürzer sind mit knapp elf Token die englischen Beiträge. Auch die Beitragslänge der Beiträge aus der Kategorie unbekannt ist mit nur 2,19 Token sehr kurz. Das ist aber nicht verwunderlich, da diese meist aus nur einem Emoticon (als ein Token gezählt) oder einem Namen bestehen. Außerdem ist hier erkennbar, dass gemischtsprachige Beiträge mit fast 20 Token pro Beitrag am längsten sind. Dies lässt den Schluss zu, dass diese Beiträge eine besondere Rolle spielen: Zum einen könnte die große Anzahl an Token in den gemischtsprachigen Beiträgen darauf hinweisen, dass es hier häufiger um komplexe Themen geht und dass diese gemischtsprachigen Beiträge wegen ihrer Länge auch hinsichtlich ihrer kommunikativen Funktionen wichtig sein könnten. Zum anderen passt die hohe Tokenanzahl in den gemischtsprachigen Beiträge auch zu der Hypothese, dass es mehr inter-sententiales als intra-sententiales CS gibt und dass Sprachwechsel, vor allem in Form von Wiederholungen, auftreten (siehe Kapitel ).
Es kann somit kein Zusammenhang zwischen der Verteilung der Sprachen hinsichtlich des Verhältnisses Token pro Beitrag festgestellt werden. Deutsche und italienische Beiträge unterscheiden sich nur geringfügig in ihrer Länge, während englische sehr kurz sind. Die gemischtsprachigen Beiträge sind am längsten, was auf eine hohe Anzahl an inter-sententialem CS schließen lässt.
6.1.1.3. Übersicht nach Nutzern
Um zu überprüfen, ob es einen Zusammenhang zwischen dem Verfasser eines Beitrags und der Sprachwahl gibt, werden im Folgenden die verwendeten Sprachen auf Beitragsebene nach Nutzern dargestellt. Dabei wird auch zwischen der Beitragsart differenziert, da bei den Statusmeldungen die Nutzer die Beiträge selbst verfassen, während es sich bei den Posts um von Facebook Freunden produzierte Beiträge handelt.
Facebook Statusmeldungen
Die Gesamtanzahl der Beiträge unterscheidet sich von Nutzer zu Nutzer (wie auch schon in Kapitel gesehen). Davon ausgehend wird erwartet, dass sich die Nutzer auch hinsichtlich ihrer Sprachverwendung voneinander unterscheiden. So zeigt Tabelle 34 auf der einen Seite, dass jeder der Facebook Nutzer, der in die Datenbank aufgenommen wurde, sowohl Beiträge auf Italienisch, als auch auf Deutsch veröffentlicht. Das zeigt, dass damit auch das Kriterium der hinreichenden Sprachverwendung (siehe Kapitel ) erfüllt ist und die Nutzer somit als (online) bilingual angesehen werden können.
| de | it | en | mx | ot | nn | Gesamt | ||||||||
| Anz. | % | Anz. | % | Anz. | % | Anz. | % | Anz. | % | Anz. | % | Anz. | % | |
| 1021 | 30 | 11 | 162 | 59 | 12 | 4 | 54 | 20 | 1 | 0 | 14 | 5 | 273 | 100 |
| 1112 | 75 | 20 | 112 | 30 | 89 | 24 | 84 | 23 | 3 | 1 | 5 | 1 | 368 | 100 |
| 1211 | 96 | 48 | 57 | 29 | 5 | 3 | 32 | 16 | 0 | 0 | 9 | 5 | 199 | 100 |
| 1301 | 57 | 34 | 45 | 27 | 9 | 5 | 24 | 14 | 20 | 12 | 12 | 7 | 167 | 100 |
| 1411 | 22 | 39 | 7 | 12 | 13 | 23 | 11 | 19 | 2 | 4 | 2 | 4 | 57 | 100 |
| 1501 | 5 | 33 | 5 | 33 | 1 | 7 | 3 | 20 | 0 | 0 | 1 | 7 | 15 | 100 |
| 1621 | 56 | 6 | 575 | 64 | 88 | 10 | 115 | 13 | 13 | 1 | 56 | 6 | 903 | 100 |
| 1701 | 4 | 5 | 24 | 33 | 14 | 19 | 11 | 15 | 0 | 0 | 20 | 27 | 73 | 100 |
| 1824 | 33 | 9 | 204 | 58 | 24 | 7 | 51 | 15 | 5 | 1 | 33 | 9 | 350 | 100 |
| 1921 | 56 | 7 | 461 | 57 | 76 | 9 | 161 | 20 | 35 | 4 | 19 | 2 | 808 | 100 |
| 2001 | 37 | 44 | 23 | 27 | 6 | 7 | 9 | 11 | 1 | 1 | 9 | 11 | 85 | 100 |
| 2101 | 20 | 37 | 19 | 35 | 4 | 7 | 5 | 9 | 0 | 0 | 6 | 11 | 54 | 100 |
| 2211 | 205 | 39 | 147 | 28 | 78 | 15 | 83 | 16 | 3 | 1 | 10 | 2 | 526 | 100 |
| 2310 | 114 | 68 | 24 | 14 | 1 | 1 | 24 | 14 | 1 | 1 | 3 | 2 | 167 | 100 |
| Gesamt | 810 | 20 | 1.865 | 46 | 420 | 10 | 667 | 16 | 84 | 2 | 199 | 5 | 4.045 | 100 |
Auf der anderen Seite gibt es allerdings auch deutliche Unterschiede was die Präferenz einer der beiden Sprachen anbelangt. Es lassen sich zwei Gruppen an Nutzern feststellen: Bei den Nutzern der einen Gruppe gibt es mehr Statusmeldungen auf Italienisch als auf Deutsch (diese sind in Tabelle 34 durch Fettschrift markiert) und bei der anderen mehr Statusmeldungen auf Deutsch als auf Italienisch (durch Kursivschrift markiert). So überwiegen bei sechs Nutzern, die zur ersten Gruppe gezählt werden können, die italienischsprachigen Statusmeldungen, wobei die Nutzer 1621, 1021, 1824 und 1921 mit 64%, 59%, 58% und 57% italienischsprachiger Facebook Statusmeldungen besonders hervortreten. Sieben Nutzer, die zur zweiten Gruppe gezählt werden können, veröffentlichen mehr deutsche als italienische Statusmeldungen. Vor allem Nutzer 2310 sticht mit 68% deutschsprachiger Beiträge heraus. Bei Nutzer 1501 ist die Anzahl der geposteten deutsch- und italienischsprachigen Statusmeldungen mit 33% exakt gleich hoch – wenn auch die Gesamtanzahl der Beiträge mit je nur fünf veröffentlichten Statusmeldungen relativ klein ist.
Auffällig ist außerdem der hohe prozentuale Anteil englischsprachiger Statusmeldungen bei den Nutzern 1112 und 1411 mit 24% und 23% sowie die Anzahl anderssprachiger Beiträge des Nutzes 1301 (die meisten davon sind auf Spanisch verfasst). Die letzte Auffälligkeit ist die große Anzahl an nicht zuordnenbaren Beiträgen bei Nutzer 1701. Wie schon in Kapitel gesehen, verwendet dieser Nutzer überwiegend nicht-textbasierte Beiträge in Form von Bildern und Verlinkungen. Diese Präferenz setzt sich auch in den textbasierten Statusmeldungen fort, die vor allem Emoticons und verlinkte Namen enthalten.
Schließlich lässt sich feststellen, dass es bei jedem Nutzer gemischtsprachige Statusmeldungen gibt. Ihr Anteil bewegt sich dabei zwischen 9% bei Nutzer 2101 und 23% bei Nutzer 1112. Der Vergleich mit den Angaben der Nutzer zu aktuellem Wohnort und Heimatort zeigt, dass die Nutzer, deren Heimatort sich laut Angaben in Italien befindet, tatsächlich zu der Gruppe der Nutzer gehören, die mehr Statusmeldungen auf Italienisch verfassen als auf Deutsch (dazu zählen die Nutzer 1021,1621,1824 und 1921, siehe Anlage 1 und Kapitel ). Andersherum lässt sich das zwar für die Mehrheit der Nutzer, deren Heimatort in Deutschland angegeben wurde, bestätigen (wie bei den Nutzern 1211, 1411, 2211 und 2310), aber nicht für alle (beispielsweise bei Nutzer 1112). Eine Korrelation der Sprachpräferenz und des aktuellen Wohnortes kann des Weiteren ausgeschlossen werden, da nur bei den Nutzern, die beim Heimatland auch schon Deutschland nannten die Statusmeldungen auf Deutsch überwiegen. Das lässt den Schluss zu, dass sich die Sprachwahl eher nach den Facebook Freunden und deren Sprachkenntnissen und ihrer Sprachverwendung richtet, als nach dem Herkunftsland oder aktuellen Wohnort.
Facebook Posts
Auch in den Facebook Posts werden verschiedene Sprachen sowie gemischtsprachige Beiträge produziert.
| de | it | en | mx | ot | nn | Gesamt | ||||||||||
| Anz. | % | Anz. | % | Anz. | % | Anz. | % | Anz. | % | Anz. | % | Anz. | % | |||
| 1021 | 28 | 10 | 175 | 60 | 20 | 7 | 67 | 23 | 2 | 1 | 2 | 1 | 294 | 100 | ||
| 1112 | 48 | 27 | 85 | 47 | 7 | 4 | 30 | 17 | 1 | 1 | 10 | 6 | 181 | 100 | ||
| 1211 | 25 | 23 | 67 | 63 | 1 | 1 | 7 | 7 | 0 | 0 | 7 | 7 | 107 | 100 | ||
| 1301 | 105 | 36 | 86 | 30 | 6 | 2 | 72 | 25 | 12 | 4 | 10 | 3 | 291 | 100 | ||
| 1411 | 5 | 45 | 0 | 0 | 2 | 18 | 1 | 9 | 3 | 27 | 0 | 0 | 11 | 100 | ||
| 1501 | 17 | 43 | 13 | 33 | 2 | 5 | 6 | 15 | 0 | 0 | 2 | 5 | 40 | 100 | ||
| 1621 | 54 | 6 | 588 | 64 | 49 | 5 | 167 | 18 | 4 | 0 | 59 | 6 | 921 | 100 | ||
| 1701 | 9 | 7 | 77 | 62 | 26 | 21 | 9 | 7 | 2 | 2 | 2 | 2 | 125 | 100 | ||
| 1824 | 5 | 3 | 136 | 81 | 4 | 2 | 16 | 10 | 0 | 0 | 7 | 4 | 168 | 100 | ||
| 1921 | 32 | 3 | 602 | 66 | 31 | 3 | 145 | 16 | 44 | 5 | 63 | 7 | 917 | 100 | ||
| 2001 | 20 | 40 | 16 | 32 | 1 | 2 | 3 | 6 | 0 | 0 | 10 | 20 | 50 | 100 | ||
| 2101 | 102 | 37 | 61 | 22 | 27 | 10 | 49 | 18 | 5 | 2 | 31 | 11 | 275 | 100 | ||
| 2211 | 205 | 44 | 94 | 20 | 67 | 14 | 67 | 14 | 11 | 2 | 23 | 5 | 467 | 100 | ||
| 2310 | 158 | 61 | 23 | 9 | 5 | 2 | 63 | 24 | 0 | 0 | 9 | 3 | 258 | 100 | ||
| Gesamt | 813 | 20 | 2.023 | 49 | 248 | 6 | 702 | 17 | 84 | 2 | 235 | 6 | 4.105 | 100 | ||
Tabelle 35 zeigt, dass die meisten Facebook Freunde ihre Posts auf Italienisch verfassen. Vor allem bei den Freunden von Nutzer 1824 überwiegen mit 81% die italienischen Posts. Dafür werden bei Nutzer 1411 gar keine Posts auf Italienisch verfasst; die Summe aller Posts auf der Chronik dieses Nutzers ist mit 11 Beiträgen jedoch insgesamt sehr gering. Bei der Gesamzanzahl der Posts ist der Anteil an Beiträgen auf Englisch nicht so hoch. Der Anteil der gemischtsprachigen Beiträge ist hier hingegen größer.
Es lässt sich feststellen, dass in den meisten Fällen die Sprachverwendung in den Posts der Facebook Freunde ähnlich ist wie die in den Statusmeldungen. Auch hier lassen sich wieder zwei Gruppen identifizieren: nämlich die Gruppe derjenigen Facebook Freunde, die mehr Posts auf Italienisch verfassen (die Freunde der Nutzer 1021, 1112, 1621, 1701, 1824 und 1921, in Tabelle 35 durch Fettschrift markiert) und die Gruppe derer, die mehr Beiträge auf Deutsch verfassen (die Freunde der Nutzer 1301, 1411, 1501, 2001, 2101, 2211, 2310, durch Kursivschrift markiert). Einzige Ausnahme bildet die Sprachverwendung der Facebook Freunde des Nutzers 1211: die Freunde verfassen mehr Posts auf Italienisch als auf Deutsch, während bei den Statusmeldungen Deutsch überwiegt. Auffällig ist zudem noch der große prozentuale Anteil an englischen Beiträgen bei den Nutzern 1411 und 1701 sowie die Anzahl der Posts in einer anderen Sprache bei Nutzer 1411 (hier Portugiesisch).198
Es sei hier noch anzumerken, dass die Facebook Freunde nicht unbedingt bilingual sein müssen. Und auch wenn keine autobiographischen Daten zu diesen Nutzern vorliegen, kann aufgrund der Anzahl an gemischtsprachigen Beiträgen davon ausgegangen werden, dass viele online bilingual sind. Interessant ist auch, dass sich die Sprachverteilung nach Nutzern in Statusmeldungen und Posts durchaus ähnelt, wie in Abbildung 32 und Abbildung 33 grafisch dargestellt:
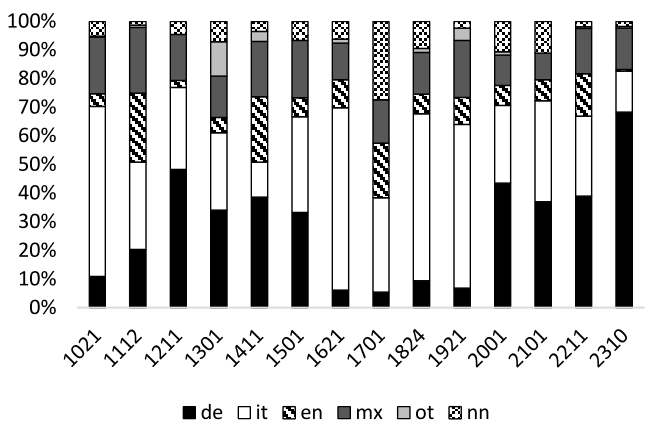
Sprachverteilung in textbasierten Statusmeldungen nach Facebook Nutzern (in Prozent).
(Lizenz: CC BY SA)
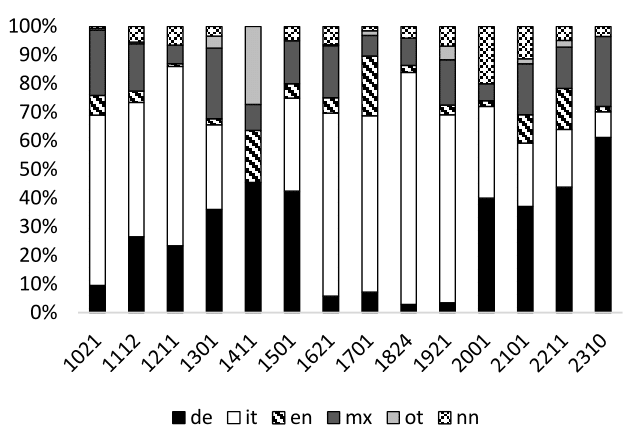
Sprachverteilung in textbasierten Posts nach Facebook Nutzern (in Prozent).
(Lizenz: CC BY SA)
Die Sprachverteilung nach Nutzern zeigt, dass es einen Zusammenhang zwischen Sprachverwendung auf Beitragsebene und Nutzern gibt. So lassen sich sowohl bei den Nutzern als auch bei den Facebook Freunden zwei Gruppen ausmachen. Der Vergleich der Verteilung nach Statusmeldungen und Posts kann die Annahme bestätigen, dass sich die Sprachverwendung eines Facebook Nutzers an der seiner Facebook Freunde orientiert. Ein Zusammenhang mit dem aktuellen Wohnort oder der Heimat ist nicht gegeben, auch wenn eine Verbindung zwischen diesen Orten und den Freunden bestehen kann.199
6.1.1.4. Übersicht nach Thema
Das Gesprächsthema kann ebenfalls ein Indiz für die verwendete Sprache sein. Gerade die Thematisierung eines Aufenthalts in einem anderen Land oder eine Reise dahin können den Nutzer veranlassen eine Statusmeldung in der Landessprache des Zielortes zu schreiben. So zeigen auch die Beispiele (76) und (77), dass ein geplanter Aufenthalt die Sprachwahl beeinflussen kann. In Ersterem wird die Reise nach Paris auf Französisch angekündigt, während in Letzterem der Aufenthalt in Chile auf Spanisch thematisiert wird.
[FB 1112_638]
Bonjour Paris j’arrive!„heart“-Emoticon
[FB 1301_454]
Faltan cinco semanas y tres días para Chile!!!
Es gibt aber auch einige Gegenbeispiele, die zeigen, dass eine Reise oder ein Aufenthalt in einem bestimmten Land nicht dazu führen müssen, die Landessprache zu verwenden:
[FB 1112_350]
Waiting for my train…to liguria! „smile“-Emoticon200
[FB 1824_1525]
With love from Firenze !!!
Die Nutzer, die die Statusmeldungen in (78) und (79) verfasst haben, erwähnen beide einen Aufenthalt beziehungsweise eine Reise nach Italien. Dafür verwenden sie allerdings nicht Italienisch, sondern Englisch. Das zeigt, dass es kaum möglich ist, allgemeingültige Schlüsse aus den Sprachwechseln zu ziehen. Auch die folgenden Beispiele (80) und (81) sind gute Belege dafür:
[FB 1211_252]
L‘ unico dei tuoi figli che non crescerá mai…..é tuo marito! „smile“-Emoticon
[FB 1211_253]
Eine Mutter muss lachen,auch wenn sie traurig ist.Sie muss trösten,auch wenn sie selbst Trost bräuchte….
Beide Statusmeldungen wurden am selben Tag und vom selben Nutzer gepostet. Daraus kann abgeleitet werden, dass sich dieser Nutzer beim Posten auch am selben Ort beziehungsweise im selben Land befand. Beide Beiträge betreffen das Familienleben, das heißt, es kann davon ausgegangen werden, dass der Nutzer in beiden Fällen emotional involviert ist. Aber auch wenn die erste Statusmeldung humoristischer Natur ist und die letzte eher eine negative Stimmung widerspiegelt, führt das nicht zu Vorhersagen zur weiteren Sprachverwendung des Nutzers. Es könnte sich bei diesen Beispielen außerdem um Zitate handeln. Wenn das aber der Fall wäre, ist das kaum überprüfbar und ebenfalls kein Kriterium für eine allgemeingültige Aussage zur Sprachenverwendung und –verteilung in den Beiträgen eines Nutzers.
Auch weitere Überlegungen zu möglichen Themen, die die Wahl der Sprache beeinflussen könnten, konnten immer gleich durch Gegenbeispiele entkräftet werden:
[FB 1621211_2457]
Forza azzurri!! „wink“-Emoticon
[FB 200143_148]
Forza BVb!!!!!!!
Eine weitere Vermutung wäre, dass Facebook Beiträge mit einem Bezug zu einem bestimmten Ereignis im Bereich des Sports in der Sprache der jeweiligen Sportmannschaft verfasst werden. Dies ist in (82) der Fall, da hier die italienische Nationalmannschaft entsprechend auf Italienisch angefeuert wird. (83) bietet ein Gegenbeispiel, weil hier eine deutsche Mannschaft Gegenstand der Äußerung ist.
Ein weiteres Thema, von dem vermutet werden kann, die Sprachwahl zu beeinflussen, wäre das Thema Essen und typische Nahrungsmittel. Demnach müsste die Erwähnung von italienischen Spezialitäten zur Verwendung des Italienischen führen, wie in (84). (85) jedoch zeigt, dass sich auch hier Gegenbeispiele finden lassen.
[FB 1021_168]
fa la pizza..
[FB 1021105_497]
Ich vermisse deine Pasta al Pesto.. „tongue“-Emoticon
Ein Zusammenhang zwischen Thema und verwendeter Sprache auf Beitragsebene kann somit nicht festgestellt werden.
6.1.2. Verteilung der Sprachen in den gemischtsprachigen Beiträgen
Es konnte im vorangehenden Unterkapitel gezeigt werden, dass es insgesamt 1.369 Beiträge gibt, in denen mehrere Sprachen verwendet werden. Nach der Definition, die dieser Arbeit zugrunde liegt, handelt es sich hierbei um Code-Switching (siehe Kapitel ). Bevor nun die einzelnen Switches nach strukturellen und sozio-pragmatischen Gesichtspunkten untersucht werden, soll zunächst die Sprachverteilung innerhalb dieser Beiträge betrachtet werden.
6.1.2.1. Übersicht nach Art des Beitrags
Nach der Tokenisierung und der Annotation nach Sprachen und Wortarten mit Hilfe des Programms der Sprachzuweisung, das über den TreeTagger verwendet wurde (siehe Kapitel ), kann die Anzahl der Token und deren Sprachen in den gemischtsprachigen Beiträgen bestimmt werden. Dabei wird auch jedes Symbol und Interpunktionszeichen (am Ende eines Satzes (SENT) oder in der Mitte eine Satzes (PON)) als ein Token gewertet, dem allerdings keine Sprache zugewiesen wird. Das ergibt insgesamt 41.639 Token, von denen 40% Symbole oder Interpunktionszeichen darstellen:
| Statusmeldungen | Posts | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| Sprachtoken | 8.370 | 57 | 16.457 | 61 | 24.827 | 60 |
| SENT/PON | 6.286 | 43 | 10.526 | 39 | 16.812 | 40 |
| Gesamt | 14.656 | 100 | 26.983 | 100 | 41.639 | 100 |
Nach Beitragsart sortiert wird deutlich, dass die Gesamtanzahl an Token in den Posts viel höher ist. Die prozentuale Verteilung der Sprachtoken innerhalb der Statusmeldungen ist mit 57% geringer als die der Sprachtoken in den Posts, die dort 61% aller Token ausmacht.
Die Anzahl der Beiträge ist in beiden Kategorien ähnlich groß: 667 gemischtsprachige Statusmeldungen und 702 Posts (siehe Kapitel ). Das bedeutet, dass die Posts mit 38,44 Token pro Beitrag länger sind als die Statusmeldungen mit 21,97 Token pro Beitrag. Eine durchschnittliche gemischtsprachige Statusmeldung umfasst somit 12,55 Sprachtoken und 9,42 Interpunktionszeichen, während der durchschnittliche gemischtsprachige Post 23,44 Sprachtoken und 14,99 Interpunktionszeichen enthält. Die hohe Anzahl an Interpunktionszeichen pro Beitrag lässt sich mit der Verwendung von Emoticons und der Iteration von Zeichen, die zu den besonderen Merkmalen der CMC gezählt werden können, erklären.
Die Verteilung der Sprachen innerhalb der Gruppe der Sprachtoken ist Folgende:
| Statusmeldungen | Posts | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| de | 2.199 | 26 | 7.111 | 43 | 9.310 | 37 |
| it | 4.493 | 54 | 7.880 | 48 | 12.373 | 50 |
| en | 1.390 | 17 | 868 | 5 | 2.258 | 9 |
| ot | 288 | 3 | 598 | 4 | 886 | 4 |
| Gesamt | 8.370 | 100 | 16.457 | 100 | 24.827 | 100 |
Dabei fällt auf, dass die Facebook Beiträge insgesamt zur Hälfte aus italienischen Token bestehen, gefolgt von deutschen Token, die einen Anteil von 37% innerhalb aller Sprachtoken erreichen.201 Einige Token stammen auch aus dem Englischen und anderen Sprachen (darunter vor allem Spanisch, aber auch Französisch und andere), die insgesamt einen Anteil von 9% und 4% ausmachen.
Nach Beitragsart betrachtet zeigt sich, dass innerhalb der gemischtsprachigen Statusmeldungen der Prozentsatz der italienischen Token mit 54 % am größten ist, gefolgt von 26% deutschen und 17% englischen Token. Bei den gemischtsprachigen Posts überwiegt ebenfalls der Anteil der italienischen Token, die 48% ausmachen. Der Anteil der deutschen Sprachtoken ist hier mit 43% deutlich höher, dafür erreichen die englischen Sprachtoken nur 5%.
Ein Vergleich mit der Sprachverteilung auf Beitragsebene (siehe Tabelle 32) zeigt, dass sich die Verteilung der Sprachen auf Beitragsebene ähnlich verhält, wie die innerhalb gemischtsprachiger Beiträge. Während 48% aller Beiträge auf Italienisch verfasst sind, ist auch der Anteil der italienischen Token innerhalb der gemischtsprachigen Beiträge mit 50% ähnlich groß. Der Anteil der deutschen Beiträge macht 20% aus, während deutsche Token 37% der Sprachtoken gemischtsprachiger Beiträge erreichen.
Die hohe Anzahl an italienischen und deutschen Token, sowohl in den Statusmeldungen als auch in den Posts, lässt die Schlussfolgerung zu, dass CS vor allem zwischen Deutsch und Italienisch stattfindet. Aber auch das Englische spielt eine wichtige Rolle, vor allem in den Facebook Statusmeldungen. Es konnte zudem gezeigt werden, dass es einen Zusammenhang zwischen Beitragsart und Sprache der Token gibt.
6.1.2.2. Übersicht nach Nutzern
Auf der Grundlage der Sprachverwendung in der Gesamtanzahl der Statusmeldungen und Posts der Nutzer kann davon ausgegangen werden, dass die Nutzer die Sprache, die sie dort präferiert verwenden auch in den gemischtsprachigen Beiträgen häufiger verwenden (siehe Abbildung 35 und Abbildung 36).
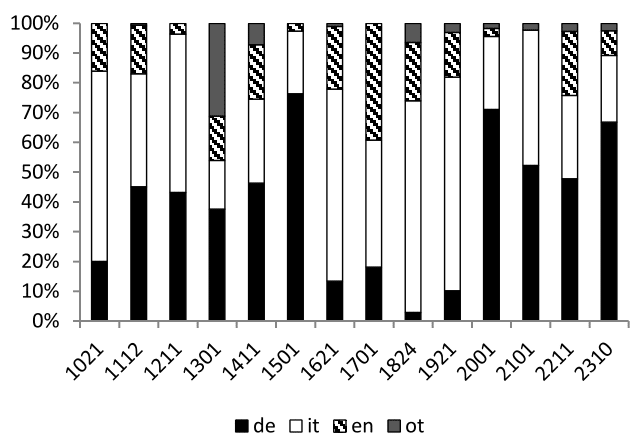
Sprachverteilung der Token in gemischtsprachigen Statusmeldungen nach Facebook Nutzern (in Prozent).
(Lizenz: CC BY SA)
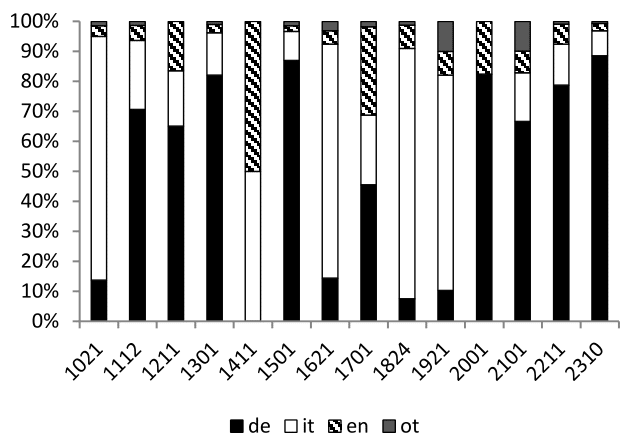
Sprachverteilung der Token in gemischtsprachigen Posts nach Facebook Nutzern (in Prozent).
(Lizenz: CC BY SA)
Tatsächlich kann bei der Sprachverteilung der Token in den Statusmeldungen (siehe Abbildung 35) festgestellt werden, dass hier dieselben Nutzer, die in der Gesamtanzahl ihrer Statusmeldungen das Italienische bevorzugen, dies auch in den gemischtsprachigen Beiträgen tun. Das gilt auch für die Gruppe der Nutzer, die das Deutsche bevorzugt verwendet. Die einzigen Ausnahmen stellen die Nutzer 1112 und 1211 dar, bei denen die in den Token bevorzugte Sprache von der für die Statusmeldungen Bevorzugten abweicht. Bei den Posts gibt es hingegen nicht nur bei den beiden eben genannten Nutzern, sondern zudem auch noch bei Nutzer 1411 und 1701 leichte Abweichungen bei der Sprachverteilung. Es kann somit also auch innerhalb der gemischtsprachigen Beiträge ein Zusammenhang zwischen Nutzer beziehungsweise Freunden des Nutzers und der Sprachverteilung festgestellt werden.
6.1.2.3. Übersicht der Sprachkombinationen
Schließlich kann gezeigt werden, welche Sprachkombinationen in den gemischtsprachigen Beiträgen verwendet werden. Dafür wird mit Hilfe einer Datenbankabfrage im Facebook Korpus festgestellt, welche Sprachen in den einzelnen Beiträgen verwendet werden. Tabelle 38 zeigt die verwendeten Kombinationen. Dabei können sowohl zwei also auch drei oder sogar mehrere verschiedene Sprachen in einem einzigen Beitrag enthalten sein.202
| Statusmeldungen | Posts | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| de-en | 72 | 10,79 | 63 | 8,97 | 135 | 9,86 |
| de-it | 269 | 40,33 | 308 | 43,87 | 576 | 42,15 |
| de-ot | 11 | 1,65 | 29 | 4,13 | 40 | 2,92 |
| en-it | 179 | 26,84 | 117 | 16,67 | 296 | 21,62 |
| en-ot | 9 | 1,35 | 2 | 0,28 | 11 | 0,80 |
| it-ot | 19 | 2,85 | 41 | 5,84 | 60 | 4,38 |
| de-en-it | 52 | 7,80 | 69 | 9,83 | 121 | 8,84 |
| de-en-ot | 5 | 0,75 | 9 | 1,28 | 14 | 1,02 |
| de-it-ot | 4 | 0,60 | 21 | 2,99 | 25 | 1,83 |
| en-it-ot | 9 | 1,35 | 16 | 2,28 | 25 | 1,83 |
| de-en-it-ot | 19 | 2,85 | 10 | 1,42 | 29 | 2,12 |
| nn | 19 | 2,85 | 17 | 2,42 | 37 | 2,63 |
| Gesamt | 667 | 100,00 | 702 | 100,00 | 1369 | 100,00 |
Wie auf Grund der Sprachverteilung in den gemischtsprachigen Beiträgen zu erwarten war, spielen vor allem das Deutsche und Italienische eine wichtige Rolle bei den verwendeten Sprachkombinationen. Deutlich zu sehen ist, dass die Sprachkombination Deutsch-Italienisch mit insgesamt über 40% die mit Abstand am häufigsten Verwendete ist, sowohl in den Statusmeldungen als auch in den Posts. Aber auch die Kombination Italienisch-Englisch wird häufig verwendet (insgesamt in über 21% der Beiträge), während Deutsch-Englisch zwar mit rund 10% noch frequenter wie andere Kombinationen ist, aber doch deutlich seltener verwendet wird. Schließlich werden in fast 9% aller Beiträge sowohl die Italienische, als auch die deutsche und englische Sprache verwendet. Andere Kombinationen kommen zwar auch vor, sind aber deutlich seltener.
Auch hier zeigt sich in einem Vergleich, dass das Englische in den Statusmeldungen eine viel größere Rolle spielt als in den Posts. So ist die Kombination Englisch und Italienisch viel häufiger in Statusmeldungen zu finden als in Posts (bei der Kombination Deutsch und Englisch ist der Unterschied nicht ganz so groß).
Dass vor allem Deutsch und Italienisch verwendet werden, liegt vor allem in der Auswahl der Nutzer (siehe Kapitel ) und bestätigt deren Status als online Bilinguale, die zum einen angeben, mehrere Sprachen zu sprechen und diese Sprachen dann auch in hinreichender Form verwenden. Interessant ist dabei auch die große Rolle, die das Englische in den Facebook Beiträgen zu spielen scheint und dass tatsächlich häufig mehr als zwei Sprachen in einem Beitrag vorkommen.
6.1.3. Die Rolle der gemischtsprachigen Beiträge auf Facebook
Es hat sich gezeigt, dass die Verwendung mehrerer Sprachen in Facebook Beiträgen bei bilingualen Nutzern durchaus üblich ist. Im Folgenden soll gezeigt werden, welche Rolle gemischtsprachige Beiträge auf Facebook einnehmen. Dabei soll zunächst eine Übersicht über die Entwicklung auf der Zeitachse gegeben werden, bevor gezeigt werden soll, in welcher Art von Beiträgen CS überhaupt vorkommt. Schließlich kann die Anzahl der Likes einen Hinweis darauf geben, welche Reaktionen gemischtsprachige Beiträge bei den Facebook Freunden auslösen und wie sie diese bewerten.
6.1.3.1. CS im zeitlichen Verlauf
Bisher wurde CS vor dem Hintergrund diskutiert, dass es ein wichtiges Merkmal der CMC darstellt. Allerdings zeigt sich bei der Betrachtung auf der Zeitachse, dass es zwischen 2009 und 2013 schon einen deutlichen Rückgang der Anzahl der geswitchten Beiträge gibt.
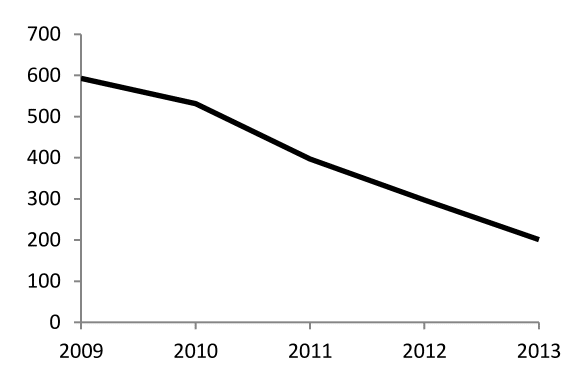
Anzahl der gemischtsprachigen Facebook Beiträgen zwischen 2009 und 2013.
(Lizenz: CC BY SA)
Während 2009 insgesamt 593 gemischtsprachig Beiträge veröffentlich wurden, waren es 2013 nur noch 201. Dieser rückläufige Trend in den Facebook Beiträgen könnte mit der abnehmenden Anzahl an textbasierten Beiträgen im gesamten Korpus erklärt werden (siehe Kapitel ). Jedoch zeigt sich, dass auch das Verhältnis der gemischtsprachigen Beiträge zu allen textbasierten Beiträgen abnimmt:
| 2009 | 2010 | 2011 | 2012 | 2013 | |
| Anz. CS | 593 | 531 | 397 | 297 | 201 |
| Anz. textbasierte Beiträge gesamt | 2.602 | 2.541 | 2.408 | 2.309 | 2.214 |
| Verhältnis gemischtsprachige Beiträge pro 100 textbasierte Beiträge | 22,79 | 20,90 | 16,49 | 12,86 | 9,08 |
Es lässt sich ein deutlicher Rückgang von CS innerhalb der textbasierten Beiträge erkennen, denn während 2009 noch auf 100 textbasierte Beiträge 22,79 gemischtsprachige kamen, waren es 2013 nur noch 9,08. Das lässt sich mit der Tendenz der Nutzer erklären, immer mehr para- und nichtsprachliche Merkmale beim Kommunizieren zu verwenden, wie schon die Übersicht nach Beitragstyp in Kapitel gezeigt hat.
6.1.3.2. CS in Kombination mit nichtsprachlichen Elementen
Wie in Kapitel gezeigt, können Facebook Beiträge verschiedener Art sein: textbasiert, nicht textbasiert oder eine Kombination daraus.
Tabelle 40 zeigt, dass die gemischtsprachigen Beiträge seltener in Kombination mit nichtsprachlichen Elementen, wie Bildern, Links oder Videos, auftauchen als der Rest der textbasierten (einsprachigen) Beiträge.
| Gemischtsprachige Beiträge | Rest textbasierte Beiträge | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| TXT | 1.178 | 86,05 | 5.007 | 73,84 | 6.185 | 75,89 |
| TXTPIC | 101 | 7,38 | 943 | 13,91 | 1044 | 12,81 |
| TXTLINK | 85 | 6,21 | 797 | 11,75 | 882 | 10,82 |
| TXTVID | 5 | 0,37 | 34 | 0,50 | 39 | 0,48 |
| Gesamt | 1.369 | 100,00 | 6.781 | 100,00 | 8.150 | 100,00 |
So sind 86% der gemischtsprachigen Beiträge rein sprachlich gestaltet und in den restlichen 14% der texbasierten Beiträge begleiten Bilder, Links oder Videos den Text. Der Anteil der rein sprachlichen Beiträge im Rest des Korpus ist mit 73,84 % deutlich geringer. Vor allem der Anteil der textbasierten Beiträge, die in Kombination mit einem Bild auftauchen, ist deutlich größer. Das bedeutet, dass die Sprachwechsel selbst eine wichtige Rolle in der Kommunikation einnehmen.
6.1.3.3. CS und Likes
Auch die Likes könnten einen Hinweis darauf geben, ob sich eine Tendenz erkennen lässt, gemischtsprachige Beiträge seltener zu verwenden (siehe Kapitel ). So kann die Anzahl der Likes einen Aufschluss darüber geben, wie CS in diesen Beiträgen bewertet wird:
| Anz. Likes | Gesamtanz. Beiträge | Anz. Likes/ Gesamtanz. Beiträge | Anz. gelikte Beiträge | Anz, Likes/ Anz. gelikte Beiträge | |
| Gemischtsprachige Beiträge | 3.261 | 1.369 | 2,38 | 631 | 5,17 |
| Rest textbasierte Beiträge | 14.671 | 6.781 | 2,16 | 3.267 | 4,50 |
| Gesamt | 17.932 | 8.150 | 2,20 | 3.898 | 4,6 |
Im Facebook Korpus lässt sich feststellen, dass 3.261 Likes für 1.369 gemischtsprachige Beiträge vergeben wurden. Das bedeutet, dass im Durschnitt 2,38 mal pro gemischtsprachigem Beitrag der “gefällt-mir“-Button betätigt wurde. Allerdings lassen sich bei manchen Beiträgen gar keine Bewertungen der Facebook Freunde in Form von Likes erkennen. Insgesamt wird jedoch nur knapp die Hälfte der gemischtsprachigen Beiträge, nämlich 631 von 1.369 überhaupt geliket. Demzufolge kommen dann auf jeden dieser gelikten Beiträge 5,17 „gefällt-mir“- Angaben. In allen anderen textbasierten Beiträgen lässt sich feststellen, es hier 14.671 Likes auf 6.781 Beiträge kommen. Das entspricht durchschnittlich 2,16 Likes pro Beitrag und zeigt, dass gemischtsprachige Beiträge im Durchschnitt mehr Likes erhalten. Die Anzahl der gelikten Beiträge stellt mit 3.267 ebenfalls rund die Hälfte aller Beiträge dar, auf die damit 4,5 Likes pro Beitrag kommen.
Beiträge mit CS erwecken also Aufmerksamkeit und rufen häufiger die Reaktionen von Freunden hervor. Die positiven Bewertungen zeigen, dass nicht nur der Inhalt der Beiträge, sondern auch der Sprachwechsel von den Facebook Freunden akzeptiert und sogar gut geheißen werden.
Zusammenfassend heißt das, dass auch wenn im zeitlichen Verlauf ein Rückgang bei den gemsichtsprachigen Beiträgen erkennbar ist, spielen diese trotzdem eine wichtige Rolle. Sie werden viel seltener durch parasprachliche Kommunikationsmittel wie Bildern begleitet, was bedeutet, dass sie selbst eine darstellende Funktion übernehmen. Es konnte auch festgestellt werden, dass gemischtsprachige Beiträge durchaus gut bei den Facebook Freunde ankommen und die Aufmerksamkeit erregen. Für die Abnahme im zeitlichen Verlauf müssen deshalb andere Gründen angenommen werden. Beispielweise kann das damit zusammenhängen, dass generell immer weniger Beiträge verfasst werden und auch deren Länge abnimmt.203 Das kann aber auch bedeuten, dass sich die Kommunikationsfunktionen weiter entwickeln und wandeln und anderen Plattformen beziehungsweise anderen Kommunikationsmitteln auf Facebook (beispielsweise den Nachrichten oder dem Chat) der Vorzug gegeben wird.
6.1.4. Übersicht der Ergebnisse
Zusammenfassend lässt sich festhalten, dass in den Facebook Beiträgen tatsächlich mehrere Sprachen verwendet werden. Auf den Chroniken aller Nutzer lassen sich Statusmeldungen und Posts finden, die komplett auf Deutsch oder Italienisch verfasst sind, wobei die Anzahl der italienischen Beiträge im gesamten Korpus höher als die der deutschen ist. Es gibt außerdem auch eine große Anzahl an gemischtsprachigen Beiträgen.
Es kann kein Zusammenhang zwischen der Art des Beitrags und der verwendeten Sprache festgestellt werden. Zwar gibt es bei den Statusmeldungen geringfügig mehr englische Beiträge, dafür werden in den Posts geringfügig mehr italienische Beiträge verwendet. Die gemischtsprachigen Beiträge sind in beiden Beitragsarten gleichermaßen verteilt. Die Anzahl der Token in den verschiedenen nach Sprachen sortierten Beiträgen zeigt eine ähnliche Verteilung wie die der Sprachen innerhalb der Token. Allerdings konnte festgestellt werden, dass englische Beiträge sehr viel kürzer sind als italienische und deutsche, wobei die gemischtsprachigen Beiträge durchschnittlich am längsten sind. So kann schließlich davon ausgegangen werden, dass Englisch in den Beiträgen für kurze Aussagen, Ausrufe oder feste Phrasen verwendet wird, während es in gemischtsprachigen Beiträgen eher um komplexe Themen geht oder hier inter-sententiales CS stattfindet (siehe Kapitel ).
Es lassen sich zwei Gruppen an Nutzern identifizieren, die entweder häufiger Italienisch oder häufiger Deutsch in ihren Beiträgen verwenden. Die Sprachverwendung hängt dabei nicht mit dem aktuellen Wohnort, und auch nur bedingt mit dem Heimatland, zusammen. Vielmehr reflektiert sie die Sprachen und die Sprachverwendung der Facebook Freunde. Wenn also die Posts von Facebook Freunden auf Italienisch überwiegen, ist dies auch bei den Statusmeldungen der Fall.
Schließlich wurde an einigen Beispielen diskutiert, ob es einen Zusammenhang zwischen Thema und Sprache geben könnte. Es hat sich zwar gezeigt, dass ein Beitrag, der eine Reise oder den Aufenthalt in einem anderen Land thematisiert, die Verwendung der Landessprache triggern kann, dies ist aber nicht immer der Fall und anhand der Daten auch nicht überprüfbar. Es konnten auch andere Beispiele gefunden werden, die zeigen, dass sich die Sprachverwendung kaum an der Themenwahl festmachen lässt. So bleibt festzuhalten, dass es keinen klar erkennbaren Zusammenhang zwischen Thema und Statusmeldung gibt.
Die Verteilung der Sprachen innerhalb der gemischtsprachigen Beiträge bestätigt die Annahme, dass CS vor allem zwischen Deutsch und Italienisch stattfindet, da vor allem deutsche und italienische Token verwendet werden. Aber auch das Englische spielt eine wichtige Rolle. Die prozentuale Verteilung der Sprachen auf Tokenebene in gemischtsprachigen Beiträgen ähnelt der Sprachverteilung auf Beitragsebene im gesamten Korpus. Somit kann also von der Sprachverteilung innerhalb der Beiträge auf die der gemischtsprachigen Beiträge geschlossen werden.
Die Tatsache, dass meist eine der beiden Sprache, Italienisch oder Deutsch, häufiger als die andere(n) verwendet wird, führt zu der Vermutung, dass bei diesen Nutzern die bevorzugte Sprache als Basissprache fungiert, in die Elemente aus der anderen eingefügt werden. Das würde aber auch heißen, dass hier häufiger intra-sentententiales CS zu finden ist. Ob das bestätigt werden kann, soll später verifiziert werden (siehe Kapitel ). Schließlich kann ebenfalls verifiziert werden, dass die am häufigsten verwendete Sprachkombination Deutsch und Italienisch ist. Aber es kommen auch weitere Kombinationen vor – häufig auch mit mehr als zwei Sprachen – und auch hier lässt sich die wichtige Rolle des Englischen festhalten, das hier wieder bei den Statusmeldungen im Vergleich zu den Posts überwiegt.
6.1.5. Diskussion
Die eben präsentierten Ergebnisse sind in zweierlei Hinsicht relevant. Zum einen zeigt sich, dass die Datenerhebung und Korpusannotation insoweit geglückt sind, dass sich mittels Korpusabfragen aus der Datenbank quantitativ die Sprachverteilung und -verwendung ermitteln lässt. Auch die Darstellung von Zusammenhängen verschiedener Art, wie beispielsweise zwischen den verwendeten Sprachen und den Nutzern oder der Beitragsart, ist möglich. Zum anderen ergibt sich ein Überblick über die verwendeten Sprachen und Sprachwechsel.
Es konnte gezeigt werden, dass CS in 17% aller Facebook Beiträge vorkommt. Leider gibt es bislang kaum Vergleichsdaten aus anderen Studien. Einzig Shafie & Nayan (2013) merken an, dass es sich in ihrem Korpus bei 536 von 5.000 Beiträgen (also 11,36%) um CS handelt. In den meisten anderen Arbeiten zum CS in der CMC werden hingegen nur die Okkurrenzen von CS herausgefischt und so merkt Montes-Alcalá (2007) an: „I only considered blogs where there was actual code-switching“. Eine quantitative Verteilung aller innerhalb eines CMC Typs verwendeten Sprachen ist aber wichtig, da sie, wie gerade gesehen, Voraussagen über die Sprachwahl innerhalb eines gemischtsprachigen Beitrags machen kann. Auch in anderen Studien wird auf die Gesamtanzahl aller gesammelten Token eingegangen, CS wird aber meist nur qualitativ diskutiert und nicht gezeigt, wie groß der Anteil CS innerhalb des CMC Typs ist. Ob nun also CS in Facebook Beiträgen eher verwendet wird als beispielweise im Chat kann so nicht geklärt werden und es bleibt erst einmal offen bis weitere Studien sich der quantitativen Darstellung der Sprachverteilung widmen.
Anders wie bei dem situationsbedingten Sprachwechsel im Sinne von Gumperz (siehe Kapitel ), der die Verwendung der Sprachen bilingualer Sprecher externen Faktoren zuordnet, ist die Sprachwahl auf Facebook durch die Analyse der Beiträge nicht vorhersagbar. Bei online bilingualen Sprechern in einem virtuellen Raum lässt weder die Herkunft noch der aktuelle reale Aufenthaltsort einen Schluss über die Wahl der Sprache zu. Die Ergebnisse der Sprachverteilung zeigen, dass es wohl die Facebook Freunde sind, die auf dieser SNS die Sprachverwendung beeinflussen. Es konnte gezeigt werden, dass sich sowohl bei den Statusmeldungen als auch den Posts zwei Gruppen identifizieren lassen, die je eine der beiden Sprachen Deutsch oder Italienisch bevorzugt verwendet. Während es sich bei dem Nutzer aber um nur eine reale Person mit einer Sprachbiografie handelt, gibt es auf Seiten der Facebook Freunde viele verschiedene Sprachbiografien: von deutsch oder italienisch monolingualen Sprechern, über ebenfalls deutsch-italienisch bilinguale Sprechern, bis hin zu Sprechern ganz anderer Sprachen. Die Facebook Freunde schreiben an den Nutzer und verwenden dabei die Sprache oder die Sprachkombination, die sie mit diesem teilen. Der Nutzer hingegen hat beim Verfassen einer Statusmeldung das Gros seiner Facebook Freunde mit den unterschiedlichen Sprachkenntnissen vor Augen. Um seine Freunde also möglichst gleichmäßig zu erreichen, spiegelt er die Sprachverwendung seiner Freunde in den Posts.
Die Frage, ob das Thema die Sprachwahl beeinflusst, wurde verneint. Androutsopoulos (2006, 193) beobachtet zwar in einer anderen Form der CMC, den Ethnoportalen, dass Diskussionsthema und Sprache zusammenhängen können, geht aber auch davon aus, dass es sich dabei um eine „nicht bindende Tendenz“ handelt. Um herauszufinden, ob es eventuell doch persönliche Motivationen bilingualer Facebook Nutzer gibt, die eine oder andere Sprache zu verwenden, müssten diese Nutzer direkt befragt werden. Auch das Sammeln und Aufzeichnen von Informationen zu Aufenthaltsort, Adressaten und anderen Rahmenbedingungen bei der Eingabe eines Beitrags könnte hilfreich sein. Es sei hier jedoch festzuhalten, dass sich die Sprachwahl bilingualer Sprecher in einem virtuellen Raum nur bedingt auf externe Faktoren zurückführen lässt.
Es konnte auch bestätigt werden, dass das Englische eine wichtige Rolle in den Facebook Beiträgen spielt. Interessant ist, dass hier die englischen Beiträge sehr kurz sind, also wohl nicht auf komplexe Themen schließen lassen, wie das Beispiele (86) verdeutlicht.
[FB 1621_410]
at work…
Englisch wird aber auch häufig in gemischtsprachigen Beiträgen verwendet, was zu der Vermutung führt, dass sich hier häufig englischstämmige Entlehnungen finden lassen. Das soll im nächsten Kapitel überprüft werden.
Schließlich lassen sich aus einem Vergleich der verschiedenen Sprachkombinationen mit der quantitativen Verteilung der Sprachen in den gemischtsprachigen Beiträgen verschiedene Schlüsse ziehen. Es wurde schon vermutet, dass es häufiger inter- als intra-sententiales CS in Form von Wiederholungen geben muss. Aber die Sprachverteilung nach Nutzern führt zu der Annahme, dass es in den Statusmeldungen häufig Einzel-Wort Switches gibt. Anhand der Gesamtanzahl der Token müsste demnach die Zahl der Beiträge, bei denen deutsche Wörter in ansonsten auf Italienisch verfasste Beiträge eingefügt werden höher sein. Diese Vermutungen sollen im folgenden Kapitel geprüft werden werden.
6.2. Die verwendeten CS Typen in Facebook Beiträgen und ihre kommunikativen Funktionen
Unter CS in Facebook Beiträgen wird nach der Definition, die dieser Arbeit zugrunde liegt, das Wechseln zwischen zwei oder mehreren Sprachen innerhalb eines einzigen Beitrags verstanden (siehe Kapitel ). Somit stellen die gemischtsprachigen Beiträge des Facebook Korpus CS dar. Diese Beiträge sollen im Folgenden analysiert werden. Dafür erfolgt zunächst die Bestimmung und die Präsentation der quantitativen Verteilung nach einem strukturellen Ansatz, wie sie in Kapitel vorgeschlagen wurde. Dabei können schon einige Strategien beim Wechseln der Sprache festgestellt werden. Im Anschluss daran erfolgt eine qualitative Analyse ausgewählter Beispiele zur Bestimmung der kommunikativen Funktionen.
Im ersten Teil wird eine Übersicht, wie die Typen im Facebook Korpus bestimmt wurden und wie sie in den gemischtsprachigen Beiträgen des Korpus verteilt sind präsentiert. In den folgenden beiden Teil werden zunächst die Ergebnisse des inter-sententialen und danach die des intra-sententialen CS vorgestellt und diskutiert.
6.2.1. Verteilung von CS nach inter- und intra-sententialem CS
Die gemischtsprachigen Beiträge werden zunächst in inter- und intra-sentential unterteilt, um diese danach weiter untergliedern zu können. Eine Unterteilung in diese beiden übergeordneten CS Typen ist dabei nicht immer einfach, da in einem Beitrag mehrere verschiedene Code-Switches vorkommen können. Außerdem können verschiedene Sprachen verwendet werden und die Unterscheidung zwischen inter- und intra-sententialem CS ist nicht immer eindeutig.
Alle Fälle, bei denen eine eindeutige strukturelle Trennung der Sätze erkennbar ist, werden hier zum inter-sententialen CS gezählt. Hinweise darauf geben satztrennende Zeichen. Dazu zählen Satz beendende Interpunktionen, wie Punkt(e), Ausrufe- oder Fragezeichen, aber auch andere strukturierende Elemente, wie Emoticons. Im Facebook Korpus kann mit Hilfe einer Abfrage inter-sententiales CS anhand der eben genannten Trennungszeichen und der sich ändernden Sprache des Tokens erkannt werden. Beispielsweise wird eine Abfolge nach dem Schema Token_it Token_it Token _it TokenSENT Token_de Token_de als inter-sententiales CS markiert. Alle anderen Switches, bei denen eine solche strukturelle Trennung nicht vorliegt, werden zunächst als intra-sententiales CS markiert.204
In dem folgenden Facebook Post werden nach diesem Verfahren zwei Okkurrenzen für inter-sententiales CS identifiziert: ein Wechsel vom Italienischen ins Deutsche nach dem Ausrufezeichen und nach „frown“-Emoticon zurück vom Deutschen ins Italienische:
[FB 231083_291]
Ciao bella mia! In welchem Land treibst dich grad rum und wann kann ich dich mal telefonisch erreichen??? Fehlst mir „frown“-Emoticon Bacione
Dieses Beispiel zeigt außerdem, dass es in einem Beitrag durchaus mehrere Switches geben kann und dass Emoticons tatsächlich als Trennungszeichen eingesetzt werden.
In Beispiel (88) können sogar drei Okkurrenzen für inter-sententiales CS erkannt werden, nämlich vom Deutschen ins Italienische vor Mi manchate [sic!] già ins Deutsche vor Wir sollten im übrigen… und wieder ins Italienische bei VI VOGLIO BENE.
[FB 1112113_12]
Es war toll euch wiederzusehen, ragazze [NAME]! Mi manchate già!!! Wir sollten im übrigen eine CD rausbringen! Unser Lied stürmt demnächst bestimmt die Charts!VI VOGLIO BENE!!!!
Hier gibt es außerdem auch noch einen Fall von intra-sententialem CS bei ragazze. Da dieser Sprachwechsel innerhalb eines Satzes erfolgt, also nicht von Satz strukturierenden Elementen begrenzt ist, kann er deshalb zu der Kategorie intra-sententiales CS gezählt werden. Auch Beispiel (89) zeigt einen Switch dieses Typs:
[FB 1211_139]
Hallo a tutti….
Eine Unterscheidung zwischen inter- und intra-sententialem CS ist allerdings nicht immer eindeutig, weshalb eine manuelle Nachkontrolle zwingend notwendig ist. In Zweifelsfällen wird hier eine Trennung nach Satz strukturierenden Elementen der Vorzug gegeben. So wird in einem Fall wie in Beispiel (90) der Switch zwischen sn viva ‚sono viva‘ und don’t worry als intra-sententiales CS gewertet, während der Switch nach den Interpunktionszeichen als inter-sententiales CS markiert wird.
[FB 1621_14]
sn viva don`t worry…c`ho solo la crisi!!!
Problematisch erweisen sich Beiträge wie der Post in (91), bei dem nach der Korpusabfrage nur intra-sententiales CS erkannt wird. Allerdings handelt es sich hier um feste Phraseologismen, die in den anderen Sprachen wiederholt werden und bei denen es keine syntaktische Einbettung gibt. Für solche Fälle wurde deshalb entschieden, diese als inter-sententiales CS zu werten und des Weiteren als Wiederholungen zu markieren (siehe Kapitel ).
[FB 2211_924]
Frohe Weihnachten, buon natale, joyeux noel, merry xmas, … „smile“-Emoticon
Im Folgenden soll nun eine Übersicht gegeben werden, wie inter- und intra-sententiales CS im Korpus verteilt sind. Dabei wird zunächst geprüft, ob es einen Zusammenhang zwischen dem Beitragstyp und inter- und intra-sententialem CS gibt und ob verschiedene Nutzer die eine oder andere Art von CS bevorzugen.
6.2.1.1. Übersicht nach Art des Beitrags
In den gemischtsprachigen Facebook Beiträgen des Korpus gibt es sowohl inter- als auch intra-sententiales CS, wie die folgende Tabelle zeigt:
| Statusmeldung | Post | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| Inter-sentential | 489 | 54,33 | 540 | 48,39 | 1.029 | 51,04 |
| Intra-sentential | 411 | 45,67 | 576 | 51,61 | 987 | 48,96 |
| Gesamt | 900 | 100,00 | 1.116 | 100,00 | 2.016 | 100,00 |
Es fällt auf, dass es mehr CS als gemischtsprachige Beiträge gibt, also auch mehrere Sprachwechsel in einem Beitrag vorkommen können. Von den gemischtsprachen Beiträgen lassen sich 667 den Statusmeldungen und 702 den Posts zuordnen (siehe Tabelle 32 in Kapitel ). Das bedeutet, dass es pro Statusmeldung durchschnittlich insgesamt 1,34 Sprachwechsel gibt, wovon 0,73 inter- und 0,61 intra-sententiale Switches sind. Bei den Posts sind es 1,59 Switches pro Beitrag, davon 0,77 inter- und 0,82 intra-sentential.
In Tabelle 42 wird deutlich, dass insgesamt mehr inter- als intra-sententiales CS verwendet wird. Was die prozentuale Verteilung dieser beiden CS Typen in den verschiedenen Beitragsarten anbelangt, überwiegt in den Statusmeldungen der Anteil des inter-sententialen CS, während in den Posts häufiger intra-sententiale Switches verwendet werden. Der Anteil des inter-sententialen CS ist somit nur geringfügig größer als der des intra-sententialen CS (die Differenz liegt bei nur 47 Okkurrenzen). In Statusmeldungen wird hingegen inter-sententiales CS bevorzugt, in Posts intra-sententiales.
6.2.1.2. Übersicht nach Nutzern
Im Folgenden wird die Verteilung der Switching Typen in Statusmeldungen und Posts nach Nutzern betrachtet, um zu prüfen, ob es sich bestimmte Präferenzen für inter- oder intra-sententiales CS abbilden lassen.
Facebook Statusmeldungen
Die Verteilung nach inter- und intrasententialem CS in den von den Nutzern selbst verfassten Statusmeldungen lässt sich wie folgt darstellen:
| inter-sentential | intra-sentential | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| 1021 | 20 | 32,79 | 41 | 67,21 | 61 | 100,00 |
| 1112 | 64 | 60,95 | 41 | 39,05 | 105 | 100,00 |
| 1211 | 32 | 96,97 | 1 | 3,03 | 33 | 100,00 |
| 1301 | 35 | 83,33 | 7 | 16,67 | 42 | 100,00 |
| 1411 | 12 | 70,59 | 5 | 29,41 | 17 | 100,00 |
| 1501 | 4 | 100,00 | 0 | 0,00 | 4 | 100,00 |
| 1621 | 53 | 36,30 | 93 | 63,70 | 146 | 100,00 |
| 1701 | 13 | 81,25 | 3 | 18,75 | 16 | 100,00 |
| 1824 | 12 | 19,67 | 49 | 80,33 | 61 | 100,00 |
| 1921 | 111 | 46,64 | 126 | 52,94 | 238 | 100,00 |
| 2001 | 9 | 75,00 | 3 | 25,00 | 12 | 100,00 |
| 2101 | 6 | 100,00 | 0 | 0,00 | 6 | 100,00 |
| 2211 | 94 | 75,81 | 30 | 24,19 | 124 | 100,00 |
| 2310 | 23 | 63,89 | 13 | 36,11 | 36 | 100,00 |
| Gesamt | 488 | 54,22 | 412 | 45,78 | 900 | 100,00 |
Einige der Facebook Nutzer benutzen in den Statusmeldungen nur inter-sententiales CS. Die Nutzer 1501 und 2101 sowie der Nutzer 1211 verwenden fast ausschließlich inter-sententiale Sprachwechsel. Allerdings ist bei diesen Nutzern auch die Anzahl an Switches insgesamt nicht sehr groß. Bei den meisten anderen Nutzern (1112, 1301, 1411, 1701, 2001, 2101, 2211 und 2310) überwiegt ebenfalls das inter-sententiale CS. Einzig die Nutzer 1021, 1621, 1824 und 1921 verwenden mehr intra-sententiales CS, wobei bei Letzterem der Anteil nur geringfügig größer ist.
Es kann schließlich kein Zusammenhang mit der Gesamtanzahl der Switches ausgemacht werden. Interessanterweise gehören jedoch alle Nutzer, bei denen das intra-sententiale CS überwiegt, zu der Gruppe der Sprecher, die häufiger Italienisch als Deutsch in den Statusmeldungen verwenden (siehe Kapitel ). Die Nutzer, bei denen wiederum deutsche Statusmeldungen überwiegen, präferieren inter-sententiales CS.
Facebook Posts
Die Verteilung von inter- und intra-sententialem CS in den von den Facebook Freunden verfassten Posts, kann wie folgt dargestellt werden:
| inter-sentential | intra-sentential | Gesamt | ||||
| Anz. | % | Anz. | % | Anz. | % | |
| 1021 | 22 | 22,92 | 74 | 77,08 | 96 | 100,00 |
| 1112 | 40 | 72,73 | 15 | 27,27 | 55 | 100,00 |
| 1211 | 6 | 66,67 | 3 | 33,33 | 9 | 100,00 |
| 1301 | 62 | 56,36 | 48 | 43,64 | 110 | 100,00 |
| 1411 | 0 | 0,00 | 1 | 100,00 | 1 | 100,00 |
| 1501 | 4 | 66,67 | 2 | 33,33 | 6 | 100,00 |
| 1621 | 123 | 40,07 | 184 | 59,93 | 307 | 100,00 |
| 1701 | 14 | 87,50 | 2 | 12,50 | 16 | 100,00 |
| 1824 | 11 | 36,67 | 19 | 63,33 | 30 | 100,00 |
| 1921 | 123 | 55,16 | 100 | 44,84 | 223 | 100,00 |
| 2001 | 4 | 57,14 | 3 | 42,86 | 7 | 100,00 |
| 2101 | 29 | 47,54 | 32 | 52,46 | 61 | 100,00 |
| 2211 | 51 | 51,00 | 49 | 49,00 | 100 | 100,00 |
| 2310 | 51 | 53,68 | 44 | 46,32 | 95 | 100,00 |
| Gesamt | 540 | 48,39 | 576 | 51,61 | 1116 | 100,00 |
Die Facebook Freunde der Nutzer 1112, 1211, 1301, 1501, 1701 bevorzugen eindeutig inter-sententiales CS. Die Präferenz für diese Art des CS ist auch bei den Nutzern selbst erkennbar (siehe Tabelle 43). Somit lässt sich feststellen, dass sowohl die eben genannten Facebook Freunde als auch die entsprechenden Nutzer inter-sententiales CS bevorzugen. Die Facebook Freunde der Nutzer 1021, 1621 und 1824 verwenden mehr intra-sententiales CS; auch hier stimmt diese Präferenz der Facebook Freunde mit der der Nutzer überein.205 Die Verteilung von inter- und intra-sententialem CS in den Posts der Nutzer 1921, 2001, 2101, 2211 und 2310 ist schließlich relativ gleichmäßig. Interessant daran ist, dass es sich dabei um die Nutzer der Gruppe handelt, die in den Beiträgen Deutsch bevorzugen, wie Kapitel zeigt (Ausnahme sind die Freunde von Nutzer 1921).
Es kann also festgestellt werden, dass sich Facebook Freunde und Nutzer in ihren Posts und Statusmeldungen hinsichtlich der Verwendung bestimmter CS Tyen ähnlich verhalten. Grafisch lassen sich die prozentualen Verteilungen der CS Typen nach Beitragsart und Nutzer wie folgt zusammenfassen:
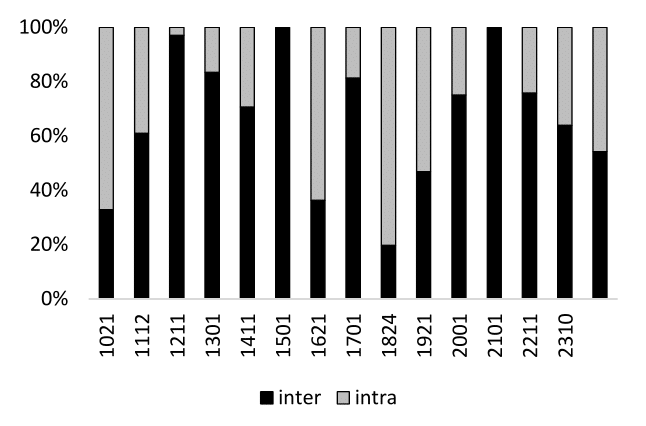
Verteilung von inter- und intra-sententialem CS in Posts nach Nutzern (in Prozent).
(Lizenz: CC BY SA)
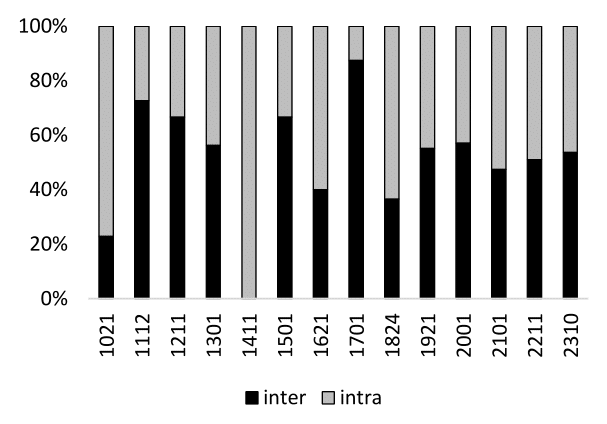
Verteilung von inter- und intra-sententialem CS in Posts nach Nutzern (in Prozent).
(Lizenz: CC BY SA)
Zusammenfassend lässt sich sagen, dass im gesamten Facebook Korpus inter- und intra-sententiales CS zwar einigermaßen gleichmäßig verteilt ist. Das gilt allerdings nicht für die Verteilung bei den einzelnen Nutzern. Hier überwiegen bei den meisten Nutzern, mal mehr und mal weniger deutlich, inter-sententiale Switches, und nur in wenigen Fällen ist der prozentuale Anteil des intra-sententialen CS deutlich höher.
Nach der Betrachtung der Verteilung von inter- und intra-sententialem CS nach Beitragsart und Nutzern kann die Hypothese bestätigt werden, dass inter-sententiales CS in den Facebook Beiträgen überwiegt. Im Zusammenhang mit der Beitragsart zeigt sich, dass in Statusmeldungen eher inter-sententiales CS bevorzugt wird, in den Posts intra-sententiales CS. Aber auch wenn im gesamten Korpus das inter-sententiale CS zahlenmäßig mit dem intra-sententialen CS fast gleichauf liegt, zeigt die Verteilung nach Nutzern, dass die meisten Nutzer inter-sententiales CS bevorzugen und dass sich die Anzahlen eher mit den Präferenzen für bestimmte Switching Typen erklären lassen, wie die folgenden Kapitel zeigen werden.
6.2.2. Inter-sententiales CS und kommunikative Funktionen
Nachdem 1.029 Okkurrenzen für inter-sententiales CS im Korpus belegt wurden, sollen diese genauer betrachtet werden. Dabei treten bei einer Untersuchung vor allem zwei darin verwendete kommunikative Strategien hervor: die Grußformeln und die Wiederholungen:
| Statusmeldungen | Post | Gesamt | |||||
| Anz. | % | Anz. | % | Anz. | % | ||
| Grußformeln | 81 | 16,56 | 364 | 67,41 | 445 | 43,25 | |
| davon: | Begrüßung | 7 | 1,43 | 68 | 12,59 | 75 | 7,29 |
| Verabschiedung | 70 | 14,31 | 279 | 51,67 | 349 | 33,92 | |
| Anrede | 4 | 0,82 | 17 | 3,15 | 21 | 2,04 | |
| Wiederholungen | 219 | 44,79 | 27 | 5,00 | 246 | 23,91 | |
| Andere | 189 | 38,65 | 149 | 27,59 | 338 | 32,85 | |
| Gesamt | 489 | 100,00 | 540 | 100,00 | 1.029 | 100,00 |
Die Grußformeln, zu denen sowohl Begrüßungs- und Verabschiedungsfloskeln, als auch Anredeformen gezählt werden, können aufgrund ihrer peripheren Stellung im Satz leicht identifiziert werden. Sie bilden mit 43,25% den größten Anteil innerhalb der Gruppe des inter-sententialen CS. Dabei werden Verabschiedungen häufiger verwendet als Begrüßungen. Unter Wiederholungen werden Switches gezählt, bei denen eine Äußerung in der anderen Sprache wiederholt wird. Die Anzahl dieser Wiederholungen ist mit 23,91% ebenfalls relativ groß. Für die restlichen 32,85% der inter-sententialen Switches konnte auf den ersten Blick keine Unterkategorie ausgemacht werden, später wird sich aber zeigen, dass sich doch verschiedene Strategien erkennen lassen.
Nach Beitragsart sortiert fällt auf, dass in den Statusmeldungen der prozentuale Anteil der Wiederholungen mit 44,79% deutlich überwiegt; bei den Posts sind es nur 5%. Dafür fallen bei den Statusmeldungen die Grußformeln weniger ins Gewicht. Während es sich in den inter-sententialen Switches in Statusmeldungen bei 16,56% aller Okkurrenzen Grußformeln handelt, ist der Anteil der Grußformeln in Posts mit 67,41% deutlich höher. Wie das zu erklären ist, soll im Folgenden diskutiert werden.
6.2.2.1. Wiederholungen
Bei den Wiederholungen lassen sich verschiedene Arten identifizieren. Zum einen kann es sich bei den Wiederholungen um wörtliche Übersetzungen handeln, wie die Beispiele (92) und (93) und zeigen:
[FB 1211_26]
Guten Morgen Allerseits…Buon Giorno a tutti…
[FB 1701_396]
It’s never too late! Non è mai tropo tardi! Es ist niemals zu spät!
Zum anderen kommen auch sinngemäße und inhaltliche Wiedergaben in einer anderen Sprache, die gegebenenfalls etwas von der Äußerung in der anderen Sprache abweichen, vor. So handelt es sich bei dem jeweils zweiten Satz in (94) und (95) um sinngemäße und nicht um wörtliche Übersetzungen.
[FB 1211_106]
che giornata noiosa…uff Voll der öde tag heute…
[FB 2211_450]
jetz fehlt no eine Klausur (und eine Praktische) und dann Feeerien „smile“-Emoticon – Manca un’esame –> feeerieeee „smile“-Emoticon
Diese inhaltlichen Wiedergaben treten dabei wesentlich häufiger auf als wörtliche Übersetzungen. Dies lässt auch Rückschlüsse auf die Kompetenz der Nutzer in den beiden verwendeten Sprachen zu, da diese hier nicht einfach übersetzen, sondern ihre Äußerungen an die Gepflogenheiten der jeweiligen Sprache anpassen.
Bei den meisten Wiederholungen handelt es sich um Glückwünsche zum Geburtstag, zu Feiertagen oder aber um Danksagungen zu erhaltenen Glückwünschen. Ein Beispiel dafür wurde schon in (91) präsentiert, aber auch bei den Beispielen (96) bis (98) handelt es sich um Wiederholungen dieser Art:
[FB 1701_426]
Merry christmas everyone! Frohe Weihnachten! Auguri di buon natale! [NAME]
[FB 1112_321]
Grazie mille per gri tantissimi auguri. Danke für die vielen lieben Geburtstagsgruesse!
[FB 1112_317]
Buona pasqua a tutti! frohe ostern! „smile“-Emoticon
Nach Tabelle 45 werden von den insgesamt 246 Wiederholungen 219 in den Statusmeldungen verwendet – das entspricht 23,91% aller inter-sententialen Switches. Das lässt sich damit erklären, dass Posts an den Nutzer gerichtet sind und in der Sprache verfasst werden, die Nutzer und Facebook Freunde miteinander teilen. Der Nutzer selbst möchte mit dem Veröffentlichen von Statusmeldungen jedoch mehrere Nutzer(gruppen) seiner Facebook Freunde erreichen und verwendet deshalb mehrere Sprachen. Glückwünsche von Freunden werden deshalb in Posts meist einsprachig auf der Chronik veröffentlicht (dabei verwenden unterschiedliche Freunde auch unterschiedliche Sprachen). Der Nutzer bedankt sich dann häufig mit einer „Sammel-Statusmeldung“, in der er mehrere Sprachen verwendet, wie beispielweise in (97).
In einigen Fällen wird eine bestimmte Gruppe an Facebook Freunde explizit adressiert. So wird in Beispiel (99) die italienische Wiederholung durch die direkte Adressierung per gli italiani ‚für die Italiener‘ eingeleitet:
[FB 2310_235]
Vielen lieben Dank an alle, die mir zum Geburtstag gratuliert haben!! Hab mich riesig gefreut!! E per gli italiani: GRAZIE di cuore a tutti per gli auguri!!!!!!
Es gibt auch einige Beispiele, bei denen Wiederholungen in einer anderen Sprache andere Zwecke erfüllen:
[FB 1301_427]
„Prioritäten setzen heißt auswählen, was liegenbleiben soll. Choosing priorities means deciding what will remain undone. Fixer des priorités veut dire choisir ce qui doit attendre.“
[FB 1211_96]
bin krank, so ein mist… ho l’influenza, merda…
[FB 2211_528]
Schnee, meeeehr Schneee „smile“-Emoticon Nevica, troppo bello, tutto bianco fuori.. „smile“-Emoticon
Das Beispiel in (100) gibt ein Zitat wieder, zusätzlich markiert durch Anführungsstriche. Durch Zitate teilt der Facebook Nutzer den anderen mit, was ihn bewegt und was er interessant findet. Er kann damit aber auch seine Zustimmung ausdrücken. Durch die Übersetzungen ins Englische und Französische demonstriert er zudem seine Sprachkompetenzen. Das heißt, das Verfassen des Beitrags selbst dient der Demonstration dessen, was der Nutzer interessant findet und was zu seinen Grundsätzen passt. Der Sprachwechsel soll diese Informationen vielen Facebook Freunden zugänglich machen und ermöglicht gleichzeitig die Selbstdarstellung des Nutzers als Sprecher mehrerer Sprachen.
In (101) teilt der Nutzer schließlich eine Information über seinen Gesundheitsstatus und in (102) wird ebenfalls ein Ereignis, das dem Nutzer interessant erscheint und an dem er emotional beteiligt ist, über den Facebook Beitrag mitgeteilt. Durch die Wiederholung einer Äußerung in der jeweils anderen Sprache kann diese nicht nur von den deutschen, sondern auch von den italienischen Facebook Freunden gelesen werden. Der Sprachwechsel dient auch hier vor allem dazu, persönliche Interessen mit möglichst vielen Freunden zu teilen.
Zusammenfassend lässt sich feststellen, dass Wiederholungen vor allem in Statusmeldungen zu finden sind. Sie dienen dazu, Glückwünsche und Danksagungen mit möglichst allen Facebook Freunden zu teilen. Mit den Beiträgen soll das gesamte Netzwerk, das auf Facebook aufgebaut wurde, angesprochen werden. Außerdem dienen die Wiederholungen der Selbstdarstellung, da der Nutzer mit der Verwendung mehrerer Sprachen seine Bilingualität unter Beweis stellt. Gestützt wird diese Bemerkung auch durch die Tatsache, dass es sich bei 15 der 19 Statusmeldung um Beiträge mit der Sprachkombination Deutsch, Englisch, Italienisch und anderen (Ot-it-de-en in Tabelle 38) handelt (bei den Posts sind es nur 3 von 10 dieser Sprachkombinationen).
6.2.2.2. Grußformeln
Zu den Grußformeln gehören zum einen Begrüßungsformeln und Verabschiedungsformeln, zum anderen Anredeformen. Die Grußformeln stellen als Routineformeln feste Strukturen dar, die sich einfach in einen Beitrag, der ansonsten nur Elemente in einer anderen Sprache enthält, einfügen lassen. Die primäre Funktion ist das Grüßen. Grußformeln werden aber auch dazu verwendet, einen Diskurs zu eröffnen oder zu schließen.
Zu den Begrüßungen zählen Floskeln, aber auch kurze Phrasen wie hallo, hey, guten Morgen, wie geht’s, was läuft, etc., zu den Verabschiedungen gehören aus einem Wort bestehende Grüße, aber auch Phrasen wie tschüss, bis bald, Küsse, hab dich lieb, gute Nacht, vermisse dich etc. (sowie jeweils deren Entsprechungen im Italienischen und Englischen ). Begrüßungen werden typischerweise am Anfang einer Statusmeldung oder eines Posts verwendet, Verabschiedungen am Ende.
Zu den Grußformeln werden auch Anreden gezählt. Diese können aus einem einzigen Nomen bestehen, wie bellezza! im folgenden Beispiel zeigt:
[FB 1301116_46]
bellezza!was geht ab??wann sind wir mal wieder zusammen am start da unten „wink“-Emoticon bacione
Auch Kombinationen bestehend aus Anrede und Begrüßung oder Verabschiedung werden hier eingeschlossen. Ciao bella oder ciao coinquilina in (104) und (105) und a presto bella in (105) sind gute Beispiele dafür:206
[FB 130118_3]
ciao bella!!schön das du jetzt auch hier bist! „smile“-Emoticon Sehn wir uns die Woche mal? Speriamo a presto! bacione! [NAME]
[FB 130180_301]
ciao coinquilina! „smile“-Emoticon hab heut von dir geträumt! hoff, dir geht’s gut! bist du jetzt einen monat zu hause oder? a presto bella!
Wie Tabelle 11 zeigt überwiegen dabei eindeutig die Verabschiedungen mit 33,92% (der Gesamtanzahl aller inter-sententialen Switches). Begrüßungen sind mit 7,29% deutlich seltener, ebenso wie Anredeformen, die nur 2,04% ausmachen. Das könnte daran liegen, dass hierzu auch Routineformeln wie de. ich liebe dich, de. ich vermisse dich, en. love you oder it. mi manchi, gerechnet werden. Eine weitere mögliche Erklärung ergibt sich aus dem Kommunikationsmedium. Durch das Veröffentlichen des Beitrags wird der Nutzer angesprochen, seine Aufmerksamkeit erregt, weshalb eine Eröffnung des Diskurses durch eine Begrüßung überflüssig erscheint. Verabschiedungen hingegen schließen den Diskurs, sie dienen aber auch dazu, eine Verbindung mit dem Adressaten oder den Adressaten herzustellen. Sie stellen zudem eine Routine in dieser Kommunikationsform dar, wie sich an der hohen Anzahl ablesen lässt.
Grußformeln werden mit 67,41% viel häufiger in Posts verwendet als in Statusmeldungen, wo sie nur 16,56% aller inter-sententialen Switches ausmachen (siehe Tabelle 11). Das lässt sich damit erklären, dass die Facebook Freunde den Nutzer direkt ansprechen, mit ihm also in einen Dialog treten und sich auch entsprechend verabschieden. Statusmeldungen dienen eher der Selbstdarstellung. Hier können Interessen und Meinungen sowie Informationen zur eigenen Person geteilt werden (siehe primäre Funktionen der Facebook Beiträge in Kapitel ). Sie sprechen deshalb nicht die anderen Nutzer konkret an, sie sollen also keinen Dialog initiieren. Wenn Grußformeln in den Statusmeldungen verwendet werden, handelt es sich meist um Verabschiedungsfloskeln. Begrüßungen stellen eine Ausnahme dar und enthalten selten eine Adressierung bestimmter Nutzer, wie bonjour monde in (106) verdeutlicht:
[FB 1621_16]
bonjour monde….raffreddata….acciù…questo significa che sn umana anche io ahhhhhh
Es kann festgehalten werden, dass Grußformeln und vor allem Abschiedsfloskeln eine wichtige Strategie der Facebook Beiträge darstellen. Vor allem in den Posts spielen sie eine wichtige Rolle. Sie erfüllen so eine Networking Funktion, indem sie eine Relation zwischen Verfasser und Adressat herstellen. Die Verwendung einer anderen Sprache in der Grußformel dient zum einen dazu, die Verbindung herzustellen, sich den Adressaten anzunähern und einen Diskurs zu beginnen. Zum anderen dienen Grußformeln ebenfalls der Selbstdarstellung, indem sie die eigene Identität als bilinguale Sprecher offenbaren.
6.2.2.3. Andere inter-sententiale Code-Switches
Zu der letzten Kategorie werden alle übrigen Okkurrenzen für inter-sententiales CS gezählt. Es lässt sich gleich vorweg sagen, dass nicht bei allen Belegen eindeutig erkennbar ist, welche Funktion mit dem Sprachwechsel erreicht werden soll. Bei den anderen lassen sich jedoch einige Strategien erkennen, aus denen weitere kommunikative Funktionen hergeleitet werden können.
In einigen Wechseln dient die Äußerung in der anderen Sprache als eine Art Einleitung. Sie stellt den äußeren Rahmen dar oder dient gar als eine Art Überschrift für das was folgt.
[FB 102130_367]
Mission accomplished: contratto firmato e strappato dopo una strenua lotta senza esclusione di colpi. Inquinati davanti alla vincitrice!!!! „grin“-Emoticon scherzo, il panzone e´ stato gentilissimo e simpa.
[FB 1621_2608]
Lesson of the year: se non hai trovato il giusto con cui stare, sta da solo ma ti prego non stare con chi non saresti stato mai.
[FB 1621_3]
….Beim Vorbereitung des Koffers….207
So kann Mission accomplished in (107) und Lesson of the year in (108) als eine zusammenfassende Überschrift aufgefasst werden, die in den darauffolgenden Sätzen ausgeführt wird. Hier deutet auch der Doppelpunkt darauf hin, dass eine Erklärung oder eine Ausführung folgt. In (109) stellt valigiando eine solche Zusammenfassung für das Darauffolgende dar. Es handelt sich dabei außerdem um eine kreative Wortbildung, da hier an das Nomen (valigia ‚Koffer‘) die Gerundium-Endung –ndo angehängt wird, was den Vorgang des Kofferpackens beschreiben soll. Die kommunikativen Funktionen dieser einleitenden Sprachwechsel können wieder mit der Selbstdarstellung und dem Teilen von Informationen mit bestimmten Facebook Freunden zusammengefasst werden. Es ist aber auch ein kreativer Gebrauch der Sprache erkennbar.
Inter-sententiales CS kann auch dazu verwendet werden, emotionale Beteiligung oder Meinungen auszudrücken. So werden häufig Floskeln, die eine persönliche Meinung widerspiegeln, in einer anderen Sprache als der Rest des Beitrags verfasst wie love it in (110). Sie stellen eine subjektive Empfindung dar, wie brrr wie kalt in (111), während sich der Satz davor auf eine objektive Tatsache bezieht.208 Schließlich kann der Ausdruck des persönlichen Empfindens auch von einem Emoticon verstärkt werden, wie in (112). Hier fasst traurig den Gemütszustand des Nutzers zusammen, der durch das Vermissen anderer hervorgerufen wird, und wird dabei zusätzlich von einem traurigen Emoticon begleitet.
[FB 1621_1502]
Io appartengo a quest’altra vitaaaaaaaaa „smile“-Emoticon love it „smile“-Emoticon
[FB 1112_490]
Che freddo Milano stamattina 6gradi! E io sono uscita a Bologna col sole e le ballerine….brrr wie kalt!!!!
[FB 1211125_300]
Mi mancate tanto… traurig „sadly“-Emoticon
Die Sprachwechsel in dieser Art der Beiträge stellen Signale für eine persönliche Positionierung dar. Sie können aber durchaus auch der Distanzierung dienen, wie die Beiträge des nächsten Typs zeigen.
Es gibt außerdem einige idiomatische Ausdrücke oder feststehende Phrasen, Floskeln oder Zitate in den inter-sententialen Switches. Mit make love not wird ein bekannter Slogan in (113) verwendet. IN YOUR FACE in (114) stellt eine häufig verwendete Beschimpfung in Liedtexten, Filmen, aber auch in der CMC im Allgemeinen dar (beispielsweise bei Online-Spielen).
[FB 11112_522]
Hab das Video gesehen und Gänsehaut bekommen… make love not war!
[FB 1411_28]
Latein (und letzter Schein)..IN YOUR FACE! „smile“-Emoticon nunc bibendum est!!!
Tatsächlich sind Ausdrücke, Zitate oder Floskeln dieser Art häufig in Englisch und werden sowohl in ansonsten auf Italienisch, als auch auf Deutsch verfassten Beiträgen verwendet (mit einer leichten Präferenz in den zuletzt Genannten). Diese dienen dazu, sich selbst darzustellen, aber auch der persönlichen Positionierung.
Außerdem bezwecken inter-sententiale Sprachwechsel häufig, eine bestimmte Untergruppe an Facebook Freunden anzusprechen, wie es in (115) der Fall ist. Die Funktion der Beiträge dieses Typs ist damit wieder die Annäherung an eine bestimmte Gruppe von Facebook Freunden und signalisiert damit eine Zugehörigkeit.
[FB 1621_2051]
Das ist nicht DEFINITIV meine Welt…Amici italiani ho bisogno di voiiiiiii „smile“-Emoticon
Schließlich gibt es Okkurrenzen, die sich keinem der eben genannten Typen zuordnen lassen. Diese können mit einem Themenwechsel begründet werden, sind aber sehr selten.
[FB 2211_376]
Mit Gewalt geht alles „smile“-Emoticon Blinkrelais vorerst wieder heil!! … fra due giorni sarò a Pavia „smile“-Emoticon
So wird in (116) zuerst eine Tatsache oder ein Vorgang beschrieben, während die Äußerung nach dem Switch eine konkrete Verbindung zum Nutzer, der die Äußerung tätigt, herstellt. Zudem wird die erste Person Singular verwendet, woran sich ebenfalls eine Personalisierung erkennen lässt.
Es gibt schließlich auch noch einige wenige getriggerte Switches. Dabei wird nach dem Einfügen eines Nomens aus einer anderen Sprache die Sprache gewechselt. Eine kommunikative Funktion ist bei diesem (inter-sententialen) Switch nicht erkennbar.
[FB 1921_995]
molto soddisfatta del LERNGRUPPE!!!und jetzt weiter lernen, lernen und lernen!!
Zusammenfassend lässt sich festhalten, dass sich innerhalb der restlichen 32,25% der inter-sententialen Switches verschiedene Strategien erkennen lassen. Dazu gehört die Einleitung oder Zusammenfassung, deren kommunikative Funktionen von der Selbstdarstellung bis zu einem kreativen Gebrauch reichen. Aber auch Ausdrücke von Empfindungen oder Meinungen, beispielsweise in Form von Floskeln, werden durch einen Sprachwechsel markiert und dienen der persönlichen Positionierung. Zitate und idiomatische Ausdrücke hingegen dienen vor allem der Selbstdarstellung, können aber auch subjektive Empfindungen verdeutlichen oder werden schlicht und einfach in der Sprache, aus der sie kommen, angeführt. Manchmal dient der Sprachwechsel auch dazu, um eine bestimmte Gruppe von Facebook Freunde anzusprechen. CS markiert dabei einen Themenwechsel und stellt eine Distanzierung beziehungsweise Annäherung dar.
Nachdem nun einige Strategien innherhalb der Unterkategorie des inter-sententialen CS vorgestellt sowie deren Funktionen und Zwecke diskutiert wurden, soll es im Folgenden um das intra-sententiale CS gehen. Dabei wird auch hier zunächst ein Überblick gegeben und im Anschluss daran werden alle identifizierbaren Unterkategorien vorgestellt.
6.2.3. Intra-sententiales CS und dessen kommunikative Funktionen
Die insgesamt 987 gefundenen Okkurrenzen für intra-sententiales CS lassen sich in weitere Untergruppen unterteilen. Dabei wurde eine Aufteilung nach Insertion und Alternation gewählt, wie von Muysken vorgeschlagen wurden (siehe Kapitel ). Allerdings werden hier unter Insertion Einfügungen aller Art verstanden, also sowohl einzelne Inhaltswörter, wie Nomen, aber auch ganze Phrasen oder Konstituenten. Letztere jedoch nur, wenn diese einer anderen untergeordnet sind, wie beispielsweise eine Nominalphrase in einer Verbalphrase. Unter Alternation hingegen wird hier ein Wechsel von der einen in die andere Sprache aufgefasst, bei denen nur in eine Richtung gewechselt wird und wobei es sich um größere Einheiten handelt.
Zur Insertion werden Ein-Wort-Switches, die nur einzelne Wörter betreffen sowie wortinterne Switches gezählt. Die Switching Typen können wieder mit Hilfe von Korpusabfragen bestimmt werden. Wenn in den annotierten und tokenisierten Facebook Beiträgen ein einzelnes Token einen Sprach-Tag einer anderen Sprache trägt als der Rest des Satzes, dann wurde es als Ein-Wort-Switch markiert. So wird beispielsweise eine Abfolge nach dem Schema Token_it Token_it Token_de Token_it Token_it dazu gezählt.209 Aufgrund der POS-Tags, die den Token bei der Annotation zugewiesen wurden, können diese Switches dann nach Nomen, Eigennamen und anderen Wortarten sortiert werden.
Die Beispiele (118) und (119) werden demnach als Ein-Wort Switches kategorisiert. Sie enthalten Nomen aus der jeweils anderen Sprache. Während im Facebook Post in (118) die Anrede des Nutzers bellezza auf Italienisch in einen ansonsten auf Deutsch verfassten Satz eingefügt wird, wird in (119) der deutsche Eigennamen der Stadt München, für den es im Italienischen durchaus eine Entsprechung gäbe (it. Monaco), in einen ansonsten auf Italienisch verfassten Satz eingefügt. Diese Arten der Nomen-Switches sind sehr häufig im Korpus zu finden und werden deshalb in den Unterkapitel in Kapitel ausführlich besprochen.
[FB 1301116_141]
bellezza ich bin nächste woche wieder da?bist du noch da?bacione
[FB 162138_848]
[…] Tutto bene a München?
Die restlichen Switches werden weiter mit Hilfe von Korpusabfragen und einer manuellen Nachkontrolle sortiert.
| Statusmeldungen | Posts | Gesamt | |||||
| Anz. | % | Anz. | % | Anz. | % | ||
| Alternation | 41 | 9,98 | 39 | 6,77 | 80 | 8,11 | |
| davon: | Tag-Switching | 16 | 3,89 | 15 | 2,60 | 31 | 3,14 |
| andere | 25 | 6,08 | 24 | 4,17 | 49 | 4,96 | |
| Insertion | 370 | 90,02 | 537 | 93,23 | 907 | 91,89 | |
| davon: | Nomen | 134 | 32,60 | 201 | 34,90 | 335 | 33,94 |
| Eigennamen | 77 | 18,73 | 85 | 14,76 | 162 | 16,41 | |
| Anredeformen | 28 | 6,81 | 71 | 12,33 | 99 | 10,03 | |
| Wort | 49 | 11,92 | 63 | 10,94 | 112 | 11,35 | |
| Wortintern | 11 | 2,68 | 27 | 4,69 | 38 | 3,85 | |
| andere | 71 | 17,27 | 90 | 15,63 | 161 | 16,31 | |
| Gesamt | 411 | 100,00 | 576 | 100,00 | 987 | 100,00 | |
Zu der Unterkategorie der Alternation werden emblematische Switches gezählt, also Tag-Switches nach Muysken (siehe Kapitel ). Zu den Insertionen gehören die Switches, die Nomen, Eigennamen, Anreden oder Wörter anderer Wortarten betreffen sowie wortinterne Switches. Andere Sprachwechsel, die sich nicht diesen Kategorien zuordnen ließen, wurden entweder der Kategorie andere Insertion oder andere Alternation zugeordnet:
Insgesamt zeigt sich, dass die Insertion mit 91,89% weitaus häufiger in intra-sententialen Switches vorkommt als die Alternation (8,11%). Innerhalb der Insertion überwiegen vor allem die Ein-Wort-Switches. Die Nomen machen 33,94% aller intra-sententialen Switches aus, die Eigennamen 16,41% und die anderen Wort-Switches 11,35%. Von den nominalen Anredeformen werden wiederum 10,03% eingenommen. Der Anteil an wortinternen Switches ist wie erwartet gering. Es zeigt sich, dass es zudem noch einige weitere Alternationen (8,11%) und Insertionen (16,31%) gibt. Der Vergleich zwischen Statusmeldungen und Posts zeigt, dass bei den Posts der prozentuale Anteil an Insertionen sogar noch deutlich höher als bei den Statusmeldungen ist. Außerdem ist bei den Posts der Anteil an Anredeformen größer.
Im Folgenden sollen die einzelnen Unterkategorien genauer betrachtet werden. Dafür werden erst die Switches, die der Alternation zugerechnet wurden, betrachtet und anschließend die der Insertion. Für einige der Unterkategorien werden Wortlisten, die im Anhang der Arbeit zu finden sind, beschrieben und an ausgewählten Beispielen deren möglichen kommunikativen Funktionen abgeleitet.
6.2.3.1. Tag-Switching
Insgesamt lassen sich nur 31 Okkurrenzen für Tag-Switching finden, wobei die Anzahl in den Posts und Statusmeldungen fast gleich hoch ist. Folgende Tabelle zeigt, aus welchen Sprachen die Tags eingefügt werden, unterteilt in Token und Types (den unterschiedlichen Vorkommen der Token):210
| Anz. Token | Anz. Type | |
| de | 13 | 6 |
| it | 4 | 2 |
| en | 14 | 11 |
| Gesamt | 31 | 19 |
Ein Beispiel für einen typischen Tag-Switch stellt das Beispiel in (120) dar, bei dem ein Gesprächswort, hier scheisse, aus dem Deutschen an eine ansonsten auf Italienisch verfasste Statusmeldung angefügt wird.
[FB 1621_1445]
voglio il caffè…scheisse
Tag-Switches sind in den untersuchten gemischtsprachigen Beiträgen recht selten zu finden. Es gibt 13 Switches, bei denen Tags aus dem Deutschen entnommen werden, darunter 4 Okkurrenzen für scheisse und zwei für mann. Aus dem Italienischen werden 4 Tags in ansonsten auf anderen Sprachen verfasste Beiträge einfügt; bei 3 Okkurrenzen davon handelt es sich um che palle, wie das folgenden Beispiel zeigt:
[FB 1301179_29]
[…] hab mir was eingeklemmt im rücken und muss jetzt relativ starkes schmerzmittel nehmen… und aufgrund desssen langes autofahren vermeiden…che palle… jetzt musst mit mir beten, dass des im laufe der nächsten tage weg geht… […]
Die Anzahl an englischen Tags, wie yyessss in (122), ist mit 14 Okkurrenzen interessanterweise die höchste.
[FB 1112_101]
yyessss das ist ein Zitat!
Die geringe Anzahl an Tags lässt sich damit erklären, dass Beiträge nicht so spontan verfasst werden, wie es beispielsweise im Gesprochenen der Fall ist. Es werden seltener „Lückenfüller“ benötigt. Außerdem dienen die Beiträge nicht unbedingt dazu, einen Dialog zu initiieren, weshalb es kaum Zustimmungsfragen (en. recall) gibt. Wenn Tag-Switches verwendet werden, dann werden diese ganz bewusst eingesetzt und sogar durch eine Iteration von Buchstaben hervorgehoben, wie das Beispiel (122) demonstriert.
Über die kommunikative Funktion lässt sich aufgrund der geringen Anzahl kaum eine Angabe machen. Allerdings kann in allen drei hier präsentierten Beispielen eine emotionale Beteiligung ausgemacht werden, die mit den Tag-Switches untermauert wird.
6.2.3.2. Andere Alternationen
Die Anzahl anderer Alternationen ist im Korpus mit 4,96% aller intra-sententialen Switches ebenfalls recht gering. Dabei fällt auf, dass diese mit 25 Okkurrenzen in den Statusmeldungen fast genauso häufig verwendet werden wie in den Posts (24 Okkurrenzen).
[FB 2211209_820]
danke dir, that was really nice „grin“-Emoticon
[FB 1301157_626]
„heart“-Emoticon Habe gerade das Lied zufällig gehört ti ricordi „wink“-Emoticon
In ihrer Verwendung ähneln diese recht stark den inter-sententialen Switches. In manchen Fällen wird der Satzwechsel durch die Interpunktion deutlich gemacht. In anderen Fällen allerdings, wie in (124), stehen hier zwei Äußerungen nebeneinander, die zwar nicht graphematisch voneinander getrennt sind, bei denen aber auch die grammatischen Strukturen am Wechsel beteiligt sind (siehe Kapitel ).
Um den Anteil der kommunikativen Funktionen bestimmen zu können, ist die Anzahl in diesem Korpus zwar zu niedrig, allerdings kann aufgrund ihrer Struktur davon ausgegangen werden, dass diese den Funktionen des inter-sententialen CS ähneln, wie in Kapitel vorgestellt. Ausgenommen werden hierbei allerdings die Strategien der Wiederholung und Grußformeln und deren Funktionen, für die sich innerhalb der Gruppe der Alternationen keine Belege finden lassen.211
6.2.3.3. Nomen-Switching
Als Nomen-Switches werden nur einzelne Nomen markiert, die in einen ansonsten auf einer anderen Sprache verfassten Satz eingefügt werden.212 Es lassen sich insgesamt 335 Nomen-Switches innerhalb der gemischtsprachigen Beiträge feststellen. Dabei werden 201 in Posts und 134 in Statusmeldungen verwendet. In Anhang 3 werden die Nomen nach Sprachen sortiert wiedergegeben, inklusive ihrer Okkurrenzen. Tabelle 48 zeigt eine Übersicht der Anzahl an Token sowie der Types:
| Anz. Token | Anz. Type | |
| de | 139 | 112 |
| it | 47 | 34 |
| en | 134 | 102 |
| ot | 15 | 11 |
| Gesamt | 335 | 258 |
Aus der Tabelle geht hervor, dass die größte Anzahl an Nomen aus dem Deutschen stammt (139 Token). Bis auf wenige Ausnahmen werden diese deutschen Nomen in ansonsten auf Italienisch verfasste Äußerungen eingefügt. Dabei gibt es 112 verschiedene Types unter den Nomen aus dem Deutschen. Das bedeutet zwar, dass die meisten Token nur einmalig verwendet werden, einige aber durchaus auch wiederholt im Korpus vorkommen. Die Anzahl der italienischen Token, die in ansonsten anderssprachige Beiträge eingefügt werden, ist deutlich kleiner (47 Token). Die Basissprache ist dabei meist Deutsch, kann aber auch Englisch sein. Auffällig ist bei diesem Switching Typ schließlich die hohe Anzahl der englischen Nomen, die sowohl in deutschen als auch italienischen Beiträgen verwendet werden.
Zu den Nomen aus dem Deutschen, die in den gemischtsprachigen Beiträgen verwendet werden, zählen Bezeichnungen für kulinarische Spezialitäten, die typisch für Deutschland sind, wie Glühwein (7 Okkurrenzen), Currywurst (2 Okkurrenzen) oder Kartoffelsalat (2 Okkurrenzen). Ebenfalls zu dieser Gruppe können Apfelsaft, Kässpätzle, Kölsch, Bier, Laugenstange, oder Nudeln gerechnet werden (je eine Okkurrenz). Aber auch andere für Deutschland und die deutsche Kultur als typisch angesehene Dinge, für die es teilweise keine italienische Übersetzungen gibt, werden auf Deutsch verwendet: Biergarten, Dirndl, Fundbüro, Kanzlerin, Mauerfall, Mitfahr ‚Mitfahrgelegenheit‘, Adventskalender, Stammtisch und andere (je eine Okkurrenz).
[FB 192194_1865]
[…] Oggi ho iniziato a ricevere la prime minacce di morte al lavoro… Altro che Biergarten, domani mi chiudo in casa! […]
Es gibt des Weiteren Nomen, für die es zwar im Italienischen eine Entsprechung gäbe, bei denen aber das Konzept von dem des Deutschen abweicht. Dazu gehört beispielsweise die WG ‚Wohngemeinschaft‘ (3 Okkurrenzen, und zusätzlich 4 Okkurrenzen für wg-party und eine Okkurrenz für wg-sucher).
Interessant ist auch die Verwendung von Wortschatz, der sich auf das deutsche Bildungswesen bezieht, und für den es eigentlich immer eine italienische Entsprechung gäbe: Referat und Universität (je 2 Okkurrenzen) sowie Ausbildung, Labor, Praktikum, Prüfung, Statistik (je eine Okkurrenz).
[FB 2211_1195]
But where is the EICHHÖRNCHEN??? „wink“-Emoticon [NAME]
Eichhörnchen (2 Okkurrenzen) in (126) spiegelt schließlich einen spielerischen Gebrauch von CS wider, da dieses Wort in Italien häufig dazu verwendet wird, um die schwierige oder gar unmögliche Aussprache des Deutschen zu demonstrieren.
Italienische Nomen lassen sich deutlich weniger finden. Als nicht übersetzbare Bezeichnungen kann squillo ‚Anklingeln auf dem Handy‘(2 Okkurrenzen) angeführt werden.
[FB 231079_169]
… squillo vergessen… sorry!!!!!!!!
Nomen, die typische Gerichte oder Dinge Italiens oder der italienischen Kultur bezeichnen, können auch ausgemacht werden, beispielweise bistecca, café, palazzo, sagre, centro (je eine Okkurrenz). Bezeichnungen des italienischen Bildungswesens sind ebenfalls seltener, werden aber durchaus verwendet, wie tesi, esami und discusione (je eine Okkurrenz) zeigen.
Wie schon in Kapitel gesehen, ist eine Unterscheidung zwischen Entlehnung und CS nicht immer einfach. Als ein Kriterium zur Bestimmung von Entlehnungen wurde die Assimilation genannt. In einigen Fällen könnte die graphematische Assimilation berücksichtigt werde: Tandem-Partner in (128), in dem das deutsche Nomen mit Großbuchstaben (und nach den Regeln der morphologischen Komposition im Deutschen) wiedergegen wird, stellt ein gutes Beispiel für CS dar.
[FB 1021134_348]
Ciao „smile“-Emoticon hehe …veramente non posso parlare in italiano, ma d’ora in avanti siamo Tandem-Partner …
Im Umkehrschuss kann aber nicht davon ausgegangen werden, dass es sich bei einer Kleinschreibung von deutschen Nomen in italienischen Beiträgen um Entlehnung handelt, da eine durchgängige Kleinschreibung ein Merkmal der CMC darstellt (siehe Kapitel ). In Kapitel wurde gezeigt, dass aber auch eine Assimilation, die am Genus von Artikel und Nomen erkennbar ist, als ein Kriterium zur Differenzierung dienen kann. In nur wenigen Fällen konnten allerdings Okkurrenzen gefunden werden, in denen sich das Genus des deutschen Nomens von dem des Italienischen unterscheidet. So kann danach festgestellt werden, dass es sich bei il Tisch in (129) um CS handelt (it. la tavola, Femininum, de. der Tisch, Maskulinum).
[FB 102130_432]
alberto siamo nella scheiße piè totale.. da sabato siamo senza Stühle, la tipa ci lascia solo il Tisch x 15 €!! conviene secondo te poi comprarlo?? io rimango pure senza letto, vedi te.. scheiße scheiße schieße und noch scheiße!!!
In den meisten Fällen handelt es sich nach dem eben genannten Kriterium jedoch eher um Entlehnungen, wie in (130) und (131). In dem ersteren Beispiel könnte aufgrund der fehlenden graphematischen Assimilation auch für CS plädiert werden, in Letzterem spricht der von dem deutschen Nomen getriggerte Sprachwechsel ebenfalls eher für CS.
[FB 162177_1481]
ricevuto l´überweisung…ex ladrona „smile“-Emoticon ehehehe
[FB 1921_995]
molto soddisfatta del LERNGRUPPE!!!und jetzt weiter lernen, lernen und lernen!!
Schlussendlich kann bei vielen Nomen gar keine Assimilation festgestellt werden. Auch das Kriterium der Frequenz ist unzureichend, da die Nomen aufgrund des relativ kleinen Umfangs des Facebook Korpus nur sehr selten im Korpus zu finden sind (in den meisten Fällen gibt es nur eine Okkurrenz). So ist eine Entscheidung bei den meisten deutschen und italienischen Nomen alles andere als einfach und eine genauere Betrachtung auch im Vergleich mit einem anderen Korpus deutsch-italienischer CMC wäre hilfreich. Obwohl in einigen Fällen sicher für Entlehnung plädiert werden könnte, soll hier deren Definition als CS Vorzug gegeben werden.
Etwas anders verhält es sich mit den englischen Nomen. Deren Anzahl ist in deutschen und italienischen Beiträge im Verhältnis zur allgemeinen Sprachverteilung im Korpus ziemlich groß. Die Verwendung von englischen Nomen stellt sehr oft Entlehnung dar. Hierunter fallen viele Nomen, die schon in das Lexikon sowohl des Deutschen als auch des Italienischen übernommen wurden. Dazu gehören shopping (9 Okkurrenzen), news (6 Okkurrenzen), relax und tour (je 4 Okkurrenzen).213 Es gibt auch einige technische Termini, wie picture, app, conference call oder network, die sich vor allem mit ihrer Verwendung innerhalb der CMC erklären lassen. Nur in einigen wenigen Fällen lassen sich englische Nomina nicht in den Lexika des Deutschen oder Italienischen finden. So kommt teacher nur einmal im Korpus vor und ist nicht morphologisch assimiliert, weshalb hier eindeutig von CS die Rede ist.
Die Funktionen der Nomen-Switches sind folglich unterschiedlich. Es konnte gezeigt werden, dass es sich hier häufig um Fälle handelt, in denen es keine Entsprechung des Wortes (oder aber des Konzepts) in der anderen Sprache gibt, also eine lexikalische Notwendigkeit vorliegt. Zum anderen werden die Nomen auch verwendet, wenn sie mit dem Land und dessen Sprache assoziiert werden können. Hier drückt der Sprachwechsel die Zugehörigkeit hierzu aus. Dazu lassen sich auch die Nomen, die beispielsweise mit dem akademischen Umfeld zu tun haben, zählen: so kann in Beispiel (132) davon ausgegangen werden, dass die Prüfung an einer deutschen Bildungseinrichtung abgeschlossen wurden, wie auch der darauf folgende Satz verrät.
[FB 192175_1327]
Tesorooo! e allora, die letzte Prüfung, com’è andato???!!!! goditi gli ultimi giorni d Halleeeee! tvb! e a domenica! „grin“-Emoticon
Es sei noch anzumerken, dass es vor allem die Nutzer 1021, 1621, 1824 und 1921 sind, die Nomen-Switches verwenden. Bei diesen überwiegt in ihrer Sprachverwendung das Italienische (siehe Kapitel und Kapitel ), weshalb es schließlich nicht verwunderlich ist, dass so viele deutsche Nomen in ansonsten auf Italienisch verfasste Beiträge eingefügt werden. Außerdem handelt es sich bei diesen Nutzern auch um diejenigen, die häufiger intra-sententiales CS verwenden, wobei es sich dabei um viele Nomen-Switches handelt (siehe Kapitel ).
6.2.3.4. Eigennamen
Zu der Kategorie der geswitchten Nomen lassen sich auch die Eigennamen zählen.214 Insgesamt gibt es 162 Eigennamen, die in einen ansonsten auf einer anderen Sprache verfassten Satz eingefügt werden. Davon lassen sich 77 in Statusmeldungen und 85 in Posts ausmachen. In Anhang 3 werden alle Eigennamen nach Sprache sortiert aufgelistet. Vor allem deutsche Eigennamen werden häufig in ansonsten auf Italienisch verfassten Beiträgen verwendet, wie die 93 Okkurrenzen belegen. Aber auch italienische Eigennamen werden mit 42 Okkurrenzen häufig verwendet. Interessanterweise spielen hier englische Eigennamen – im Vergleich zu den Nomen-Switches – eine deutlich untergeordnete Rolle.
Bei den Eigennamen handelt es sich meist um geographische Bezeichnungen.215 Insbesondere Städte- oder Ländernamen, aber auch Bezeichnungen für Zugstationen, Sehenswürdigkeiten oder Straßennamen, spielen hierbei eine Rolle.
| Anz. Token | Anz. Type | |
| de | 93 | 27 |
| it | 42 | 15 |
| en | 13 | 5 |
| ot | 9 | 8 |
| Gesamt | 157 | 55 |
Die Eigennamen für die Städte München (16 Okkurrenzen) und Köln (10 Okkurrenzen und zusätzlich weitere 5 für Kölle) werden besonders häufig verwendet, aber auch Berlin (8 Okkurrenzen) und Frankfurt (5 Okkurrenzen) tauchen oft auf. Deutschland wird in italienischen Beiträgen zehnmal verwendet. Und schließlich lassen sich auch für das Oktoberfest 12 Okkurrenzen im Korpus finden.
Italienische Städtenamen werden ebenfalls recht häufig in deutsch- oder englischsprachigen Beiträgen verwendet, wie beispielsweise Milano (5 Okkurrenzen), Napoli (4 Okkurrenzen), Firenze und Roma (jeweils 3 Okkurrenzen). Vor allem die Bezeichnung für das Land Italia (9 Okkurrenzen) ist häufig zu finden. In die Liste aufgenommen wurde auch die Bezeichnung bella Italia, die als feste Phrase fast ebenso oft in den gemischtsprachigen Beiträgen vorzufinden ist (8 Okkurrenzen), wie Beispiel (133) zeigt:
[FB 1112_276]
nur noch vier Tage in München-dann fahr ich wieder nach bella Italia! „smile“-Emoticon
Die Verwendung von geographischen Bezeichnungen könnte damit begründet werden, dass der Nutzer diese als Eigennamen fest mit der bezeichneten Lokalität verbunden sieht und eine Substitution dieser eine Art Distanzierung oder Objektivierung darstellen würde (einen Giuseppe würde man im Deutschen wohl auch nicht Josef rufen).
Ob bei Facebook Beiträgen insgesamt Eigenamen, bei denen es eine Entsprechung gibt, bevorzugt in der Landessprache verwendet werden, zeigt ein Vergleich. Die Distribution der deutschen Entsprechung für Italia, also Italien, zeigt, dass es in den komplett auf Deutsch verfassten Beiträgen 26 Okkurrenzen für Italien gibt, während es in den gemischtsprachigen Beiträgen, bei denen Deutsch die Basissprache darstellt, 9 Okkurrenzen für Italia gibt. Dies kann den Schluss nahe legen, dass Eigennamen tatsächlich häufig in der Sprache ihres Landes verwendet werden. Allerdings gibt es für die italienische Entsprechung für Deutschland, also ‚Germania‘, 43 Okkurrenzen in den komplett auf italienischverfassten Beiträgen, während sich in den gemischtsprachigen Beiträgen mit 10 Okkurrenzen deutlich weniger finden lassen. Es kann hiermit widerlegt werden, dass Eigennamen präferiert in ihrer Herkunftssprache verwendet werden. Trotzdem ist eine Tendenz erkennbar und die kommunikative Funktion des Sprachwechsels als Widerspiegelung einer Zugehörigkeit und zum Ausdruck einer persönlichen Positionierung erscheinen plausibel.
Auch externe Faktoren, wie eine Reise oder der Aufenthalt in einem bestimmten Land, beeinflussen nicht die Sprachwahl bei den Eigennamen. In (134) wird eine Reise nach Deutschland angekündigt, wobei der Ländernamen einen Switch darstellt. In (135) handelt es sich auch um eine Reiseankündigung, bei der allerdings kein CS stattfindet.
[FB 1921_1003]
si riparte verso la Deutschland!!![…]
[FB 2211_318]
tra poco deve ritornare in Germania.. „frown“-Emoticon
Ein weiterer Grund könnte schließlich mit der primären Funktion der Selbstpräsentation in Facebook Beiträgen zusammenhängen: der Nutzer möchte demonstrieren, dass er sich mit den Ländern und Städten gut auskennt und somit seine Weltoffenheit beweisen. Dafür sprechen auch die Bezeichnungen auf Englisch oder anderen Sprachen in ansonsten auf Deutsch oder Italienisch verfassten Beiträgen: zum Beispiel Italy (7 Okkurrenzen) und Germany (3 Okkurrenzen).
Interessant ist des Weiteren die Verwendung von Genua, der deutschen Bezeichnung für it. ‚Genova‘ in einem italienischen Beitrag. Ebenso lassen sich italienische Bezeichnungen für die deutschen Städte Francoforte (2 Okkurrenzen) und Monaco (1 Okkurrenz) in deutschsprachigen Beiträgen finden. Während es sich bei Genua auch um die lateinische Bezeichnung der Stadt handeln, und Monaco auf das in Italien liegende Fürstentum referieren könnte, ist der Fall von Francoforte nicht so eindeutig, und der Gebrauch lässt sich am ehesten durch eine kreative und spielerische Sprachverwendung erklären.
[FB 2211255l_8]
[NAME] so gut dass du da warst!!! und ich erinner mich so gut an dich! „grin“-Emoticon oh man muss dich echt ganz bald besuchen kommen, du fehlst hier in heidi so!!! hoff du bist gut nach hause gedüsert am freitag! biggest baci nach francoforte! „heart“-Emoticon
Es sei noch kurz darauf eingegangen, wieso Eigennamen hier als CS und nicht als Entlehnungen bewertet werden. Obwohl deren Frequenz im Korpus recht hoch ist, sind sie nicht morphologisch in die andere Sprache integriert worden. Und auch deren Status in der jeweiligen anderen Sprache spricht eher dafür, diese als CS und nicht als Lehnwörter zu bewerten.
Zu guter Letzt soll noch beantwortet werden, warum diese hier dargestellten Eigennamen-Switches an sich schon eine Ausnahme darstellen. Im Normalfall gelten Eigennamen als unübersetzbar und es gibt nur für große und (historisch) wichtige Städte Entsprechungen in der jeweils anderen Sprache. So können die meisten Städtenamen, wie Hannover, Sindelfingen, Dachau etc. im Deutschen und Palermo, Bari, Pavia, etc. im Italienischen, gar nicht in einer anderen Sprache wiedergegeben werden und können somit nicht Gegenstand von Eigennamen-Switches werden. Aber gerade deshalb ist die Verwendung von Eigennamen, für die es Entsprechungen in anderen Sprachen gibt, so interessant und lässt darauf schließen, dass diese von den Nutzern bewusst als Strategie eingesetzt werden, um bestimmte kommunikative Funktionen zu erfüllen. Dazu zählt das Signalisieren der Zugehörigkeit zu und der Verbundenheit mit einem Land, einer Stadt, der Sprache und der Sprecher. Auch die Selbstdarstellung kann ein Grund dafür sein.
6.2.3.5. Anredeformen
Insgesamt lassen sich 99 Okkurrenzen für Anredeformen finden, die in Anhang 3 aufgelistet werden. Wie zu erwarten, gibt es in Posts mit 71 Okkurrenzen deutlich mehr Anredeformen als in Statusmeldungen (28 Okkurrenzen).
| Anz. Token | Anz. Type | |
| de | 31 | 11 |
| it | 40 | 20 |
| en | 12 | 6 |
| ot | 16 | 10 |
| Gesamt | 99 | 47 |
Als Anredeformen innerhalb der Gruppe des intra-sententialen CS zählen nominale Anredeformen, wie in Beispiele (137), die innerhalb der Satzgrenzen verwendet werden.
[FB 210163_465]
Frau vi sto aspettando, sono pronta!!!
Es können 31 Okkurrenzen für deutsche Nomen und Nominalphrasen, die der Anrede dienen, gefunden werden. Bei 21 davon handelt es sich um das Token frau, das in einem ansonsten auf Italienisch oder Englisch verfassten Beitrag verwendet wird. Alle anderen Anredeformen tauchen nur einmalig in den gemischtsprachigen Beiträgen auf, wie schatz, süße, kleine, aber auch Pluralformen, wie leute, mädels, sturmtruppen, die vor allem in Statusmeldungen verwendet werden, während der Rest Facebook Posts entstammt.
Italienische Nomen der Anrede sind mit 40 Okkurrenzen frequenter. Davon ist bella mit 6 Okkurrenzen die am häufigsten gewählte Anredeform. Aber auch bellezza (3 Okkurrenzen), bellissima und bella mia (je eine Okkurrenz) sind vertreten. Hier werden zudem Pluralformen eher in Statusmeldungen verwendet, wie amiche (4 Okkurrenzen). Auffällig ist, dass hier bis auf fratellino und pacconaro (je eine Okkurrenz) alle Formen weibliche Nutzer ansprechen.
Außerdem gibt es auch noch einige englische (12 Okkurrenzen) und anderssprachige Anredeformen (16 Okkurrenzen), wobei bei Letzteren 10 aus dem Spanischen stammen, wie beispielsweise hermanita (4 Okkurrenzen).
Die primäre Funktion dieser Anredeformen ist natürlich das Adressieren einer bestimmten Person. Deshalb sind auch diese Formen, wie auch die inter-sententialen Grußfloskeln, öfter in den Facebook Posts zu finden, die den Nutzer direkt ansprechen. Da diese meist in der weiblichen Form verwendet werden, heißt das entweder, dass es sich bei den Nutzern vor allem um Nutzer des weiblichen Geschlechts handelt (was für die Nutzer, die Angaben zu ihrem Geschlecht gemacht haben, bestätigt werden kann, siehe Kapitel ), oder, dass vor allem bei Nutzern weiblichen Geschlechts nominale Anredeformen verwendet werden. Dass diese in einer anderen Sprache verwendet werden, lässt sich auch hier wieder damit erklären, dass eine Annäherung bezweckt werden soll, um eine Zusammengehörigkeit zu demonstrieren.
6.2.3.6. Andere Ein-Wort-Switches
Von den verbleibenden 112 Ein-Wort-Switches, bei denen es sich nicht um Nomen, Eigennamen oder Anreden handelt, werden 49 in Statusmeldungen und 63 in Posts verwendet. Interessanterweise stammt die Mehrheit davon aus dem Englischen. Eine Übersicht dieser Wörter nach Sprachen sortiert und mit der Angabe der Anzahl befindet sich in Anhang 3. Diese englisch-stämmigen Wörter werden sowohl in ansonsten italienische, als auch deutsche Sätze eingefügt. Dabei überwiegen allerdings die Switche ins Italienische.
| Anz. Token | Anz. Type | |
| de | 22 | 17 |
| it | 11 | 1 |
| en | 69 | 43 |
| ot | 10 | 10 |
| Gesamt | 112 | 71 |
Für Ein-Wort-Switches aus dem Deutschen gibt es 20 Okkurrenzen. Bitte, dabei (siehe (138)) und danke werden je zweimal in ansonsten auf Italienisch verfassten Beiträgen verwendet.
[FB 162177_351]
domani verso le 9 vado alla festa di compleanno di una mia amica peruviana, beviamo li qualcosina e poi andiamo al flanagans e poi venerdi anche loro vogliono fare il grill…saremo un gruppo enorme…questo é il mio programma per domani, fammi sapere se sei dabei!beso d
Auch in anderen Okkurrenzen überwiegen Inhaltswörter wie Adjektive, Adverbien (fleißig, überwältigend, wunderschön, je eine Okkurrenz), die zumeist in italienischen Sätzen verwendet werden. Funktionswörter gibt es nur sehr wenige (ein und und, je 1 Okkurrenz).
Ein-Wort-Switches aus dem Italienischen lassen sich noch seltener feststellen. Dabei handelt es sich in allen Fällen um Inhaltswörter: z.B. bellissimi, brillo, sciare (je 1 Okkurrenz). Schließlich gibt es auch noch einige Ein-Wort-Switches aus anderen Sprachen. Dabei handelt es sich vornehmlich um Wörter des Grüßens, die innerhalb einer Grußformel verwendet werden (beispielsweise adieu, adios, bonjour).
Bei den englischen Ein-Wort-Switches handelt es sich bei den meisten um Inhaltswörter, davon sind 5 Verben, der Rest Adjektive und Adverbien. Es lassen sich nur sehr wenige Funktionswörter ausmachen wie not und to. Bei den Inhaltswörtern ist wieder die Unterscheidung zwischen CS und Entlehnung relevant. Da aber einige schon allein im Korpus häufig auftreten (sorry 10 Okkurrenzen, please 7 Okkurrenzen, busy und together je 4 Okkurrenzen), kann hierbei von Entlehnungen ausgegangen werden. Auch deren Status im Italienischen und Deutschen spricht dafür, ebenso wie die morphologisch Assimilation, die in einigen Fällen vorliegt, wie relaxxen im folgenden Beispiel:
[FB 1112_348]
In apuglien am Meer relaxxen „smile“-Emoticon
Bei den Ein-Wort Switches aus anderen Sprachen ist eine Abgrenzung schwierig. Allerdings spricht die geringe Frequenz schon einmal gegen eine Klassifikation als Entlehnungen, genauso wie die fehlende Assimilation. Interessant ist hier auch die Wortstellung bei dialect „napoletano“ in (141). Zwar werden aus der anderen Sprache übernommene Wörter mit Anführungszeichen markiert, zudem wird aber auch die Wortstellung Nomen Adjektiv aus dem Italienischen mit übernommen.
[FB 1621_3057]
Here we are. A strange true story about a „palombo“ and Carmelina. What did happen to Carmelina? She wrote something in her dialect „napoletano“ for all the people living in the same place. What is a „palombo“? and what are „middiche“? let´s get into the secret of the italian dialect of Neaples…
Die Funktionen sind bei diesen Switches wenig transparent. In einigen Fällen, wie in (141), handelt es sich offensichtlich um Zitate, bei denen die Selbstdarstellung sowie die persönliche Positionierung als Gründe genannt werden können. Auch ein kreativer Gebrauch der Sprache kann hier eine Rolle spielen. Ein weiteres Beispiel für diesen kreativen Gebrauch wäre das folgende Beispiel:
[FB 1621_2814]
Lasagnando for my italian family „smile“-Emoticon
Hierbei wird an ein italienisches Nomen eine Gerundiumendung angehängt, um damit eine Handlung zu beschreiben.216 Das verdeutlicht den bewussten Einsatz der Sprache und auch des darauf folgenden Sprachwechsels. In anderen Fällen, wie in (138), bleibt der Grund des Wechselns unklar.
6.2.3.7. Wortinternes Switching
Es lassen sich auch insgesamt 38 Beispiele für wortinternes Switching finden. Diese überwiegen dabei mit 27 Okkurrenzen in den Posts, während sich nur 11 in den Statusmeldungen finden lassen. Diese Switches erfolgen auf verschiedenen Ebenen der Morphologie. So stellen sie sowohl Flexionsformen als auch Wortbildungsphänomene dar.
Bei den wortinternen Switches handelt es sich häufig um Flexionen, bei denen an einen Flexionsstamm aus der einen Sprache eine Flexionsendung aus der anderen Sprache angehängt wird.
| Sprache des Flexionsstamms | Sprache der Endung | Anz. | ||
| Verbflexion | druecko | de | it | 1 |
| speicherati | de | it | 1 | |
| vermissiamo | de | it | 1 | |
| relaxen* | en | de | 1 | |
| rockst* | en | de | 1 | |
| flippi | en | it | 1 | |
| lovvo | en | it | 4 | |
| mixa | en | it | 1 | |
| Deklinationen | geilo | de | it | 1 |
| spassive | de | it | 1 | |
| answerino | en | it | 5 | |
| cooler* | en | de | 1 | |
| tedeschen | it | de | 1 | |
| bacios | it | de | 1 |
So wird beispielsweise an das deutsche Verb drücken die italienische Endung für die erste Person Singular angehängt, wie das Beispiel (142) zeigt. Auch bei speicherati in Beispiel (143) handelt es sich um das deutsche Verb speichern, dem nicht nur die italienische Imperativendung, sondern zudem auch noch das Pronomen ti angehängt wird.
[FB 1621268_727]
[…]ti druecko fest „tongue“-Emoticon […]
[FB 162138_1310]
[…] t’ho detto 20 volte speicherati i numeri […]
Auch bei Deklinationen von Adjektiven und Nomen lassen sich wortinterne Switches finden, wie in dem folgenden Beispiel, bei dem an ein deutsches Adjektiv oder Nomen (‚Spaß‘ oder ‚spaßig‘) eine italienische Adjektivendung angehängt wird:
[FB 162177_183]
[…]ho delle nuove proposte interessanti per te…sia lavorative che „spassive“ ( bella sta nuova parola coniata,no?) […]
Interessant dabei ist auch, dass der Verfasser dieses Facebook Posts in einem Hinweis in Klammern sogar ergänzt, dieses Wort neu geprägt zu haben. Am häufigsten sind schließlich wortinterne Switches, bei denen der Flexionsstamm aus dem Englischen stammt und an den eine italienische oder deutsche Endung angehängt werden.
Des Weiteren gibt es auch Fälle, in denen von einer Derivation zu sprechen ist. Dabei wird an eine Derivationsbasis aus der einen Sprache ein Affix aus einer anderen Sprache angehängt.
| Sprache der Derivationsbasis | Sprache des Affixes | Anz. | |
| skypare* | en | it | 1 |
| skypen* | en | de | 2 |
| skypiamo* | en | it | 2 |
| chattiamo* | en | it | 1 |
| googlato* | en | it | 1 |
| sprizziamo | ? | it | 1 |
Als Basis werden hier vor allem englischstämmige Lexeme aus dem Computerjargon verwendet wie Skype, Chat oder Google, an die ein Affix aus dem deutschen oder italienischen angehängt wird. Bei allen so gebildeten Derivaten handelt es sich schließlich um Verben. Einen Zweifelsfall stellt sprizziamo dar: es ist zwar klar, dass es sich hierbei um ein Derivat handelt, bei der die Bezeichnung des Getränkes ‚Spritz‘ die Derivationsbasis darstellt, aber da es sich um einen Eigennamen handelt, der ein Getränk italienischer Herkunft bezeichnet, ist sein Status als wortinterner Switch unsicher. Aufgrund der abweichenden Schreibweise kann allerdings vermutet werden, dass das Deutsch anmutende Wort „italianisiert“ wurde.219
Es können zudem auch noch Kompositionen innerhalb der Gruppe der wortinternen Switches gefunden werden:
| Sprache des Determinans | Sprache des Determinatum | Anz. | |
| businesstag | en | de | 1 |
| derbytag | en | de | 1 |
| guinesslandia | (en) | it | 1 |
| hallewood | (de) | en | 1 |
| Riesen-bacio | de | it | 1 |
| tatenwochenende | it | de | 1 |
Bei allen Determinativkomposita handelt es sich um Prädeterminationen, wie sie eher in den germanischen Sprachen vorkommen. Auch hier spielt häufig das Englische eine Rolle. Besonders interessant sind die kreativen Wortbildungen bei tatenwochenende (it. tata ‚Kindermädchen‘) und Guinesslandia.220
Schließlich gibt es noch Switches, die zu der Kategorie der wortinternen Switches gezählt wurden, die sich aber keiner der oben genannten Gruppen zuordnen lassen: apuglien, batscho, HalloWien und baciodalass. Bei dem ersten Token kann es sich um eine Mischung aus der italienischen Bezeichnung puglia und des deutschen Apulien handeln. Es könnte sich aber durchaus auch um einen Schreibfehler handeln. Bei dem zweiten wird die italienische Aussprache für bacio mit der dafür im deutschen entsprechenden Orthographie dargestellt und auch bei HalloWien handelt es sich um ein Wortspiel, bei dem das englische Halloween durch die Kombination deutscher Wörter dargestellt wird.
[FB 1112_361]
buon HalloWien!!!
Der Beitrag wurde auch tatsächlich am 31.10.2011 verfasst, aber leider wird nicht klar, ob sich der Nutzer an diesem Datum auch wirklich in Wien aufgehalten hat. Es handelt sich hierbei also um die Darstellung von Wörtern aus der anderen Sprache auf phonologischer Ebene, weshalb diese wohl eher nicht zu dieser Kategorie gerechnet werden sollten. Das letzte Beispiel stellt einen wortinternen Switch innerhalb eines Inflektivs (siehe Kapitel ) dar:
[FB 2211255l_592]
*baciodalass* „smile“-Emoticon
Der Status dieser Belege als wortinterne Switches ist folglich umstritten. Trotzdem lässt sich an ihnen ein besonders kreativer und spielerischer Gebrauch der Sprache erkennen.
Zusammenfassend kann gesagt werden, dass sich wortinterne Switches in Facebook Beiträgen feststellen lassen. Diese können unterschiedlicher Art sein und verschiedene Sprachkombinationen beinhalten. Allerdings spielt häufig das Englische eine wichtige Rolle. Vor allem bei den Flexionsformen ist es schwierig zu unterscheiden, ob es sich hierbei nicht auch um Entlehnungen handeln könnte. Dafür spricht die Assimiliation, die hier bei allen gegeben ist. Und auch nach deren Status im deutschen oder italienischen Lexikon sind relaxen, rockst und cooler sowie fast alle wortinternen Switchs in Tabelle 53 Entlehungen (mit * in den entsprechenden Tabellen markiert). Bei lovvo bestätigt das auch die hohe Anzahl an Okkurrenzen bei verschiedenen Nutzern. Bei den anderen wortinternen Switches lässt sich allerdings ein spielerischer und kreativer Umgang mit diesem Typ des Sprachwechsels beobachten. Das spricht für eine gewollte Verwendung und eine bewusst eingesetzte Strategie dieser Form des CS, weshalb in vielen Fällen hier tatsächlich von wortinternem CS gesprochen werden kann.
6.2.3.8. Andere Insertionen
Bei Insertionen handelt es sich im Allgemeinen um Einfügungen. Ein-Wort-Switches (Nomen, Eigennamen und andere) wurden schon in den vorangehenden Kapiteln vorgestellt. Schließlich lassen sich auch noch insgesamt 161 weitere Insertionen in den intra-sententialen Switches ausmachen. Dabei können in den Statusmeldungen 71 Okkurrenzen gefunden werden, während es in den Posts mit 90 Okkurrenzen etwas mehr sind.
Bei den meisten Switches dieser Art werden Phrasen in eine übergeordnete Konstituente eingefügt.
[FB 1921_385]
waiting for l’invasione a casa [NAME]…
[FB 1921512_1221]
amore mi manchi!!!! quando ci vediamo on skype??? hai già iniziato lo stage?? love u [
In Beispiel (147) wird die Nominalphrase l’invasione a casa [NAME] eingefügt, während es sich in (148) bei on skype um eine Präpositionalphrase handelt. Die Nominalphrasen sind dabei die am häufigsten verwendeten Typen bei der Insertion, aber es lassen sich auch viele Präpositionalphrasen finden. Phrasen anderer Art, wie die Adjektivphrase guten rutsch in (149), sind deutlich seltener.
[FB 2211150_333]
„heart“-Emoticon cara, ti auguro un guten rutsch „wink“-Emoticon trinksch abba net zu viel, gell? „wink“-Emoticon baci e salutami anche la tua sorella
Zu dieser Unterkategorie werden aber auch noch Fälle, wie (150) und (151), gerechnet, bei denen keine Basissprache erkennbar ist. Insgesamt lassen sich hiefür 15 Okkurrenzen finden.
[FB 1921_2074]
Gluehwein time!
[FB 1021_190]
stasera Mittwoch?!
Das unterscheidet diese Switches von den eben genannten Insertionen, bei denen ganze Phrasen in einen ansonsten auf einer anderen Sprache verfassten Satz eingefügt werden. Aber ebenso unterscheidet sie das auch von den Ein-Wort-Switches, denen sie nach einem formalen Gesichtspunkt zugeordnet werden müssen (schließlich weicht hier nur die Sprache eines Wortes ab).
Das zeigt also, dass sich die restlichen Insertionen vor allem auf Phrasenebene gliedern lassen, bei denen vor allem NPs und PPs in ansonsten auf anderen Sprachen verfasste VPs eingefügt werden. Aber es gibt auch Switches, bei denen aufgrund der Unmöglichkeit der Identifizierung einer Basissprache keine Richtung des Switchings fesgestellt werden kann. Die kommunikativen Funktionen können hier weit gefächert sein. Gerade die zuletzt genannten Insertionen sind häufig auf einen spielerischen, kreativen Sprachgebrauch zurückzuführen. Aber auch bei anderen Insertionen ist dies oft der Fall. Es handelt sich in einigen Fällen auch um Routineformeln, wie in (149), die in einen ansonsten auf einer anderen Sprache verfassten Beitrag eingefügt werden. Vorstellbar ist hier, dass der Sprachwechsel sich hier erneut auf die Selbstdarstellung zurückführen lässt.
6.2.4. Übersicht der Ergebnisse
Es konnte gezeigt werden, dass inter-sententiales CS in der Gesamtanzahl aller Beiträge überwiegt. Zwar ist der prozentuale Anteil nur knapp über dem des intra-sententialen CS, allerdings zeigt die Verteilung nach Nutzern, dass bis auf ein paar Ausnahmen die meisten Nutzer inter-sententiales CS bevorzugen (siehe Kapitel ). Innerhalb der Statusmeldungen ist ebenfalls die Anzahl der inter-sententialen Switches höher, während bei den Posts die intra-sententialen Switches leicht überwiegen.
In der folgenden Tabelle sind die Ergebnisse der strukturellen Typisierung des CS noch einmal zusammengefasst:
| Statusmeldungen | Post | Gesamt | ||||||
| Anz. | % | Anz. | % | Anz. | % | |||
| Inter-sententiales CS | 489 | 54,33 | 540 | 48,39 | 1.029 | 51,04 | ||
| Grußformeln | 81 | 9,00 | 364 | 32,62 | 445 | 22,07 | ||
| davon: | Begrüßung | 7 | 0,78 | 68 | 6,09 | 75 | 3,72 | |
| Verabschiedung | 70 | 7,78 | 279 | 25,00 | 349 | 17,31 | ||
| Anrede | 4 | 0,44 | 17 | 1,52 | 21 | 1,04 | ||
| Wiederholungen | 219 | 24,33 | 27 | 2,42 | 246 | 12,20 | ||
| Andere | 189 | 21,00 | 149 | 13,35 | 338 | 16,77 | ||
| Intra-sententiales CS | 411 | 45,67 | 576 | 51,61 | 987 | 48,96 | ||
| Alternation | 41 | 4,56 | 39 | 3,49 | 80 | 3,97 | ||
| davon: | Tag-Switching | 16 | 1,78 | 15 | 1,34 | 31 | 1,54 | |
| andere | 25 | 2,78 | 24 | 2,15 | 49 | 2,43 | ||
| Insertion | 370 | 41,11 | 537 | 48,12 | 907 | 44,99 | ||
| davon: | Nomen | 134 | 14,89 | 201 | 18,01 | 335 | 16,62 | |
| Eigennamen | 77 | 8,56 | 85 | 7,62 | 162 | 8,04 | ||
| Anredeformen | 28 | 3,11 | 71 | 6,36 | 99 | 4,91 | ||
| Wort | 49 | 5,44 | 63 | 5,65 | 112 | 5,56 | ||
| Wortintern | 11 | 1,22 | 27 | 2,42 | 38 | 1,88 | ||
| andere | 71 | 7,89 | 90 | 8,06 | 161 | 7,99 | ||
| Gesamt | 900 | 100,00 | 1.116 | 100,00 | 2.016 | 100,00 |
Innerhalb der Gruppe des inter-sententialen CS können verschiedene Strategien ausgemacht werden. Vor allem Wiederholungen und Grußformeln werden häufig in einer anderen Sprache als der Rest des Beitrags geäußert. Dabei sind Erstere vor allem in Statusmeldungen zu finden und Letztere in Posts. In Wiederholungen werden zumeist Glückwünsche und Danksagungen geäußert. Bei den Grußformeln hingegen handelt es sich in den meisten Fällen um Verabschiedungen. Aber auch weitere Strategien des Sprachwechsels konnten identifiziert werden. Dazu zählen Einleitungen beziehungsweise Zusammenfassungen und das Ausdrücken von Meinungen oder emotionalen Empfindungen. Aber auch die Verwendung von Zitaten oder idiomatischen Ausdrücken können in den Beiträgen beobachtet werden. Und schließlich werden Anredeformen in einer anderen Sprache benutzt, um bestimmte Freunde zu adressieren. In den intra-sententialen Switches zeigt sich eine deutliche Präferenz für Insertionen. Alternationen, worunter auch die Tag-Switches fallen, werden kaum verwendet. Zu den Insertionen werden alle möglichen Arten von Ein-Wort-Switches gerechnet, wobei Nomen, Eigennamen und Anredeformen aufgrund ihrer großen Anzahl als eigene Unterkategorien angeführt werden. Innerhalb der restlichen Insertionen überwiegen Insertionen von Nominal- und Präpositionalphrasen.
Auf Grundlage dieser Ergebnisse kann bestätigt werden, dass ein höherer Planungsaufwand bei den Facebook Beiträgen zu einer Präferenz von inter-sententialem CS führt. Und auch bei den innerhalb der intra-sententialen CS verwendeten Typen werden mit einer großen Mehrheit Switches verwendet, die keinen allzu hohen Planungsaufwand erfordern, beispielsweise Nomen-Switches.
Wie schon in Kapitel dargestellt, werden in den Studien nach einem sozio-pragmatischen Ansatz Strategien und Gründe für CS oft gleichermaßen als kommunikative Funktionen aufgezählt. Mit der hier vorgenommenen Unterteilung werden Strategien, wie Wiederholungen, Anreden, Grußformeln, mit der Begründung, dass hier bestimmte formale Eigenschaften zugrunde liegen, zu den strukturellen CS Typen gezählt. Davon ausgehend können Gründe und Funktionen identifiziert werden.
Innerhalb des inter-sententialen CS kann festgehalten werden, dass vor allem Wiederholungen dazu verwendet werden, mit dem Netzwerk, das auf Facebook geschaffen wurde, in Kontakt zu treten. Dabei handelt es sich meist um Glückwünsche. Durch die Sprachverwendung wird eine Zusammengehörigkeit signalisiert. Auch bei den Grußformeln ist diese Funktion erkennbar und so stellen diese eine Annäherung her und signalisieren Zusammengehörigkeit. Gleichzeitig demonstriert der Verfasser aber auch seine Sprachkenntnisse und äußert seine Identität als bilingualer Sprecher. In den übrigen inter-sententialen Switches dienen die Sprachwechsel der persönlichen Positionierung, aber auch der Selbstdarstellung durch die Performance in einer anderen Sprache. Zudem wird damit eine Annäherung an eine bestimmte Gruppe von Freunden erreicht und eine Gruppenidentität unter bestimmten Freunden geschaffen. Vereinzelt lässt sich auch hier schon der kreative Gebrauch von Sprachmischungen feststellen.
Auch innerhalb der intra-sententialen Switches lassen sich verschiedene Funktionen aufzeigen. Während bei den wenigen Tag-Switches beobachtet werden kann, dass die Sprachwechsel vor allem dem Ausdrücken von emotionaler Beteiligung dienen, konnte bei den restlichen Alternationen aufgrund der geringen Anzahl keine Klassifikation der kommunikativen Funktionen bestimmt werden. Hinsichtlich ihrer strukturellen Beschaffenheit ähneln sie allerdings den inter-sententialen Switches und so kann davon ausgegangen werden, dass dies auch bei den Funktionen der Fall ist. Nomen werden nur selten in einer anderen Sprache verwendet, um lexikalische Lücken zu füllen. Vielmehr beschreiben sie Gegenstände oder Handlungen, die entweder mit Deutschland oder Italien assoziiert werden können. Durch die Verwendung signalisiert der Nutzer seine Zugehörigkeit zu diesem Land und den Sprechern der Sprache dieses Landes. Anders ist es bei den englischen Nomen, denn der Nutzer demonstriert damit seine Sprachkenntnisse und Weltgewandtheit und stellt sich damit selbst dar. Bei der Verwendung von geographischen Eigennamen in einer anderen Sprache ist die Tendenz erkennbar, dass es sich dabei um die Sprache des Landes, in dem sich dieser Ort befindet, handelt. Durch deren Verwendung werden die Zugehörigkeit und die Verbindung, die der Nutzer zu diesem Ort hat, ausgedrückt. Auch spielerische Verwendungen können beobachtet werden, wenn beispielsweise der Eigennamen in einer anderen als der Landessprache verwendet wird. Die Anredeformen, die in Insertionen verwendet werden, sind vergleichbar mit den Anredeformen, die zu den Grußformeln des inter-sententialen CS gezählt wurden und erfüllen somit auch ähnliche Funktionen. Die restlichen Ein-Wort-Switches können schließlich zu einem großen Teil mit den eben genannten Funktionen der Nomen-Switches begründet werden, allerdings ist eine Tendenz erkennbar, dass die bewusste Wahl dieser Wörter einem kreativen, spielerischen Zweck dient. Am deutlichsten zeigt sich dieser Verwendungszweck bei den wortinternen Switches, aber auch bei den verbleibenden Insertionen. Erstere stellen in den Beiträgen eigentlich immer ein bewusstes und geplantes Spiel mit der Sprache dar (insofern es sich dabei nicht um Entlehnungen handelt) und auch bei den Letzteren lässt sich diese Funktion des kreativen Sprachgebrauchs erkennen.
Die Sprachwechsel lassen sich unter Einbezug der wichtigsten primären Funktionen von Facebook (siehe Der Selbstpräsentation und dem Social Networking.
- Selbstpräsentation
- Darstellung als bilingualer Nutzer
- Signalisieren der Zugehörigkeit zu einer bestimmten Nutzgemeinschaft
- Demonstration von Weltoffenheit und -gewandtheit
- Humor, spielerischer Umgang mit Sprache
- Markieren von Verbindungen zu Sprechern, Orten oder Ländern
- Social Networking
- Schaffen eines Netzwerkes von Facebook Freunden
- Aufrechterhalten und Pflege des Netzwerkes
- Signalisieren der Zugehörigkeit zu einer Nutzergemeinschaft
Die Selbstpräsentation ist dabei in gewisser Art und Weise auch Voraussetzung für Social Networking und es sei zu vermerken, dass sich diese beiden Funktionen nicht immer klar voneinander trennen lassen. Allerdings ist hier die Gerichtetheit oder der Bezug zu den anderen Nutzern wichtig. Während bei der Selbstpräsentation in erster Linie der Nutzer selbst im Fokus steht, sind es bei der Social Networking Funktion die anderen Facebook Freunde.
Damit erklären sich auch die Unterschiede bei den verwendeten CS Typen in den Facebook Statusmeldungen und Posts. Bei einer Betrachtung nach Beitragsart lassen sich dabei deutliche Präferenzen erkennen. Während das Social Networking in Posts überwiegt und mittels Grußformeln und Anreden der Nutzer häufig direkt angesprochen wird, ist das Adressatenfeld in den Statusmeldungen weiter angelegt. Diese dienen oft nur der Selbstdarstellung und sind an niemanden konkret adressiert.
Schließlich lässt sich ein Zusammenhang zwischen inter- und intra-sententialem CS und den kommunikativen Funktionen feststellen. Während bei den inter-sententialen Switches vor allem die Selbstdarstellung und die Ansprache möglichst vieler Facebook Freunde im Fokus stehen, steigt in den intra-sententialen Switches das Signalisieren der Zugehörigkeit zu bestimmten Teilgemeinschaften. Auch der spielerische, humorvolle Einsatz von Sprachwechseln ist hier deutlich größer.
Zusammenfassend lässt sich festhalten, dass CS in Facebook Beiträgen bestimmte kommunikative Funktionen erfüllt, die hier von strukturellen Typen und Strategien des CS ausgehend bestimmt werden konnten.
6.2.5. Diskussion
Mit diesem Auswertungsansatz wurde in dieser Arbeit ein neuer Weg eingeschlagen, CS zu analysieren. Ein direkter Vergleich mit Ergebnissen aus der Forschungsliteratur ist deshalb nicht möglich, sondern erfolgt entweder nach einem rein strukturellen oder nach einem rein sozio-pragmatischen Ansatz.
Bei einem Vergleich nach Ersterem zeigt sich, dass die Verteilung nach strukturellen CS Typen deutlich von Studien zur spontanen, gesprochenen Sprache abweicht. Allerdings ist das hinsichtlich der CMC nicht ganz ungewöhnlich. So stellt auch Androutospulos 8cite key=androutsopoulos2006 f=year] in den von ihm untersuchten Ethnoportalen fest, dass es dort mehr inter-sententiales CS gibt und bemerkt, dass die Insertionen innerhalb des intra-sententialen CS überwiegen. Der Autor kann ebenfalls Grußformeln und Anreden innerhalb der Insertionen ausmachen. Auch in anderen Formen der CMC überwiegt inter-sententiales CS (vgl. Cárdenas-Claros & Isharyanti 2009). Allerdings werden hier bei weitem mehr Tag-Switches gefunden, die meist als eigene Kategorie analysiert wurden. Der Anteil dieser Switches ist im vorliegenden Korpus mit 1,54% (siehe Tabelle 55) sehr klein im Vergleich zur Studie von Cárdenas-Claros & Isharyanti (2009). Nun könnte zwar gemutmaßt werden, dass das an der Form der CMC liegt – die Autoren beschreiben CS in Chats – allerdings lassen sich auch in den Studien zu CS auf Facebook mit Anteilen von 8% (vgl. Hidayat 2012) bis 17% (vgl. Sukyadi & Wirza & Hasiani 2012) deutlich mehr Switches dieser Art erkennen. Da bei den Letzteren jeweils das Englische eine wichtige Rolle in diesem Switching-Typ spielt, kann der verhältnismäßig niedrige Anteil in dieser Arbeit mit den verwendeten Sprachkombinationen erklärt werden.221
Bei einem Vergleich mit den Ergebnissen aus Studien nach einem sozio-pragmatischen Ansatz zeigt sich, dass sich hier ähnliche Funktionen und Gründe für den Sprachwechsel ausmachen lassen wie in Studien zur gesprochenen Sprache. Auch Androutsopoulos & Hinnenkamp (2001) konnten dies schon feststellen. Bei einem Vergleich mit anderen Studien zu den kommunikativen Funktionen der CMC Typen zeigt sich jedoch, dass es durchaus Unterschiede gibt. Während nach Montes-Alcalá (2007), Hidayat (2012) und Sukyadi & Wirza & Hasiani (2012) vor allem die lexikalische Notwendigkeit eine Rolle spielt, stellt diese in den Facebook Beiträgen nur eine untergeordnete Funktion dar; und dies auch nur in Ein-Wort-Switches.222 Schließlich konnte hier bestätigt werden, dass Sprachwechsel in der CMC dazu dienen können, Zusammengehörigkeit und Annäherungen an bestimmte Facebook Freunde zu signalisieren (vgl. Ackermann 2007, Androutsopoulos & Hinnenkamp 2001, Paolillo 1996). Auch in anderen Studien wurde schon vorgeschlagen, dass CS auch der Selbstpräsentation dienen kann (vgl. Georgakopoulous 1997, Lanz Vallejo 2011). In den Facebook Beiträgen wurde das bestätigt und sogar behauptet, dass die Selbtsdarstellung eines der übergeordneten Ziele darstellt. Das liegt vor allem auch an einer der primären Funktionen von Facebook, die darin besteht, sich dort mit einem Profil und seinen geteilten Beiträgen selbst zu präsentieren. Zu dieser Selbstdarstellung lässt sich auch die humoristische, spielerische Verwendung zuordnen, die in so einem Ausmaß sonst nur bei Twitter festgestellt wurde (vgl. Lanz Vallejo 2011). Schließlich konnte auch hier gezeigt werden, dass CS selten durch externe Faktoren getriggert wird, sondern dass es meist geplant und bewusst eingesetzt wird.
Schließlich wurde eine der kommunikative Funktionen, die häufig in der CS benannt wird (siehe Kapitel ), hier ganz außen vor gelassen: die Emphatisierungsfunktion. Es konnte jedoch gezeigt, dass CS in Facebook Beiträge ganz bewusst eingesetzt wird und deshalb eigentlich immer eine hervorhebende Funktion hat.
Bei der allgemeinen Sprachverteilung konnte verifiziert werden, dass vor allem Deutsch und Italienisch verwendet werden, was aufgrund der Nutzerauswahl nicht weiter verwunderlich ist. Während im inter-sententialen CS häufig mehr als diese beiden Sprachen verwendet wurden (vor allem in den Wiederholungen), stellte beim intra-sententialen CS entweder das Deutsche oder das Italienische die Basissprache dar, in die Elemente aus der anderen Sprache eingefügt wurden. Dabei zeigte sich, dass Sprachwechsel, bei denen deutsche Elemente in ansonsten auf Italienisch verfasste Sätze eingefügt werden, deutlich überwiegen. Schließlich konnte auch die wichtige Rolle des Englischen ausgemacht werden. Vor allem in Nomen-, Einzel-Wort- und wortinternen Switches wurden viele Elemente aus dem Englischen gefunden. Dabei handelt es sich häufig um Entlehnungen, weshalb die Anzahl der Switches in Tabelle 55 entsprechend nach unten korrigiert werden müsste.223 Auch Ausdrücke, die für die CMC und das mediale Umfeld spezifisch sind, konnten beobachtet werden. Dies passt auch zu den Erkenntnissen aus anderen Studien. Androutsopoulos (2001, 12–13) stellt beispielsweise fest, dass Anglizismen häufig in Sprachpaaren, bei denen keine der beiden Sprachen Englisch ist, zu finden sind. Dies lässt sich darauf zurückführen, dass das Englische eines der besonderen Merkmale der CMC darstellt (siehe Kapitel ): „Sein Gebrauch markiert Teilhabe an der globalen Chatter-Community, gleichzeitig ist er ritualisiert und vorhersagbar und stellt kein echtes alternierendes Switchen dar“ (Androutsopoulos & Hinnenkamp 2001, 32). Ein Vergleich mit Studien zu anderen Sprachpaarungen könnte das bestätigen.
Es kann festgehalten werden, dass eine Bestimmung der kommunikativen Funktionen ausgehend von den strukturellen CS Typen sinnvoll ist. Zum einen trägt es zu einem besseren Vergleich dieser Typen bei und außerdem zeigt es, welche Funktionen in den Facebook Beiträgen überwiegen. Zum anderen wurde dieser Ansatz auch damit begründet, dass Nutzer bestimmte CS Strategien bewusst einsetzen, um mit den Sprachwechseln bestimmte Zwecke zu erfüllen. Ein Vergleich der CS Verwendung unter den Nutzern zeigt auch deutlich, dass bestimmte Nutzergruppen bestimmte CS Typen bevorzugen. Auch der Vergleich zwischen Statusmeldungen und Posts beweist, dass Nutzer und Facebook Freunde bestimmte CS Typen geplant einsetzen, um damit auch bestimmte Ziele zu erreichen. So verwenden Facebook Freunde eher Grußformeln aus Gründen des Social Networking, während die Facebook Nutzer selbst häufig Wiederholungen verwenden; vor allem aus Gründen der Selbstpräsentation. Interessant wäre zu überprüfen, inwieweit das mit dem hier betrachteten Untersuchungsgegenstand zusammenhängt. Ein Vergleich mit einer anderen Form der CMC könnte hier weitere Erkenntnisse liefern.
Abschließend soll noch einmal die Behauptung aufgegriffen werden, dass sich eine hohe Anzahl an Insertionen auf geringe Sprachkompetenz zurückführen lassen (vgl. Cárdenas-Claros & Isharyanti 2009). Dem sei hier allerdings widersprochen, da zum einen die allgemeine Sprachverteilung schon gezeigt hat, dass auch komplette Beiträge in den beiden in Betrachtung gezogenen Sprachen verfasst werden. Zum anderen zeigt auch die große Anzahl an anderen CS Typen, dass die Sprachkompetenz im Allgemeinen hoch ist. Schließlich spricht vor allem der geplante und bewusste Einsatz gegen diese Ansicht.
Die Prämisse der vorgestellten Auswertungen war, dass CS ein besonderes Merkmal der CMC darstellt. In Kapitel wurden Sprachwechsel dabei als sprachliche Kommunikationsmittel der CMC, die dort neben anderen nichtsprachlichen und parasprachlichen Besonderheiten verwendet werden, vorgestellt. In den vorangehenden Unterkapiteln wurde in den Beispielen auch schon deutlich, dass innerhalb der gemischtsprachigen Beiträge weitere Merkmale der CMC Verwendung finden, wie Phoneticons und Emoticons. Gerade Emoticons werden häufig als Trennungszeichen verwendet, weshalb sie sogar als ein Kriterium zur Bestimmung von inter-sententialem CS benutzt wurden (siehe Kapitel ):
[FB 1021_732]
un grazie a tutti per gli auguri „smile“-Emoticon danke an alle für die Glückwünsche!
Es könnte nun vermutet werden, dass Emoticons noch weitere Funktionen erfüllen. Sie könnte beispielweise zeigen, ob der Zweck des Sprachwechsels humoristischer und/oder spielerischer Natur ist. Tatsächlich zeigt ein Vergleich des Verhältnisses der Anzahl an Emoticons zur Gesamtanzahl der Beiträge nach Sprachen, dass diese in gemischtsprachigen Beiträgen am größten ist.
| mix | de | it | ||||
| Anz. | Verhältnis | Anz. | Verhältnis | Anz. | Verhältnis | |
| „smile“-Emoticon | 303 | 22,13 | 387 | 23,84 | 531 | 13,66 |
| „heart“-Emoticon | 206 | 15,05 | 81 | 4,99 | 446 | 11,47 |
| „wink“-Emoticon | 150 | 10,96 | 220 | 13,56 | 173 | 4,45 |
| „grin“-Emoticon | 83 | 6,06 | 83 | 5,11 | 84 | 2,16 |
| „frown“-Emoticon | 45 | 3,29 | 59 | 3,64 | 71 | 1,83 |
| „tongue“-Emoticon | 31 | 2,26 | 20 | 1,23 | 40 | 1,03 |
| „kiss“-Emoticon | 22 | 1,61 | 34 | 2,09 | 26 | 0,67 |
| „squint“-Emoticon | 2 | 0,15 | 0 | 0,00 | 13 | 0,33 |
| „kiki“-Emoticon | 2 | 0,15 | 3 | 0,18 | 9 | 0,23 |
| „unsure“-Emoticon | 3 | 0,22 | 1 | 0,06 | 5 | 0,13 |
| „unsure“-Emoticon | 3 | 0,22 | 1 | 0,06 | 5 | 0,13 |
| „gasp“-Emoticon | 0 | 0,00 | 1 | 0,06 | 5 | 0,13 |
| „cry“-Emoticon | 0 | 0,00 | 2 | 0,12 | 2 | 0,05 |
| „confused“-Emoticon | 1 | 0,07 | 0 | 0,00 | 0 | 0,00 |
| Gesamt | 851 | 62,16 | 892 | 54,96 | 1.410 | 36,27 |
Tabelle 56 zeigt, dass auf 100 italienische Beiträge 36,27 Emoticons kommen, während in 100 deutschen Beiträgen 54,96 Emoticons zu finden sind. In den gemischtsprachigen Beiträgen werden mit 62,16 Emoticons pro 100 Beiträge durchschnittlich am meisten Emoticons verwendet. Das lässt darauf schließen, dass Emoticons im CS besondere Funktionen einnehmen.
Allerdings werden Emoticons vor allem als Trennungszeichen eingesetzt. Das „smile“-Emoticon wird beispielsweise in insgesamt 169 Beiträgen mit inter-sententialem CS dazu verwendet, Sätze zu trennen. Trotzdem lassen Emoticons auch auf eine bestimmte Grundhaltung oder -stimmung des Beitrags schließen. Interessant sind des Weiteren die verhältnismäßig hohe Anzahl der „smile“-Emoticons und die Anzahl der „wink“-Emoticons in den gemischtsprachigen Beiträgen. Beispiel (153) zeigt, dass diese tatsächlich auch auf eine ironische Verwendung schließen lassen.
[FB 162177_1481]
ricevuto l´überweisung…ex ladrona „smile“-Emoticon ehehehe
Die hohe Anzahl an „heart“-Emoticons könnte schließlich die Funktion des Social Networkings unterstützen, da sie Affekt gegenüber den Adressaten ausdrücken können.
Auch wenn in den CS Beiträgen eine verhältnismäßig hohe Anzahl an Emoticons ausgemacht werden konnte, müssten diese auch in einsprachigen Beiträgen untersucht werden, um eine verlässliche Aussage darüber treffen zu können, dass diese die Funktionen von Sprachwechseln in Facebook Beiträgen unterstützen.
Wie schon in Kapitel gezeigt wurde, werden auch Phoneticons in den Facebook Beiträgen verwendet. Auch in den gemischtsprachigen Beiträgen lassen sie sich beobachten. Sie werden dabei sowohl im inter-sententialen als auch intra-sententialem CS verwendet, wie die folgenden Beispiele zeigen.
[FB 2211_460]
Der Plan is: Plattmachen „wink“-Emoticon … FORZA GERMAAANIAAAAAAA „smile“-Emoticon
[FB 1021_631]
ansonsten NIENTE!! (espressione tedesca mai sentita finora)
Phoneticons erfüllen dabei nicht nur die Funktion, bestimmte Teile eines Satzes hervorzuheben, sie markieren auch den Sprachwechsel an sich. Das bestätigt, dass CS von den Facebook Nutzern ganz bewusst eingesetzt wird, da der Nutzer diese durch die Versalienschreibung und Iteration von Buchstaben hervorhebt. Allerdings gibt es auch viele Sprachwechsel, die ohne diese Mittel hervorgehoben werden. Deshalb kann davon ausgegangen werden, dass die Phoneticons in den Beispielen (154) und (155) zusätzlich prosodische Merkmale widerspiegeln sollen. FORZA GERMAAANIAAAAAAA in Beispiel (154) kann danach als Imitation von Schreien interpretiert werden. Dabei ist dies jedoch eher ein allgemeines Merkmal der CMC und ist nicht als besonderes Merkmal des CS zu werten.
Somit lässt sich nicht bestätigen, dass andere Merkmale der CMC einen besonderen Status in den gemischtsprachigen Facebook Beiträgen haben. Zwar erfüllen sie hier häufig eine Trennungsfunktion (vor allem in Wiederholungen), allerdings sind sie eher als typische Merkmale der CMC zu verstehen. Es kann somit kein unmittelbarer Zusammenhang zwischen anderen Merkmalen der CMC und dem CS in den Facebook Beiträgen festgestellt werden.
7. Schlussfolgerung
Das Ziel dieser Arbeit war es, Sprachwechsel in einer speziellen Form der CMC, nämlich den Facebook Beiträgen, zu untersuchen, um festzustellen, wie und aus welchen Gründen CS verwendet wird. Als Basis dafür wurde ein annotiertes Korpus erstellt, mit Hilfe dessen CS identifiziert und strukturell klassifiziert werden konnte.
Die Erkenntnisse dieser Arbeit lassen sich dabei verschiedenen Bereichen zuordnen: 1. der Medienlinguistik sowie dem Bereich der linguistischen Forschung im Bereich der CMC, 2. der Korpus- oder Computerlinguistik und 3. der Mehrsprachigkeits- oder Sprachkontaktforschung.
In dieser abschließenden Diskussion sollen noch einmal die wichtigsten Aspekte und Erkenntnisse der vorliegenden Arbeit zusammengefasst werden. Dabei werden mit dem theoretischen Beitrag beginnend die Erkenntnisse, die im Bereich der computervermittelten Kommunikation durch die Gegenüberstellung verschiedener Definitionen, Klassifikationskriterien und Abgrenzungen gewonnen werden konnten, vorgestellt. Es folgt eine Synthese der Methoden, die den Beitrag dieser Arbeit im korpus- und computerlinguistischen Bereich hervorhebt. Abschließend wird auf die Schlussfolgerungen des vorangehenden Kapitels, das die Untersuchung der Sprachverwendung und der Sprachwechsel zum Inhalt hatte, eingegangen. Ein Ausblick auf Forschungsdesiderate und das Fazit schließen die Arbeit ab.
7.1. Facebook Beiträge als linguistischer Untersuchungsgegenstand
In dem ersten Teil der vorliegenden Arbeit wurde Facebook vorgestellt (siehe Kapitel ). Da sich das Aussehen, aber auch die Funktionen dieser Plattform immer weiter entwickeln und ändern, wurde eine systematische Beschreibung vorgenommen. Dabei wurde die Rolle Facebooks bei der Internetnutzung in Deutschland und Italien hervorgehoben. Der Fokus bei der Beschreibung richtete sich vor allem auf die kommunikativen Nutzungsmöglichkeiten. Die Facebook Beiträge, die den Untersuchungsgegenstand dieser Arbeit darstellten, wurden skizziert und in vom Nutzer selbst verfasste Statusmeldungen und von Facebook Freunden verfasste Posts unterteilt. Die primären kommunikativen Funktionen wurden ebenfalls benannt. Dazu zählt die Beschreibung dessen, was gerade gemacht wird, das Berichten von Alltäglichem, eigenen Meinungen oder dem persönlichen Befinden. Die Facebook Beiträge dienen aber auch dazu, Zitate, die der Nutzer gut findet, wiederzugeben, und stellen eine Plattform dar, Humoristisches zu teilen. Facebook ist aufgrund dessen auch als Social Network Seite (SNS) zu betrachten. Diese primären Funktionen, die sich unter Selbstdarstellung und dem Vernetzen mit anderen Facebook Nutzern zusammenfassen lassen, konnten später auch in den Sprachwechseln festgestellt werden.
Für eine Beschreibung der Facebook Beiträge als linguistischer Untersuchungsgegenstand war allerdings im Vorfeld eine Einordnung und Klassifikation notwendig. In Kapitel zeigte sich jedoch bei der Betrachtung verschiedener Definitionen, Begriffsvarianten und Unterkategorien der CMC, dass hier zunächst eine eindeutige Definition und Abgrenzung stattfinden musste: unter CMC wird danach die Kommunikation, die mit Hilfe von internetfähigen, computerbasierten Geräten zwischen Menschen stattfindet, verstanden. Die Art der CMC, die in dieser Arbeit diskutiert wurde, beschränkte sich dabei auf schriftliche, oder besser gesagt getippte, Texte.
In Kapitel konnte in der Diskussion darüber, wie sich die CMC in den medialen Diskurs einbetten lässt, gezeigt werden, dass sich die gängigen Medienbegriffe nur schwer auf die CMC übertragen lassen. Deshalb wurde hier für alle technischen Komponenten, die bei der CMC eine Rolle spielen, der Begriff des technischen Medienkomplexes vorgeschlagen. Darunter lassen sich alle im Computer inhärenten Elemente (Software, Hardware sowie das Internet) zusammenfassen. Die Beziehungen der einzelnen Komponenten zueinander sind dabei essentiell. Sie können dabei je nach Funktion verschiedene Arten von Medien darstellen: Speichermedium, Produktions- oder Präsentationsmedium, Übertragungsmedium oder gar digitalisierendes Medium. Mit letzterem Begriff wurde außerdem der Prozess der Digitalisierung hervorgehoben. Schließlich können Kommunikationsplattformen, wie Facebook, als Kommunikationsmedien bezeichnet werden. Die Einführung und Bestimmung des Begriffs des digitalen Medienkomplexes helfen somit dabei, die Grundlage der CMC zu bestimmen und eine Typisierung einzelner CMC Typen zu ermöglichen.
Nicht nur die speziellen äußeren Faktoren und Rahmenbedingungen der CMC machen aus den Facebook Beiträgen einen interessanten Untersuchungsgegenstand, auch innere Faktoren tragen dazu bei, dass diese in der Linguistik Berücksichtigung finden sollten. In einem zweiten theoretischen Teil konnte zum einen gezeigt werden, dass eine Einordnung der CMC als medial geschrieben, aber konzeptionell gesprochen schon allein aufgrund der Heterogenität der CMC Typen fragwürdig ist; und auch die Verortung der CMC auf dem Nähe-/Distanzkontinuum ist problematisch (siehe Kapitel ). So konnte auch hier aufgrund der verschiedenen Kommunikationsformen der CMC keine einheitliche Verortung vorgenommen werden. Es wurde festgehalten, dass allgemeine Kritikpunkte an dem Modell nach Koch & Oesterreicher bei der Adaption auf die CMC einfach mit übernommen wurden, wie beispielsweise die Operationalisierbarkeit. Andere Kritikpunkte bekommen vor diesem Hintergrund hingegen noch mehr Gewicht: Dazu zählt die fehlende Berücksichtigung des Mediums. Innerhalb des Modells bereitet schließlich vor allem die Kommunikationsbedingung „physische Nähe“ Probleme, da diese bei der CMC per definitionem nicht vorhanden sein muss. Die Schlussfolgerung, die daraus gezogen wurde, ist, dass eine Situierung in diesem Zusammenhang gar nicht von Nöten ist. Es wurde gezeigt, dass vielmehr die Affordanzen und Constraints, also die Rahmenbedingungen, die sich aus dem verwendeten digitalen Medienkomplex bei der CMC ergeben, die Kommunikationsform, die sich daraus herauskristallisiert, bestimmen. In Kapitel wurde dargestellt, dass sich spezifische sprachliche, aber auch nichtsprachliche Merkmale ohne den Kontext dieser Situierung ermitteln lassen – es braucht weder eine Sonderform, wie den lalischen Kode, noch ein Modell, das nur die CMC berücksichtigt. Eine wichtige Erkenntnis, die aus diesem Kapitel gezogen werden kann, ist, dass es nicht immer ohne weiteres möglich ist, etablierte Modelle aus der Linguistik einfach auf die CMC zu übertragen. Auch Adaptionen und Modifikationen stellen nicht immer zufriedenstellende Lösungen dar. Vielmehr sollten auf Grundlage der Daten neue Modelle geschaffen werden.
Das Fazit, das aus der Präsentation der Merkmale der CMC in Facebook Beiträgen in Kapitel gezogen werden kann, stützt die Behauptung, dass eine Situierung zwischen Mündlichkeit und Schriftlichkeit gar nicht nötig ist. Es wurden Merkmale vorgestellt, die in die Unterkategorien sprachlich, para- und nichtsprachlich geordnet wurden, wobei eine eindeutige Trennung dieser von vorneherein ausgeschlossen wurde. Merkmale, wie der Gebrauch von Gesprächswörtern, Inflektiven und Grußformeln, könnten den Rückschluss zulassen, dass die CMC Charakteristika übernimmt, die dem Gesprochenen und der Dialogizität zugeordnet werden können. Allerdings dienen Facebook Beiträge der Selbstdarstellung, weshalb hier von einem größeren Planungsaufwand ausgegangen werden kann. Diese Merkmale werden von den Nutzern somit bewusst eingesetzt und es könnte allerhöchstens behauptet werden, dass sie das Gesprochene imitieren. Allerdings zeugt die Verwendung anderer Merkmale, wie Emoticons und Phoneticons, aber auch der Einsatz von Abkürzungen, die ebenfalls bewusst eingesetzt werden, eher davon, dass diese als spezielle Merkmale der CMC angesehen und demensprechend verwendet werden. Weitere Argumente dafür sind auch die kreative Verwendung von Sprache, beispielsweise in Abkürzungen, beim Gebrauch fremdsprachlicher Elemente oder in Fällen von Code-Switching.
Zusammenfassend konnte gezeigt werden, dass es sich bei Facebook Beiträgen um eine Kommunikationsform der CMC handelt, die sowohl auf der Grundlage der äußeren als auch der inneren Faktoren einen interessanten linguistischen Untersuchungsgegenstand darstellt. Um dies an einem konkreten Beispiel zu verdeutlichen, wurde Code-Switching als ein Merkmal der CMC herausgegriffen, anhand dessen bestätigt wurde, dass die medialen Rahmenbedingungen Einfluss auf die Kommunikation mittels Facebook Beiträgen haben.
7.2. Das Facebook Korpus und die kombinierte Methode der Annotation
Diese Arbeit leistet auch einen Beitrag im Bereich der Korpus- und Computerlinguistik. Obwohl die Daten, die die Basis der Untersuchungen der vorliegenden Arbeit darstellen, digital vorhanden sind, mussten sie trotzdem aufbereitet werden, um in Form eines Korpus die Analyse der Daten zu ermöglichen. Bei der Extraktion der Daten mussten dabei verschiedene Kodierungen, wie die Emoticons, aber auch Iterationen von Buchstaben, Groß- und Kleinschreibung und nicht zuletzt die Diakritika der verwendeten Sprachen beachtet werden. Auch Vorüberlegungen zu Kriterien der Datensammlung, beispielsweise hinsichtlich des Datenschutzes, wurden angestellt (Kapitel ). Es konnten schließlich Methoden gefunden werden, die Daten zu sammeln, zu bereinigen und schließlich in einem Korpus auf einer Datenbank zu speichern. Die Dokumentation der Datensammlung in den Kapitel und DEFAULT zeigte, wie Korpora aufgebaut werden können und kann damit als Beitrag im Bereich der Korpuslinguistik verstanden werden.
Die größte Herausforderung stellte bei der Korpuserstellung die Annotation der Daten nach Sprachen dar. Eine morpho-syntaktische Annotation kann zwar mit bereits existierenden Annotationsprogrammen vorgenommen werden, diese sind jedoch immer nur auf eine bestimmte Sprache ausgelegt. Die Bestimmung der Sprachen in gemischtsprachigen Beiträgen war bisher mit gängigen Annotationsprogrammen nicht möglich; vor allem wenn nicht nur zwischen zwei sondern sogar mehreren Sprachen gewechselt wird. In Kapitel wurde ein Weg vorgeschlagen, wie sich mehrere Sprachen zu einem gemischtsprachigen Lexikon zusammenfassen lassen. Dieses Lexikon stellte wiederum den Ausgangspunkt für eine auf dem TreeTagger basierende Anwendung dar, mit der nicht nur die Sprache, sondern gleichzeitig auch die Wortarten hinzugefügt werden können. Damit wurde schließlich ein Datenbank basiertes Korpus erstellt, das nicht nur Facebook Beiträge enthält, sondern auch die Annotationen.
In einem Übersichtsteil in Kapitel wurde gezeigt, welche Informationen aus diesem Korpus herausgelesen werden können. So wurde nach der Korpuserstellung eine allgemeine Übersicht über die erhobenen Daten des Facebook Korpus vorgestellt. Bei der Präsentation der autobiographischen Daten wurde gezeigt, dass die Nutzer einen guten Querschnitt des typischen Facebook Nutzers darstellen. Es wurde unterstrichen, dass es zwar die Möglichkeiten gibt, Heimatland und aktuellen Wohnort anzugeben, die Angaben dazu wurden jedoch nicht immer mitgeteilt und sind in diesem virtuellen Raum auch nicht als relevant anzusehen. Dies konnte auch bei der Sprachverteilung und -wahl bestätigt werden. Dafür zeugen die angegeben Sprachkenntnisse der Nutzer davon, dass sie sich selbst als online bilingual betrachten. Bei der Übersicht über die Metadaten der gesammelten Facebook Beiträge zeigte sich, dass die Anzahl der nicht textbasierten Beiträge im Laufe der Jahre immer größer wurde. Trotzdem überwiegen in den gesammelten Daten die textbasierten Beiträge, wobei es mehr Statusmeldungen als Posts gibt. Die Ergebnisse hieraus vervollständigen die systematische Beschreibung von Facebook aus Kapitel 2.1 und lassen Tendenzen erkennen, in welche Richtung sich Facebook entwickeln könnte.
7.3. CS in Facebook Beiträgen als ein besonderes Merkmal der CMC
In der Aufarbeitung des Forschungsstandes zum CS in Kapitel zeigte sich, dass es zwar schon ein paar Studien zu CS in der CMC gibt, allerdings orientieren sich diese recht stark an den Ergebnissen aus der klassischen CS-Forschung. Diese Arbeit konzentrierte sich auf einen strukturellen und sozio-pragmatischen Ansatz, da dieser in Bezug auf den Untersuchungsgegenstand am vielversprechendsten anmutete. Die Fragestellung zielte dabei darauf ab, herauszufinden, wie und auf welche Art und Weise CS in den Facebook Beiträgen verwendet wird.
Die Sprachverwendung innerhalb des Korpus in Kapitel zeigte, dass es sich – unabhängig von den eigenen Angaben der Nutzer auf ihren Facebook Profilen – um bilinguale Nutzer handelt. Es ließen sich dabei zwei Gruppen identifizieren, die in ihren Beiträgen entweder das Italienische oder das Deutsche bevorzugen. Es konnte bei der Sprachverwendung ein Zusammenhang zwischen den Facebook Nutzern und ihren Facebook Freunden ausgemacht werden und es wurde der Schluss gezogen, dass sich die Nutzer bei der Sprachwahl vor allem an den verwendeten Sprachen ihrer Freunde orientieren. Es konnte jedoch nicht bestätigt werden, dass andere externe Kriterien, wie das Thema des Beitrags, die Wahl der Sprache oder des Sprachwechsels beeinflussen. Schließlich wurde jedoch die Annahme bestätigt, dass ausgehend von der Sprachverteilung auf der gesamten Facebook Chronik, Rückschlüsse über die verwendeten Sprachen in dem gemischtsprachigen CS gezogen werden können.
Die Auswertungen der Sprachwechsel in Kapitel Kapitel wurden nach einem strukturellen und einem soziolinguistischen Ansatz vorgenommen. Die Ergebnisse beider Bereiche heben sich deutlich von den Studien zum Gesprochenen ab. Und auch der Vergleich mit den vorliegenden Ergebnissen zu anderen Formen der CMC zeigte, dass CS hier besondere Charakteristika aufweist. Bei der Typisierung nach einem strukturellen Ansatz wurde festgestellt, dass die Verwendung von inter-sententialen Switches in den gemischtsprachigen Beiträgen überwiegt. Insbesondere Grußformeln und Wiederholungen sind wichtige Strategien dieser CS-Unterkategorie. Bei den intra-sententialen Switches werden vor allem Ein-Wort-Switches in Form von Nomen und geographischen Eigennamen verwendet. Die Verwendung bestätigte, dass CS in den Facebook Beiträgen ganz bewusst und geplant eingesetzt wird. Es handelt sich also nicht um spontane, psychologisch getriggerte Switches, weshalb davon ausgegangen werden kann, dass mit CS auch konkrete kommunikative Funktionen erfüllt werden sollen.
Die Auswertung, bei der von einer strukturellen Typisierung ausgehend die kommunikativen Funktionen des CS bestimmt wurden, ging damit einen neuen Weg. So zeigt sich, dass Selbstdarstellung und Social Networking die Hauptbeweggründe für Sprachwechsel in den Facebook Beiträgen sind. Es lässt sich dabei auch ein Zusammenhang zwischen dem CS Typ und dem Wechsel an sich feststellen. Während so im CS auf Satzebene verschiedene Sprachen vor allem aus Gründen der Vernetzung eingesetzt werden, dienen die Wechsel innerhalb eines Satzes dazu, die eigene Bilingualität unter Beweis zu stellen, eine Zugehörigkeit zu Land, Leuten oder Sprechern zu demonstrieren oder zeugen von der Fähigkeit, Sprache kreativ, spielerisch oder humoristisch einzusetzen.
Schließlich konnte festgestellt werden, dass die Wahl des CS Typs zwischen Posts und Statusmeldungen deutlich variiert und somit auch die kommunikativen Funktionen. Posts sind meist an den Nutzer gerichtet, dienen dem Social Networking und enthalten viele Grußformeln und Anredeformen. Statusmeldungen dienen eher der Selbstdarstellung und richten sich nicht nur an einzelne Nutzer, sondern meist an ganze Gruppen von Facebook Freunden oder gar an alle. Mit dieser Auswertung konnten so neue Erkenntnisse im Bereich der Sprachkontaktforschung gewonnen werden. Es wurde gezeigt, dass beim CS spezielle Typen bevorzugt werden, die bestimmte Funktionen erfüllen. Die identifizierten Funktionen lassen sich schließlich auch auf die Rahmenbedingungen der Facebook Beiträge, die durch das Kommunikationsmedium geprägt wurden, zurückführen.
7.4. Ausblick
Die Erkenntnisse und Ergebnisse aus dieser Arbeit führen zu einer Reihe von Forschungsdesideraten, die sich den verschiedenen hier besprochenen Teilbereichen zuordnen lassen. Zum einen hat sich hinsichtlich der CMC gezeigt, dass diese ein längst noch nicht ausreichend erforschtes Gebiet der Linguistik darstellt. Zum andere unterliegen die medialen Rahmenbedingungen ständigen Veränderungen und Erweiterungen, auf die mit Untersuchungen und systematischen Beschreibungen reagiert werden muss. Ein Vergleich der Ergebnisse der vorliegenden Arbeit mit Studien zu anderen CMC Typen könnte so zu einer besseren Kategorisierung der CMC und einer Bestimmung der entsprechenden Unterscheidungskriterien führen. Davon ausgehend könnte auch aufgezeigt werden, wie sich die Sprache in der CMC verändert. Die Beschreibung anderer sprachlicher Besonderheiten könnte ebenfalls zu einem besseren Verständnis der CMC beitragen. Es wurde außerdem immer davon ausgegangen, dass die CMC von der gesprochenen und geschriebenen Sprache, die nicht computervermittelt ablaufen, beeinflusst wird. Interessant wäre jedoch eine Untersuchung, ob auch die CMC auf diese Bereiche Einfluss hat und welcher Art diese sind.
Die vorhandenen Daten des Facebook Korpus können als Startpunkt für weiterführende Studien aus verschiedenen Bereichen der Linguistik dienen: Von einer genaueren Betrachtung der Funktionsweisen der Emoticons, über eine Beschreibung morphologischer Elemente in der CMC, bis hin zu einer syntaktischen Analyse italienischer oder deutscher Beiträge ist vieles denkbar. Ein Ausbau und die Erweiterung des Korpus sind dabei wünschenswert, denn auch wenn die Größe des Korpus die Datenbasis anderer Studien zu Sprachwechseln in der CMC deutlich übersteigt (siehe Kapitel ), ist sie im Verhältnis zu den großen Korpora der CMC, wie dem itWaC, recht klein. Auch in dem Bereich der Datenaufbereitung können weitere Ziele formuliert werden. Die Methode der kombinierten Annotation wurde bisher nur für Facebook Beiträge verwendet. Damit sich auch Texte aus anderen CMC Typen annotieren lassen, müsste das zugrundeliegende Korpus dahingehend trainiert und modifiziert werden. Schließlich können nach dem Vorbild der hier vorgestellten Annotationsmethode auch Programme für Annotationen auf anderen Ebenen erstellt werden, damit auch dort die Annotation für verschiedene alternierende Sprachen gewährleistet werden kann.
Schließlich ergeben sich auch aus den Schlussfolgerungen zum hier untersuchten CS weitere Fragen. Zum einen wäre ein Vergleich der Sprachverwendung und der Sprachwechsel bei anderen Sprachenpaaren interessant; dabei könnte auch die Rolle des Englischen weiter verfolgt werden. Ebenso könnten nach dem in dieser Arbeit verwendeten Ansatz Code-Switches in anderen CMC Formen untersucht werden, um festzustellen, welche Charakteristika den Sprachwechseln aller CMC Typen gleich sind und worin sie sich unterscheiden. CS könnte auch nach einem ganz anderen Ansatz untersucht werden. So ging die Auswertung wie hier vorgeschlagen von einem strukturellen Ansatz aus und untersuchte davon ausgehend die Funktionen. Bei der Konstruktionsgrammatik wird auch von Form-Bedeutungspaaren ausgegangen, weshalb in diesem Kontext geprüft werden könnte, ob eine Beschreibung innerhalb dieser Theorie möglich wäre.
Schließlich wurde bei der Analyse nach kommunikativen Funktionen die Vermutung vorausgesetzt, dass die Facebook Nutzer die Sprachwechsel bewusst einsetzen. Um zu überprüfen, inwieweit Sprachwechsel und deren kommunikativen Funktionen im Bewusstsein der Nutzer vorhanden sind, könnten weiterführende Studien dazu durchgeführt werden. Es würde sich beispielsweise eine Befragung der Nutzer anbieten, um deren Beweggründe für CS herauszufinden. Vorstellbar wäre hier ein Programm, das Sprachwechsel direkt beim Teilen und Veröffentlichen erkennt (zum Beispiel auf Grundlage des Sprachzuweisungs-Tools) und daraufhin den Nutzer nach dem Zweck und dem Grunde des Switches fragt. Ebenfalls möglich wäre hier auch eine perzeptive Studie, die zeigt, wie solche Sprachwechsel wahrgenommen werden.
7.5. Fazit
In dieser Arbeit wurde Code-Switching in den Beiträgen deutsch-italienischer Nutzer der Social Network Seite Facebook untersucht.
Die Arbeit leistet einen theoretischen Beitrag, indem verschiedene Konzepte diskutiert und Termini definitorisch aufgearbeitet werden. So wurde die CMC ausgehend von einem Medienkomplex definiert und klassifiziert. Eine Diskussion, ob und wo sich CMC im „Spannungsfeld zwischen Mündlichkeit“ und Schriftlichkeit verorten lässt, schließt mit der Feststellung, dass dies nicht möglich, aber auch nicht nötig ist, ab. Eine systematische Beschreibung des Untersuchungsgegenstandes mit einem Fokus auf die Kommunikation und die Auflistung der besonderen Merkmale, die in der Kommunikation mittels Facebook Beiträgen gefunden werden können, vervollständigen die Arbeit.
Es wurde außerdem ein Datenbank basiertes Korpus erstellt, in dem Facebook Beiträge gesammelt wurden. Mit Hilfe einer speziell für diese Arbeit entwickelten Methode der Korpusannotation wurden die darin enthaltenen sprachlichen Daten tokenisiert und mit Sprach-Tags und POS-Tags versehen. Diese kombinierte Methode der Korpusannotation auf morpho-syntaktischer und sprachlicher Ebene, stellte eine gute Grundlage für die Datenauswertung dar. Diese Methode kann somit als Grundlage für den Aufbau anderer mehrsprachiger Korpora dienen.
Schließlich liefert die Untersuchung der Sprachwechsel neue Erkenntnisse im Bereich der Mehrsprachigkeitsforschung. Es konnte gezeigt werden, dass in den Facebook Beiträgen CS bewusst eingesetzt wird und dabei verschiedene Strategien verwendet werden. Diese werden dabei von den bilingualen Nutzern eingesetzt, um bestimmte kommunikative Funktionen zu erfüllen.
Die vorliegende Arbeit zeigt, dass die Facebook Beiträge – und damit auch die CMC – linguistische Untersuchungsgegenstände darstellen, die es zu erforschen lohnt. Beim CS handelt es sich dabei um ein besonderes Merkmal der CMC, das auch in Facebook Beiträgen existiert und hier in einer besonderen Art und Weise verwendet wird. Außerdem konnte gezeigt werden, dass computergestützte Verfahren und die systematische Auswertung digitaler Daten der Linguistik neue Perspektiven eröffnen – ganz im Sinne der Digital Humanities.